KathaTrace: Diagnosing Semantic Trajectory Collapse in Generated Visual Narratives
Pith reviewed 2026-07-03 21:12 UTC · model grok-4.3
The pith
Visual narrative generators lose 23.5 points of recoverable transition meaning between scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
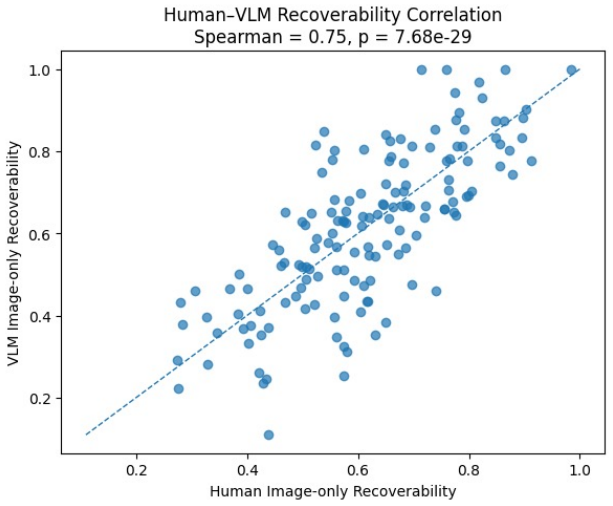
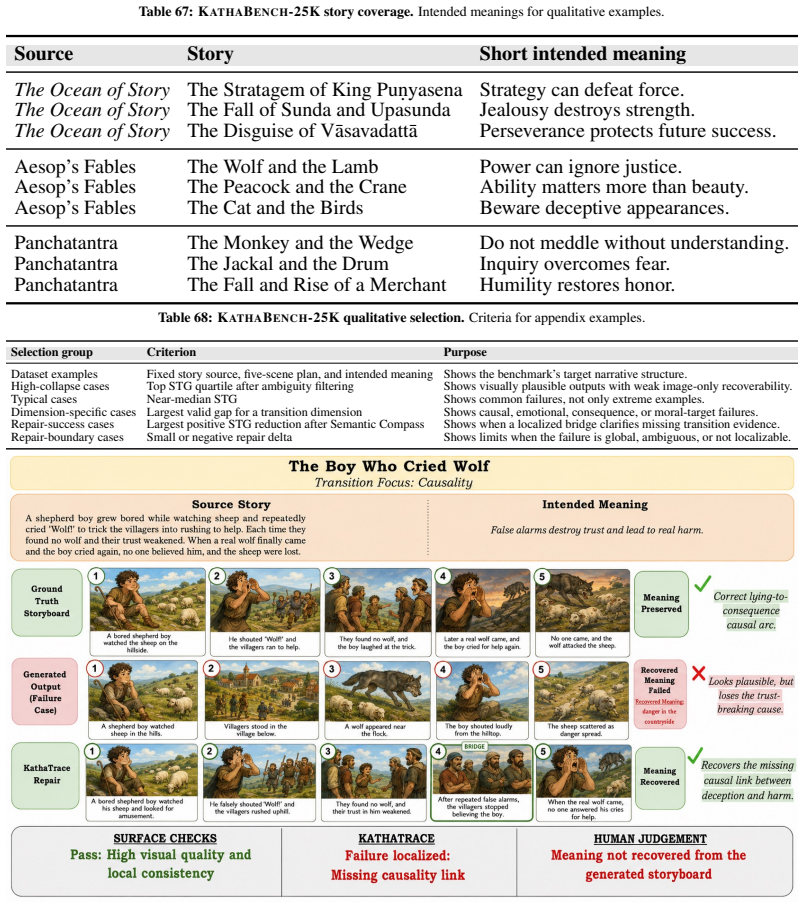
KathaTrace evaluates generated visual narratives by comparing human recoverability of transition meaning across text-only, image-only, and text-plus-image conditions on KathaBench-25K. Semantic Trajectory Gap is defined as text-only recoverability minus image-only recoverability, directly quantifying the semantic link lost during visualization. State-of-the-art generators exhibit an STG of 23.5 plus or minus 1.3, and Semantic Compass leverages these signals to improve storyboard selection.
What carries the argument
Semantic Trajectory Gap (STG), the arithmetic difference between text-only and image-only recoverability scores on filtered transition questions.
If this is right
- Existing visual quality and coherence benchmarks miss a distinct failure mode of semantic loss between scenes.
- Post-generation repair methods such as Semantic Compass can use KathaTrace signals to select or adjust storyboards.
- A 25K-item benchmark enables systematic comparison of generators on transition fidelity rather than surface appearance.
- The three-condition recoverability design isolates the visualization step as the source of meaning loss.
Where Pith is reading between the lines
- Training objectives for story generators may need explicit terms that penalize loss of transition semantics rather than only image-level coherence.
- The protocol could be adapted to video or animation generators where temporal ordering carries additional narrative weight.
- Classical story collections provide a stable, culturally diverse test bed that avoids modern copyright constraints while preserving complex transition structures.
Load-bearing premise
The recoverability questions under text-only, image-only, and text-plus-image conditions, after filtering ambiguous items, accurately and unbiasedly measure the loss of transition meaning.
What would settle it
Apply KathaTrace to a generator engineered to copy every original transition explicitly into its image sequence and observe whether the measured STG falls to near zero.
