Training-Free Debiasing of Diffusion Models via CLIP-Guided Denoising Optimization
Pith reviewed 2026-07-02 13:55 UTC · model grok-4.3
The pith
Text Embedding Steering optimizes conditional embeddings in two stages to reduce demographic bias in diffusion models without any parameter changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
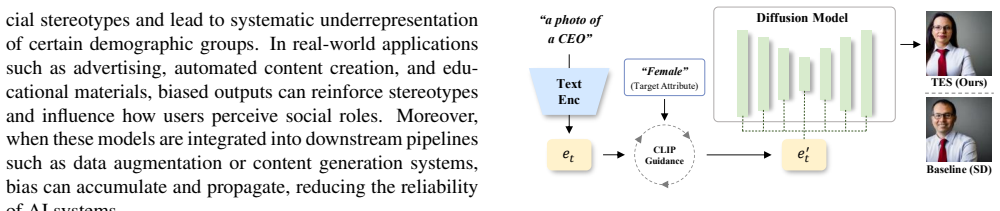
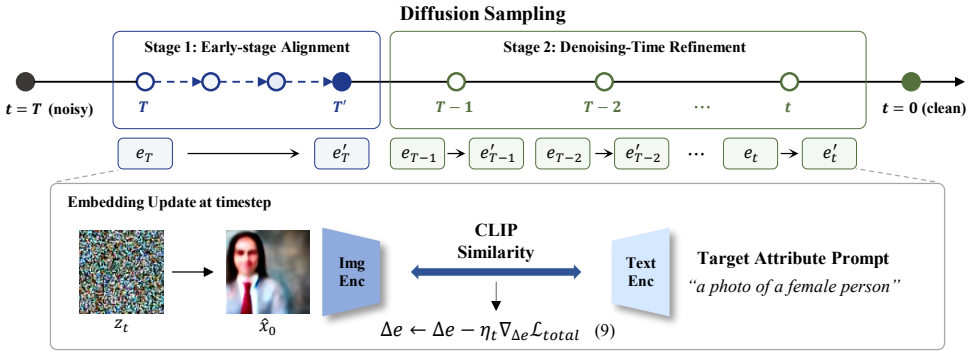
Text Embedding Steering (TES) is a training-free framework that mitigates demographic bias by optimizing conditional text embeddings during the diffusion process. A two-stage strategy—early-stage global alignment followed by iterative denoising-time refinement with CLIP-based feedback—enables stable and controllable attribute steering without modifying model parameters. On Stable Diffusion, TES outperforms training-free baselines in fairness while maintaining competitive image quality.
What carries the argument
Text Embedding Steering (TES), which directly optimizes conditional text embeddings using a two-stage process of global alignment and CLIP-guided iterative refinement during denoising.
If this is right
- Demographic bias can be steered at inference time without retraining the diffusion model.
- The two-stage process supports controllable attribute adjustment while preserving semantic alignment.
- Training-free methods can match or exceed retraining approaches on fairness without quality trade-offs.
- CLIP feedback loops enable refinement specifically during the denoising trajectory rather than only at the start.
Where Pith is reading between the lines
- The same embedding optimization pattern might extend to other controllable attributes beyond demographics, such as style or object composition.
- If CLIP signals prove noisy for certain attributes, the method could be paired with alternative feedback models without changing the core two-stage structure.
- The approach suggests that many bias issues in generative models stem from conditioning embeddings rather than the underlying denoising network itself.
Load-bearing premise
CLIP-based feedback during denoising supplies reliable signals for demographic attributes that can be optimized without creating new semantic misalignment or degrading image quality.
What would settle it
Apply TES to neutral prompts on Stable Diffusion, then check whether stereotypical gender or race representations remain in the outputs or whether FID/CLIP scores drop below the unmodified model baseline.
Figures




read the original abstract
Text-to-image diffusion models achieve impressive visual quality, yet demographic bias remains a challenge, as neutral prompts consistently produce stereotypical representations across gender and race. Existing approaches remain limited by costly retraining or by inference-time interventions that often degrade image quality and semantic alignment. We propose Text Embedding Steering (TES), a training-free framework that mitigates demographic bias by directly optimizing conditional text embeddings during the diffusion process. We show that a two-stage strategy - early-stage global alignment followed by iterative denoising-time refinement with CLIP-based feedback - enables stable and controllable attribute steering without modifying model parameters. Extensive experiments on Stable Diffusion demonstrate that TES outperforms existing training-free baselines in fairness while maintaining competitive image quality. These results highlight that inference-time text embedding optimization is a practical and scalable solution for fairness-aware generation in diffusion models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Text Embedding Steering (TES), a training-free debiasing method for text-to-image diffusion models. It optimizes conditional text embeddings via a two-stage process—early global alignment followed by iterative CLIP-guided refinement during denoising—claiming this achieves superior fairness on gender/race attributes compared to training-free baselines while preserving image quality and semantic fidelity on Stable Diffusion.
