Relation-Centric Open-Vocabulary 3D Gaussian Segmentation
Pith reviewed 2026-07-02 13:31 UTC · model grok-4.3
The pith
PairGS reframes 3D Gaussian segmentation as pairwise relation modeling to separate Gaussians along object boundaries for any language query.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
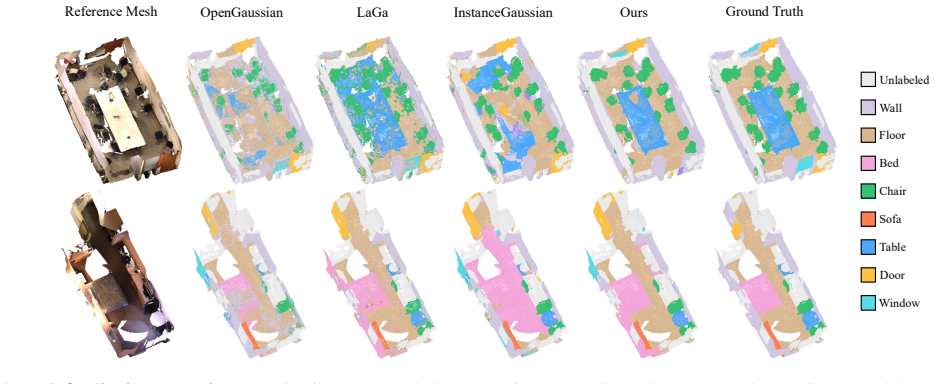
PairGS explicitly constructs a relation graph for segmentation by first proposing sparse edge candidates using low-dimensional descriptors, then computing precise pairwise affinities only on those candidates, and finally building a hierarchical cluster tree for multi-granular querying, yielding state-of-the-art results on open-vocabulary 3D Gaussian segmentation benchmarks with a fast variant that runs 50 times faster than optimization-based instance-feature methods.
What carries the argument
The relation graph constructed from view contribution weights and multi-view mask evidence, which encodes pairwise affinities to group Gaussians into object-consistent clusters.
If this is right
- Gaussian segmentations become responsive to diverse language queries without embedding language knowledge into individual points.
- Hierarchical cluster trees support querying at multiple levels of granularity from the same relation graph.
- Segmentation avoids the computational overhead of per-scene optimization of instance features.
- Performance reaches state-of-the-art levels on standard open-vocabulary 3D Gaussian segmentation benchmarks.
Where Pith is reading between the lines
- The same pairwise-relation construction could be tested on tasks such as 3D instance tracking across time or editing of reconstructed scenes.
- If the low-dimensional descriptors reliably surface relevant edges, similar candidate-proposal steps might reduce cost in other dense 3D correspondence problems.
- The approach suggests that explicit graph modeling may substitute for learned per-point embeddings in additional open-vocabulary 3D perception settings.
Load-bearing premise
View contribution weights and multi-view mask evidence supply signals rich enough to build an accurate relation graph that cleanly separates Gaussians along object boundaries for arbitrary language queries.
What would settle it
A test scene containing clear multi-view mask evidence where the resulting relation graph merges Gaussians from distinct objects or splits Gaussians from the same object under a straightforward language query.
