Persona Non Grata: LLM Persona-Driven Generations in MCQA are Unstable in Distinct Dimensions
Pith reviewed 2026-07-02 13:04 UTC · model grok-4.3
The pith
LLM persona-driven generations in multiple-choice question answering exhibit instability across performance, outcome, and question correctness that varies by model family, size, domain, and prompt format.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
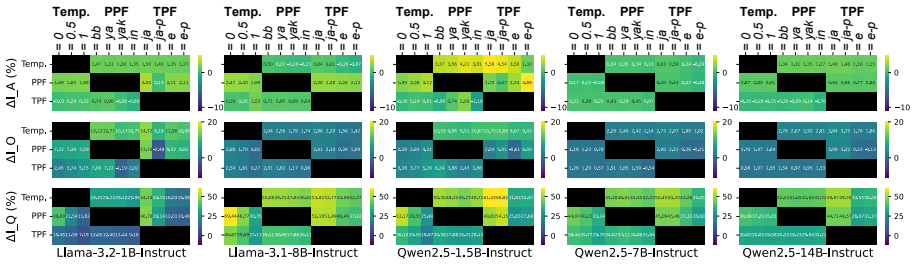
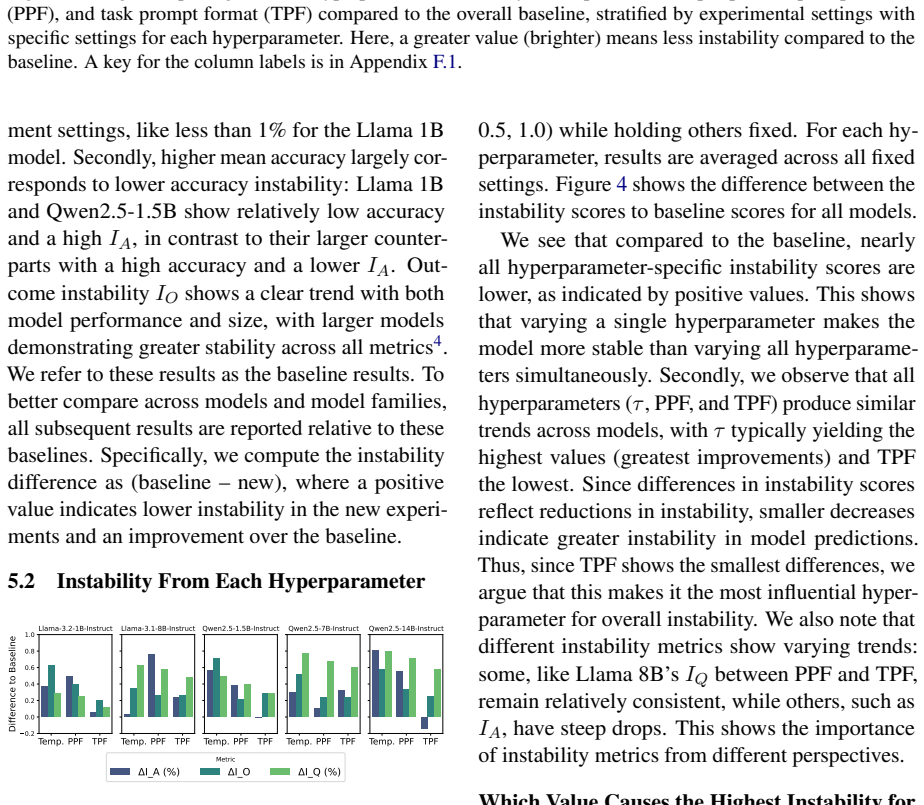
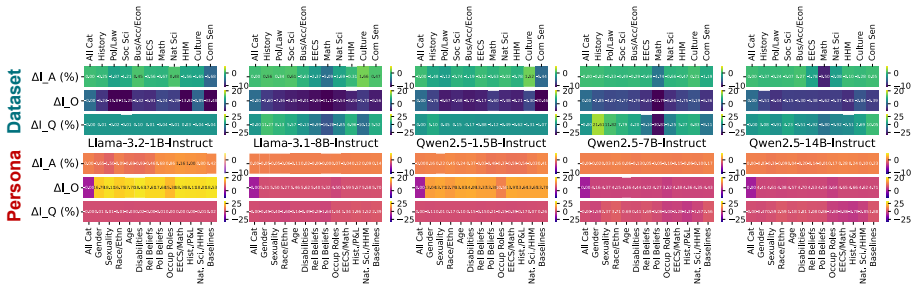
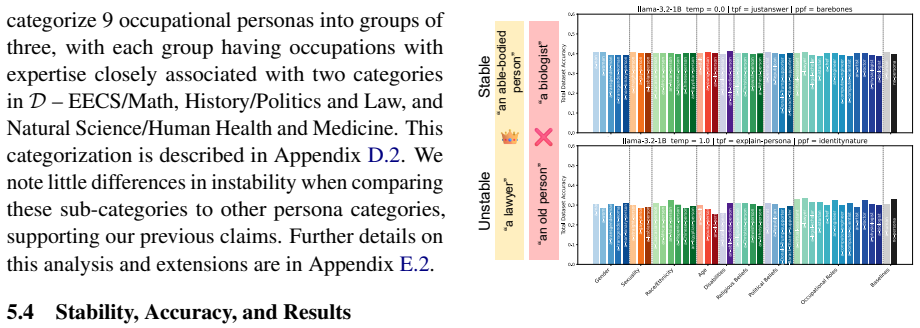
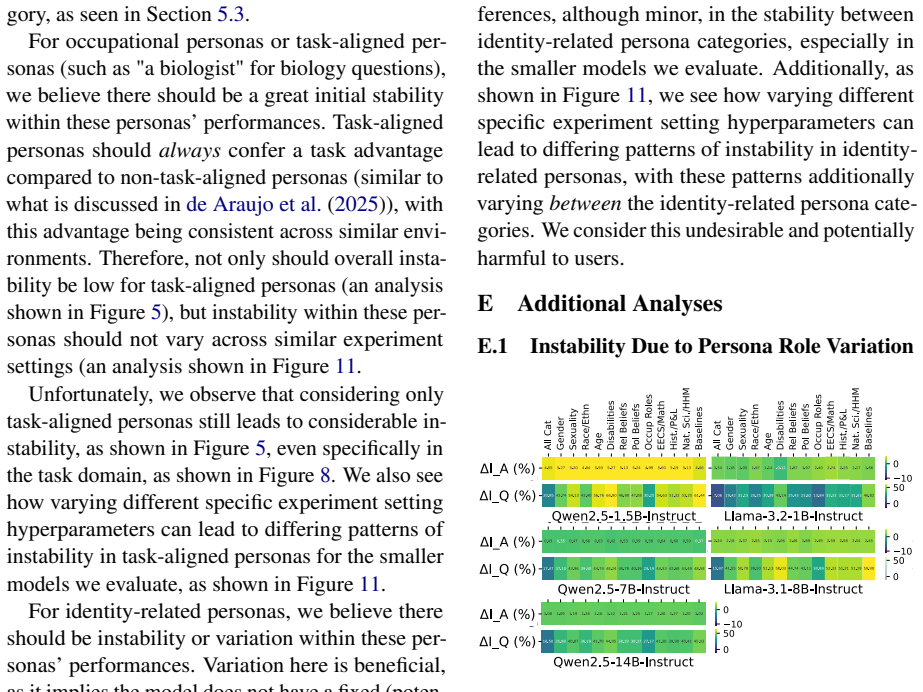
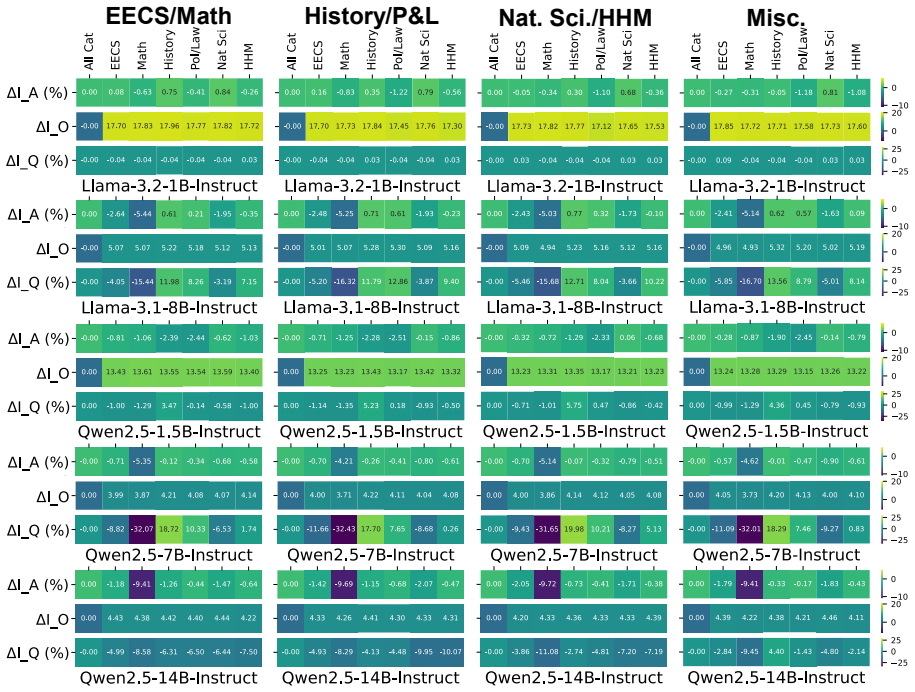
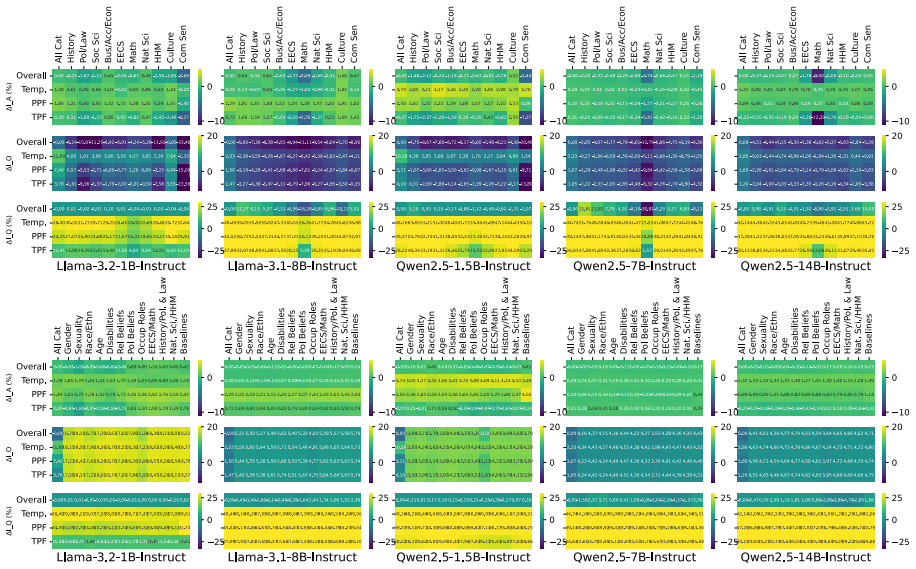
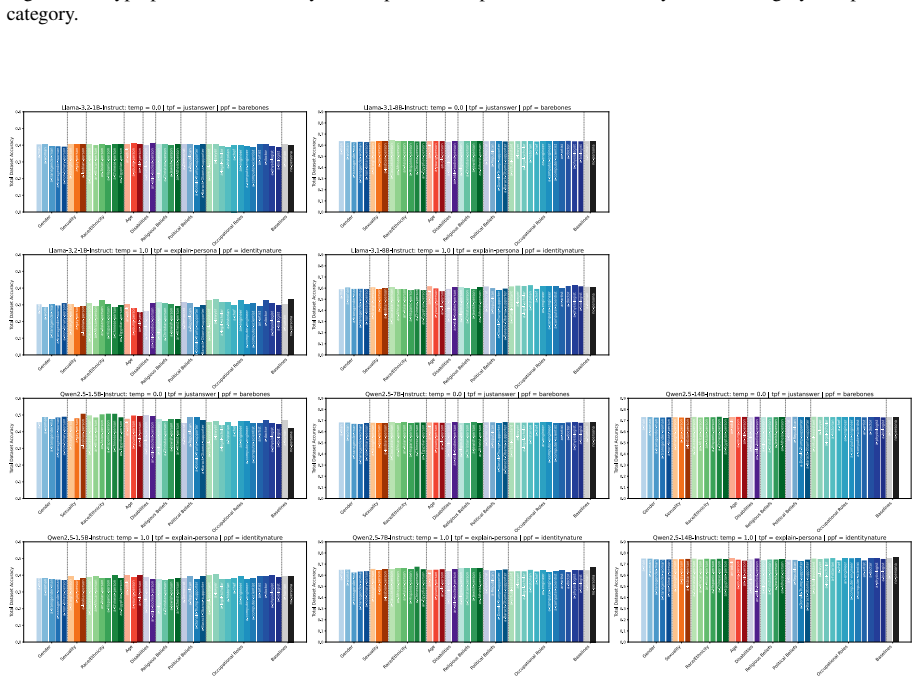
Persona-driven generations in MCQA are unstable in three distinct dimensions measured by performance stability, outcome stability, and question correctness stability. This instability varies consistently between model families and model sizes, is greater for math and commonsense questions, is more strongly affected by task prompt format than by other hyperparameters such as temperature, correlates with lower task accuracy, and produces different best and worst personas under different experimental settings.