Figures
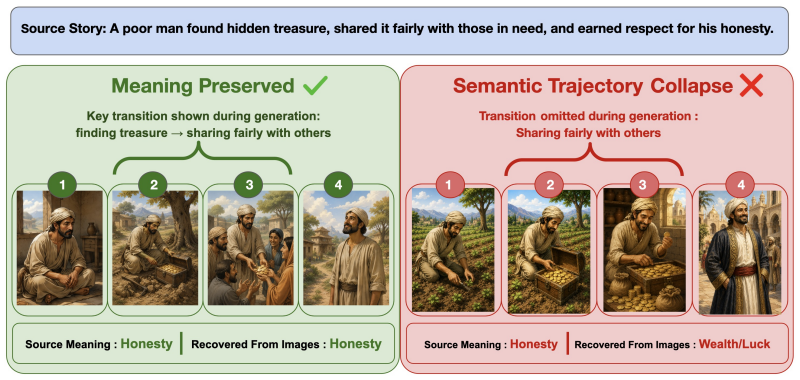
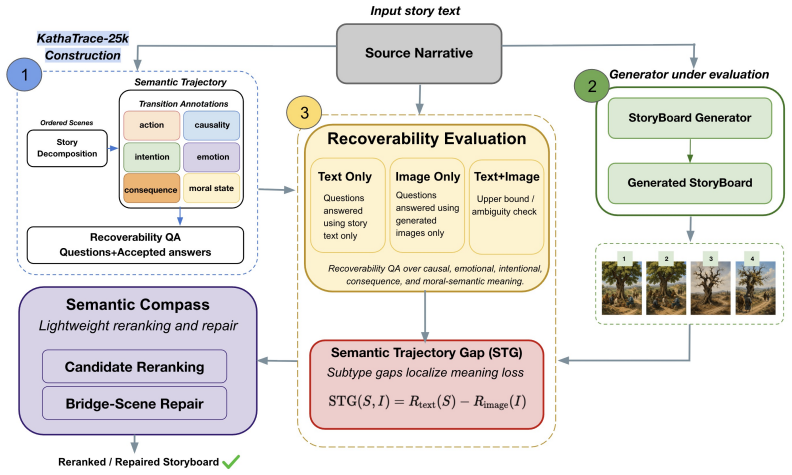

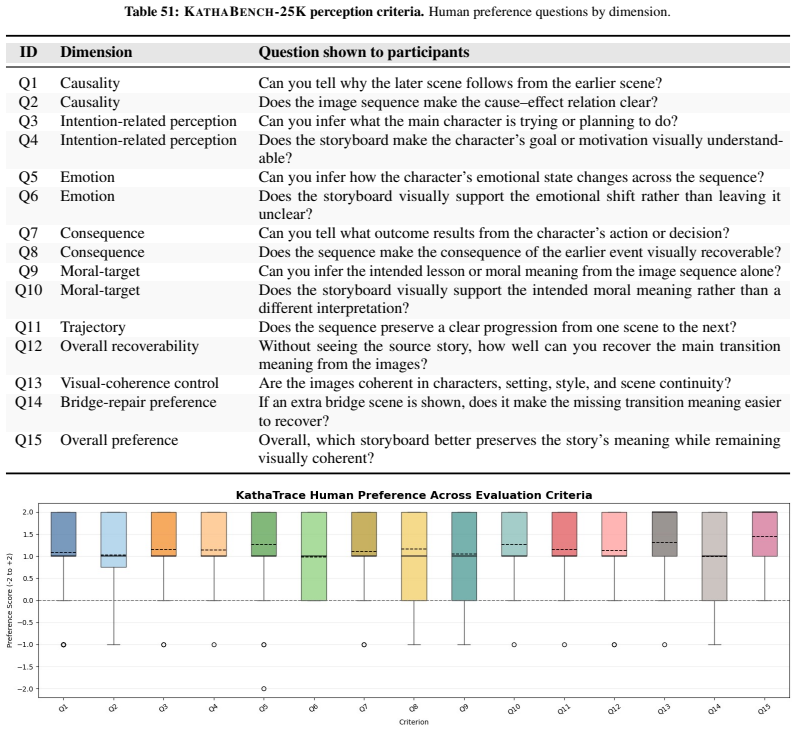
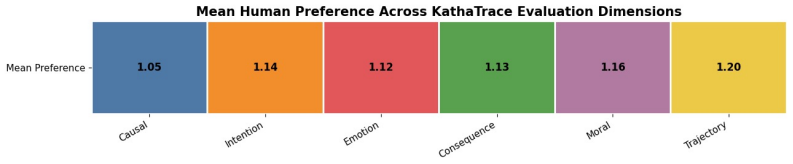
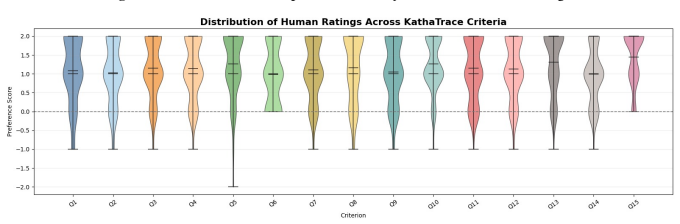
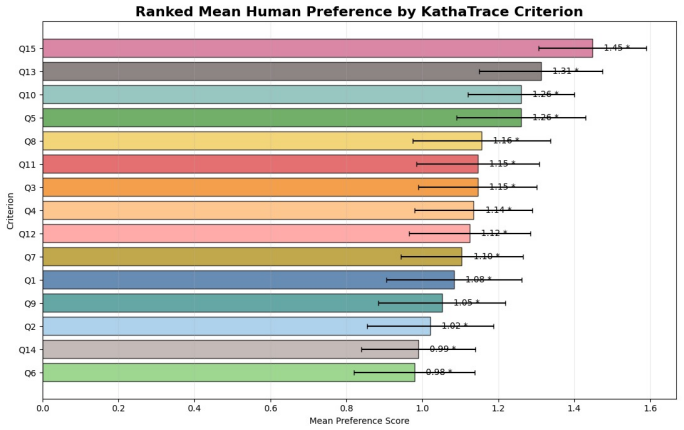
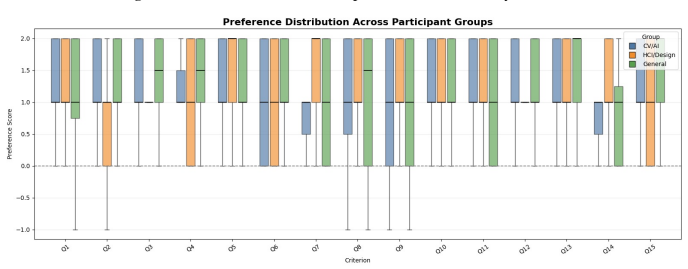
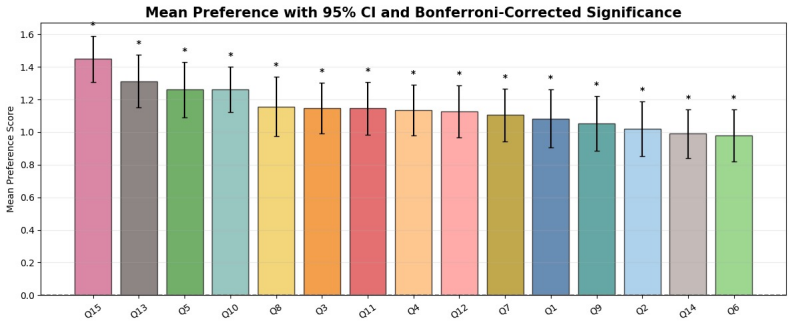

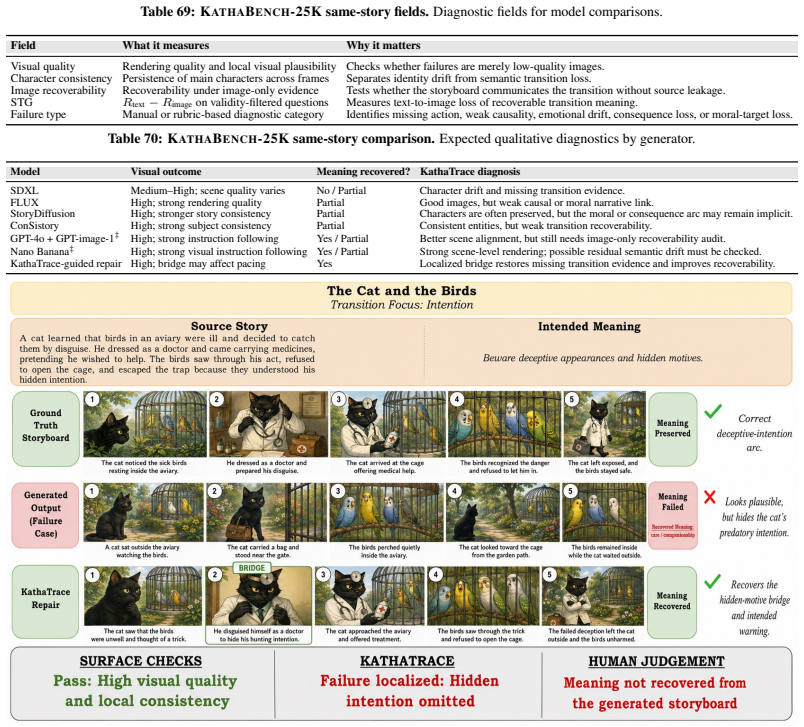






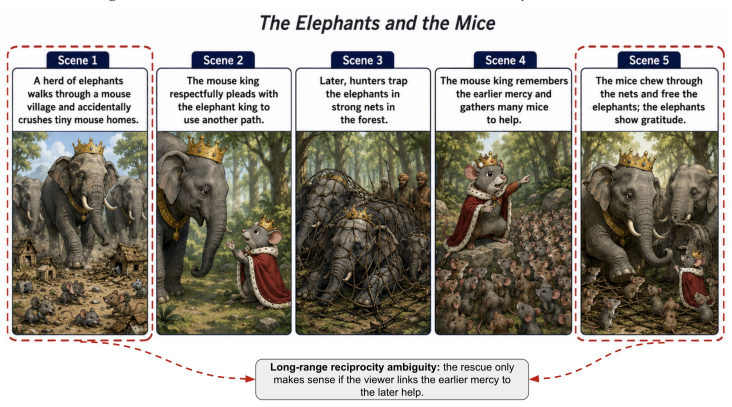
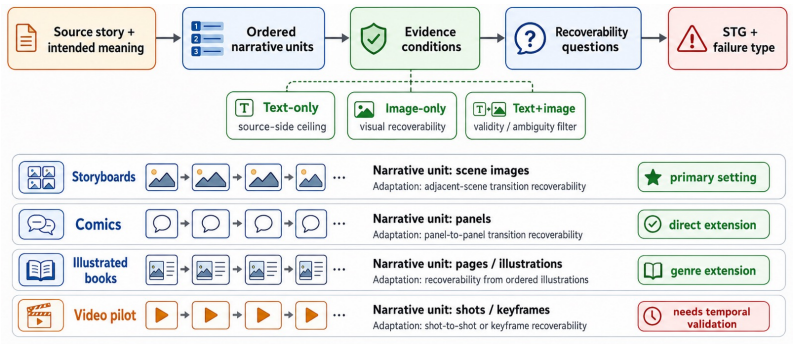


read the original abstract
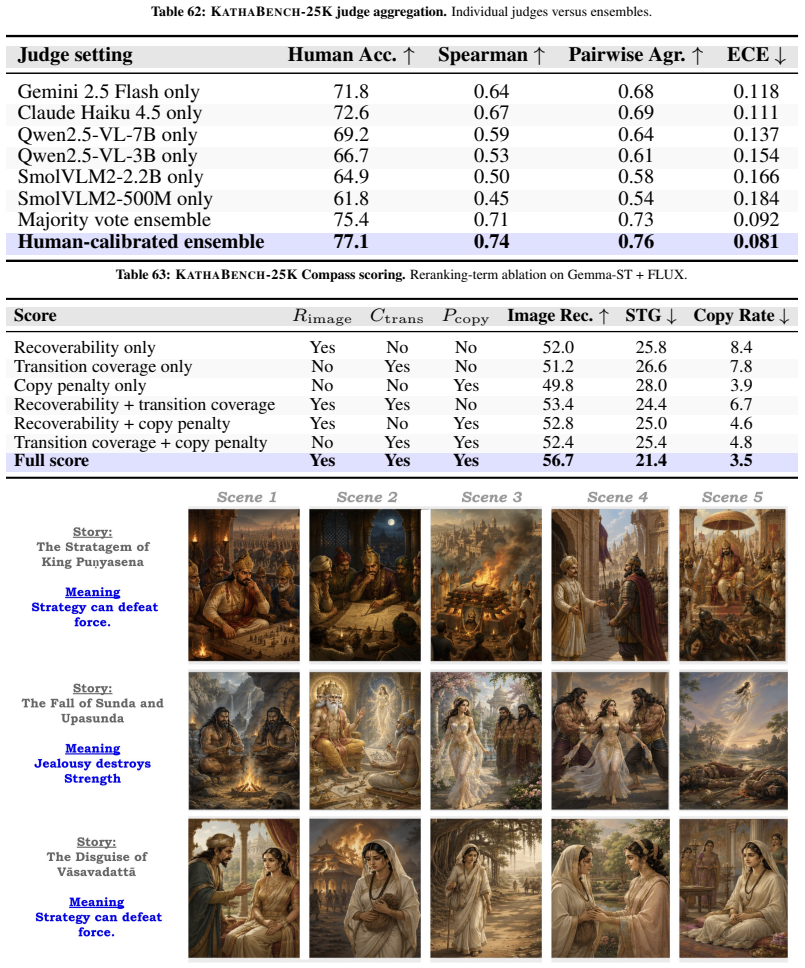
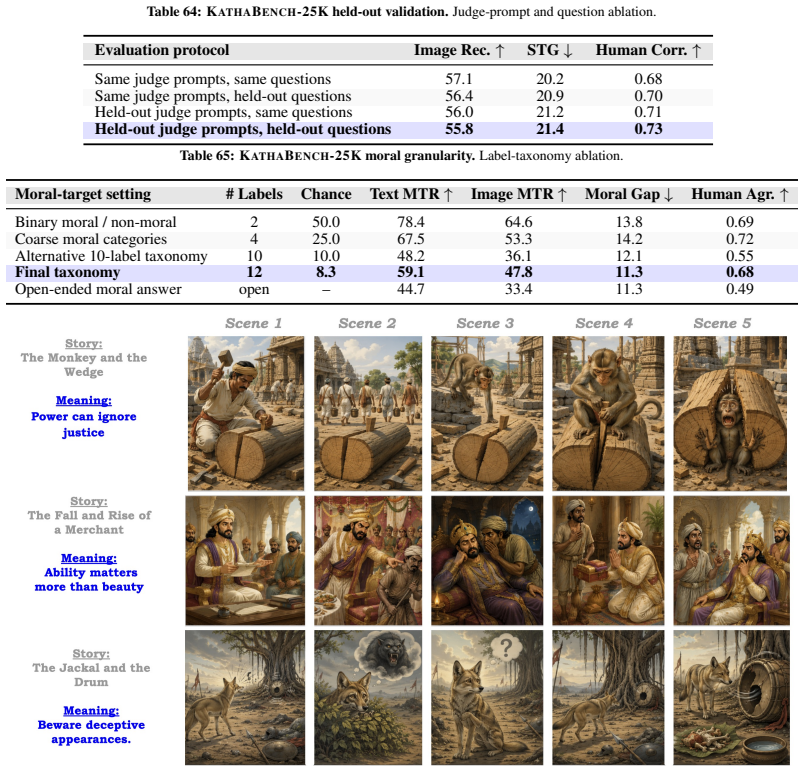
Visual narratives are central to storyboards, comics, children's media, and film previsualization, where viewers understand stories from images alone. Recent generators such as StoryDiffusion produce coherent sequences, but visual coherence does not guarantee that source-story transition meaning remains recoverable. Existing benchmarks assess visual quality, content faithfulness, and scene coherence, but miss a critical failure mode: storyboards where scenes appear visually coherent while the semantic link between scenes disappears. We introduce KathaTrace, a generator-agnostic protocol for diagnosing semantic trajectory collapse, defined as the loss of transition meaning needed to understand how one scene follows another. KathaTrace evaluates transitions under three evidence conditions: text-only, image-only, and text-plus-image, and filters ambiguous items. We contribute KathaBench-25K, with 5,000 narratives from classical collections including Aesop, Panchatantra, and Kathasaritasagara, 20,000 