Slope-Guided Mamba and Angular-Refined Transformer for Light Field Super-Resolution
Pith reviewed 2026-07-02 13:42 UTC · model grok-4.3
The pith
SMART combines slope-guided Mamba and angular-refined Transformer to fix decoupled spatial-angular modeling and scan-geometry mismatches in light field super-resolution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
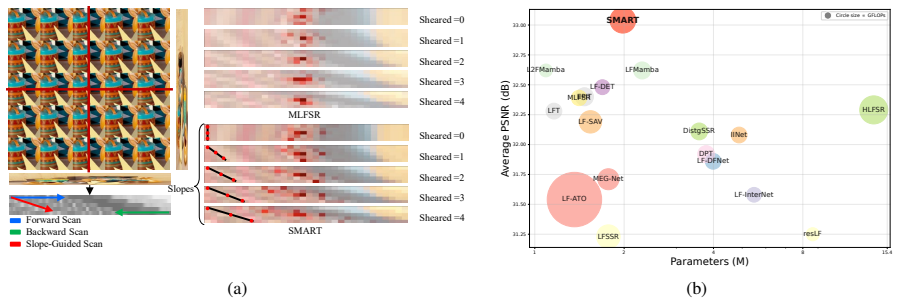
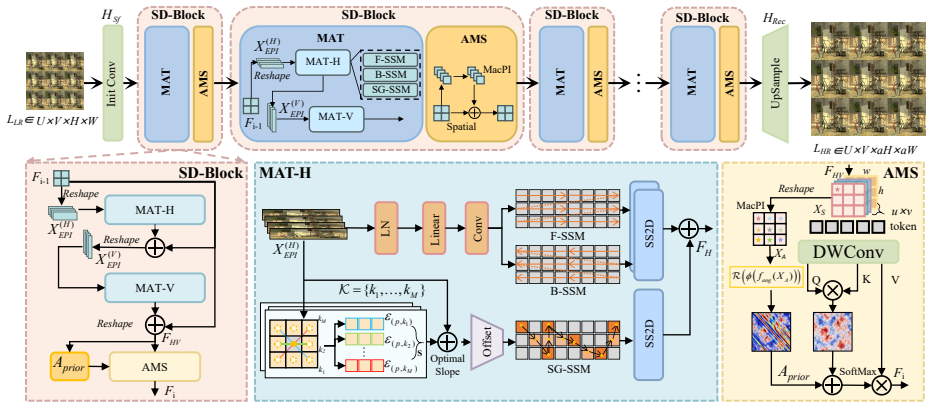
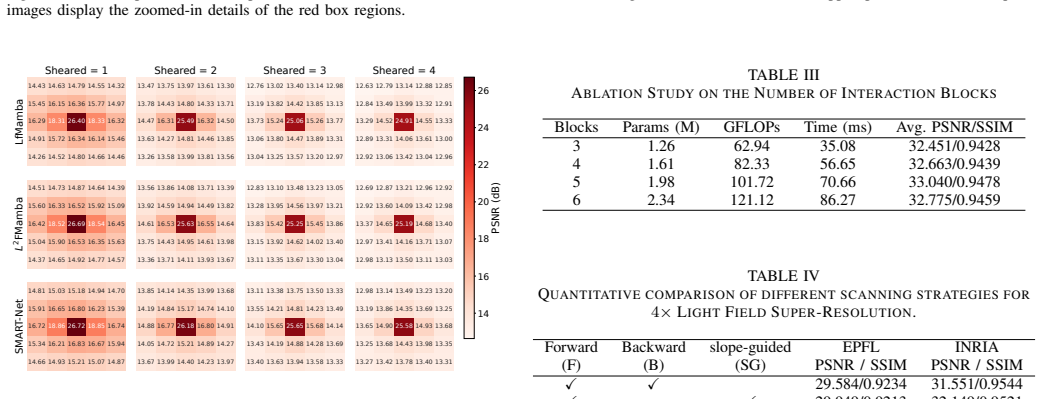
SMART integrates a Slope-Guided Mamba and an Angular-Refined Transformer. An angular-modulated spatial module incorporates angular priors to strengthen cross-dimensional correlation, while a manifold-aligned trajectory module aligns sequence modeling with epipolar geometry. Together they overcome the decoupling of dimensions and the mismatch between rigid scans and ray structure, producing state-of-the-art results on five benchmarks with a 0.42 dB PSNR gain and visibly fewer artifacts.
What carries the argument
The angular-modulated spatial module and manifold-aligned trajectory module, which add angular priors to spatial processing and redirect sequence paths to match epipolar structures for consistent aggregation.
If this is right
- Early incorporation of angular priors enables consistent spatial-angular feature interaction from the start of processing.
- Sequence modeling that follows epipolar trajectories aggregates features without geometry conflicts.
