GAIA: Geometry-Adaptive Operator Learning for Forward and Inverse Problems
Pith reviewed 2026-07-02 15:31 UTC · model grok-4.3
The pith
Encoding domain boundaries and fields into tokens lets one operator solve forward, BVP, and inverse PDE problems on arbitrary geometries in a single pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
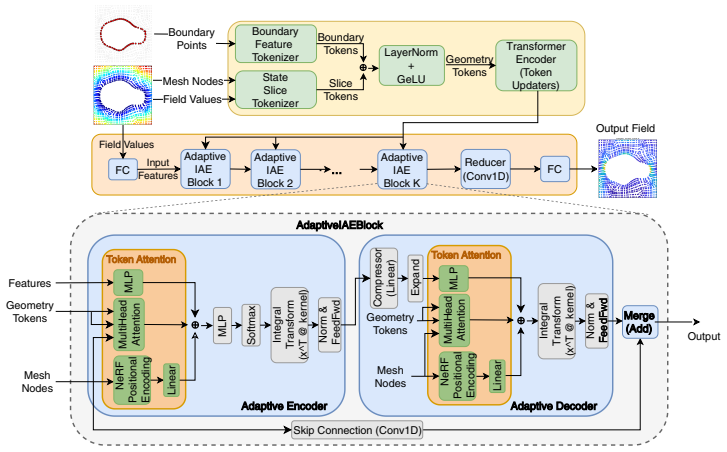
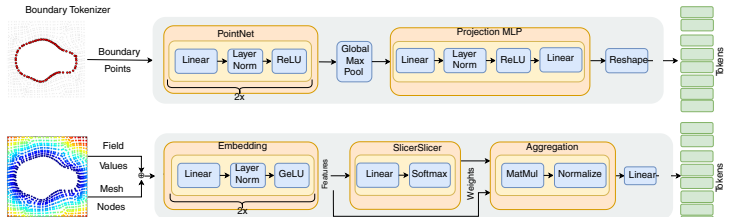
By encoding the domain boundary and the interior field distribution into geometry tokens and conditioning integral transform layers on these tokens via cross-attention, GAIA yields a single architecture for forward (including BVPs) and inverse problems on arbitrary domains in one pass, without retraining, iterative optimization, or graph construction, and sets new state-of-the-art results on every inverse and BVP task.
What carries the argument
Geometry-Adaptive Integral Autoencoder (GAIA) that turns boundary and interior field information into tokens and uses cross-attention to condition integral transform layers for local kernel adaptation.
If this is right
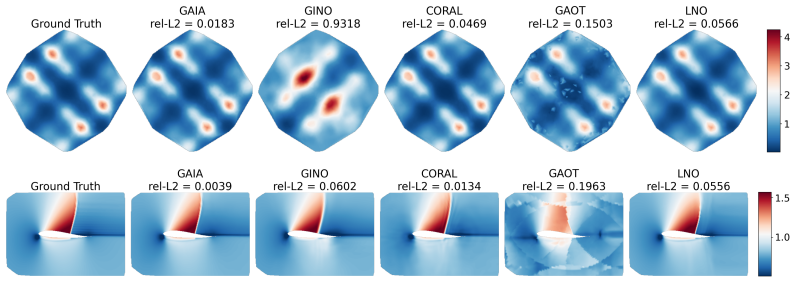
- GAIA reduces median relative L2 error by 64 percent on airfoil flow reconstruction and 27 percent on electrical impedance tomography relative to the next best amortized method.
- The model outperforms all baselines on every shape category of the modified mechanical components benchmark for Poisson BVPs.
