Benchmarking Code Improvement with Progressive, Adaptive, and Interactive Feedback
Pith reviewed 2026-07-03 19:21 UTC · model grok-4.3
The pith
PAIR-Bench evaluates LLM code improvement by tracking repair trajectories with controlled progressive feedback instead of binary pass/fail outcomes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
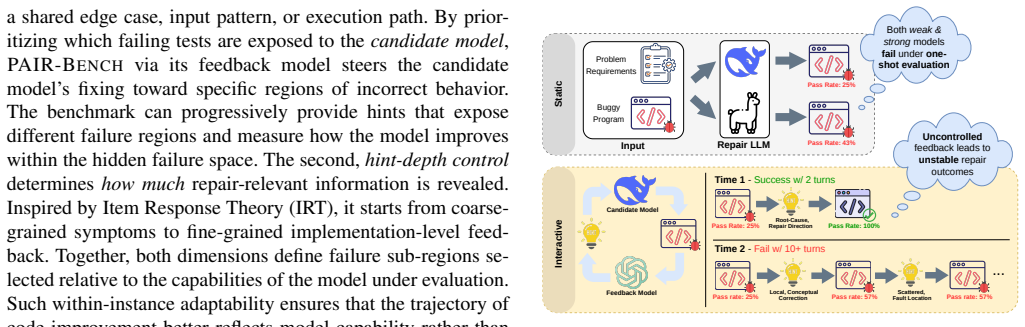
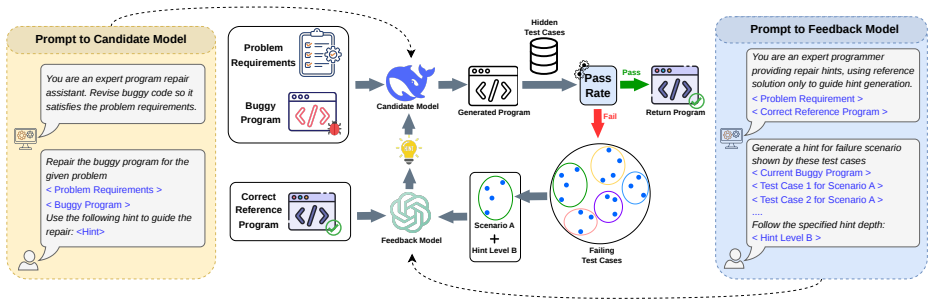
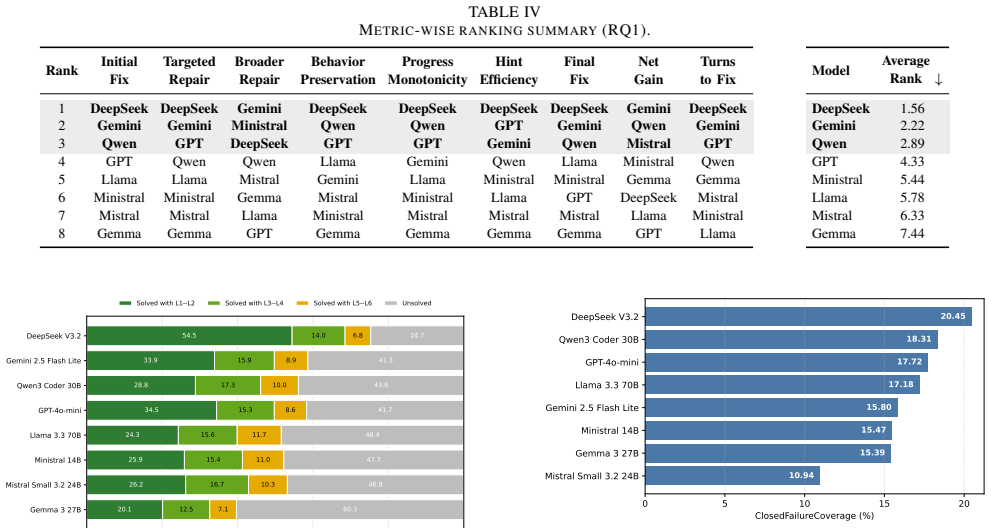
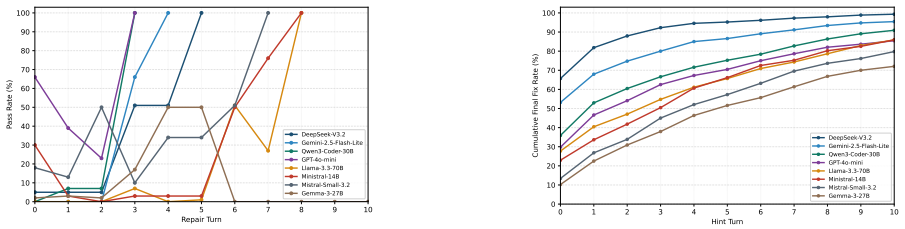
PAIR-Bench evaluates code improvement by applying progressive hinting, a structured feedback protocol with failure-region control that groups hidden failing tests into scenarios and hint-depth control that scales revealed information from coarse symptoms to detailed guidance, thereby measuring targeted repairs, generalization beyond hints, preservation of correct behavior, and required assistance levels through progressive metrics on full repair trajectories rather than endpoint outcomes alone.
What carries the argument
Progressive hinting, the structured feedback protocol with failure-region control and hint-depth control that generates adaptive hints during refinement.
If this is right
- Models can be scored on whether they successfully repair the specific failure scenarios targeted by the hints.
- The benchmark distinguishes cases where a model generalizes a repair to tests outside the hinted region from cases where it only fixes the hinted cases.
- Metrics capture whether models introduce regressions in parts of the code that were already correct before the hint.
- The protocol quantifies the minimum hint depth at which a model achieves successful improvement.
- Evaluation shifts from single-pass correctness to analysis of the full sequence of refinements and feedback utilization.
Where Pith is reading between the lines
- Adoption could encourage LLM training objectives that reward efficient use of iterative feedback rather than one-shot generation.
- The same controlled-hint structure might extend to evaluating models on non-code refinement tasks such as adjusting mathematical proofs or editing technical documents.
- If the metrics correlate with performance in open-ended user debugging sessions, the benchmark could serve as a proxy for real-world assistance quality.
- Developers might use failure-region groupings to create targeted training data that improves model robustness on specific bug patterns.
