Active Spatial Guidance: Eliminating Injected Positional Mechanisms in Vision Transformers
Pith reviewed 2026-07-02 14:50 UTC · model grok-4.3
The pith
Vision transformers can learn spatial organization from an auxiliary coordinate loss without any positional embeddings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
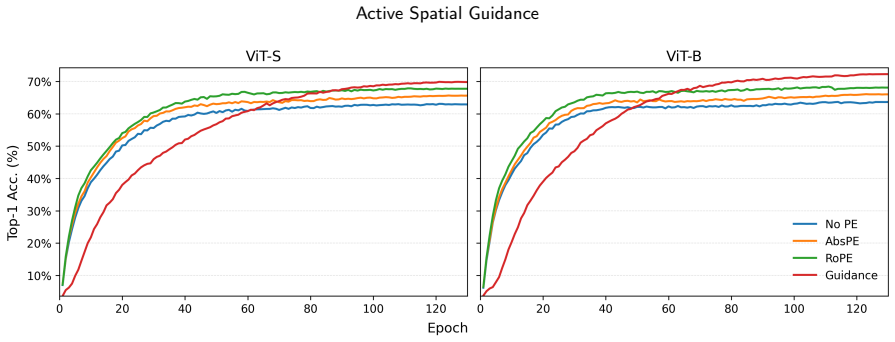
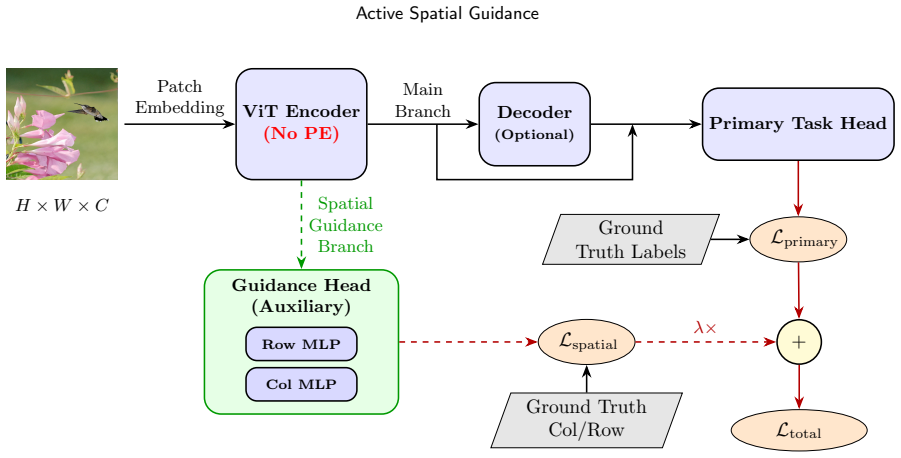
Active Spatial Guidance disables positional injection entirely and applies an auxiliary 2D coordinate-regression loss only to the final-layer patch tokens during training. The guidance head is discarded at inference, so the deployed model is a pure positional-injection-free ViT encoder plus task module. On ImageNet-100, ADE20K, and Hypersim, this yields higher accuracy than matched models that use learned absolute positional embeddings or rotary positional embeddings, with further gains in resolution-transfer robustness when multi-resolution training is added.
What carries the argument
Active Spatial Guidance: a training-only auxiliary 2D coordinate-regression loss on final-layer patch tokens that induces spatial organization without any positional injection mechanism.
If this is right
- Guidance improves ImageNet-100 top-1 accuracy over learned absolute and rotary positional embeddings under identical training.
- Guidance raises mIoU on ADE20K semantic segmentation and reduces depth error on Hypersim relative to the same injected baselines.
- Models trained with Guidance exhibit better accuracy when test resolution differs from training resolution.
- Multi-resolution training further improves Guidance models across a range of input sizes.
- Spatial inductive bias in ViTs can be supplied by training supervision instead of architectural injection.
Where Pith is reading between the lines
- If the coordinate loss truly organizes tokens, analogous auxiliary supervision might allow removal of positional encodings from other transformer domains such as language modeling.
- The approach could simplify architecture search by reducing the need to design or tune positional mechanisms.
- The method suggests that self-attention's permutation invariance can be countered by data-driven supervision rather than by explicit position signals.
Load-bearing premise
The performance gains are caused by genuine spatial organization learned via the auxiliary loss rather than by uncontrolled differences in optimization or regularization.