- The combined network exceeds prior methods by 0.42 dB PSNR across five standard light-field benchmarks.
- Output images exhibit visibly fewer artifacts than those from decoupled or scan-mismatched baselines.
Where Pith is reading between the lines
- The same angular-prior and trajectory-alignment ideas might transfer to other ray-based or multi-view tasks such as light-field depth estimation.
- One could test whether the modules remain effective when the input light fields come from different camera arrays or real-world capture conditions rather than the current benchmarks.
- Extending the hybrid design to video or volumetric data could reveal whether the geometry-alignment principle scales beyond static 4D light fields.
Load-bearing premise
The two new modules actually produce geometrically consistent features across dimensions without creating fresh mismatches or overfitting to the test benchmarks.
What would settle it
If visual inspection or quantitative checks of the super-resolved outputs still reveal broken epipolar lines or angular inconsistencies on the same five benchmarks, the claim that the modules bridge the gaps would be refuted.
Figures

read the original abstract
Light Field Super-Resolution (LFSR) necessitates accurate modeling of spatial-angular correlations while preserving intrinsic 4D ray coherence. However, maintaining such high-dimensional consistency remains challenging, primarily due to two inherent limitations in prevailing modeling paradigms. First, spatial and angular dimensions are often modeled in a decoupled manner, restricting early cross-dimensional interaction and leading to geometric inconsistencies. Moreover, although continuous sequence modeling paradigms show promise in representing epipolar structures, their rigid scanning mechanisms fundamentally conflict with epipolar geometry, limiting geometry-aware feature aggregation. To address these challenges, we propose a hybrid light field super-resolution network, termed SMART, which integrates a Slope-Guided Mamba and an Angular-Refined Transformer to effectively overcome these limitations. Specifically, we introduce an angular-modulated spatial module to bridge the decoupling gap, incorporating angular priors to strengthen spatial-angular correlation modeling. To mitigate the scan-geometry mismatch, we propose a manifold-aligned trajectory module that enables geometry-consistent sequence modeling along epipolar structures. Experiments on five benchmarks demonstrate that SMART achieves state-of-the-art performance, surpassing previous methods by 0.42 dB (PSNR) with significantly reduced artifacts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SMART, a hybrid network for light field super-resolution that combines a Slope-Guided Mamba with an Angular-Refined Transformer. It introduces an angular-modulated spatial module that incorporates angular priors to address decoupled spatial-angular modeling, and a manifold-aligned trajectory module that aligns sequence modeling with epipolar geometry to resolve scan-geometry mismatch. Experiments on five benchmarks are reported to achieve state-of-the-art performance, with a 0.42 dB PSNR gain over prior methods and visibly reduced artifacts.
Significance. If the performance gains can be shown to arise specifically from improved 4D ray coherence rather than model capacity or training choices, the hybrid Mamba-Transformer design with explicit angular and manifold modules would represent a meaningful step toward geometry-aware light field modeling. The approach directly targets two recurring limitations in existing LFSR pipelines and could influence subsequent work on epipolar-consistent sequence modeling.
major comments (2)
- [Experiments / Results] The central claim that the angular-modulated spatial module and manifold-aligned trajectory module produce geometrically consistent 4D features (thereby explaining the 0.42 dB gain) rests on benchmark PSNR alone. No ablation isolating the geometric-consistency contribution, no epipolar-line consistency metric, and no comparison against capacity-matched baselines are referenced, leaving open the possibility that gains arise from other factors.
- [Method / Manifold-aligned trajectory module] The abstract states that the manifold-aligned trajectory module mitigates scan-geometry mismatch, yet the manuscript provides no quantitative verification (e.g., trajectory alignment error or ray-coherence score) that the learned trajectories actually follow epipolar lines more closely than standard Mamba scanning.
minor comments (1)
- [Abstract / Introduction] The abstract and method descriptions use several compound terms ("slope-guided," "angular-modulated," "manifold-aligned") without an early figure or diagram that visually contrasts the proposed modules against the two limitations they claim to solve.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions we will make to strengthen the evidence for the geometric contributions of our modules.
read point-by-point responses
-
Referee: [Experiments / Results] The central claim that the angular-modulated spatial module and manifold-aligned trajectory module produce geometrically consistent 4D features (thereby explaining the 0.42 dB gain) rests on benchmark PSNR alone. No ablation isolating the geometric-consistency contribution, no epipolar-line consistency metric, and no comparison against capacity-matched baselines are referenced, leaving open the possibility that gains arise from other factors.