Load-bearing premise
The controls on which failure regions receive hints and how much repair detail is provided will produce measurements that validly reflect a model's ability to generalize, preserve behavior, and respond to assistance in code improvement tasks.
What would settle it
Running the benchmark on multiple models and finding that progressive metrics show no consistent differences across hint-depth levels or failure-region groupings, with all models exhibiting identical trajectories and final success rates.
Figures
read the original abstract
Large language models (LLMs) are typically evaluated on code generation and program repair using binary functional correctness: a generated program or patch either passes or fails a test suite. This protocol is simple but coarse, as it ignores partial progress, feedback use, regressions, and the refinement trajectory through which models often improve code. We introduce PAIR-Bench, a progressive and adaptive benchmark for evaluating code improvement: transforming an incorrect or incomplete program into a more correct one through feedback-guided refinement. PAIR-Bench uses progressive hinting, a structured feedback protocol with two controls. Failure-region control determines what the feedback targets by grouping hidden failing tests into failure scenarios, while hint-depth control determines how much repair-relevant information is revealed, from coarse symptoms to implementation-level guidance. This design enables PAIR-Bench to measure whether a model repairs targeted failures, generalizes beyond the hint, preserves already-correct behavior, and how much assistance it requires. By evaluating repair trajectories progressive metrics rather than only final pass/fail outcomes, PAIR-Bench provides a finer-grained assessment of LLM code-improvement capability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PAIR-Bench, a benchmark for evaluating LLM code improvement via progressive hinting. It introduces two controls—failure-region control (grouping hidden failing tests into scenarios) and hint-depth control (varying information from symptoms to implementation guidance)—to assess repair trajectories with progressive metrics rather than binary pass/fail outcomes, claiming this enables measurement of targeted repairs, generalization beyond hints, preservation of correct behavior, and assistance requirements.