What would settle it
A controlled re-run in which models trained with Guidance show equal or lower accuracy than matched models that retain absolute or rotary embeddings on the same three tasks would falsify the central claim.
Figures
read the original abstract
Vision Transformers (ViTs) commonly rely on injected positional mechanisms to address self-attention's permutation invariance. Motivated by the spatial regularities of natural images, we ask whether spatial organization can be induced from data rather than explicitly injected. Under controlled, matched from-scratch training, we propose Active Spatial Guidance (Guidance), a training-only objective that disables positional injection and applies an auxiliary 2D coordinate-regression loss to the final-layer patch tokens. The guidance head is used only during training and removed for inference; the deployed model consists of a positional-injection-free ViT encoder and the task-specific prediction module. Using DINOv3 ViT backbones, Guidance consistently improves performance on ImageNet-100 classification, ADE20K semantic segmentation, and Hypersim monocular depth estimation, outperforming strong injected baselines such as learned absolute positional embeddings and rotary positional embeddings under identical training protocols. On ImageNet-100, broader comparisons against representative injected positional designs further support Guidance's effectiveness. Guidance also improves robustness under resolution transfer, and multi-resolution training further strengthens accuracy across input sizes. Overall, our results suggest that spatial inductive bias in ViTs need not be architecturally injected, but can be shaped through training-time supervision. The code used for training and evaluation is publicly available in https://github.com/cloudlc/asg.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Active Spatial Guidance, a training-only auxiliary 2D coordinate-regression loss on final-layer patch tokens of a positional-injection-free ViT. Under matched from-scratch training with DINOv3 backbones, Guidance outperforms injected baselines (learned absolute and rotary positional embeddings) on ImageNet-100 classification, ADE20K segmentation, and Hypersim depth estimation; the head is removed at inference. Additional results cover resolution transfer and multi-resolution training, with public code released.
Significance. If the central empirical claim holds after controls, the work shows that spatial inductive bias need not be architecturally injected and can instead be shaped by training-time supervision, which would simplify ViT design and potentially improve robustness. Public code is a clear strength for reproducibility.
major comments (2)
- [Abstract, §3 (method), §4 (experiments)] The interpretation that gains arise specifically from learned spatial organization (rather than from the mere presence of any auxiliary loss) requires an ablation with a non-spatial auxiliary target (e.g., regression to random coordinates or a mismatched task). No such control is described in the abstract or experimental sections; without it the causal link between the 2D spatial objective and the observed deltas remains unisolated.
- [§4.1, Table 1] §4.1 and Table 1: the reported gains are stated to be under identical training protocols, yet no values are given for the auxiliary-loss weight, number of random seeds, or statistical testing; these omissions make it impossible to assess whether the performance deltas are robust or sensitive to hyper-parameter choices.
minor comments (2)
- [§3] Notation for the guidance head and its removal at inference could be formalized with a short equation or diagram in §3 to avoid ambiguity.
- [Figures 2–4] Figure captions should explicitly list the exact baseline configurations (e.g., “RoPE with same training schedule”) for quick cross-reference.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and will revise the manuscript to incorporate the suggested improvements for clarity and rigor.
read point-by-point responses
-
Referee: [Abstract, §3 (method), §4 (experiments)] The interpretation that gains arise specifically from learned spatial organization (rather than from the mere presence of any auxiliary loss) requires an ablation with a non-spatial auxiliary target (e.g., regression to random coordinates or a mismatched task). No such control is described in the abstract or experimental sections; without it the causal link between the 2D spatial objective and the observed deltas remains unisolated.
Authors: We agree that an ablation with a non-spatial auxiliary target (such as regression to random coordinates) would help isolate whether the performance gains are specifically due to the spatial 2D coordinate objective rather than the presence of any auxiliary loss. While the design of Active Spatial Guidance is motivated by spatial supervision, this control experiment was not included in the original submission. We will add the requested ablation to the revised experimental section to strengthen the causal claim. revision: yes
-
Referee: [§4.1, Table 1] §4.1 and Table 1: the reported gains are stated to be under identical training protocols, yet no values are given for the auxiliary-loss weight, number of random seeds, or statistical testing; these omissions make it impossible to assess whether the performance deltas are robust or sensitive to hyper-parameter choices.