Authors: We agree that the current results do not fully isolate whether the observed gains stem specifically from improved 4D ray coherence. In the revised manuscript we will add module-level ablations (removing or disabling the angular-modulated spatial module and the manifold-aligned trajectory module individually) and will report performance against capacity-matched baselines obtained by scaling the parameter counts of the strongest prior methods. We will also expand the epipolar-plane-image visualizations to provide qualitative support for geometric consistency. A new quantitative epipolar-line consistency metric is not added, as PSNR on standard LFSR benchmarks remains the accepted primary measure in the field. revision: partial
-
Referee: [Method / Manifold-aligned trajectory module] The abstract states that the manifold-aligned trajectory module mitigates scan-geometry mismatch, yet the manuscript provides no quantitative verification (e.g., trajectory alignment error or ray-coherence score) that the learned trajectories actually follow epipolar lines more closely than standard Mamba scanning.
Authors: We acknowledge the absence of direct quantitative verification. In the revised version we will introduce a ray-coherence score, computed as the average deviation of the learned scan trajectories from ground-truth epipolar lines, and will report this score for both the manifold-aligned module and standard Mamba scanning across the five benchmarks. revision: yes
Circularity Check
No circularity: empirical architecture proposal with benchmark validation
full rationale
The paper proposes a hybrid neural architecture (SMART) consisting of Slope-Guided Mamba and Angular-Refined Transformer modules to address spatial-angular decoupling and scan-geometry mismatch in light field super-resolution. All central claims rest on experimental PSNR/artifact results across five external benchmarks rather than any mathematical derivation, fitted-parameter prediction, or self-citation chain. No equations reduce a claimed output to an input by construction, and the performance delta is presented as an observed outcome, not a quantity defined inside the model. This is a standard empirical ML paper with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Detail- preserving transformer for light field image super-resolution,
Shunzhou Wang, Tianfei Zhou, Yao Lu, and Huijun Di, “Detail- preserving transformer for light field image super-resolution,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2022
2022
-
[2]
Learning non-local spatial-angular correlation for light field image super-resolution,
Zhengyu Liang, Yingqian Wang, Longguang Wang, Jungang Yang, Shilin Zhou, and Yulan Guo, “Learning non-local spatial-angular correlation for light field image super-resolution,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2023, pp. 12376–12386
2023
-
[3]
Rethinking the upsampling process in light field super- resolution with spatial-epipolar implicit image function,
Ruixuan Cong, Yu Wang, Mingyuan Zhao, Da Yang, Rongshan Chen, and Hao Sheng, “Rethinking the upsampling process in light field super- resolution with spatial-epipolar implicit image function,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025
2025
-
[4]
Disentangling light fields for super- resolution and disparity estimation,
Yingqian Wang, Longguang Wang, Gaochang Wu, Jungang Yang, Wei An, Jingyi Yu, and Yulan Guo, “Disentangling light fields for super- resolution and disparity estimation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022
2022
-
[5]
Light field image super-resolution with transformers,
Zhengyu Liang, Yingqian Wang, Longguang Wang, Jungang Yang, and Shilin Zhou, “Light field image super-resolution with transformers,” IEEE Signal Processing Letters, 2022
2022
-
[6]
VMamba: Visual State Space Model
Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, and Yunfan Liu, “Vmamba: Visual state space model,”arXiv preprint arXiv:2401.10166, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Mamba-based light field super-resolution with efficient subspace scanning,
Ruisheng Gao, Zeyu Xiao, and Zhiwei Xiong, “Mamba-based light field super-resolution with efficient subspace scanning,” inProceedings of the Asian Conference on Computer Vision, December 2024, pp. 531–547
2024
-
[8]
Lfmamba: Light field image super-resolution with state space model,
Yao Lu, Shunzhou Wang, Ziqi Wang, Peiqi Xia, Tianfei Zhou, et al., “Lfmamba: Light field image super-resolution with state space model,” arXiv preprint arXiv:2406.12463, 2024
-
[9]
L 2 fmamba: Lightweight light field image super-resolution with state space model,
Zeqiang Wei, Kai Jin, Zeyi Hou, Kuan Song, and Xiuzhuang Zhou, “L 2 fmamba: Lightweight light field image super-resolution with state space model,”IEEE Transactions on Computational Imaging, 2025
2025
-
[10]
Evaluation of performance of vdsr super resolution on real and synthetic images,
D Vint, G Di Caterina, JJ Soraghan, RA Lamb, and D Humphreys, “Evaluation of performance of vdsr super resolution on real and synthetic images,” in2019 Sensor Signal Processing for Defence Conference (SSPD). IEEE, 2019, pp. 1–5