Significance. If the protocol can be shown through validation to produce the intended measurements, PAIR-Bench would advance evaluation methodology in code generation and repair by capturing partial progress, feedback utilization, and regressions that current binary protocols overlook.
major comments (1)
- [Abstract] Abstract: The central claim that the failure-region and hint-depth controls enable measurement of targeted repairs, generalization beyond the hint, preservation of already-correct behavior, and assistance requirements is unsupported by any empirical results, example trajectories, ablation studies, or validation data. This is load-bearing, as the contribution rests on the assertion that the design produces these specific measurements rather than being confounded (e.g., by test-suite coverage or hint leakage).
minor comments (1)
- [Abstract] Abstract: The sentence 'By evaluating repair trajectories progressive metrics rather than only final pass/fail outcomes' is missing the preposition 'with'.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for recognizing the potential of PAIR-Bench to advance evaluation methodology. We address the single major comment below and commit to revisions that strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the failure-region and hint-depth controls enable measurement of targeted repairs, generalization beyond the hint, preservation of already-correct behavior, and assistance requirements is unsupported by any empirical results, example trajectories, ablation studies, or validation data. This is load-bearing, as the contribution rests on the assertion that the design produces these specific measurements rather than being confounded (e.g., by test-suite coverage or hint leakage).
Authors: We agree that the abstract asserts these measurement capabilities without accompanying empirical support, examples, or validation in the current version. The manuscript is a benchmark proposal whose claims follow from the protocol design (failure-region grouping of hidden tests and graduated hint-depth levels). To make the contribution robust, we will (1) revise the abstract to state that the controls are designed to enable these measurements, (2) add concrete example trajectories that illustrate targeted repair, generalization, preservation, and assistance quantification, and (3) include a validation section with ablation experiments that test for confounds such as test-suite coverage gaps and hint leakage. These additions directly address the load-bearing concern. revision: yes
Circularity Check
No circularity; benchmark protocol defined independently of results
full rationale
The paper proposes PAIR-Bench, a new evaluation protocol using progressive hinting with failure-region and hint-depth controls. No equations, fitted parameters, predictions, or derivations appear in the abstract or described content. The central contribution is the explicit definition of the benchmark structure itself, which stands independently of any target measurements or empirical outcomes. No self-citations, ansatzes, or reductions to inputs by construction are present. This matches the expected non-finding for a definitional benchmark paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. Her...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Livecodebench: Holistic and contamination free evaluation of large language models for code,
N. Jain, K. Han, A. Gu, W.-D. Li, F. Yan, T. Zhang, S. Wang, A. Solar-Lezama, K. Sen, and I. Stoica, “Livecodebench: Holistic and contamination free evaluation of large language models for code,” in The Thirteenth International Conference on Learning Representations,
-
[3]
Available: https://openreview.net/forum?id=chfJJYC3iL
[Online]. Available: https://openreview.net/forum?id=chfJJYC3iL
-
[4]
SWE-bench: Can language models resolve real-world github issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. R. Narasimhan, “SWE-bench: Can language models resolve real-world github issues?” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=VTF8yNQM66
2024
-
[5]
Autocoderover: Autonomous program improvement,
Y . Zhang, H. Ruan, Z. Fan, and A. Roychoudhury, “Autocoderover: Autonomous program improvement,” inProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, ser. ISSTA 2024. New York, NY , USA: Association for Computing Machinery, 2024, p. 1592–1604. [Online]. Available: https://doi.org/10.1145/3650212.3680384
-
[6]
Agentless: Demystifying llm-based software engineering agents,
C. S. Xia, Y . Deng, S. Dunn, and L. Zhang, “Agentless: Demystifying llm-based software engineering agents,”CoRR, 2024
2024
-
[7]
Is the cure worse than the disease? overfitting in automated program repair,
E. K. Smith, E. T. Barr, C. Le Goues, and Y . Brun, “Is the cure worse than the disease? overfitting in automated program repair,” in Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering, ESEC/FSE 2015, Bergamo, Italy, August 30 - September 4, 2015, E. D. Nitto, M. Harman, and P. Heymans, Eds. ACM, 2015, pp. 532–543. [Online]....