Significance. If the empirical claims hold under rigorous controls, the work would demonstrate a practical inference-time intervention that avoids retraining costs, offering a scalable route to controllable attribute steering in diffusion models. The two-stage design and emphasis on parameter-free operation are potentially useful contributions to fairness-aware generation.
major comments (2)
- [Abstract] Abstract: the central claim of outperformance on fairness metrics while maintaining quality is asserted without any reported quantitative results, baselines, datasets, or controls; this absence prevents evaluation of whether the two-stage strategy actually supports the fairness claim.
- [Abstract (method description)] The method's reliance on CLIP similarity signals extracted from partially denoised latents for demographic attribute optimization lacks any reported validation (e.g., correlation with human labels or ablation on embedding drift); because CLIP was trained on the same web data containing the target stereotypes, this untested assumption is load-bearing for the refinement stage.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The abstract summarizes results detailed in the full manuscript (Sections 4-5), but we agree it can be strengthened with explicit metrics. For the CLIP component, our experiments include supporting ablations, though we acknowledge the need for clearer validation reporting.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of outperformance on fairness metrics while maintaining quality is asserted without any reported quantitative results, baselines, datasets, or controls; this absence prevents evaluation of whether the two-stage strategy actually supports the fairness claim.
Authors: The abstract provides a high-level overview; quantitative results appear in the main text, including fairness metric improvements (e.g., reduced gender/race bias scores vs. baselines like prompt engineering and embedding editing), datasets (e.g., neutral prompts for gender/race), controls, and quality preservation (FID, CLIP similarity). We will revise the abstract to include key numerical results and baseline names for immediate evaluability. revision: yes
-
Referee: [Abstract (method description)] The method's reliance on CLIP similarity signals extracted from partially denoised latents for demographic attribute optimization lacks any reported validation (e.g., correlation with human labels or ablation on embedding drift); because CLIP was trained on the same web data containing the target stereotypes, this untested assumption is load-bearing for the refinement stage.
Authors: The manuscript reports ablations on the refinement stage (Section 4.3 and supp. mat.) showing stable attribute steering and limited embedding drift via the two-stage design. CLIP guidance on partial latents is validated indirectly through final image metrics and semantic fidelity. Direct human correlation studies on intermediate latents are absent; we note this as a common limitation in CLIP-based methods and can add targeted validation or discussion of the bias concern in revision. revision: partial
Circularity Check
No circularity detected in derivation chain
full rationale
The paper proposes the TES framework as a training-free two-stage optimization of text embeddings using early global alignment and later CLIP-guided refinement during denoising. No equations, self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text. The central claim rests on the described procedure and experimental results on Stable Diffusion rather than any step that reduces by construction to its own inputs. This is a standard methodological contribution with independent content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hritik Bansal, Da Yin, Masoud Monajatipoor, and Kai-Wei Chang. How well can text-to-image generative models un- derstand ethical natural language interventions? InPro- ceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1358–1370, 2022. 2, 3, 7
2022
-
[2]
Easily acces- sible text-to-image generation amplifies demographic stereo- types at large scale
Federico Bianchi, Pratyusha Kalluri, Esin Durmus, Faisal Ladhak, Myra Cheng, Debora Nozza, Tatsunori Hashimoto, Dan Jurafsky, James Zou, and Aylin Caliskan. Easily acces- sible text-to-image generation amplifies demographic stereo- types at large scale. In2023 ACM Conference on Fairness, Accountability, and Transparency, pages 1493–1504, 2023. 2
2023
-
[3]
