A Cost-Aware, Paired Protocol for Auditing Dynamic Tool Synthesis in Agentic Video Question Answering
Pith reviewed 2026-07-03 20:57 UTC · model grok-4.3
The pith
A paired audit protocol shows Dynamic-SAGE raises video QA accuracy by 7.5 points while cutting tool calls 28 percent but raising token use 34 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Dynamic-SAGE improves final-answer accuracy by 7.5 points over the SAGE baseline on SAGE-Bench while reducing reasoning turns and visible tool calls by roughly 28 percent; the same comparison shows token usage rising 34 percent and inference cost rising 26 percent, with the largest gains on visual and open-ended questions.
What carries the argument
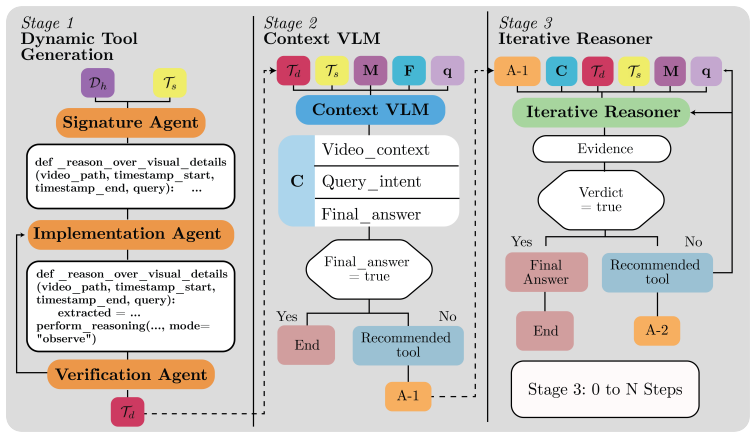
The six-group classification of paired outcomes defined by joint correctness and change in visible tool calls, which isolates accuracy-preserving efficiency changes from regressions.
If this is right
- Dynamic-SAGE achieves a 7.5-point accuracy lift with p less than 0.001.
- Reasoning turns and visible tool calls fall by about 28 percent.
- Token consumption rises 34 percent and monetary cost rises 26 percent.
- Accuracy and efficiency gains concentrate on visual and open-ended questions.
- Failures remain concentrated on hard open-ended questions that trigger the most synthesis work.
Where Pith is reading between the lines
- The same paired protocol could be reused on other agentic pipelines to detect when tool synthesis merely relocates cost rather than eliminating it.
- Persistent registration of synthesized tools may produce compounding savings only after many questions have been seen.
- Extending the six-group taxonomy to include latency or memory metrics would give a fuller cost profile.
- The protocol could serve as a standard benchmark addition for any system that expands its tool library at runtime.
Load-bearing premise
That sorting each paired outcome into one of six groups defined by joint correctness and change in visible tool calls reliably separates accuracy-preserving efficiency gains from harmful regressions.
What would settle it
A direct side-by-side measurement of wall-clock inference time and actual API spend on the same questions showing that the 28 percent drop in visible tool calls produces no net reduction in total cost or latency.
Figures

read the original abstract
Agentic Video Question Answering (VideoQA) systems invoke tools during inference, but their tool libraries are fixed, so recurring procedures are rebuilt from primitives on every question. Synthesizing composite tools could remove this overhead, but whether such expansion helps is hard to assess: final-answer accuracy, the standard metric, ignores inference effort, so it cannot reveal how a system shifts cost. We propose a cost-aware, paired protocol for auditing tool-augmented video agents. The protocol pairs two complete systems on the same input for each question and reports their net difference across accuracy and cost jointly. For each question, it sorts the paired outcome into one of six groups defined by joint correctness and by the change in visible tool calls, separating accuracy-preserving efficiency gains from harmful regressions. Significance is reported with McNemar's test and paired bootstrap confidence intervals. We instantiate the protocol on Dynamic-SAGE, an agentic VideoQA framework that synthesizes, validates, and persistently registers executable composite tools for reuse on unseen questions, and evaluate it against the SAGE baseline on SAGE-Bench. The audit reveals a multi-axis profile that a scalar accuracy comparison would miss: Dynamic-SAGE improves accuracy by 7.5 points (p < 0.001) and reduces reasoning turns and visible tool calls by roughly 28%, while shifting rather than reducing inference cost, as token usage rises 34% and cost 26%. Gains are largest on visual and open-ended questions and neutral on verbal and multimodal ones, and residual failures concentrate on hard, open-ended questions where the pipeline does the most work. By measuring accuracy and cost jointly, the protocol shows where the pipeline-level difference is reliable and where it is not. The code is available at https://github.com/KurbanIntelligenceLab/Dynamic-SAGE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a cost-aware paired auditing protocol for agentic VideoQA systems that synthesizes composite tools. For each question the protocol pairs two complete systems, classifies the outcome into one of six groups by joint correctness and change in visible tool calls, and reports net differences with McNemar's test and paired bootstrap intervals. On SAGE-Bench, Dynamic-SAGE vs. SAGE yields +7.5 accuracy points (p<0.001), ~28% fewer reasoning turns and visible tool calls, but +34% tokens and +26% monetary cost; gains are largest on visual/open-ended questions.