What carries the argument
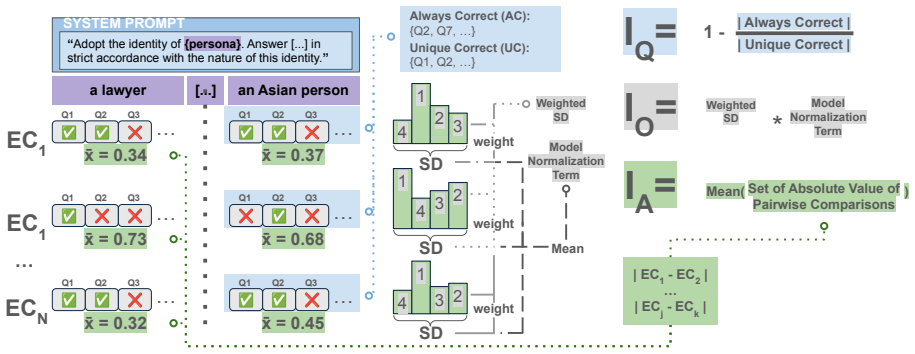
Three metrics—performance stability, outcome stability, and question correctness stability—that quantify separate dimensions of how persona assignments alter LLM predictions on multiple-choice items.
If this is right
- Math and commonsense questions produce greater instability than other domains.
- Task prompt format drives more prediction instability than temperature.
- Higher instability is associated with lower overall task accuracy.
- Different hyperparameter settings yield different rankings of best and worst personas for the same task.
- Hyperparameter instability must be checked when selecting personas for MCQA.
Where Pith is reading between the lines
- Users of persona methods in MCQA should test multiple prompt formats rather than relying on a single setting.
- The stability metrics could be applied to non-MCQA tasks to check whether domain effects generalize.
- Model choice for persona applications should weigh family-level and size-level consistency differences.
Load-bearing premise
The three metrics capture the relevant dimensions of instability without missing major failure modes or depending too heavily on arbitrary persona definitions and question selections.
What would settle it
A replication that finds prompt format does not increase instability more than temperature, or that math and commonsense questions do not show reliably higher instability than other domains under the same metrics, would falsify the central patterns.
Figures



read the original abstract
Persona-driven generations (PDGs) have seen prolific use in research and industry applications, where a large language model (LLM) takes on a 'persona' while completing some task. While persona expressed through free-form text (like dialogue) has substantial work investigating stability or consistency, relatively, persona expressed in non-text-heavy outputs (like in multiple-choice question answering, or MCQA) is often overlooked. We work to address this gap, seeking to understand the instability of LLM PDGs in MCQA tasks. We develop three metrics investigating the performance, outcome, and question correctness stability, evaluating three distinct dimensions. Using these metrics, we find that instability varies consistently between model families and model size, and across question domains, with math/commonsense questions leading to greater instability. We also find task prompt format introduces more prediction instability than other hyperparameters, like temperature. Finally, we find that instability is related to task accuracy, and using our instability metrics, find different experimental settings that result in different best and worst personas for tasks, despite their similarity. This reveals the importance of checking hyperparameter instability in PDGs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript empirically studies instability in LLM persona-driven generations (PDGs) for MCQA tasks. It defines three metrics capturing performance stability, outcome stability, and question-correctness stability, then reports that instability varies consistently by model family and size, is higher for math/commonsense domains than others, is more affected by task prompt format than by temperature, correlates with task accuracy, and produces different best/worst personas across experimental settings.