Figures
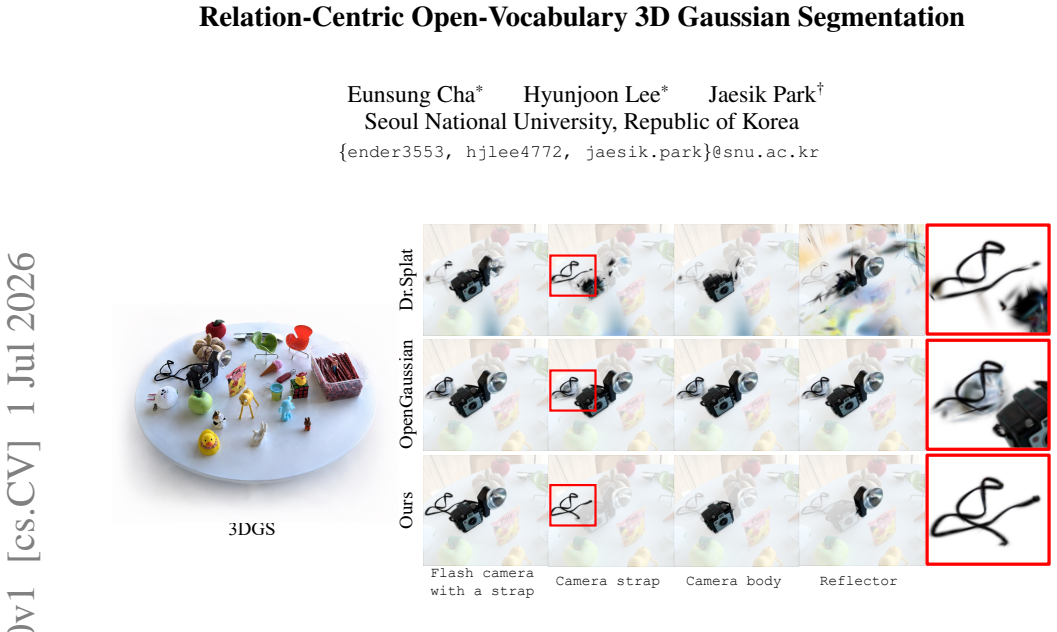
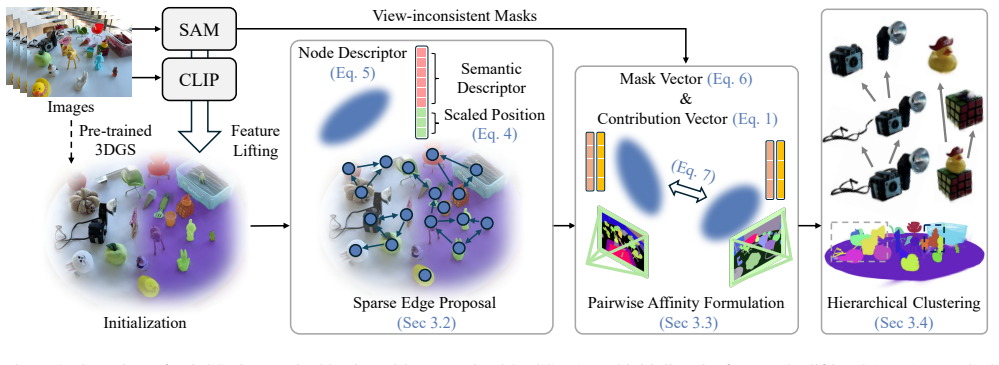

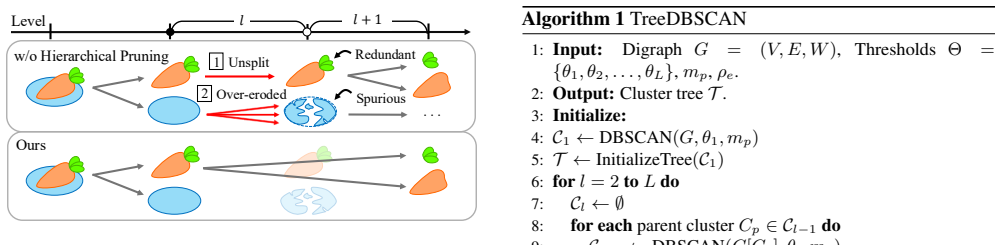
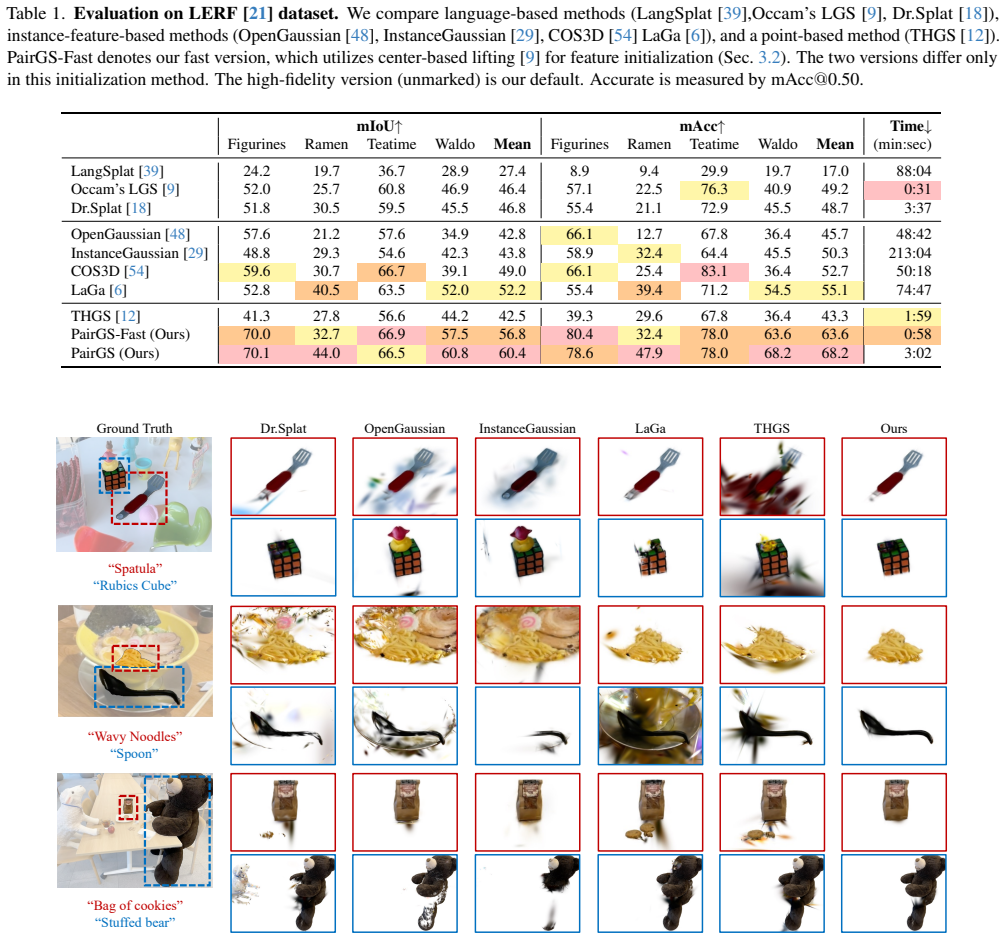
read the original abstract
Open-vocabulary 3D Gaussian segmentation is challenging because it requires language understanding for diverse queries and accurate separation of Gaussians along object boundaries. Prior approaches either embed language knowledge into individual Gaussians to improve query responsiveness or optimize per-Gaussian instance features to encode object identity. However, these strategies may produce noisy Gaussian segmentations or rely on cost-inefficient per-scene optimization. We propose PairGS, a framework that reframes Gaussian segmentation as modeling pairwise relations between Gaussians. 3D Gaussian representations provide rich signals for relation estimation, such as view contribution weights and multi-view mask evidence. By leveraging these cues, PairGS explicitly constructs a relation graph for segmentation without a heavy optimization process. PairGS first proposes sparse edge candidates using low-dimensional descriptors, computes precise pairwise affinities only on those candidates, and builds a hierarchical cluster tree for multi-granular querying. It achieves state-of-the-art results on open-vocabulary 3D Gaussian segmentation benchmarks, while the fast variant is 50x faster than optimization-based instance-feature approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PairGS, a framework that reframes open-vocabulary 3D Gaussian segmentation as explicit modeling of pairwise relations between Gaussians. It leverages view contribution weights and multi-view mask evidence to propose sparse edge candidates, compute affinities, and construct a hierarchical cluster tree that supports multi-granular language queries, claiming state-of-the-art results on benchmarks together with a 50x speedup for the fast variant relative to optimization-based instance-feature methods.
Significance. If the performance claims are substantiated with quantitative evidence, the relation-centric formulation offers a potentially scalable alternative to per-scene optimization or per-Gaussian language embedding, which could reduce computational overhead in practical 3D scene understanding applications while preserving query flexibility.
major comments (2)
- [Abstract] Abstract: the central SOTA and 50x speedup claims are asserted without any quantitative numbers, benchmark names, ablation tables, or error analysis, rendering the primary performance contribution unverifiable from the provided text.