transitions, and 28,712 recoverability questions. We define Semantic Trajectory Gap, or STG, as text-only minus image-only recoverability, measuring transition meaning lost during visualization. Human validation yields Fleiss' kappa = 0.845. Experiments across state-of-the-art generators show substantial STG of 23.5 +/- 1.3. Semantic Compass, an actionability probe, uses KathaTrace signals for post-generation repair and improves storyboard selection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces KathaTrace, a generator-agnostic protocol and KathaBench-25K dataset (5,000 classical narratives, 20,000 transitions, 28,712 questions) to diagnose semantic trajectory collapse in AI-generated visual narratives. It defines Semantic Trajectory Gap (STG) as text-only minus image-only recoverability of transition meaning, reports STG = 23.5 +/- 1.3 across SOTA generators with Fleiss' kappa = 0.845 after ambiguous-item filtering, and introduces Semantic Compass for post-generation repair using the signals.
Significance. If the recoverability questions validly isolate transition semantics, the work identifies and quantifies a previously unmeasured failure mode (semantic loss despite visual coherence) with a large-scale, human-validated benchmark and an actionable repair probe. The generator-agnostic design and dataset scale from classical sources are clear strengths.
major comments (2)
- [Abstract / recoverability question protocol] Abstract and question-design description: the headline STG claim (23.5 +/- 1.3) is interpreted as semantic trajectory collapse only if the 28,712 recoverability questions specifically probe 'transition meaning needed to understand how one scene follows another.' High Fleiss' kappa = 0.845 confirms consistency but does not establish construct validity; no evidence is given that questions avoid confounding with general story recall, visual detail extraction, or prompt alignment, and the text-plus-image condition is mentioned without reported results to rule out bias.
- [STG definition and results] STG definition and filtering: STG is computed directly as text-only minus image-only recoverability on filtered KathaBench-25K transitions. Without explicit reporting of exclusion criteria, inter-condition question matching, or an ablation showing that the difference survives controls for non-transition factors, the numerical result cannot be unambiguously attributed to semantic collapse rather than other comprehension differences.
minor comments (1)
- [Abstract] The abstract states 'experiments across state-of-the-art generators' but does not name the specific models or report per-generator breakdowns; adding this would strengthen reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. The comments identify opportunities to strengthen the presentation of construct validity and methodological details. We address each major comment below and indicate revisions that will be incorporated.
read point-by-point responses
-