-
[8]
Y . Wang, M. Pradel, and Z. Liu, “Are ”solved issues” in swe-bench really solved correctly? an empirical study,”CoRR, vol. abs/2503.15223,
-
[9]
[Online]. Available: https://doi.org/10.48550/arXiv.2503.15223
-
[10]
Introducing SWE-bench verified,
OpenAI, “Introducing SWE-bench verified,” https://openai.com/index/introducing-swe-bench-verified/, 2024, accessed: 2026-06-17
2024
-
[11]
Graph-based, self-supervised program repair from diagnostic feedback,
M. Yasunaga and P. Liang, “Graph-based, self-supervised program repair from diagnostic feedback,” inProceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, ser. Proceedings of Machine Learning Research, vol. 119. PMLR, 2020, pp. 10 799–10 808. [Online]. Available: http://proceedings.mlr.press/v119/y...
2020
-
[12]
FeedbackEval: A benchmark for evaluating large language models in feedback-driven code repair tasks,
D. Dai, M. Liu, A. Li, J. Cao, Y . Wang, C. Wang, X. Peng, and Z. Zheng, “FeedbackEval: A benchmark for evaluating large language models in feedback-driven code repair tasks,”arXiv preprint arXiv:2504.06939, 2025
-
[13]
Self-edit: Fault-aware code editor for code generation,
K. Zhang, Z. Li, J. Li, G. Li, and Z. Jin, “Self-edit: Fault-aware code editor for code generation,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, A. Rogers, J. L. Boyd-Graber, and N. Okazaki, Eds. Association for Computational Linguistics, 202...
-
[14]
Teaching large language models to self-debug,
X. Chen, M. Lin, N. Sch ¨arli, and D. Zhou, “Teaching large language models to self-debug,” inThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. [Online]. Available: https://openreview.net/forum?id=KuPixIqPiq
2024
-
[15]
Large language model guided self-debugging code generation,
M. Adnan, Z. Xu, and C. C. N. Kuhn, “Large language model guided self-debugging code generation,”CoRR, vol. abs/2502.02928, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2502.02928
-
[16]
ConvCodeWorld: Benchmarking conversational code generation in reproducible feedback environments,
H. Han, S.-w. Hwang, R. Samdani, and Y . He, “ConvCodeWorld: Benchmarking conversational code generation in reproducible feedback environments,” inInternational Conference on Learning Representa- tions, 2025
2025
-
[17]
When benchmarks talk: Re-evaluating code LLMs with interactive feedback,
J. Pan, R. Shar, J. Pfau, A. Talwalkar, H. He, and V . Chen, “When benchmarks talk: Re-evaluating code LLMs with interactive feedback,” inFindings of the Association for Computational Linguistics: ACL 2025, 2025
2025
-
[18]
Available: https://pairbench.site
[Online]. Available: https://pairbench.site
-
[19]
Program Synthesis with Large Language Models
J. Austin, A. Odena, M. Nye, M. Bosma, H. Michalewski, D. Dohan, E. Jiang, C. Cai, M. Terry, Q. Le, and C. Sutton, “Program synthesis with large language models,”arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[20]
InterCode: Stan- dardizing and benchmarking interactive coding with execution feed- back,
J. Yang, A. Prabhakar, K. Narasimhan, and S. Yao, “InterCode: Stan- dardizing and benchmarking interactive coding with execution feed- back,” inAdvances in Neural Information Processing Systems, 2023
2023
-
[21]
Measuring coding challenge competence with APPS,