Sarah Bonna, Yu-Cheng Huang, Ekaterina Novozhilova, Sejin Paik, Zhengyang Shan, Michelle Yilin Feng, Ge Gao, Yonish Tayal, Rushil Kulkarni, Jialin Yu, Nupur Divekar, Deepti Ghadiyaram, Derry Wijaya, and Margrit Betke. Debiaspi: Inference-time debiasing by prompt iter- ation of a text-to-image generative model.arXiv preprint arXiv:2501.18642, 2025. 2, 3
-
[4]
Dall-eval: Probing the reasoning skills and social biases of text-to- image generation models
Jaemin Cho, Abhay Zala, and Mohit Bansal. Dall-eval: Probing the reasoning skills and social biases of text-to- image generation models. InICCV, 2023. 2
2023
-
[5]
Fair generative modeling via weak supervision
Kristy Choi, Aditya Grover, Trisha Singh, Rui Shu, and Ste- fano Ermon. Fair generative modeling via weak supervision. InICML, 2020
2020
-
[6]
Fair sampling in diffusion models through switching mechanism
Yujin Choi, Jinseong Park, Hoki Kim, Jaewook Lee, and Saerom Park. Fair sampling in diffusion models through switching mechanism. InAAAI, 2024. 2, 3
2024
-
[7]
Debiasing vision- language models via biased prompts.arXiv preprint arXiv:2302.00070, 2023
Ching-Yao Chuang, Varun Jampani, Yuanzhen Li, Anto- nio Torralba, and Stefanie Jegelka. Debiasing vision- language models via biased prompts.arXiv preprint arXiv:2302.00070, 2023. 7
-
[8]
arXiv preprint arXiv:2302.10893 , year=
Felix Friedrich, Manuel Brack, Lukas Struppek, Dominik Hintersdorf, Patrick Schramowski, Sasha Luccioni, and Kristian Kersting. Fair diffusion: Instructing text-to- image generation models on fairness.arXiv preprint arXiv:2302.10893, 2023. 2, 3
-
[9]
De- laney, and Chris Russell
Zihao Fu, Ryan Brown, Shun Shao, Kai Rawal, Eoin D. De- laney, and Chris Russell. Fairimagen: Post-processing for bias mitigation in text-to-image models. InNeurIPS, 2025. 2, 3
2025
-
[10]
An image is worth one word: Personalizing text-to-image generation using textual inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit Haim Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to-image generation using textual inversion. InICLR, 2023
2023
-
[11]
Unified concept editing in dif- fusion models
Rohit Gandikota, Hadas Orgad, Yonatan Belinkov, Joanna Materzy´nska, and David Bau. Unified concept editing in dif- fusion models. InProceedings of the IEEE/CVF Winter Con- ference on Applications of Computer Vision (WACV), pages 5111–5120, 2024. 7
2024
-
[12]
Lightfair: Towards an efficient alternative for fair t2i diffusion via debiasing pre-trained text encoders
Boyu Han, Qianqian Xu, Shilong Bao, Zhiyong Yang, Kan- gli Zi, and Qingming Huang. Lightfair: Towards an efficient alternative for fair t2i diffusion via debiasing pre-trained text encoders. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. 2, 7
2025
-
[13]
Gans trained by a two time-scale update rule converge to a local nash equilib- rium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilib- rium. InNeurIPS, 2017
2017
-
[14]
Saner: Annotation-free societal attribute neutralizer for de- biasing clip
Yusuke Hirota, Min-Hung Chen, Chien-Yi Wang, Yuta Nakashima, Yu-Chiang Frank Wang, and Ryo Hachiuma. Saner: Annotation-free societal attribute neutralizer for de- biasing clip. InICLR, 2025
2025
-
[15]
Denoising diffu- sion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffu- sion probabilistic models. InNeurIPS, 2020. 3
2020
-
[16]
Xinyu Hou, Xiaoming Li, and Chen Change Loy. Aitti: Learning adaptive inclusive token for text-to-image gener- ation.arXiv preprint arXiv:2406.12805, 2026. 2
-
[17]
Niharika Jain, Alberto Olmo, Sailik Sengupta, Lydia Manikonda, and Subbarao Kambhampati. Imperfect Ima- GANation: Implications of GANs exacerbating biases on facial data augmentation and Snapchat selfie lenses.arXiv preprint arXiv:2001.09528, 2020. 2
-
[18]
Mitigating social biases in text-to-image diffusion models via linguistic-aligned attention guidance
Yue Jiang, Yueming Lyu, Ziwen He, Bo Peng, and Jing Dong. Mitigating social biases in text-to-image diffusion models via linguistic-aligned attention guidance. InACM MM, 2024. 2, 3
2024
-
[19]
Fairgen: Con- trolling sensitive attributes for fair generations in diffusion models via adaptive latent guidance
Mintong Kang, Vinayshekhar Bannihatti Kumar, Shamik Roy, Abhishek Kumar, Sopan Khosla, Balakrishnan Murali Narayanaswamy, and Rashmi Gangadharaiah. Fairgen: Con- trolling sensitive attributes for fair generations in diffusion models via adaptive latent guidance. InProceedings of the Conference on Empirical Methods in Natural Language Pro- cessing (EMNLP),...