Referee: [Abstract / recoverability question protocol] Abstract and question-design description: the headline STG claim (23.5 +/- 1.3) is interpreted as semantic trajectory collapse only if the 28,712 recoverability questions specifically probe 'transition meaning needed to understand how one scene follows another.' High Fleiss' kappa = 0.845 confirms consistency but does not establish construct validity; no evidence is given that questions avoid confounding with general story recall, visual detail extraction, or prompt alignment, and the text-plus-image condition is mentioned without reported results to rule out bias.
Authors: The recoverability questions are generated from the explicit transition semantics in the source narratives (Section 3.2), targeting the inferential link required to understand scene succession rather than isolated scene content. We agree that additional evidence for construct validity would be valuable. In the revision we will (i) report the text-plus-image condition results (recoverability >90% across items), (ii) include representative question examples that isolate transition meaning, and (iii) add a short discussion of how question phrasing was constrained to avoid general recall or visual-detail confounds. These additions will be placed in a new subsection of the methods. revision: yes
-
Referee: [STG definition and results] STG definition and filtering: STG is computed directly as text-only minus image-only recoverability on filtered KathaBench-25K transitions. Without explicit reporting of exclusion criteria, inter-condition question matching, or an ablation showing that the difference survives controls for non-transition factors, the numerical result cannot be unambiguously attributed to semantic collapse rather than other comprehension differences.