2019
-
[11]
Enhanced deep residual networks for single image super- resolution,
Bee Lim, Sanghyun Son, Heewon Kim, Seungjun Nah, and Kyoung Mu Lee, “Enhanced deep residual networks for single image super- resolution,” inThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, July 2017
2017
-
[12]
Image super-resolution using very deep residual channel attention networks,
Yulun Zhang, Kunpeng Li, Kai Li, Lichen Wang, Bineng Zhong, and Yun Fu, “Image super-resolution using very deep residual channel attention networks,” inECCV, 2018
2018
-
[13]
Residual networks for light field image super-resolution,
Shuo Zhang, Youfang Lin, and Hao Sheng, “Residual networks for light field image super-resolution,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 11046–11055
2019
-
[14]
Light field spatial super-resolution using deep efficient spatial-angular separable convolution,
Henry Wing Fung Yeung, Junhui Hou, Xiaoming Chen, Jie Chen, Zhibo Chen, and Yuk Ying Chung, “Light field spatial super-resolution using deep efficient spatial-angular separable convolution,”IEEE Transactions on Image Processing, vol. 28, no. 5, pp. 2319–2330, 2018
2018
-
[15]
Light field spa- tial super-resolution via deep combinatorial geometry embedding and structural consistency regularization,
Jing Jin, Junhui Hou, Jie Chen, and Sam Kwong, “Light field spa- tial super-resolution via deep combinatorial geometry embedding and structural consistency regularization,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 2260– 2269
2020
-
[16]
Spatial-angular interaction for light field image super- resolution,
Yingqian Wang, Longguang Wang, Jungang Yang, Wei An, Jingyi Yu, and Yulan Guo, “Spatial-angular interaction for light field image super- resolution,” inEuropean Conference on Computer Vision. Springer, 2020, pp. 290–308
2020
-
[17]
Light field image super-resolution using deformable convolution,
Yingqian Wang, Jungang Yang, Longguang Wang, Xinyi Ying, Tianhao Wu, Wei An, and Yulan Guo, “Light field image super-resolution using deformable convolution,”IEEE Transactions on Image Processing, vol. 30, pp. 1057–1071, 2021
2021
-
[18]
End-to-end light field spatial super-resolution network using multiple epipolar geometry,
Shuo Zhang, Song Chang, and Youfang Lin, “End-to-end light field spatial super-resolution network using multiple epipolar geometry,” IEEE Transactions on Image Processing, vol. 30, pp. 5956–5968, 2021
2021
-
[19]
Intra-inter view interaction network for light field image super-resolution,
Gaosheng Liu, Huanjing Yue, Jiamin Wu, and Jingyu Yang, “Intra-inter view interaction network for light field image super-resolution,”IEEE Transactions on Multimedia, 2021
2021
-
[20]
Spatial-angular versatile convolution for light field reconstruction,
Zhen Cheng, Yutong Liu, and Zhiwei Xiong, “Spatial-angular versatile convolution for light field reconstruction,”IEEE Transactions on Computational Imaging, vol. 8, pp. 1131–1144, 2022
2022
-
[21]
Light field image super-resolution network via joint spatial-angular and epipolar information,
V . V . Duong, T. H. Nguyen, J. Yim, and B. Jeon, “Light field image super-resolution network via joint spatial-angular and epipolar information,”IEEE Trans. Compuational Imaging, 2023
2023
-
[22]
Exploiting spatial and angular correlations with deep efficient transformers for light field image super-resolution,
Ruixuan Cong, Hao Sheng, Da Yang, Zhenglong Cui, and Rongshan Chen, “Exploiting spatial and angular correlations with deep efficient transformers for light field image super-resolution,”IEEE Transactions on Multimedia, 2023
2023
-
[23]
New light field image dataset,
Martin Rerabek and Touradj Ebrahimi, “New light field image dataset,” in8th international conference on quality of multimedia experience, 2016
2016
-
[24]
Light field compression with homography-based low-rank approximation,
Xiaoran Jiang, Mika ¨el Le Pendu, Reuben A Farrugia, and Christine Guillemot, “Light field compression with homography-based low-rank approximation,”IEEE Journal of Selected Topics in Signal Processing, vol. 11, no. 7, pp. 1132–1145, 2017
2017
-
[25]
Light field inpainting propagation via low rank matrix completion,
Mikael Le Pendu, Xiaoran Jiang, and Christine Guillemot, “Light field inpainting propagation via low rank matrix completion,”IEEE Transactions on Image Processing, vol. 27, no. 4, pp. 1981–1993, 2018
1981
-
[26]
A dataset and evaluation methodology for depth estimation on 4d light fields,
Katrin Honauer, Ole Johannsen, Daniel Kondermann, and Bastian Gold- luecke, “A dataset and evaluation methodology for depth estimation on 4d light fields,” inAsian conference on computer vision. Springer, 2016, pp. 19–34
2016
-
[27]
Datasets and benchmarks for densely sampled 4d light fields.,
Sven Wanner, Stephan Meister, and Bastian Goldluecke, “Datasets and benchmarks for densely sampled 4d light fields.,” inVMV, 2013, vol. 13, pp. 225–226
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.