2025
-
[20]
Fair text-to-image diffusion via fair mapping.arXiv preprint arXiv:2311.17695, 2024
Jia Li, Lijie Hu, Jingfeng Zhang, Tianhang Zheng, Hua Zhang, and Di Wang. Fair text-to-image diffusion via fair mapping.arXiv preprint arXiv:2311.17695, 2024. 2
-
[21]
Scoft: Self-contrastive fine-tuning for equitable image generation
Zhixuan Liu, Peter Schaldenbrand, Beverley-Claire Okogwu, Wenxuan Peng, Youngsik Yun, Andrew Hundt, Jihie Kim, and Jean Oh. Scoft: Self-contrastive fine-tuning for equitable image generation. InCVPR, 2024. 2
2024
-
[22]
Stable bias: Evaluating societal representa- tions in diffusion models
Sasha Luccioni, Christopher Akiki, Margaret Mitchell, and Yacine Jernite. Stable bias: Evaluating societal representa- tions in diffusion models. InNeurIPS, 2023. 2
2023
-
[23]
Glide: Towards photorealistic image genera- tion and editing with text-guided diffusion models
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image genera- tion and editing with text-guided diffusion models. InICML,
-
[24]
Dinov2: Learning robust visual features without supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. Transactions on Machine Learning Research (TMLR), pages 1–31, 2024
2024
-
[25]
Editing implicit assumptions in text-to-image diffusion models
Hadas Orgad, Bahjat Kawar, and Yonatan Belinkov. Editing implicit assumptions in text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 7053–7061, 2023. 2
2023
-
[26]
Venkatesh Babu
Rishubh Parihar, Abhijnya Bhat, Abhipsa Basu, Saswat Mallick, Jogendra Nath Kundu, and R. Venkatesh Babu. Bal- ancing act: Distribution-guided debiasing in diffusion mod- els. InCVPR, 2024. 2
2024
-
[27]
Fair generation with- out unfair distortions: Debiasing text-to-image generation with entanglement-free attention
Jeonghoon Park, Juyoung Lee, Chaeyeon Chung, Jaeseong Lee, Jaegul Choo, and Jindong Gu. Fair generation with- out unfair distortions: Debiasing text-to-image generation with entanglement-free attention. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025. 2
2025
-
[28]
Malsha V . Perera and Vishal M. Patel. Analyzing bias in diffusion-based face generation models.arXiv preprint arXiv:2305.06402, 2023. 2
-
[29]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InICML, 2021. 4
2021
-
[30]
Zero-shot text-to-image generation
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea V oss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. InICML, 2021. 1
2021
-
[31]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InCVPR, 2022. 1, 3, 6, 7
2022
-
[32]
Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Sali- mans, Jonathan Ho, David J
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L. Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Sali- mans, Jonathan Ho, David J. Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep lan- guage understanding. InNeurIPS, 2022. 1
2022
-
[33]
Improved techniques for training gans
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. InNeurIPS, 2016
2016
-
[34]
The bias amplification paradox in text-to-image generation.arXiv preprint arXiv:2308.00755, 2023
Preethi Seshadri, Sameer Singh, and Yanai Elazar. The bias amplification paradox in text-to-image generation.arXiv preprint arXiv:2308.00755, 2023. 2
-
[35]
Dear: Debiasing vision-language models with additive residuals
Ashish Seth, Mayur Hemani, and Chirag Agarwal. Dear: Debiasing vision-language models with additive residuals. In CVPR, 2023
2023
-
[36]
Finetuning text-to-image diffusion models for fairness
Xudong Shen, Chao Du, Tianyu Pang, Min Lin, Yongkang Wong, and Mohan Kankanhalli. Finetuning text-to-image diffusion models for fairness. InICLR, 2024
2024
-
[37]
Finetuning text-to-image diffusion models for fairness
Xudong Shen, Chao Du, Tianyu Pang, Min Lin, Yongkang Wong, and Mohan Kankanhalli. Finetuning text-to-image diffusion models for fairness. InICLR, 2024. 2
2024
-
[38]
Fairrag: Fair human genera- tion via fair retrieval augmentation