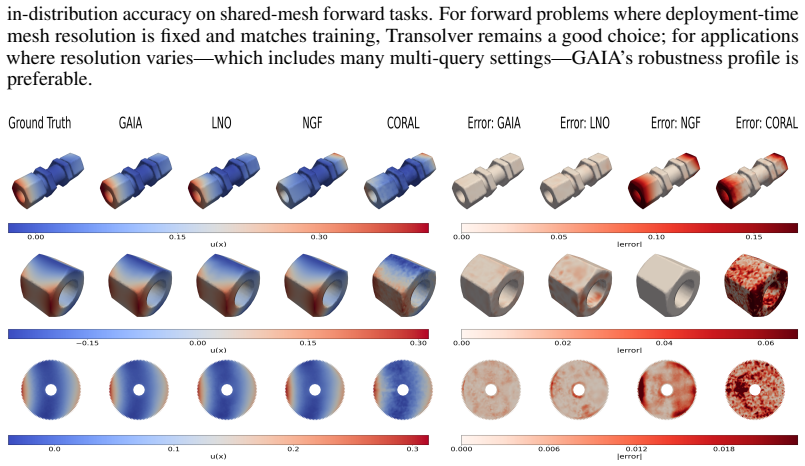
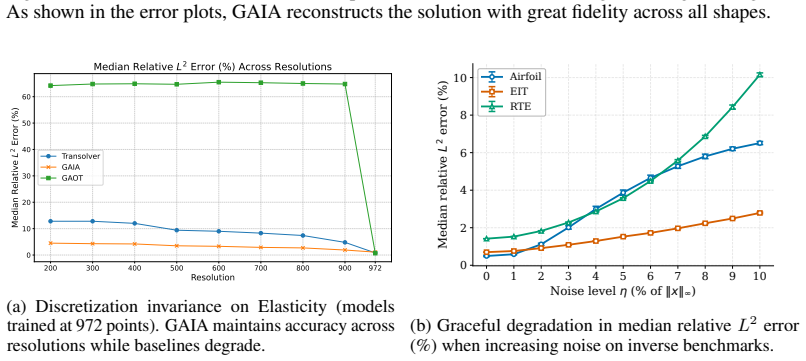
- GAIA maintains stable accuracy across varying point resolutions where transformer-based baselines degrade.
- The architecture solves both 2D and 3D problems without requiring graph construction or per-instance retraining.
Where Pith is reading between the lines
- The token-based conditioning could allow rapid evaluation on families of geometries that differ only locally if the cross-attention mechanism generalizes beyond the training shapes.
- Replacing the integral transform backbone with other kernel approximations might preserve the geometry adaptation while lowering memory cost for very large 3D domains.
- The same encoding strategy might transfer to time-dependent or parametric PDEs if the tokens are extended to carry time or parameter information.
Load-bearing premise
Encoding the domain boundary and interior field distribution into geometry tokens and conditioning integral transform layers on these tokens via cross-attention is sufficient to adapt the kernel locally to geometric features for arbitrary domains and both forward and inverse problem types.
What would settle it
GAIA fails to reduce median relative L2 error below the next-best amortized method on a new inverse problem benchmark with an unseen arbitrary geometry, or its accuracy drops sharply on a BVP whose boundary conditions lie outside the token-encoded training distribution.
Figures



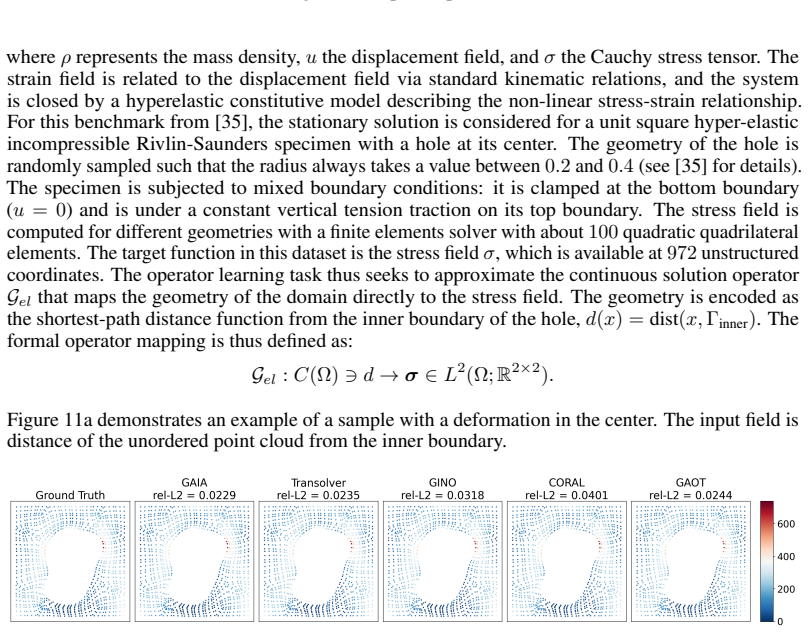

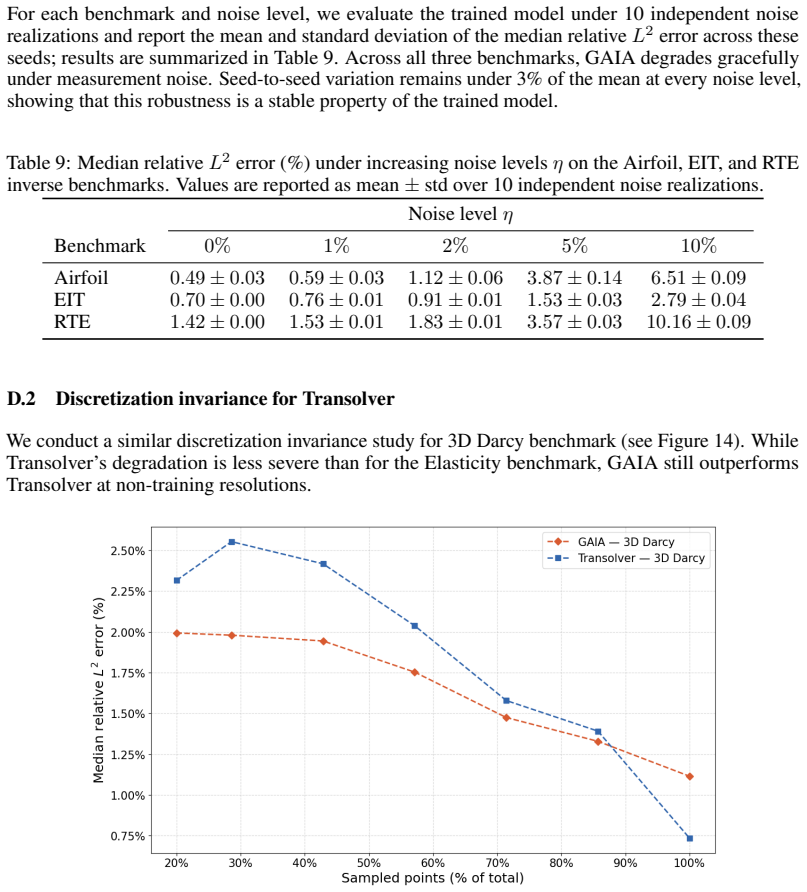
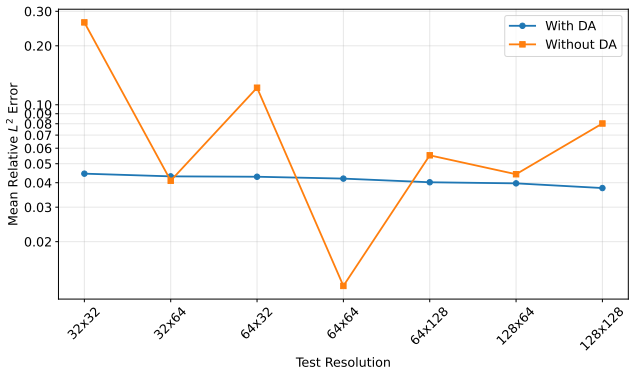
read the original abstract
Operator learning for partial differential equations (PDEs) on arbitrary geometries builds fast neural surrogates for large-scale simulation. Although recent geometry-adaptive neural operators have made substantial progress, they are mainly designed for forward problems in which inputs and outputs share the same spatial domain. This limits their applicability for boundary value problems (BVPs) and inverse problems, where inputs and outputs may live on different domains. We introduce the Geometry-Adaptive