Authors: Exclusion criteria (low inter-annotator agreement on ambiguous items) are stated in Section 4.2, and the same question set is administered under all three evidence conditions to ensure direct matching. We acknowledge that an explicit ablation isolating transition-specific effects would further support attribution to semantic collapse. The revised manuscript will therefore include (a) a consolidated table of exclusion statistics and (b) an ablation comparing STG on transition questions versus matched non-transition (scene-detail) questions. This will be added to the results section. revision: yes
Circularity Check
No significant circularity; STG is an explicit operational definition
full rationale
The paper defines Semantic Trajectory Gap (STG) directly as text-only recoverability minus image-only recoverability on the KathaBench-25K transitions after filtering. This is presented as a measurement protocol rather than a derived quantity obtained from fitting, self-citation chains, or an ansatz that reduces to the input by construction. No equations, uniqueness theorems, or predictions are shown that collapse back to the same fitted values or self-referential definitions. The central empirical claim (STG of 23.5 +/- 1.3) is therefore an observation under the stated definition and remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human judgments on recoverability questions reliably measure semantic transition meaning
invented entities (2)
-
Semantic Trajectory Gap (STG)
no independent evidence
-
KathaTrace protocol
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Story visualization by online text augmentation with context memory
Daechul Ahn, Daneul Kim, Gwangmo Song, Seung Hwan Kim, Honglak Lee, Dongyeop Kang, and Jonghyun Choi. Story visualization by online text augmentation with context memory. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3125–3135, 2023
2023
-
[2]
Storybench: A multifaceted benchmark for continuous story visualization
Emanuele Bugliarello, H Hernan Moraldo, Ruben Villegas, Mohammad Babaeizadeh, Moham- mad Taghi Saffar, Han Zhang, Dumitru Erhan, Vittorio Ferrari, Pieter-Jan Kindermans, and Paul V oigtlaender. Storybench: A multifaceted benchmark for continuous story visualization. Advances in Neural Information Processing Systems, 36:78095–78125, 2023
2023
-
[3]
Interleaved scene graphs for interleaved text-and-image generation assessment
Dongping Chen, Ruoxi Chen, Shu Pu, Zhaoyi Liu, Yanru Wu, Caixi Chen, Benlin Liu, Yue Huang, Yao Wan, Pan Zhou, et al. Interleaved scene graphs for interleaved text-and-image generation assessment. InInternational Conference on Learning Representations, volume 2025, pages 74693–74756, 2025
2025
-
[4]
Comm: A coherent interleaved image-text dataset for multimodal understanding and generation
Wei Chen, Lin Li, Yongqi Yang, Bin Wen, Fan Yang, Tingting Gao, Yu Wu, and Long Chen. Comm: A coherent interleaved image-text dataset for multimodal understanding and generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 8073–8082, 2025
2025
-
[5]
Davidsonian scene graph: Improving reliability in fine-grained evaluation for text-to-image generation
Jaemin Cho, Yushi Hu, Jason Baldridge, Roopal Garg, Peter Anderson, Ranjay Krishna, Mohit Bansal, Jordi Pont-Tuset, and Su Wang. Davidsonian scene graph: Improving reliability in fine-grained evaluation for text-to-image generation. InInternational conference on learning representations, volume 2024, pages 15625–15645, 2024
2024
-
[6]
David Dinkevich, Matan Levy, Omri Avrahami, Dvir Samuel, and Dani Lischinski. Story2board: a training-free approach for expressive storyboard generation.arXiv preprint arXiv:2508.09983, 2025
-
[7]
Vista: Vi- sual storytelling using multi-modal adapters for text-to-image diffusion models
Sibo Dong, Ismail Shaheen, Maggie Shen, Rupayan Mallick, and Sarah Adel Bargal. Vista: Vi- sual storytelling using multi-modal adapters for text-to-image diffusion models. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 12–21, 2026
2026
-
[8]
Mohamed Elmoghany, Liangbing Zhao, Xiaoqian Shen, Subhojyoti Mukherjee, Yang Zhou, Gang Wu, Viet Dac Lai, Seunghyun Yoon, Ryan Rossi, Abdullah Rashwan, et al. Infinitystory: Unlimited video generation with world consistency and character-aware shot transitions.arXiv preprint arXiv:2603.03646, 2026
-
[9]
Improved visual story generation with adaptive context modeling
Zhangyin Feng, Yuchen Ren, Xinmiao Yu, Xiaocheng Feng, Duyu Tang, Shuming Shi, and Bing Qin. Improved visual story generation with adaptive context modeling. InFindings of the Association for Computational Linguistics: ACL 2023, pages 4939–4955, 2023
2023
-
[10]
Vinabench: Benchmark for faithful and consistent visual narratives
Silin Gao, Sheryl Mathew, Li Mi, Sepideh Mamooler, Mengjie Zhao, Hiromi Wakaki, Yuki Mitsufuji, Syrielle Montariol, and Antoine Bosselut. Vinabench: Benchmark for faithful and consistent visual narratives. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2870–2879, 2025