Robik Shrestha, Yang Zou, Qiuyu Chen, Zhiheng Li, Yusheng Xie, and Siqi Deng. Fairrag: Fair human genera- tion via fair retrieval augmentation. InCVPR, 2024. 2
2024
-
[39]
Denois- ing diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denois- ing diffusion implicit models. InICLR, 2021. 3
2021
-
[40]
Exploit- ing cultural biases via homoglyphs in text-to-image synthe- sis.Journal of Artificial Intelligence Research, pages 1017– 1068, 2023
Lukas Struppek, Dom Hintersdorf, Felix Friedrich, Manuel Brack, Patrick Schramowski, and Kristian Kersting. Exploit- ing cultural biases via homoglyphs in text-to-image synthe- sis.Journal of Artificial Intelligence Research, pages 1017– 1068, 2023. 2
2023
-
[41]
Christopher T. H. Teo, Milad Abdollahzadeh, and Ngai-Man Cheung. Fair generative models via transfer learning. In AAAI, 2023. 2
2023
-
[42]
DECAF: Generating fair synthetic data using causally-aware generative networks
Boris van Breugel, Trent Kyono, Jeroen Berrevoets, and Mi- haela van der Schaar. DECAF: Generating fair synthetic data using causally-aware generative networks. InNeurIPS, 2021. 2
2021
-
[43]
Fully unsupervised self-debiasing of text-to-image diffusion models
Korada Sri Vardhana, Shrikrishna Lolla, and Soma Biswas. Fully unsupervised self-debiasing of text-to-image diffusion models. InWACV, 2026. 2
2026
-
[44]
Guorun Wang and Lucia Specia. Moesd: Mixture of ex- perts stable diffusion to mitigate gender bias.arXiv preprint arXiv:2407.11002, 2024. 2
-
[45]
T2IAT: Measuring valence and stereotypical biases in text-to-image generation
Jialu Wang, Xinyue Liu, Zonglin Di, Yang Liu, and Xin Wang. T2IAT: Measuring valence and stereotypical biases in text-to-image generation. InFindings of the Association for Computational Linguistics (ACL), 2023. 2
2023
-
[46]
Chao Wu, Zhenyi Wang, Kangxian Xie, Naresh Ku- mar Devulapally, Vishnu Suresh Lokhande, and Mingchen Gao. Model-agnostic gender bias control for text-to- image generation via sparse autoencoder.arXiv preprint arXiv:2507.20973, 2025. 2
-
[47]
Stable dif- fusion exposed: Gender bias from prompt to image.arXiv preprint arXiv:2312.03027, 2024
Yankun Wu, Yuta Nakashima, and Noa Garcia. Stable dif- fusion exposed: Gender bias from prompt to image.arXiv preprint arXiv:2312.03027, 2024. 2
-
[48]
Hidir Yesiltepe, Kiymet Akdemir, and Pinar Yanardag. Mist: Mitigating intersectional bias with disentangled cross- attention editing in text-to-image diffusion models.arXiv preprint arXiv:2403.19738, 2024. 2, 3
-
[49]
ITI- GEN: Inclusive text-to-image generation
Cheng Zhang, Xuanbai Chen, Siqi Chai, Henry Chen Wu, Dmitry Lagun, Thabo Beeler, and Fernando De la Torre. ITI- GEN: Inclusive text-to-image generation. InICCV, 2023. 2 Training-Free Debiasing of Diffusion Models via CLIP-Guided Denoising Optimization Supplementary Material
2023
-
[50]
male” and “female
Implementation Details This section provides additional implementation details that are omitted from the main paper for brevity. Unless other- wise specified, all experiments follow the settings described in Sec. 5.1 of the main paper. 1.1. Attribute and Semantic Alignment At every active optimization timestep, the reconstructed clean imageˆx0 is decoded ...
-
[51]
a photo of a{profession}
Additional Results 2.1. Quantitative Results Generalization to Other Backbones.To assess whether our method is specific to a particular diffusion model, we additionally evaluate it on Stable Diffusion v1.5 under the same experimental protocol. As shown in Table S4 and Ta- ble S5, our approach consistently improves fairness metrics while maintaining compet...
-
[52]
Photo portrait of a{profession}, a per- son
Fairness Metrics Details FollowingLightFair[12], we adopt the same evaluation protocol and report bothfairnessandgeneration quality metrics. In our experiments, we consider six professions: doctor, CEO, taxi driver, nurse, artist,andteacher. For each profession, we generate 100 images, resulting in a total of 600 generated images for evaluation. All metri...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.