- [Abstract] PairGS construction (abstract description of relation graph): the claim that view contribution weights plus multi-view mask evidence suffice to produce a query-agnostic hierarchical cluster tree whose boundaries align with semantic objects for arbitrary queries is load-bearing, yet no analysis is supplied of failure modes when 2D masks from open-vocabulary models mis-segment visually similar or occluded objects or when low-dimensional descriptors omit critical edges.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central SOTA and 50x speedup claims are asserted without any quantitative numbers, benchmark names, ablation tables, or error analysis, rendering the primary performance contribution unverifiable from the provided text.
Authors: We agree that the abstract would benefit from greater specificity to allow readers to immediately verify the claims. In the revised version we will expand the abstract to name the primary benchmarks, report concrete metrics (including the exact speedup factor relative to the cited optimization-based baselines), and explicitly reference the main-text tables and ablations that substantiate the SOTA results. revision: yes
-
Referee: [Abstract] PairGS construction (abstract description of relation graph): the claim that view contribution weights plus multi-view mask evidence suffice to produce a query-agnostic hierarchical cluster tree whose boundaries align with semantic objects for arbitrary queries is load-bearing, yet no analysis is supplied of failure modes when 2D masks from open-vocabulary models mis-segment visually similar or occluded objects or when low-dimensional descriptors omit critical edges.
Authors: The abstract summarizes the core design choice; the full manuscript already contains quantitative results across scenes containing occlusions and visually similar objects that implicitly evaluate robustness. Nevertheless, we acknowledge the value of an explicit failure-mode discussion. We will add a dedicated paragraph in the revised manuscript that examines cases where 2D mask errors or descriptor omissions occur and shows how the multi-view affinity computation and hierarchical clustering limit their impact. revision: yes
Circularity Check
No significant circularity; method relies on external signals without self-referential reduction
full rationale
The paper reframes open-vocabulary 3D Gaussian segmentation as pairwise relation modeling and constructs a relation graph from view contribution weights and multi-view mask evidence. No equations, derivations, or self-citations are shown that reduce the claimed SOTA performance or cluster quality to a fitted parameter or input defined by the same data. The fast variant's speed advantage is presented as arising from avoiding per-scene optimization rather than any tautological prediction. The central construction uses external cues (masks, weights) to build the graph, making the derivation self-contained against benchmarks without fitting-input-called-prediction or self-definition patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Principal component anal- ysis.Wiley interdisciplinary reviews: computational statistics, 2(4):433–459, 2010
Herv´e Abdi and Lynne J Williams. Principal component anal- ysis.Wiley interdisciplinary reviews: computational statistics, 2(4):433–459, 2010. 4
2010
-
[2]
Lightsplat: Fast and memory-efficient open-vocabulary 3d scene understanding in five seconds
Jaehun Bang, Jinhyeok Kim, Minji Kim, Seungheon Jeong, and Kyungdon Joo. Lightsplat: Fast and memory-efficient open-vocabulary 3d scene understanding in five seconds. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 19812–19821, 2026. 3
2026
-
[3]
Mip-nerf 360: Unbounded anti-aliased neural radiance fields
Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Peter Hedman. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. InProceedings of the IEEE/CVF conference on computer vision and pattern recog- nition, pages 5470–5479, 2022. 5, 9
2022
-
[4]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. InPro- ceedings of the IEEE/CVF international conference on com- puter vision, pages 9650–9660, 2021. 2
2021
-
[5]
Segment any 3d gaussians
Jiazhong Cen, Jiemin Fang, Chen Yang, Lingxi Xie, Xiaopeng Zhang, Wei Shen, and Qi Tian. Segment any 3d gaussians. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 1971–1979, 2025. 2, 3
1971
-
[6]
Tackling view-dependent semantics in 3d language gaussian splatting
Jiazhong Cen, Xudong Zhou, Jiemin Fang, Changsong Wen, Lingxi Xie, XIAOPENG ZHANG, Wei Shen, and Qi Tian. Tackling view-dependent semantics in 3d language gaussian splatting. InForty-second International Conference on Ma- chine Learning, 2025. 2, 3, 5, 6, 7, 8, 1, 4
2025
-
[7]
Lifting by gaussians: A simple, fast and flexible method for 3d instance segmentation
Rohan Chacko, Nicolai H¨ani, Eldar Khaliullin, Lin Sun, and Douglas Lee. Lifting by gaussians: A simple, fast and flexible method for 3d instance segmentation. In2025 IEEE/CVF Win- ter Conference on Applications of Computer Vision (WACV), pages 3497–3507. IEEE, 2025. 3, 5
2025
-
[8]
Tracking anything with de- coupled video segmentation
Ho Kei Cheng, Seoung Wug Oh, Brian Price, Alexander Schwing, and Joon-Young Lee. Tracking anything with de- coupled video segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1316– 1326, 2023. 3, 7, 8, 5
2023
-
[9]
Jiahuan Cheng, Jan-Nico Zaech, Luc Van Gool, and Danda Pani Paudel. Occam’s lgs: An efficient ap- proach for language gaussian splatting.arXiv preprint arXiv:2412.01807, 2024. 2, 4, 6, 7, 3
-
[10]
Click-gaussian: Interactive segmenta- tion to any 3d gaussians
Seokhun Choi, Hyeonseop Song, Jaechul Kim, Taehyeong Kim, and Hoseok Do. Click-gaussian: Interactive segmenta- tion to any 3d gaussians. InEuropean Conference on Com- puter Vision, pages 289–305. Springer, 2024. 2, 3
2024
-
[11]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017. 7, 8, 3, 5
2017
-
[12]
Training-free hierarchi- cal scene understanding for gaussian splatting with superpoint graphs
Shaohui Dai, Yansong Qu, Zheyan Li, Xinyang Li, Shengchuan Zhang, and Liujuan Cao. Training-free hierarchi- cal scene understanding for gaussian splatting with superpoint graphs. InProceedings of the 33rd ACM International Con- ference on Multimedia, pages 3673–3682, 2025. 3, 5, 6, 7, 1, 2, 4
2025
-
[13]
Extrinsplat: Decoupling geometry and semantics for open-vocabulary understanding in 3d gaussian splatting
Jiayu Ding, Xinpeng Liu, Zhiyi Pan, Shiqiang Long, and Ge Li. Extrinsplat: Decoupling geometry and semantics for open-vocabulary understanding in 3d gaussian splatting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 31019–31028, 2026. 3
2026
-
[14]
Francis Engelmann, Fabian Manhardt, Michael Niemeyer, Keisuke Tateno, Marc Pollefeys, and Federico Tombari. Open- nerf: Open set 3d neural scene segmentation with pixel- wise features and rendered novel views.arXiv preprint arXiv:2404.03650, 2024. 2
-
[15]
Panoptic nerf: 3d-to-2d label transfer for panoptic urban scene segmentation
Xiao Fu, Shangzhan Zhang, Tianrun Chen, Yichong Lu, Lanyun Zhu, Xiaowei Zhou, Andreas Geiger, and Yiyi Liao. Panoptic nerf: 3d-to-2d label transfer for panoptic urban scene segmentation. In2022 International Conference on 3D Vision (3DV), pages 1–11. IEEE, 2022. 2
2022
-
[16]
2d gaussian splatting for geometrically ac- curate radiance fields
Binbin Huang, Zehao Yu, Anpei Chen, Andreas Geiger, and Shenghua Gao. 2d gaussian splatting for geometrically ac- curate radiance fields. InACM SIGGRAPH 2024 conference papers, pages 1–11, 2024. 3, 7
2024
-
[17]
V otesplat: Hough voting gaussian splatting for 3d scene understanding