Integral Autoencoder (GAIA), an operator learning model that encodes the domain boundary and the interior field distribution into geometry tokens, and conditions integral transform layers on these tokens via cross-attention, allowing the kernel to adapt locally to geometric features. This yields a single architecture for forward (including BVPs) and inverse problems on arbitrary domains in one pass, without retraining, iterative optimization, or graph construction. We evaluate GAIA on seven 2D and 3D benchmarks, four of which are new or substantially extended benchmarks for inverse problems and BVP: electrical impedance tomography, optical tomography, 3D Darcy flow on varying geometries, and a modified setting of Poisson BVP on mechanical components benchmark (MCB). GAIA sets new state-of-the-art results on every inverse and BVP task, reducing median relative $L^2$ error by 64% on airfoil flow reconstruction and 27% on EIT relative to the next best amortized method, and outperforming all baselines on every shape category of MCB. On other forward problems, GAIA is competitive with specialized solvers while maintaining stable accuracy across point resolutions on which transformer-based baselines degrade.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GAIA, a Geometry-Adaptive Integral Autoencoder that encodes domain boundary and interior field distribution into geometry tokens and conditions integral transform layers on these tokens via cross-attention. This produces a single architecture claimed to handle forward problems (including BVPs) and inverse problems on arbitrary domains in one pass, without retraining, iterative optimization, or graph construction. The model is evaluated on seven 2D and 3D benchmarks (four new or extended for inverse/BVP tasks: EIT, optical tomography, 3D Darcy on varying geometries, modified Poisson BVP on MCB), reporting new SOTA results on every inverse and BVP task with median relative L² error reductions of 64% on airfoil flow reconstruction and 27% on EIT relative to the next best amortized method, while remaining competitive on other forward problems.