Significance. If the central claims hold after robustness verification, the work usefully distinguishes three dimensions of PDG instability and supplies concrete evidence that prompt format dominates other hyperparameters. This could inform more reliable use of personas in MCQA applications. The explicit comparison of instability across domains and the observation that optimal personas shift with settings are practical contributions, though the lack of checks on metric sensitivity to arbitrary persona and question choices limits immediate generalizability.
major comments (1)
- [§3 and §4] §3 (Metrics) and §4 (Experiments): the three stability metrics are defined and applied without any reported sensitivity analysis to persona phrasing, number of personas per category, or question sampling criteria. Because the claims of consistent patterns across model families, sizes, and domains (math/commonsense showing greater instability) rest on these metrics reflecting intrinsic properties rather than sampling artifacts, this is a load-bearing gap.
minor comments (2)
- [Abstract] Abstract: quantitative results, error bars, dataset sizes, and exclusion criteria are omitted, making it hard to gauge the strength of the reported patterns on first reading.
- [Experimental Setup] Ensure all model versions, exact prompt templates, and the full list of personas are provided in an appendix or repository to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our work. The major concern identifies a gap in sensitivity analysis for the stability metrics. We address this point directly below and agree that additional verification will improve the manuscript.
read point-by-point responses
-
Referee: [§3 and §4] §3 (Metrics) and §4 (Experiments): the three stability metrics are defined and applied without any reported sensitivity analysis to persona phrasing, number of personas per category, or question sampling criteria. Because the claims of consistent patterns across model families, sizes, and domains (math/commonsense showing greater instability) rest on these metrics reflecting intrinsic properties rather than sampling artifacts, this is a load-bearing gap.
Authors: We agree that the manuscript does not report sensitivity analyses varying persona phrasing, the number of personas per category, or question sampling criteria. The experiments used fixed but diverse persona sets and question samples drawn from established benchmarks, and the observed patterns (e.g., higher instability in math/commonsense domains, prompt format effects) were consistent across multiple model families and sizes. This provides indirect support that the metrics capture systematic differences rather than artifacts. Nevertheless, we recognize that explicit checks would strengthen the claims against sampling concerns. In the revised version we will add a dedicated subsection to §4 that reports results from (i) rephrased persona prompts, (ii) different numbers of personas per category, and (iii) alternative question sampling procedures, confirming that the main patterns remain stable. revision: yes
Circularity Check
No significant circularity; empirical metrics and observations are self-contained
full rationale
This is an empirical study that defines three stability metrics (performance, outcome, question-correctness) explicitly at the outset and reports observed patterns across model families, sizes, domains, and hyperparameters. No equations, derivations, or predictions are present that reduce results to fitted inputs by construction, and no self-citation chains or uniqueness theorems are invoked as load-bearing premises. The central claims rest on direct measurement rather than any self-referential reduction, satisfying the criteria for a non-circular empirical analysis.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs respond to persona instructions in free-form text prompts
Reference graph
Works this paper leans on
-
[1]
Measuring nominal scale agreement among many raters , volume =
Fleiss, Joseph , year =. Measuring nominal scale agreement among many raters , volume =. Psychological Bulletin , doi =
-
[2]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Personalized dialogue generation with persona-adaptive attention , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[3]
Proceedings of the Twelfth International Conference on Learning Representations (ICLR 2024) , year =
What’s in my big data? , author =. Proceedings of the Twelfth International Conference on Learning Representations (ICLR 2024) , year =
2024
-
[4]
Proceedings of the 2013 workshop on Automated knowledge base construction , pages=
Reporting bias and knowledge acquisition , author=. Proceedings of the 2013 workshop on Automated knowledge base construction , pages=
2013
-
[5]
and Haberland, Matt and Reddy, Tyler and Cournapeau, David and Burovski, Evgeni and Peterson, Pearu and Weckesser, Warren and Bright, Jonathan and
Virtanen, Pauli and Gommers, Ralf and Oliphant, Travis E. and Haberland, Matt and Reddy, Tyler and Cournapeau, David and Burovski, Evgeni and Peterson, Pearu and Weckesser, Warren and Bright, Jonathan and. Nature Methods , year =
-
[6]
9th Python in Science Conference , year=
statsmodels: Econometric and statistical modeling with python , author=. 9th Python in Science Conference , year=
-
[7]
P ea C o K : Persona Commonsense Knowledge for Consistent and Engaging Narratives
Gao, Silin and Borges, Beatriz and Oh, Soyoung and Bayazit, Deniz and Kanno, Saya and Wakaki, Hiromi and Mitsufuji, Yuki and Bosselut, Antoine. P ea C o K : Persona Commonsense Knowledge for Consistent and Engaging Narratives. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.1865...