2025
-
[11]
Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
2023
-
[12]
Narrabench: A comprehensive framework for narrative benchmarking
Sil Hamilton, Matthew Wilkens, and Andrew Piper. Narrabench: A comprehensive framework for narrative benchmarking. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3786–3801, 2026
2026
-
[13]
Dreamstory: Open-domain story visualization by llm- guided multi-subject consistent diffusion.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Huiguo He, Huan Yang, Zixi Tuo, Yuan Zhou, Qiuyue Wang, Yuhang Zhang, Zeyu Liu, Wenhao Huang, Hongyang Chao, and Jian Yin. Dreamstory: Open-domain story visualization by llm- guided multi-subject consistent diffusion.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. 11
2025
-
[14]
arXiv preprint arXiv:2411.04925 , year =
Panwen Hu, Jin Jiang, Jianqi Chen, Mingfei Han, Shengcai Liao, Xiaojun Chang, and Xiaodan Liang. Storyagent: Customized storytelling video generation via multi-agent collaboration. arXiv preprint arXiv:2411.04925, 2024
-
[15]
Tifa: Accurate and interpretable text-to-image faithfulness evaluation with question answering
Yushi Hu, Benlin Liu, Jungo Kasai, Yizhong Wang, Mari Ostendorf, Ranjay Krishna, and Noah A Smith. Tifa: Accurate and interpretable text-to-image faithfulness evaluation with question answering. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20406–20417, 2023
2023
-
[16]
arXiv preprint arXiv:2512.16853 , year=
Amita Kamath, Kai-Wei Chang, Ranjay Krishna, Luke Zettlemoyer, Yushi Hu, and Marjan Ghazvininejad. Geneval 2: Addressing benchmark drift in text-to-image evaluation.arXiv preprint arXiv:2512.16853, 2025
-
[17]
arXiv preprint arXiv:2406.13743 , year=
Baiqi Li, Zhiqiu Lin, Deepak Pathak, Jiayao Li, Yixin Fei, Kewen Wu, Tiffany Ling, Xide Xia, Pengchuan Zhang, Graham Neubig, et al. Genai-bench: Evaluating and improving compositional text-to-visual generation.arXiv preprint arXiv:2406.13743, 2024
-
[18]
Narratology meets text-to-image: a survey of consistency in ai generated storybook illustrations.Artificial Intelligence Review, 2026
Zhedong Lin, Zhongsheng Wang, Qian Liu, Xinyu Zhang, and Jiamou Liu. Narratology meets text-to-image: a survey of consistency in ai generated storybook illustrations.Artificial Intelligence Review, 2026
2026
-
[19]
Intelli- gent grimm-open-ended visual storytelling via latent diffusion models
Chang Liu, Haoning Wu, Yujie Zhong, Xiaoyun Zhang, Yanfeng Wang, and Weidi Xie. Intelli- gent grimm-open-ended visual storytelling via latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6190–6200, 2024
2024
-
[20]
One-prompt-one-story: Free-lunch consistent text-to-image generation using a single prompt
Tao Liu, Kai Wang, Senmao Li, Joost Van de Weijer, Fahad Khan, Shiqi Yang, Yaxing Wang, Jian Yang, and Ming-Ming Cheng. One-prompt-one-story: Free-lunch consistent text-to-image generation using a single prompt. InInternational Conference on Learning Representations, volume 2025, pages 24470–24497, 2025
2025
-
[21]
Lay2story: extending diffusion transformers for layout-togglable story generation
Ao Ma, Jiasong Feng, Ke Cao, Jing Wang, Yun Wang, Quanwei Zhang, and Zhanjie Zhang. Lay2story: extending diffusion transformers for layout-togglable story generation. InPro- ceedings of the IEEE/CVF International Conference on Computer Vision, pages 16102–16111, 2025
2025
-
[22]
Storydall-e: Adapting pretrained text-to- image transformers for story continuation
Adyasha Maharana, Darryl Hannan, and Mohit Bansal. Storydall-e: Adapting pretrained text-to- image transformers for story continuation. InEuropean conference on computer vision, pages 70–87. Springer, 2022
2022
-
[23]
Story-iter: A training-free iterative paradigm for long story visualization
Jiawei Mao, Xiaoke Huang, Yunfei Xie, Yuanqi Chang, Mude Hui, Bingjie Xu, Zeyu Zheng, Zirui Wang, Cihang Xie, and Yuyin Zhou. Story-iter: A training-free iterative paradigm for long story visualization. InThe Fourteenth International Conference on Learning Representations
-
[24]
Chutian Meng, Fan Ma, Chi Zhang, Jiaxu Miao, Yi Yang, and Yueting Zhuang. Logistory: A logic-aware framework for multi-image story visualization.arXiv preprint arXiv:2603.28082, 2026
-
[25]
Make-a-story: Visual memory conditioned consistent story generation
Tanzila Rahman, Hsin-Ying Lee, Jian Ren, Sergey Tulyakov, Shweta Mahajan, and Leonid Sigal. Make-a-story: Visual memory conditioned consistent story generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2493–2502, 2023
2023
-
[26]
Ayushman Sarkar, Zhenyu Yu, Chu Chen, Wei Tang, Kangning Cui, and Mohd Yamani Idna Idris. Redistory: Region-disentangled diffusion for consistent visual story generation.arXiv preprint arXiv:2602.01303, 2026
-
[27]
Storygpt-v: Large language models as consistent story visualizers