Significance. If the reported empirical gains hold under rigorous controls, the work would be significant for extending geometry-adaptive neural operators beyond same-domain forward problems to unified handling of BVPs and inverse maps on arbitrary geometries. The introduction of new benchmarks for EIT, optical tomography, and modified MCB is a constructive contribution that could facilitate future comparisons in the field.
major comments (2)
- [§4] §4 (Experiments): the manuscript reports SOTA claims and specific error reductions (64% on airfoil, 27% on EIT) but provides no details on data splits, baseline re-implementations, number of runs, error bars, or statistical significance tests; these omissions are load-bearing because the central claim rests entirely on the benchmark comparisons.
- [§3] Method (cross-attention conditioning, §3): no capacity argument or analysis is given showing why cross-attention on geometry tokens suffices for local kernel adaptation when input and output supports are disjoint (BVPs, inverse problems); the claim of handling arbitrary domains without retraining therefore rests solely on the specific benchmark geometries tested.
minor comments (2)
- [Abstract] Abstract and §4: the statement of 'stable accuracy across point resolutions' lacks quantitative tables or figures showing the tested resolutions and direct comparison to transformer baselines that degrade.
- Notation for geometry tokens and integral transform conditioning could be introduced with an explicit diagram or equation reference earlier to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential significance of GAIA for unified operator learning on arbitrary domains. We address the two major comments point by point below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): the manuscript reports SOTA claims and specific error reductions (64% on airfoil, 27% on EIT) but provides no details on data splits, baseline re-implementations, number of runs, error bars, or statistical significance tests; these omissions are load-bearing because the central claim rests entirely on the benchmark comparisons.
Authors: We agree that these experimental details are necessary to rigorously support the reported performance improvements. In the revised version we will expand §4 with a dedicated subsection (and corresponding appendix) that specifies: (i) the exact train/validation/test splits for each of the seven benchmarks, (ii) the re-implementation protocol and hyper-parameter choices for all baselines, (iii) the number of independent random seeds used, (iv) mean ± standard deviation error bars, and (v) results of paired statistical significance tests (e.g., Wilcoxon signed-rank) between GAIA and the next-best amortized method on each task. This addition will make the empirical claims fully reproducible and verifiable. revision: yes
-
Referee: [§3] Method (cross-attention conditioning, §3): no capacity argument or analysis is given showing why cross-attention on geometry tokens suffices for local kernel adaptation when input and output supports are disjoint (BVPs, inverse problems); the claim of handling arbitrary domains without retraining therefore rests solely on the specific benchmark geometries tested.
Authors: We acknowledge that the manuscript does not supply a formal capacity or expressivity argument for the cross-attention mechanism. The design encodes both boundary and interior geometry into tokens that are then used to modulate the integral kernels via cross-attention; this allows each query point in the output domain to attend to geometric features regardless of whether the input and output supports coincide. The four new or extended benchmarks (EIT, optical tomography, 3D Darcy on varying geometries, modified Poisson BVP on MCB) deliberately include disjoint-support settings and diverse shape categories, and GAIA maintains consistent accuracy across them. To strengthen the presentation we will add a short paragraph in §3 that explains, at the level of the attention operation, why the conditioning enables local kernel adaptation on disjoint domains. We view this as a clarification rather than a new theoretical proof; a rigorous capacity analysis remains an interesting direction for future work. revision: partial
Circularity Check
No circularity; claims rest on empirical benchmarks
full rationale
The paper introduces the GAIA architecture for geometry-adaptive operator learning and supports its central claims (single-pass handling of forward/BVP/inverse problems on arbitrary domains, SOTA results) exclusively through empirical evaluation on seven 2D/3D benchmarks. No derivation chain, first-principles prediction, or mathematical reduction is presented that could reduce to fitted parameters, self-definitions, or self-citations by construction. The model description (geometry tokens + cross-attention conditioning of integral transforms) is an architectural choice whose performance is validated externally on held-out test cases, not derived from quantities defined within the paper itself. This is the standard non-circular pattern for empirical ML architecture papers.