Minchao Jiang, Shunyu Jia, Jiaming Gu, Xiaoyuan Lu, Guangming Zhu, Anqi Dong, and Liang Zhang. V otesplat: Hough voting gaussian splatting for 3d scene understanding. arXiv preprint arXiv:2506.22799, 2025. 2, 3
-
[18]
Kim Jun-Seong, GeonU Kim, Kim Yu-Ji, Yu-Chiang Frank Wang, Jaesung Choe, and Tae-Hyun Oh. Dr. splat: Directly referring 3d gaussian splatting via direct language embedding registration. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14137–14146, 2025. 1, 2, 4, 6, 7, 3, 5
2025
-
[19]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023. 1, 2, 3, 7
2023
-
[20]
Lerf: Language embedded radiance fields
Justin Kerr, Chung Min Kim, Ken Goldberg, Angjoo Kanazawa, and Matthew Tancik. Lerf: Language embedded radiance fields. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 19729–19739,
-
[21]
Lerf: Language embedded radiance fields
Justin Kerr, Chung Min Kim, Ken Goldberg, Angjoo Kanazawa, and Matthew Tancik. Lerf: Language embedded radiance fields. InProceedings of the IEEE/CVF interna- tional conference on computer vision, pages 19729–19739,
-
[22]
Segment any- thing
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of the IEEE/CVF international confer- ence on computer vision, pages 4015–4026, 2023. 2, 3, 7, 8
2023
-
[23]
Tanks and temples: Benchmarking large-scale scene reconstruction.ACM Transactions on Graphics, 36(4), 2017
Arno Knapitsch, Jaesik Park, Qian-Yi Zhou, and Vladlen Koltun. Tanks and temples: Benchmarking large-scale scene reconstruction.ACM Transactions on Graphics, 36(4), 2017. 6
2017
-
[24]
Decomposing nerf for editing via feature field distillation.Ad- vances in Neural Information Processing Systems, 35:23311– 23330, 2022
Sosuke Kobayashi, Eiichi Matsumoto, and Vincent Sitzmann. Decomposing nerf for editing via feature field distillation.Ad- vances in Neural Information Processing Systems, 35:23311– 23330, 2022. 2 9
2022
-
[25]
Panoptic neural fields: A semantic object-aware neural scene representation
Abhijit Kundu, Kyle Genova, Xiaoqi Yin, Alireza Fathi, Car- oline Pantofaru, Leonidas J Guibas, Andrea Tagliasacchi, Frank Dellaert, and Thomas Funkhouser. Panoptic neural fields: A semantic object-aware neural scene representation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12871–12881, 2022. 2
2022
-
[26]
Cut pursuit: Fast algorithms to learn piecewise constant functions on general weighted graphs.SIAM Journal on Imaging Sciences, 10(4): 1724–1766, 2017
Loic Landrieu and Guillaume Obozinski. Cut pursuit: Fast algorithms to learn piecewise constant functions on general weighted graphs.SIAM Journal on Imaging Sciences, 10(4): 1724–1766, 2017. 3
2017
-
[27]
Cf3: Compact and fast 3d feature fields
Hyunjoon Lee, Joonkyu Min, and Jaesik Park. Cf3: Compact and fast 3d feature fields. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 27906– 27916, 2025. 2, 4
2025
-
[28]
Language-driven Semantic Segmentation
Boyi Li, Kilian Q Weinberger, Serge Belongie, Vladlen Koltun, and Ren ´e Ranftl. Language-driven semantic seg- mentation.arXiv preprint arXiv:2201.03546, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
Instancegaussian: Appearance-semantic joint gaussian representation for 3d instance-level perception
Haijie Li, Yanmin Wu, Jiarui Meng, Qiankun Gao, Zhiyao Zhang, Ronggang Wang, and Jian Zhang. Instancegaussian: Appearance-semantic joint gaussian representation for 3d instance-level perception. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14078– 14088, 2025. 2, 3, 6, 7, 8, 4
2025
-
[30]
Siyun Liang, Sen Wang, Kunyi Li, Michael Niemeyer, Ste- fano Gasperini, Nassir Navab, and Federico Tombari. Su- pergseg: Open-vocabulary 3d segmentation with structured super-gaussians.arXiv preprint arXiv:2412.10231, 2024. 2, 3
-
[31]
Kitti-360: A novel dataset and benchmarks for urban scene understanding in 2d and 3d.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(3):3292–3310, 2022