Xiaoqian Shen and Mohamed Elhoseiny. Storygpt-v: Large language models as consistent story visualizers. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 13273–13283, 2025
2025
-
[28]
Animaker: Multi-agent animated storytelling with mcts-driven clip generation
Haoyuan Shi, Yunxin Li, Xinyu Chen, Longyue Wang, Baotian Hu, and Min Zhang. Animaker: Multi-agent animated storytelling with mcts-driven clip generation. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–11, 2025. 12
2025
-
[29]
Msvbench: Towards human-level evaluation of multi-shot video generation
Haoyuan Shi, Yunxin Li, Nanhao Deng, Zhenran Xu, Xinyu Chen, Longyue Wang, Baotian Hu, and Min Zhang. Msvbench: Towards human-level evaluation of multi-shot video generation. arXiv preprint arXiv:2602.23969, 2026
-
[30]
Storybooth: Training-free multi-subject consistency for improved visual storytelling
Jaskirat Singh, Junshen K Chen, Jonas Kohler, and Michael Cohen. Storybooth: Training-free multi-subject consistency for improved visual storytelling. InInternational Conference on Learning Representations, volume 2025, pages 48678–48690, 2025
2025
-
[31]
AttriStory: Fine-grained Attribute Realization for Visual Storytelling with Diffusion Models
Manogna Sreenivas, Rohit Kumar, and Soma Biswas. Attristory: Fine-grained attribute realiza- tion for visual storytelling with diffusion models.arXiv preprint arXiv:2605.20777, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Storyimager: A unified and efficient framework for coherent story visualization and completion
Ming Tao, Bing-Kun Bao, Hao Tang, Yaowei Wang, and Changsheng Xu. Storyimager: A unified and efficient framework for coherent story visualization and completion. InEuropean Conference on Computer Vision, pages 479–495. Springer, 2024
2024
-
[33]
arXiv preprint arXiv:2503.05242 , year =
Xuenan Xu, Jiahao Mei, Chenliang Li, Yuning Wu, Ming Yan, Shaopeng Lai, Ji Zhang, and Mengyue Wu. Mm-storyagent: Immersive narrated storybook video generation with a multi- agent paradigm across text, image and audio.arXiv preprint arXiv:2503.05242, 2025
-
[34]
Seed-story: Multimodal long story generation with large language model
Shuai Yang, Yuying Ge, Yang Li, Yukang Chen, Yixiao Ge, Ying Shan, and Ying-Cong Chen. Seed-story: Multimodal long story generation with large language model. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1850–1860, 2025
2025
-
[35]
Zilyu Ye, Jinxiu Liu, Ruotian Peng, Jinjin Cao, Zhiyang Chen, Yiyang Zhang, Ziwei Xuan, Mingyuan Zhou, Xiaoqian Shen, Mohamed Elhoseiny, et al. Openstory++: A large-scale dataset and benchmark for instance-aware open-domain visual storytelling.arXiv preprint arXiv:2408.03695, 2024
-
[36]
Haojie Zhang, Di Wu, Bingyan Liu, Linjie Zhong, Yuancheng Wei, Xingsong Ye, Nanqing Liu, and Yaling Liang. Muss: A large-scale dataset and cinematic narrative benchmark for multi-shot subject-to-video generation.arXiv preprint arXiv:2604.23789, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
arXiv preprint arXiv:2512.19539 , year=
Kaiwen Zhang, Liming Jiang, Angtian Wang, Jacob Zhiyuan Fang, Tiancheng Zhi, Qing Yan, Hao Kang, Xin Lu, and Xingang Pan. Storymem: Multi-shot long video storytelling with memory.arXiv preprint arXiv:2512.19539, 2025
-
[38]
Contextualstory: Consistent visual storytelling with spatially- enhanced and storyline context
Sixiao Zheng and Yanwei Fu. Contextualstory: Consistent visual storytelling with spatially- enhanced and storyline context. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 10617–10625, 2025
2025
-
[39]
Jinsong Zhou, Yihua Du, Xinli Xu, Luozhou Wang, Zijie Zhuang, Yehang Zhang, Shuaibo Li, Xiaojun Hu, Bolan Su, and Ying-cong Chen. Videomemory: Toward consistent video generation via memory integration.arXiv preprint arXiv:2601.03655, 2026
-
[40]
Opening: A comprehensive benchmark for judging open-ended interleaved image-text generation
Pengfei Zhou, Xiaopeng Peng, Jiajun Song, Chuanhao Li, Zhaopan Xu, Yue Yang, Ziyao Guo, Hao Zhang, Yuqi Lin, Yefei He, et al. Opening: A comprehensive benchmark for judging open-ended interleaved image-text generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 56–66, 2025
2025
-
[41]
Storydiffusion: Consistent self-attention for long-range image and video generation.Advances in Neural Information Processing Systems, 37:110315–110340, 2024
Yupeng Zhou, Daquan Zhou, Ming-Ming Cheng, Jiashi Feng, and Qibin Hou. Storydiffusion: Consistent self-attention for long-range image and video generation.Advances in Neural Information Processing Systems, 37:110315–110340, 2024
2024
-
[42]
Cailin Zhuang, Ailin Huang, Yaoqi Hu, Jingwei Wu, Wei Cheng, Jiaqi Liao, Hongyuan Wang, Xinyao Liao, Weiwei Cai, Hengyuan Xu, et al. Vistorybench: Comprehensive benchmark suite for story visualization.arXiv preprint arXiv:2505.24862, 2025. 13 Appendix Appendix Contents A Dataset Construction and Human Validation Details 17 A.1 Construction Overview . . . ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.