Axiom & Free-Parameter Ledger
free parameters (2)
- geometry token dimension
- number of cross-attention layers
axioms (1)
- domain assumption Cross-attention on geometry tokens can produce locally adaptive kernels sufficient for arbitrary geometries and differing input/output domains.
invented entities (1)
-
geometry tokens
no independent evidence
Reference graph
Works this paper leans on
-
[1]
American Mathematical Society, 2024
Roger Temam.Navier–Stokes equations: theory and numerical analysis, volume 343. American Mathematical Society, 2024
2024
-
[2]
Electrical impedance tomography.Inverse problems, 18(6):R99–R136, 2002
Liliana Borcea. Electrical impedance tomography.Inverse problems, 18(6):R99–R136, 2002
2002
-
[3]
Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational physics, 378:686–707, 2019
2019
-
[4]
Regularization by architecture: A deep prior approach for inverse problems.Journal of Mathematical Imaging and Vision, 62(3):456–470, 2020
Sören Dittmer, Tobias Kluth, Peter Maass, and Daniel Otero Baguer. Regularization by architecture: A deep prior approach for inverse problems.Journal of Mathematical Imaging and Vision, 62(3):456–470, 2020
2020
-
[5]
Fourier Neural Operator for Parametric Partial Differential Equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differen- tial equations.arXiv preprint arXiv:2010.08895, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[6]
Lu Lu, Pengzhan Jin, and George Em Karniadakis. DeepONet: Learning nonlinear operators for identifying differential equations based on the universal approximation theorem of operators. arXiv preprint arXiv:1910.03193, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[7]
Shizheng Wen, Arsh Kumbhat, Levi Lingsch, Sepehr Mousavi, Yizhou Zhao, Praveen Chan- drashekar, and Siddhartha Mishra. Geometry aware operator transformer as an efficient and accurate neural surrogate for PDEs on arbitrary domains.arXiv preprint arXiv:2505.18781, 2025
-
[8]
Geometry-informed neural operator for large-scale 3D PDEs.Advances in Neural Information Processing Systems, 36:35836–35854, 2023
Zongyi Li, Nikola Kovachki, Chris Choy, Boyi Li, Jean Kossaifi, Shourya Otta, Moham- mad Amin Nabian, Maximilian Stadler, Christian Hundt, Kamyar Azizzadenesheli, et al. Geometry-informed neural operator for large-scale 3D PDEs.Advances in Neural Information Processing Systems, 36:35836–35854, 2023
2023
-
[9]
Transolver: A Fast Transformer Solver for PDEs on General Geometries
Haixu Wu, Huakun Luo, Haowen Wang, Jianmin Wang, and Mingsheng Long. Transolver: A fast transformer solver for PDEs on general geometries.arXiv preprint arXiv:2402.02366, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Integral autoencoder network for discretization-invariant learning.Journal of Machine Learning Research, 23(286):1–45, 2022
Yong Zheng Ong, Zuowei Shen, and Haizhao Yang. Integral autoencoder network for discretization-invariant learning.Journal of Machine Learning Research, 23(286):1–45, 2022
2022
-
[11]
Operator learning with neural fields: Tackling PDEs on general geometries.Advances in Neural Information Processing Systems, 36:70581–70611, 2023
Louis Serrano, Lise Le Boudec, Armand Kassaï Koupaï, Thomas X Wang, Yuan Yin, Jean-Noël Vittaut, and Patrick Gallinari. Operator learning with neural fields: Tackling PDEs on general geometries.Advances in Neural Information Processing Systems, 36:70581–70611, 2023
2023
-
[12]
Physics-informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
George Em Karniadakis, Ioannis G Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang. Physics-informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
2021
-
[13]
The deep Ritz method: a deep learning-based numerical algorithm for solving variational problems.Communications in Mathematics and Statistics, 6(1):1–12, 2018
Bing Yu et al. The deep Ritz method: a deep learning-based numerical algorithm for solving variational problems.Communications in Mathematics and Statistics, 6(1):1–12, 2018
2018
-
[14]
DGM: A deep learning algorithm for solving partial differential equations.Journal of computational physics, 375:1339–1364, 2018
Justin Sirignano and Konstantinos Spiliopoulos. DGM: A deep learning algorithm for solving partial differential equations.Journal of computational physics, 375:1339–1364, 2018. 11
2018
-