Authors: We acknowledge that the auxiliary-loss weight, number of random seeds, and any statistical testing details were not explicitly reported in §4.1 or Table 1, which limits assessment of robustness. These values are fixed across all compared methods and documented in the released code, but we agree they should be stated in the paper. We will add the specific hyper-parameter values, seed counts, and relevant statistics to the revised §4.1 and Table 1. revision: yes
Circularity Check
No circularity; empirical comparisons rest on external benchmarks and matched protocols
full rationale
The paper proposes an auxiliary 2D coordinate-regression loss applied only at training time to induce spatial organization in a positional-injection-free ViT, then reports performance gains on ImageNet-100, ADE20K, and Hypersim against learned absolute and rotary embeddings under identical from-scratch training. No equations, parameter fits, or self-citations are invoked to derive the central claim; results are obtained by direct experimental comparison to independent baselines. The method is self-contained against external benchmarks with no reduction of predictions to fitted inputs or author-specific priors.
Axiom & Free-Parameter Ledger
free parameters (1)
- auxiliary loss weight
axioms (1)
- domain assumption Natural images exhibit spatial regularities that can be captured by regressing 2D coordinates from final-layer tokens.
Reference graph
Works this paper leans on
-
[1]
A 2D Semantic-Aware Position Encoding for Vision Transformers. doi:10.48550/arXiv.2505.09466. Chen, Y., Shen, X., Liu, Y., Tao, Q., Suykens, J.A.,
-
[2]
ImageNet: A large-scale hierarchical image database, in: 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 248–255. doi:10.1109/CVPR.2009.5206848. Doersch, C., Gupta, A., Efros, A.A.,
-
[3]
Dosovitskiy,A.,Beyer,L.,Kolesnikov,A.,Weissenborn,D.,Zhai,X.,Unterthiner,T.,Dehghani,M.,Minderer,M.,Heigold,G.,Gelly,S.,Uszkoreit, J.,Houlsby,N.,2020
Unsupervised Visual Representation Learning by Context Prediction, in: International Conference on Computer Vision (ICCV). Dosovitskiy,A.,Beyer,L.,Kolesnikov,A.,Weissenborn,D.,Zhai,X.,Unterthiner,T.,Dehghani,M.,Minderer,M.,Heigold,G.,Gelly,S.,Uszkoreit, J.,Houlsby,N.,2020. AnImageisWorth16x16Words:TransformersforImageRecognitionatScale,in:InternationalCon...
2020
-
[4]
doi:10.48550/ arXiv.2403.18361
ViTAR: Vision Transformer with Any Resolution. doi:10.48550/ arXiv.2403.18361. Han,K.,Wang,Y.,Chen,H.,Chen,X.,Guo,J.,Liu,Z.,Tang,Y.,Xiao,A.,Xu,C.,Xu,Y.,Yang,Z.,Tao,D.,2022. Asurveyonvisiontransformer. IEEE Transactions on Pattern Analysis and Machine Intelligence 45, 87–110. doi:10.1109/TPAMI.2022.3152247. Haviv, A., Ram, O., Press, O., Izsak, P., Levy, O.,
-
[5]
1382–1390
Transformer Language Models without Positional Encodings Still Learn Positional Information, in: Findings of the Association for Computational Linguistics: EMNLP 2022, pp. 1382–1390. Heo,B.,Park,S.,Han,D.,Yun,S.,2024. Rotarypositionembeddingforvisiontransformer,in:EuropeanConferenceonComputerVision,Springer. pp. 289–305. Liu et al.:Preprint submitted to E...
2022
-
[6]
Journal of Visual Communication and Image Representation 89, Article 103664
The encoding method of position embeddings in vision transformer. Journal of Visual Communication and Image Representation 89, Article 103664. doi:10.1016/j.jvcir.2022.103664. Kim, G., Cho, H., Nam, H.,
-
[7]
Expert Systems with Applications 272, Article 126776
Solving jigsaw puzzles by predicting fragment’s coordinate based on vision transformer. Expert Systems with Applications 272, Article 126776. doi:10.1016/j.eswa.2025.126776. Liu, Z., Hu, H., Lin, Y., Yao, Z., Xie, Z., Wei, Y., Ning, J., Cao, Y., Zhang, Z., Dong, L., Wei, F., Guo, B.,
-
[8]
Ma,X.,Zhang,Z.,Yu,R.,Ji,Z.,Li,M.,Zhang,Y.,Chen,Q.,2024
Decoupled weight decay regularization, in: International Conference on Learning Representations. Ma,X.,Zhang,Z.,Yu,R.,Ji,Z.,Li,M.,Zhang,Y.,Chen,Q.,2024. SAVE:Encodingspatialinteractionsforvisiontransformers. ImageandVision Computing 152, Article 105312. doi:10.1016/j.imavis.2024.105312. Naseer,M.,Ranasinghe,K.,Khan,S.,Hayat,M.,Khan,F.S.,Yang,M.H.,2021. In...