Yiyi Liao, Jun Xie, and Andreas Geiger. Kitti-360: A novel dataset and benchmarks for urban scene understanding in 2d and 3d.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(3):3292–3310, 2022. 5, 6
2022
-
[32]
Weakly supervised 3d open- vocabulary segmentation.Advances in Neural Information Processing Systems, 36:53433–53456, 2023
Kunhao Liu, Fangneng Zhan, Jiahui Zhang, Muyu Xu, Yingchen Yu, Abdulmotaleb El Saddik, Christian Theobalt, Eric Xing, and Shijian Lu. Weakly supervised 3d open- vocabulary segmentation.Advances in Neural Information Processing Systems, 36:53433–53456, 2023. 2
2023
-
[33]
Scaffold-gs: Structured 3d gaussians for view-adaptive rendering
Tao Lu, Mulin Yu, Linning Xu, Yuanbo Xiangli, Limin Wang, Dahua Lin, and Bo Dai. Scaffold-gs: Structured 3d gaussians for view-adaptive rendering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20654–20664, 2024. 7
2024
-
[34]
Gaga: Group Any Gaussians via 3D-aware Memory Bank
Weijie Lyu, Xueting Li, Abhijit Kundu, Yi-Hsuan Tsai, and Ming-Hsuan Yang. Gaga: Group any gaussians via 3d-aware memory bank.arXiv preprint arXiv:2404.07977, 2024. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Juliette Marrie, Romain M ´en´egaux, Michael Arbel, Diane Larlus, and Julien Mairal. Ludvig: Learning-free uplifting of 2d visual features to gaussian splatting scenes.arXiv preprint arXiv:2410.14462, 2024. 2, 4
-
[36]
Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 65(1):99–106, 2021
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 65(1):99–106, 2021. 2
2021
-
[37]
Graspgen: A diffusion-based framework for 6-dof grasping with on- generator training,
Adithyavairavan Murali, Balakumar Sundaralingam, Yu-Wei Chao, Wentao Yuan, Jun Yamada, Mark Carlson, Fabio Ramos, Stan Birchfield, Dieter Fox, and Clemens Eppner. Graspgen: A diffusion-based framework for 6-dof grasping with on-generator training.arXiv preprint arXiv:2507.13097,
-
[38]
3d vision-language gaussian splatting.arXiv preprint arXiv:2410.07577, 2024
Qucheng Peng, Benjamin Planche, Zhongpai Gao, Meng Zheng, Anwesa Choudhuri, Terrence Chen, Chen Chen, and Ziyan Wu. 3d vision-language gaussian splatting.arXiv preprint arXiv:2410.07577, 2024. 2
-
[39]
Langsplat: 3d language gaussian splatting
Minghan Qin, Wanhua Li, Jiawei Zhou, Haoqian Wang, and Hanspeter Pfister. Langsplat: 3d language gaussian splatting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20051–20060, 2024. 6, 7, 1, 2, 4
2024
-
[40]
Goi: Find 3d gaussians of interest with an optimizable open-vocabulary semantic-space hyperplane
Yansong Qu, Shaohui Dai, Xinyang Li, Jianghang Lin, Liu- juan Cao, Shengchuan Zhang, and Rongrong Ji. Goi: Find 3d gaussians of interest with an optimizable open-vocabulary semantic-space hyperplane. InProceedings of the 32nd ACM international conference on multimedia, pages 5328–5337,
-
[41]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 2, 3, 8
2021
-
[42]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment any- thing in images and videos.arXiv preprint arXiv:2408.00714,
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Language- grounded indoor 3d semantic segmentation in the wild
David Rozenberszki, Or Litany, and Angela Dai. Language- grounded indoor 3d semantic segmentation in the wild. In European conference on computer vision, pages 125–141. Springer, 2022. 3
2022
-
[44]
Trace3d: Consistent segmentation lifting via gaussian instance tracing
Hongyu Shen, Junfeng Ni, Yixin Chen, Weishuo Li, Mingtao Pei, and Siyuan Huang. Trace3d: Consistent segmentation lifting via gaussian instance tracing. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6656–6666, 2025. 3
2025
-
[45]
Language embedded 3d gaussians for open-vocabulary scene understanding
Jin-Chuan Shi, Miao Wang, Hao-Bin Duan, and Shao-Hua Guan. Language embedded 3d gaussians for open-vocabulary scene understanding. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 5333–5343, 2024. 2
2024