[15]
Gradient-enhanced physics- informed neural networks for forward and inverse PDE problems.Computer Methods in Applied Mechanics and Engineering, 393:114823, 2022
Jeremy Yu, Lu Lu, Xuhui Meng, and George Em Karniadakis. Gradient-enhanced physics- informed neural networks for forward and inverse PDE problems.Computer Methods in Applied Mechanics and Engineering, 393:114823, 2022
2022
-
[16]
Understanding and mitigating gradient flow pathologies in physics-informed neural networks.SIAM Journal on Scientific Computing, 43 (5):A3055–A3081, 2021
Sifan Wang, Yujun Teng, and Paris Perdikaris. Understanding and mitigating gradient flow pathologies in physics-informed neural networks.SIAM Journal on Scientific Computing, 43 (5):A3055–A3081, 2021
2021
-
[17]
Bayesian deep convolutional encoder–decoder networks for surrogate modeling and uncertainty quantification.Journal of Computational Physics, 366: 415–447, 2018
Yinhao Zhu and Nicholas Zabaras. Bayesian deep convolutional encoder–decoder networks for surrogate modeling and uncertainty quantification.Journal of Computational Physics, 366: 415–447, 2018
2018
-
[18]
Prediction of aerodynamic flow fields using convolutional neural networks.Computational Mechanics, 64(2):525–545, 2019
Saakaar Bhatnagar, Yaser Afshar, Shaowu Pan, Karthik Duraisamy, and Shailendra Kaushik. Prediction of aerodynamic flow fields using convolutional neural networks.Computational Mechanics, 64(2):525–545, 2019
2019
-
[19]
Solving ill-posed inverse problems using iterative deep neural networks.Inverse Problems, 33(12):124007, 2017
Jonas Adler and Ozan Öktem. Solving ill-posed inverse problems using iterative deep neural networks.Inverse Problems, 33(12):124007, 2017
2017
-
[20]
Neural operator: Learning maps between function spaces with applications to PDEs.Journal of Machine Learning Research, 24(89):1–97, 2023
Nikola Kovachki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Learning maps between function spaces with applications to PDEs.Journal of Machine Learning Research, 24(89):1–97, 2023
2023
-
[21]
Factorized Fourier neural operators.arXiv preprint arXiv:2111.13802, 2021
Alasdair Tran, Alexander Mathews, Lexing Xie, and Cheng Soon Ong. Factorized Fourier neural operators.arXiv preprint arXiv:2111.13802, 2021
-
[22]
U-NO: U-shaped neural operators.arXiv preprint arXiv:2204.11127, 2022
Md Ashiqur Rahman, Zachary E Ross, and Kamyar Azizzadenesheli. U-NO: U-shaped neural operators.arXiv preprint arXiv:2204.11127, 2022
-
[23]
Jean Kossaifi, Nikola Kovachki, Kamyar Azizzadenesheli, and Anima Anandkumar. Multi-grid tensorized Fourier neural operator for high-resolution PDEs.arXiv preprint arXiv:2310.00120, 2023
-
[24]
Neural Operator: Graph Kernel Network for Partial Differential Equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Graph kernel network for partial differential equations.arXiv preprint arXiv:2003.03485, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[25]
Multipole graph neural operator for parametric partial differential equations.Advances in Neural Information Processing Systems, 33:6755–6766, 2020
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Andrew Stuart, Kaushik Bhattacharya, and Anima Anandkumar. Multipole graph neural operator for parametric partial differential equations.Advances in Neural Information Processing Systems, 33:6755–6766, 2020
2020
-
[26]
Tapas Tripura and Souvik Chakraborty. Wavelet neural operator: a neural operator for parametric partial differential equations.arXiv preprint arXiv:2205.02191, 2022
-
[27]
Learning to accelerate partial differential equations via latent global evolution.Advances in Neural Information Processing Systems, 35: 2240–2253, 2022
Tailin Wu, Takashi Maruyama, and Jure Leskovec. Learning to accelerate partial differential equations via latent global evolution.Advances in Neural Information Processing Systems, 35: 2240–2253, 2022
2022
-
[28]
Uncertainty quantification for forward and inverse problems of PDEs via latent global evolution
Tailin Wu, Willie Neiswanger, Hongtao Zheng, Stefano Ermon, and Jure Leskovec. Uncertainty quantification for forward and inverse problems of PDEs via latent global evolution. In Proceedings of the AAAI conference on artificial intelligence, volume 38, pages 320–328, 2024
2024
-
[29]