-
[9]
8024–8035
PyTorch: An imperative style, high-performance deep learning library, in: Advances in Neural Information Processing Systems, pp. 8024–8035. Press,O.,Smith,N.A.,Lewis,M.,2022. TrainShort,TestLong:AttentionwithLinearBiasesEnablesInputLengthExtrapolation,in:International Conference on Learning Representations. Raghu, M., Unterthiner, T., Kornblith, S., Zhang...
2022
-
[10]
Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding, in: 2021 IEEE/CVF International Conference on Computer Vision, pp. 10892–10902. doi:10.1109/ICCV48922.2021.01073. Siméoni,O.,Vo,H.V.,Seitzer,M.,Baldassarre,F.,Oquab,M.,Jose,C.,Khalidov,V.,Szafraniec,M.,Yi,S.,Ramamonjisoa,M.,Massa,F.,Haziza, D.,Wehrstedt,L.,Wang,J.,Darcet...
-
[11]
DINOv3. doi:10.48550/arXiv.2508.10104. Su, J., Ahmed, M., Lu, Y., Pan, S., Bo, W., Liu, Y., 2024a. RoFormer: Enhanced transformer with Rotary Position Embedding. Neurocomputing 568, Article 127063. doi:10.1016/j.neucom.2023.127063. Su, K., Cao, L., Zhao, B., Li, N., Wu, D., Han, X., Liu, Y., 2024b. DctViT: Discrete cosine transform meet vision transformer...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.10104 2023
-
[12]
A bio-inspired positional embedding network for transformer-based models. Neural Networks 166, 204–214. doi:10.1016/j.neunet.2023.07.015. Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., Jégou, H.,
-
[13]
Training data-efficient image transformers & distillation through attention, in: International conference on machine learning, PMLR. pp. 10347–10357. Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser,Ł.,Polosukhin,I.,2017. AttentionisAllyouNeed,in:Advances in Neural Information Processing Systems, pp. 5998–6008. Wang, L., Tang, X.s.,...
2017
-
[14]
GFPE-ViT: vision transformer with geometric-fractal-based position encoding. Vis Comput 41, 1021–1036. doi:10.1007/s00371-024-03381-8. Wang, N., Meng, X., Meng, X., Shao, F.,
-
[15]
IEEE Transactions on Geoscience and Remote Sensing 60, 1–9
Convolution-Embedded Vision Transformer With Elastic Positional Encoding for Pansharpening. IEEE Transactions on Geoscience and Remote Sensing 60, 1–9. doi:10.1109/TGRS.2022.3227405. Wu, K., Peng, H., Chen, M., Fu, J., Chao, H.,
-
[16]
10033–10041
Rethinking and improving relative position encoding for vision transformer, in: Proceedings of the IEEE/CVF international conference on computer vision, pp. 10033–10041. Xiao,T.,Liu,Y.,Zhou,B.,Jiang,Y.,Sun,J.,2018. Unifiedperceptualparsingforsceneunderstanding,in:ProceedingsoftheEuropeanconference on computer vision (ECCV), pp. 418–434. Xiao, T., Singh, M...
2018
-
[17]
Xie,E.,Wang,W.,Yu,Z.,Anandkumar,A.,Alvarez,J.M.,Luo,P.,2021
Early convolutions help transformers see better, in: Proceedings of the 35th International Conference on Neural Information Processing Systems, Curran Associates Inc., Red Hook, NY, USA. Xie,E.,Wang,W.,Yu,Z.,Anandkumar,A.,Alvarez,J.M.,Luo,P.,2021. SegFormer:SimpleandEfficientDesignforSemanticSegmentationwith Transformers, in: Advances in Neural Informatio...
2021
-
[18]
Scene parsing through ADE20K dataset, in: 2017 IEEE Conference on Computer Vision and Pattern Recognition, pp. 5122–5130. doi:10.1109/CVPR.2017.544. Zhu,Q.,Bi,Y.,Chen,J.,Chu,X.,Wang,D.,Wang,Y.,2025.CentrallossguidescoordinatedTransformerforreliableanatomicallandmarkdetection. Neural Networks 187, Article 107391. doi:10.1016/j.neunet.2025.107391. Liu et al...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.