Significance. If the six-group taxonomy reliably isolates accuracy-preserving efficiency gains, the protocol supplies a concrete multi-axis evaluation framework that scalar accuracy cannot provide and that is directly applicable to other tool-augmented agents. The open code release strengthens reproducibility.
major comments (1)
- [Abstract / §3] Abstract and §3 (protocol definition): the central claim that the six-group taxonomy 'separates accuracy-preserving efficiency gains from harmful regressions' rests on Δ visible tool calls as the efficiency axis. Yet the reported results show visible tool calls fall 28% while token count rises 34% and monetary cost rises 26%. If the 'efficiency-gain' cells contain cases whose token or dollar cost is nevertheless higher, the taxonomy does not perform the separation asserted and cannot underwrite the multi-axis profile.
minor comments (2)
- [Abstract] The abstract states 'residual failures concentrate on hard, open-ended questions where the pipeline does the most work' but does not define the hardness metric or show the supporting breakdown; a table or figure would clarify.
- [§4] Dataset details (SAGE-Bench question types, exclusion rules, exact pairing procedure) are referenced but not fully specified in the provided text; these belong in §4 or an appendix for replicability.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying this key point about the scope of the taxonomy. We respond below.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (protocol definition): the central claim that the six-group taxonomy 'separates accuracy-preserving efficiency gains from harmful regressions' rests on Δ visible tool calls as the efficiency axis. Yet the reported results show visible tool calls fall 28% while token count rises 34% and monetary cost rises 26%. If the 'efficiency-gain' cells contain cases whose token or dollar cost is nevertheless higher, the taxonomy does not perform the separation asserted and cannot underwrite the multi-axis profile.
Authors: The protocol defines the six groups using joint correctness and Δ visible tool calls because visible tool calls are the direct, observable proxy for the benefit of composite-tool synthesis (fewer invocations of registered composites). The abstract and §3 therefore state that the taxonomy separates accuracy-preserving efficiency gains (correct + fewer calls) from harmful regressions (incorrect + more calls) along this axis. Token count and monetary cost are reported separately as part of the multi-axis profile precisely to show that cost is shifted rather than reduced overall. The referee is correct that the group definitions do not incorporate token or dollar costs, so the manuscript does not demonstrate that every case in the efficiency-gain cells has lower token or dollar cost. We will revise the abstract and §3 to state explicitly that the taxonomy isolates tool-call efficiency while the remaining cost dimensions are analyzed independently; we will also add a sentence noting the absence of per-group token-cost breakdowns. revision: yes
Circularity Check
No circularity: protocol and results are defined independently of fitted inputs or self-referential reductions
full rationale
The paper proposes an auditing protocol that pairs systems, sorts outcomes into six groups by joint correctness and Δ visible tool calls, then applies McNemar's test and paired bootstrap intervals. These steps are definitional choices for the new method, not reductions of any claimed result to its own inputs by construction. Reported differences (accuracy +7.5, tool calls -28%, tokens +34%) are direct empirical outputs from SAGE-Bench data; no equations, fitted parameters, or self-citation chains equate the multi-axis profile to quantities defined by the authors' prior work. The evaluation is self-contained against the external benchmark and standard tests.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math McNemar's test and paired bootstrap confidence intervals are appropriate statistical tools for comparing paired system outcomes on the same questions.