Derivative-informed neural operator acceleration of geometric MCMC for infinite-dimensional Bayesian inverse problems
Lianghao Cao, Thomas O’Leary-Roseberry, and Omar Ghattas. Derivative-informed neural operator acceleration of geometric MCMC for infinite-dimensional Bayesian inverse problems. Journal of Machine Learning Research, 26(78):1–68, 2025
2025
-
[30]
Semi-supervised invertible neural operators for Bayesian inverse problems.Computational Mechanics, 72(3): 451–470, 2023
Sebastian Kaltenbach, Paris Perdikaris, and Phaedon-Stelios Koutsourelakis. Semi-supervised invertible neural operators for Bayesian inverse problems.Computational Mechanics, 72(3): 451–470, 2023. 12
2023
-
[31]
On conditional diffusion mod- els for PDE simulations.Advances in Neural Information Processing Systems, 37:23246–23300, 2024
Aliaksandra Shysheya, Cristiana Diaconu, Federico Bergamin, Paris Perdikaris, José M Hernández-Lobato, Richard E Turner, and Emile Mathieu. On conditional diffusion mod- els for PDE simulations.Advances in Neural Information Processing Systems, 37:23246–23300, 2024
2024
-
[32]
Neural inverse operators for solving PDE inverse problems.arXiv preprint arXiv:2301.11167, 2023
Roberto Molinaro, Yunan Yang, Björn Engquist, and Siddhartha Mishra. Neural inverse operators for solving PDE inverse problems.arXiv preprint arXiv:2301.11167, 2023
-
[33]
Da Long, Zhitong Xu, Qiwei Yuan, Yin Yang, and Shandian Zhe. Invertible Fourier neural operators for tackling both forward and inverse problems.arXiv preprint arXiv:2402.11722, 2024
-
[34]
Nicholas H Nelsen and Yunan Yang. Operator learning meets inverse problems: A probabilistic perspective.arXiv preprint arXiv:2508.20207, 2025
-
[35]
Fourier neural operator with learned deformations for PDEs on general geometries.Journal of Machine Learning Research, 24(388):1–26, 2023
Zongyi Li, Daniel Zhengyu Huang, Burigede Liu, and Anima Anandkumar. Fourier neural operator with learned deformations for PDEs on general geometries.Journal of Machine Learning Research, 24(388):1–26, 2023
2023
-
[36]
Sepehr Mousavi, Shizheng Wen, Levi Lingsch, Maximilian Herde, Bogdan Raoni´c, and Sid- dhartha Mishra. RIGNO: A graph-based framework for robust and accurate operator learning for PDEs on arbitrary domains.arXiv preprint arXiv:2501.19205, 2025
-
[37]
Neural fields for rapid aircraft aerodynamics simulations.Scientific Reports, 14 (1):25496, 2024
Giovanni Catalani, Siddhant Agarwal, Xavier Bertrand, Frederic Tost, Michael Bauerheim, and Joseph Morlier. Neural fields for rapid aircraft aerodynamics simulations.Scientific Reports, 14 (1):25496, 2024
2024
-
[38]
Conditional neural field latent diffusion model for generating spatiotemporal turbulence.Nature Communi- cations, 15(1):10416, 2024
Pan Du, Meet Hemant Parikh, Xiantao Fan, Xin-Yang Liu, and Jian-Xun Wang. Conditional neural field latent diffusion model for generating spatiotemporal turbulence.Nature Communi- cations, 15(1):10416, 2024
2024
-
[39]
Latent neural operator for solving forward and inverse PDE problems.Advances in Neural Information Processing Systems, 37:33085–33107, 2024
Tian Wang and Chuang Wang. Latent neural operator for solving forward and inverse PDE problems.Advances in Neural Information Processing Systems, 37:33085–33107, 2024
2024
-
[40]
GNOT: A general neural operator transformer for operator learning
Zhongkai Hao, Zhengyi Wang, Hang Su, Chengyang Ying, Yinpeng Dong, Songming Liu, Ze Cheng, Jian Song, and Jun Zhu. GNOT: A general neural operator transformer for operator learning. InInternational conference on machine learning, pages 12556–12569. PMLR, 2023
2023
-
[41]
Zijie Li, Kazem Meidani, and Amir Barati Farimani. Transformer for partial differential equations’ operator learning.arXiv preprint arXiv:2205.13671, 2022
-
[42]
Improved operator learning by orthogonal attention.arXiv preprint arXiv:2310.12487, 2023
Zipeng Xiao, Zhongkai Hao, Bokai Lin, Zhijie Deng, and Hang Su. Improved operator learning by orthogonal attention.arXiv preprint arXiv:2310.12487, 2023
-
[43]
Seungwoo Yoo, Kyeongmin Yeo, Jisung Hwang, and Minhyuk Sung. Neural Green’s functions. arXiv preprint arXiv:2511.01924, 2025
-
[44]
PointNet: Deep learning on point sets for 3D classification and segmentation
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. PointNet: Deep learning on point sets for 3D classification and segmentation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 652–660, 2017