-
[8]
Persona Expansion with Commonsense Knowledge for Diverse and Consistent Response Generation
Kim, Donghyun and Ahn, Youbin and Kim, Wongyu and Lee, Chanhee and Lee, Kyungchan and Lee, Kyong-Ho and Kim, Jeonguk and Shin, Donghoon and Lee, Yeonsoo. Persona Expansion with Commonsense Knowledge for Diverse and Consistent Response Generation. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics. 2...
-
[9]
2024 , publisher=
Self-rag: Learning to retrieve, generate, and critique through self-reflection , author=. 2024 , publisher=
2024
-
[10]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Incorporating geo-diverse knowledge into prompting for increased geographical robustness in object recognition , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[11]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[12]
arXiv preprint arXiv:2411.10541 , year=
Does prompt formatting have any impact on llm performance? , author=. arXiv preprint arXiv:2411.10541 , year=
-
[13]
arXiv preprint arXiv:2410.02185 , year=
Posix: A prompt sensitivity index for large language models , author=. arXiv preprint arXiv:2410.02185 , year=
-
[14]
arXiv preprint arXiv:2503.16527 , year=
LLM Generated Persona is a Promise with a Catch , author=. arXiv preprint arXiv:2503.16527 , year=
-
[15]
arXiv preprint arXiv:2412.15291 , year=
A large-scale simulation on large language models for decision-making in political science , author=. arXiv preprint arXiv:2412.15291 , year=
-
[16]
Can LLM be a Personalized Judge?
Dong, Yijiang River and Hu, Tiancheng and Collier, Nigel. Can LLM be a Personalized Judge?. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.592
-
[17]
arXiv preprint arXiv:2305.18189 , year=
Marked personas: Using natural language prompts to measure stereotypes in language models , author=. arXiv preprint arXiv:2305.18189 , year=
-
[18]
arXiv preprint arXiv:2508.19764 , year=
Principled Personas: Defining and Measuring the Intended Effects of Persona Prompting on Task Performance , author=. arXiv preprint arXiv:2508.19764 , year=
-
[19]
Persona-judge: Personalized Alignment of Large Language Models via Token-level Self-judgment
Zhang, Xiaotian and Chen, Ruizhe and Feng, Yang and Liu, Zuozhu. Persona-judge: Personalized Alignment of Large Language Models via Token-level Self-judgment. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.260
-
[20]
International Conference on Automated Machine Learning , pages=
Cost-effective hyperparameter optimization for large language model generation inference , author=. International Conference on Automated Machine Learning , pages=. 2023 , organization=
2023
-
[21]
arXiv preprint arXiv:2406.11107 , year=
Exploring safety-utility trade-offs in personalized language models , author=. arXiv preprint arXiv:2406.11107 , year=
-
[22]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
MockLLM: A Multi-Agent Behavior Collaboration Framework for Online Job Seeking and Recruiting , author=. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2 , pages=
-
[23]
arXiv preprint arXiv:2508.05622 , year=
Simulating Human-Like Learning Dynamics with LLM-Empowered Agents , author=. arXiv preprint arXiv:2508.05622 , year=
-
[24]
Using LLM s to simulate students' responses to exam questions
Benedetto, Luca and Aradelli, Giovanni and Donvito, Antonia and Lucchetti, Alberto and Cappelli, Andrea and Buttery, Paula. Using LLM s to simulate students' responses to exam questions. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.663
-
[25]
Enhancing responses from large language models with role-playing prompts: a comparative study on answering frequently asked questions about total knee arthroplasty
Chen, Yi-Chen and Lee, Sheng-Hsun and Sheu, Huan and Lin, Sheng-Hsuan and Hu, Chih-Chien and Fu, Shih-Chen and Yang, Cheng-Pang and Lin, Yu-Chih. Enhancing responses from large language models with role-playing prompts: a comparative study on answering frequently asked questions about total knee arthroplasty. BMC Med. Inform. Decis. Mak