-
[46]
Panoptic lifting for 3d scene understanding with neural fields
Yawar Siddiqui, Lorenzo Porzi, Samuel Rota Bul ´o, Nor- man M ¨uller, Matthias Nießner, Angela Dai, and Peter Kontschieder. Panoptic lifting for 3d scene understanding with neural fields. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 9043–9052, 2023. 2
2023
-
[47]
Neural feature fusion fields: 3d distillation of self- supervised 2d image representations
Vadim Tschernezki, Iro Laina, Diane Larlus, and Andrea Vedaldi. Neural feature fusion fields: 3d distillation of self- supervised 2d image representations. In2022 International Conference on 3D Vision (3DV), pages 443–453. IEEE, 2022. 2
2022
-
[48]
Opengaussian: Towards point-level 10 3d gaussian-based open vocabulary understanding.Advances in Neural Information Processing Systems, 37:19114–19138,
Yanmin Wu, Jiarui Meng, Haijie Li, Chenming Wu, Yahao Shi, Xinhua Cheng, Chen Zhao, Haocheng Feng, Errui Ding, Jingdong Wang, et al. Opengaussian: Towards point-level 10 3d gaussian-based open vocabulary understanding.Advances in Neural Information Processing Systems, 37:19114–19138,
-
[49]
1, 2, 3, 6, 7, 8, 4, 5
-
[50]
Relags: Relational language gaussian splatting
Yaxu Xie, Abdalla Arafa, Alireza Javanmardi, Christen Millerdurai, Jia Cheng Hu, Shaoxiang Wang, Alain Pagani, and Didier Stricker. Relags: Relational language gaussian splatting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23826– 23836, 2026. 3, 4
2026
-
[51]
Gaus- sian grouping: Segment and edit anything in 3d scenes
Mingqiao Ye, Martin Danelljan, Fisher Yu, and Lei Ke. Gaus- sian grouping: Segment and edit anything in 3d scenes. In European conference on computer vision, pages 162–179. Springer, 2024. 2, 3, 7, 5
2024
-
[52]
Sai3d: Segment any instance in 3d scenes
Yingda Yin, Yuzheng Liu, Yang Xiao, Daniel Cohen-Or, Jing- wei Huang, and Baoquan Chen. Sai3d: Segment any instance in 3d scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3292–3302,
-
[53]
Nerflets: Local radiance fields for efficient structure-aware 3d scene represen- tation from 2d supervision
Xiaoshuai Zhang, Abhijit Kundu, Thomas Funkhouser, Leonidas Guibas, Hao Su, and Kyle Genova. Nerflets: Local radiance fields for efficient structure-aware 3d scene represen- tation from 2d supervision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8274–8284, 2023. 2
2023
-
[54]
Feature 3dgs: Supercharging 3d gaussian splatting to enable distilled feature fields
Shijie Zhou, Haoran Chang, Sicheng Jiang, Zhiwen Fan, Ze- hao Zhu, Dejia Xu, Pradyumna Chari, Suya You, Zhangyang Wang, and Achuta Kadambi. Feature 3dgs: Supercharging 3d gaussian splatting to enable distilled feature fields. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21676–21685, 2024. 2
2024
-
[55]
Cos3d: Collaborative open-vocabulary 3d segmentation
Runsong Zhu, Ka-Hei Hui, Zhengzhe Liu, Qianyi Wu, Weiliang Tang, Shi Qiu, Pheng-Ann Heng, and Chi-Wing Fu. Cos3d: Collaborative open-vocabulary 3d segmentation. arXiv preprint arXiv:2510.20238, 2025. 2, 3, 6, 7, 8, 4
-
[56]
Objectgs: Object-aware scene reconstruction and scene understand- ing via gaussian splatting
Ruijie Zhu, Mulin Yu, Linning Xu, Lihan Jiang, Yixuan Li, Tianzhu Zhang, Jiangmiao Pang, and Bo Dai. Objectgs: Object-aware scene reconstruction and scene understand- ing via gaussian splatting. InInternational Conference on Computer Vision (ICCV)(19/10/2025-23/10/2025, Honolulu, Hawai’i), 2025. 2, 3, 7, 5
2025
-
[57]
Traffic sign
Xingxing Zuo, Pouya Samangouei, Yunwen Zhou, Yan Di, and Mingyang Li. Fmgs: Foundation model embedded 3d gaussian splatting for holistic 3d scene understanding.Inter- national Journal of Computer Vision, 133(2):611–627, 2025. 2 11 A. Appendix Contents A.1 . Comparison of Feature Lifting Strategies . 1 A.2 . Our 3D–2D Association Approach . . . . . 1 A.3 ....
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.