2017
-
[45]
NeRF: Representing scenes as neural radiance fields for view synthesis
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoor- thi, and Ren Ng. NeRF: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65(1):99–106, 2021
2021
-
[46]
On an inverse boundary value problem.Computational & Applied Mathematics, 25:133–138, 2006
Alberto P Calderón. On an inverse boundary value problem.Computational & Applied Mathematics, 25:133–138, 2006
2006
-
[47]
Solving optical tomography with deep learning.arXiv preprint arXiv:1910.04756, 2019
Yuwei Fan and Lexing Ying. Solving optical tomography with deep learning.arXiv preprint arXiv:1910.04756, 2019. 13
-
[48]
A large-scale annotated mechanical components benchmark for classification and retrieval tasks with deep neural networks
Sangpil Kim, Hyung-gun Chi, Xiao Hu, Qixing Huang, and Karthik Ramani. A large-scale annotated mechanical components benchmark for classification and retrieval tasks with deep neural networks. InEuropean conference on computer vision, pages 175–191. Springer, 2020
2020
-
[49]
Springer Science & Business Media, 2012
Anders Logg, Kent-Andre Mardal, and Garth Wells.Automated solution of differential equations by the finite element method: The FEniCS book, volume 84. Springer Science & Business Media, 2012
2012
-
[50]
Transformers are rnns: Fast autoregressive transformers with linear attention
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. Transformers are rnns: Fast autoregressive transformers with linear attention. InInternational conference on machine learning, pages 5156–5165. PMLR, 2020
2020
-
[51]
EIT reconstruction algorithms: pitfalls, challenges and recent develop- ments.Physiological measurement, 25(1):125, 2004
William RB Lionheart. EIT reconstruction algorithms: pitfalls, challenges and recent develop- ments.Physiological measurement, 25(1):125, 2004
2004
-
[52]
Inverse transport theory of photoacous- tics.Inverse Problems, 26(2):025011, 2010
Guillaume Bal, Alexandre Jollivet, and Vincent Jugnon. Inverse transport theory of photoacous- tics.Inverse Problems, 26(2):025011, 2010
2010
-
[53]
Elsevier, 2014
Gerald Farin.Curves and surfaces for computer-aided geometric design: a practical guide. Elsevier, 2014
2014
-
[54]
Fast tetrahedral meshing in the wild
Yixin Hu, Teseo Schneider, Bolun Wang, Denis Zorin, and Daniele Panozzo. Fast tetrahedral meshing in the wild. 2020
2020
-
[55]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014. A Datasets and Benchmarks Below is a brief summary of the datasets that we use in the paper. A.1 Inverse Problem: Electrical Impedance Tomography Electrical Impedance Tomography (EIT) is an imaging technique that involves solving an inverse pro...
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[56]
3D Poisson BVP[ 43] −∆u=f analytical, u|∂Ω =g(x, y, z)
4096 train / 2048 test samples. 3D Poisson BVP[ 43] −∆u=f analytical, u|∂Ω =g(x, y, z) . Os- cillatory analytical source; randomized poly- nomial Dirichlet BCs. BVP / Forward.3D mechanical parts (MCB): gears, nuts, fittings, screws & bolts. Setting adapted from [43]. 200 shapes/category train, 20 test with 50 boundary conditions per shape. EIT[32]∇ ·(a(x)...
2048
-
[57]
The scattering field is defined as: σs(x) = 1.0 + 1 + exp −3 mX k=1 ck sin(ωx,kπx′
denote the spatial coordinates normalized by the domain scale factor. The scattering field is defined as: σs(x) = 1.0 + 1 + exp −3 mX k=1 ck sin(ωx,kπx′
-
[58]
star shape
sin(ωy,kπx′ 2) !!−1 , 16 where the number of modes m is drawn uniformly from {2, . . . ,5}, the expansion coefficients ck are sampled independently from a uniform distribution U([−1,1]) , and the spatial frequencies ωx,k and ωy,k are drawn uniformly from the integer set {1,2,3} . This construction ensures that the scattering coefficients are smooth and st...
2048
-
[59]
after 20 warm-up iterations with CUDA synchronization; throughput is measured at batch size 16. GAIA achieves competitive latency and memory while maintaining the highest throughput among geometry-adaptive methods. To assess the computational efficiency of GAIA relative to baseline methods, we conduct a compre- hensive timing analysis on the EIT benchmark...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.