Reference graph
Works this paper leans on
-
[1]
Introducing Claude Opus 4.6.https://www
Anthropic. Introducing Claude Opus 4.6.https://www. anthropic.com/news/claude-opus-4-6, 2026
2026
-
[2]
Video question answering with procedural programs
Rohan Choudhury, Koichiro Niinuma, Kris M Kitani, and L´aszl´o A Jeni. Video question answering with procedural programs. InEuropean Conference on Computer Vision, pages 315–332. Springer, 2024. 8
2024
-
[3]
Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
2026
-
[4]
Videoagent: A memory-augmented mul- timodal agent for video understanding
Yue Fan, Xiaojian Ma, Rujie Wu, Yuntao Du, Jiaqi Li, Zhi Gao, and Qing Li. Videoagent: A memory-augmented mul- timodal agent for video understanding. InEuropean Confer- ence on Computer Vision, pages 75–92. Springer, 2024
2024
-
[5]
Visual program- ming: Compositional visual reasoning without training
Tanmay Gupta and Aniruddha Kembhavi. Visual program- ming: Compositional visual reasoning without training. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 14953–14962, 2023
2023
-
[6]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Sage: Train- ing smart any-horizon agents for long video reasoning with reinforcement learning
Jitesh Jain, Jialuo Li, Zixian Ma, Jieyu Zhang, Chris Dongjoo Kim, Sangho Lee, Rohun Tripathi, Tanmay Gupta, Christopher Clark, Humphrey Shi, et al. Sage: Train- ing smart any-horizon agents for long video reasoning with reinforcement learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 41478–41488, 2026
2026
-
[8]
Tvqa: Localized, compositional video question answering
Jie Lei, Licheng Yu, Mohit Bansal, and Tamara Berg. Tvqa: Localized, compositional video question answering. InPro- ceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 1369–1379, 2018
2018
-
[9]
Tvqa+: Spatio-temporal grounding for video question answering
Jie Lei, Licheng Yu, Tamara Berg, and Mohit Bansal. Tvqa+: Spatio-temporal grounding for video question answering. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8211–8225, 2020
2020
-
[10]
Llama-vid: An image is worth 2 tokens in large language models
Yanwei Li, Chengyao Wang, and Jiaya Jia. Llama-vid: An image is worth 2 tokens in large language models. In European Conference on Computer Vision, pages 323–340. Springer, 2024
2024
-
[11]
Video-llava: Learning united visual repre- sentation by alignment before projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual repre- sentation by alignment before projection. InProceedings of the 2024 Conference on Empirical Methods in Natural Lan- guage Processing, pages 5971–5984, 2024
2024
-
[12]
Egoschema: A diagnostic benchmark for very long- form video language understanding.Advances in Neural In- formation Processing Systems, 36:46212–46244, 2023
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long- form video language understanding.Advances in Neural In- formation Processing Systems, 36:46212–46244, 2023
2023
-
[13]
Visual agentic ai for spatial reasoning with a dynamic api
Damiano Marsili, Rohun Agrawal, Yisong Yue, and Geor- gia Gkioxari. Visual agentic ai for spatial reasoning with a dynamic api. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19446–19455, 2025
2025
-
[14]
Morevqa: Exploring modular reason- ing models for video question answering
Juhong Min, Shyamal Buch, Arsha Nagrani, Minsu Cho, and Cordelia Schmid. Morevqa: Exploring modular reason- ing models for video question answering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13235–13245, 2024
2024
-
[15]
Tony Montes and Fernando Lozano. Viqagent: Zero-shot video question answering via agent with open-vocabulary grounding validation.arXiv preprint arXiv:2505.15928, 2025
-
[16]
Minerva: Evaluating complex video reasoning
Arsha Nagrani, Sachit Menon, Ahmet Iscen, Shyamal Buch, Ramin Mehran, Nilpa Jha, Anja Hauth, Yukun Zhu, Carl V ondrick, Mikhail Sirotenko, et al. Minerva: Evaluating complex video reasoning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 23968– 23978, 2025
2025
-
[17]
Vipergpt: Visual inference via python execution for reasoning
D ´ıdac Sur´ıs, Sachit Menon, and Carl V ondrick. Vipergpt: Visual inference via python execution for reasoning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 11888–11898, 2023
2023
-
[18]
Qwen3 technical report, 2025
Qwen Team. Qwen3 technical report, 2025
2025
-
[19]
Longvideobench: A benchmark for long-context interleaved video-language understanding.Advances in Neural Informa- tion Processing Systems, 37:28828–28857, 2024
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. Longvideobench: A benchmark for long-context interleaved video-language understanding.Advances in Neural Informa- tion Processing Systems, 37:28828–28857, 2024
2024
-
[20]
Next-qa: Next phase of question-answering to explaining temporal actions
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. Next-qa: Next phase of question-answering to explaining temporal actions. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 9777–9786, 2021
2021
-
[21]
Video-llama: An instruction-tuned audio-visual language model for video un- derstanding
Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video un- derstanding. InProceedings of the 2023 Conference on Em- pirical Methods in Natural Language Processing: System Demonstrations, pages 543–553, 2023. 9 S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 This appendix is organized around the same multi-axis argument...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.