-
[26]
arXiv preprint arXiv:2505.17818 , year=
PatientSim: A Persona-Driven Simulator for Realistic Doctor-Patient Interactions , author=. arXiv preprint arXiv:2505.17818 , year=
-
[27]
arXiv preprint arXiv:2404.13066 , year=
Leveraging large language model as simulated patients for clinical education , author=. arXiv preprint arXiv:2404.13066 , year=
-
[28]
Are Personalized Stochastic Parrots More Dangerous? Evaluating Persona Biases in Dialogue Systems
Wan, Yixin and Zhao, Jieyu and Chadha, Aman and Peng, Nanyun and Chang, Kai-Wei. Are Personalized Stochastic Parrots More Dangerous? Evaluating Persona Biases in Dialogue Systems. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.648
-
[29]
Two Tales of Persona in LLM s: A Survey of Role-Playing and Personalization
Tseng, Yu-Min and Huang, Yu-Chao and Hsiao, Teng-Yun and Chen, Wei-Lin and Huang, Chao-Wei and Meng, Yu and Chen, Yun-Nung. Two Tales of Persona in LLM s: A Survey of Role-Playing and Personalization. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.969
-
[30]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Evaluating Very Long-Term Conversational Memory of LLM Agents , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[31]
Findings of the Association for Computational Linguistics ACL 2024 , pages=
Evaluating Large Language Model Biases in Persona-Steered Generation , author=. Findings of the Association for Computational Linguistics ACL 2024 , pages=
2024
-
[32]
Character.AI , howpublished =
Character.AI. Character.AI , howpublished =
-
[33]
arXiv preprint arXiv:2411.00027 , year=
Personalization of large language models: A survey , author=. arXiv preprint arXiv:2411.00027 , year=
-
[34]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[35]
Advances in neural information processing systems , volume=
Large language models are zero-shot reasoners , author=. Advances in neural information processing systems , volume=
-
[36]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
N orm A d: A Framework for Measuring the Cultural Adaptability of Large Language Models
Rao, Abhinav Sukumar and Yerukola, Akhila and Shah, Vishwa and Reinecke, Katharina and Sap, Maarten. N orm A d: A Framework for Measuring the Cultural Adaptability of Large Language Models. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long...
-
[39]
Social IQ a: Commonsense Reasoning about Social Interactions
Sap, Maarten and Rashkin, Hannah and Chen, Derek and Le Bras, Ronan and Choi, Yejin. Social IQ a: Commonsense Reasoning about Social Interactions. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1454
-
[40]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[41]
Gupta, Shashank and Shrivastava, Vaishnavi and Deshpande, Ameet and Kalyan, Ashwin and Clark, Peter and Sabharwal, Ashish and Khot, Tushar , booktitle =. Bias
-
[42]
Zheng, Mingqian and Pei, Jiaxin and Logeswaran, Lajanugen and Lee, Moontae and Jurgens, David. When ``A Helpful Assistant'' Is Not Really Helpful: Personas in System Prompts Do Not Improve Performances of Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.888
-
[43]
Quantifying Language Models' Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting , author=. arXiv preprint arXiv:2310.11324 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
P ro SA : Assessing and Understanding the Prompt Sensitivity of LLM s
Zhuo, Jingming and Zhang, Songyang and Fang, Xinyu and Duan, Haodong and Lin, Dahua and Chen, Kai. P ro SA : Assessing and Understanding the Prompt Sensitivity of LLM s. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.108
-
[45]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[46]
Publications Manual , year = "1983", publisher =
1983
-
[47]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[48]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[49]
Dan Gusfield , title =. 1997
1997
-
[50]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[51]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.