D. Hendrycks, S. Basart, S. Kadavath, M. Mazeika, A. Arora, E. Guo, C. Burns, S. Puranik, H. He, D. Song, and J. Steinhardt, “Measuring coding challenge competence with APPS,” inThirty- fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021. [Online]. Available: https://openreview.net/forum?id=sD93GOzH3i5
2021
-
[22]
Is your code generated by chatGPT really correct? rigorous evaluation of large language models for code generation,
J. Liu, C. S. Xia, Y . Wang, and L. Zhang, “Is your code generated by chatGPT really correct? rigorous evaluation of large language models for code generation,” inThirty-seventh Conference on Neural Information Processing Systems, 2023. [Online]. Available: https://openreview.net/forum?id=1qvx610Cu7
2023
-
[23]
Evaluating language models for efficient code generation,
J. Liu, S. Xie, J. Wang, Y . Wei, Y . Ding, and L. Zhang, “Evaluating language models for efficient code generation,” in First Conference on Language Modeling, 2024. [Online]. Available: https://openreview.net/forum?id=IBCBMeAhmC
2024
-
[24]
Defects4j: a database of existing faults to enable controlled testing studies for java programs,
R. Just, D. Jalali, and M. D. Ernst, “Defects4j: a database of existing faults to enable controlled testing studies for java programs,” in Proceedings of the 2014 International Symposium on Software Testing and Analysis, ser. ISSTA 2014. New York, NY , USA: Association for Computing Machinery, 2014, p. 437–440. [Online]. Available: https://doi.org/10.1145...
-
[25]
R. Widyasari, S. Q. Sim, C. Lok, H. Qi, J. Phan, Q. Tay, C. Tan, F. Wee, J. E. Tan, Y . Yieh, B. Goh, F. Thung, H. J. Kang, T. Hoang, D. Lo, and E. L. Ouh, “Bugsinpy: a database of existing bugs in python programs to enable controlled testing and debugging studies,” inProceedings of the 28th ACM Joint Meeting on European Software Engineering Conference an...
-
[26]
Quixbugs: a multi-lingual program repair benchmark set based on the quixey challenge,
D. Lin, J. Koppel, A. Chen, and A. Solar-Lezama, “Quixbugs: a multi-lingual program repair benchmark set based on the quixey challenge,” inProceedings Companion of the 2017 ACM SIGPLAN International Conference on Systems, Programming, Languages, and Applications: Software for Humanity, ser. SPLASH Companion 2017. New York, NY , USA: Association for Comput...
-
[27]
The power of feedback,
J. Hattie and H. Timperley, “The power of feedback,”Review of Educational Research, vol. 77, no. 1, pp. 81–112, 2007
2007
-
[28]
Focus on formative feedback,
V . J. Shute, “Focus on formative feedback,”Review of Educational Research, vol. 78, no. 1, pp. 153–189, 2008
2008
-
[29]
The role of tutoring in problem solving,
D. Wood, J. S. Bruner, and G. Ross, “The role of tutoring in problem solving,”Journal of Child Psychology and Psychiatry, vol. 17, no. 2, pp. 89–100, 1976
1976
-
[30]
L. S. Vygotsky,Mind in Society: The Development of Higher Psycho- logical Processes. Harvard University Press, 1978
1978
-
[31]
Codeforces-python-submissions,
MatrixStudio, “Codeforces-python-submissions,” Hug- ging Face dataset, 2024. [Online]. Available: https://huggingface.co/datasets/MatrixStudio/Codeforces-Python- Submissions
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.