MVFusion-GS: Motion-Variance Guided Temporal Attention for High-Quality Dynamic Gaussian Splatting
Pith reviewed 2026-07-03 17:09 UTC · model grok-4.3
The pith
Adding explicit motion awareness to deformation networks improves accuracy in dynamic 3D Gaussian Splatting for both moving objects and static backgrounds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
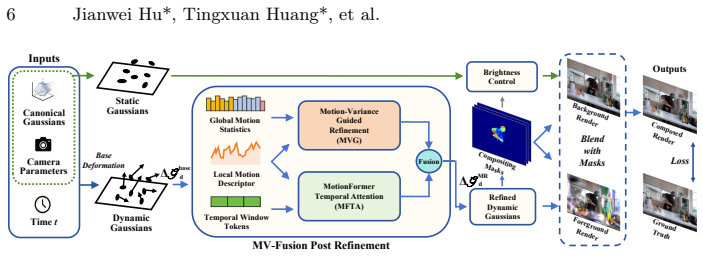
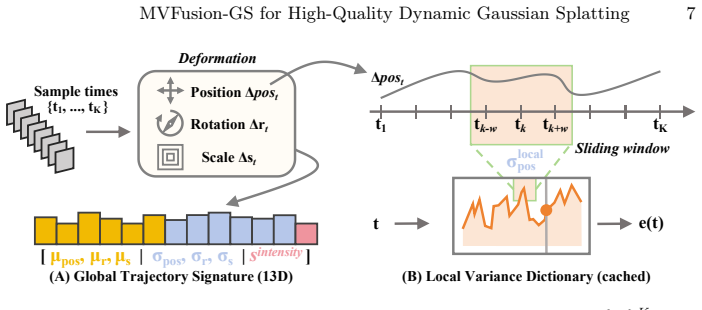
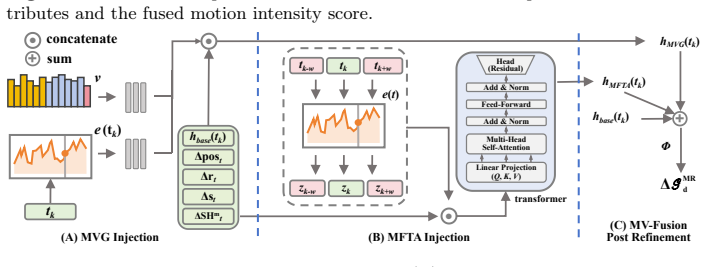
MVFusion-GS enhances deformation networks by aggregating per-Gaussian deformation statistics across time to compute motion variance for guiding dynamic-static separation, and by applying Transformer self-attention over neighboring timesteps to capture local motion dependencies, resulting in more accurate foreground deformation and reduced pseudo-static residuals in the background.
What carries the argument
Motion-Variance Guided Refinement, which uses time-aggregated deformation statistics to estimate motion variance and direct separation, and MotionFormer Temporal Attention, which models dependencies via self-attention across timesteps.
If this is right
- More accurate deformation for moving foreground objects.
- Cleaner reconstruction of static background regions without pseudo-residuals.
- Improved temporal consistency in rendered dynamic scenes.
- State-of-the-art results on dynamic scene reconstruction benchmarks.
- Effective distractor-free reconstruction by better handling motion.
Where Pith is reading between the lines
- Similar motion variance signals could be tested in other neural rendering frameworks beyond Gaussian Splatting.
- The approach might extend to longer-range temporal modeling if attention is scaled up.
- Real-time performance could be evaluated by measuring the added computational cost of the attention module.
- Application to scenes with multiple independent moving objects would test the robustness of the variance estimation.
Load-bearing premise
The assumption that per-Gaussian deformation statistics aggregated over time provide a reliable indicator of motion variance that correctly separates dynamic and static content.
What would settle it
A controlled experiment where the motion variance signal is replaced with random values or noise and performance does not degrade would falsify the claim that the guidance is effective.
Figures








read the original abstract
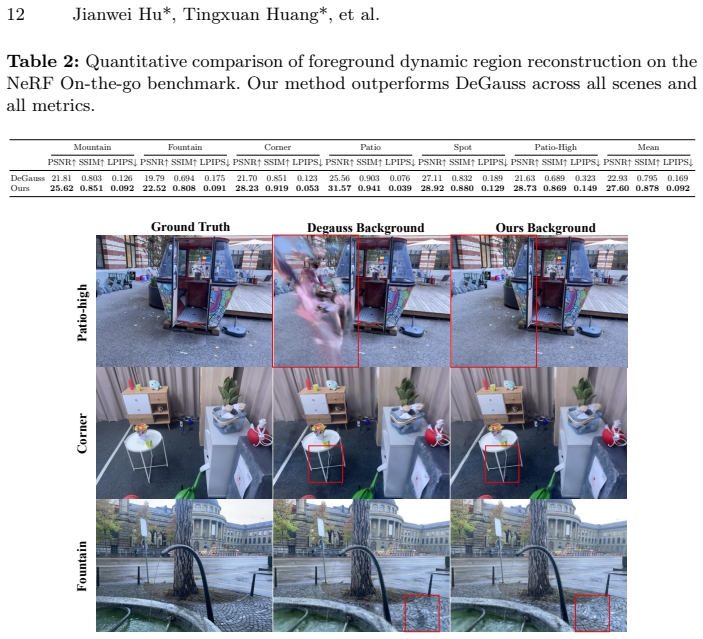
3D Gaussian Splatting (3DGS) enables real-time novel view synthesis for static scenes. Extending it to dynamic scenes via deformation fields has recently attracted significant attention, particularly for dynamic scene reconstructionband distractor-free. However, existing deformation networks lack explicit motion awareness: they neither capture long-term motion intensity nor exploit short-term temporal coherence, leading to inaccurate foreground deformation and pseudo-static residuals in the background. We present MVFusion-GS, a method that enhances deformation networks with two complementary motion-aware mechanisms. The Motion-Variance Guided Refinement aggregates per-Gaussian deformation statistics across time to estimate motion variance and uses it to guide dynamic-static separation during deformation prediction. The MotionFormer Temporal Attention module applies Transformer self-attention over neighboring timesteps to model local motion dependencies and improve temporal consistency. Extensive experiments on both dynamic scene reconstruction and distractor-free reconstruction benchmarks demonstrate state-of-the-art performance, showing that explicit motion awareness improves both foreground motion modeling and static background reconstruction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MVFusion-GS to extend 3D Gaussian Splatting to dynamic scenes by augmenting deformation networks with two motion-aware components: Motion-Variance Guided Refinement, which aggregates per-Gaussian deformation statistics over time to estimate motion variance and guide dynamic-static separation, and MotionFormer Temporal Attention, which applies Transformer self-attention across neighboring timesteps to capture local motion dependencies. The central claim is that these explicit mechanisms yield more accurate foreground deformation and cleaner static backgrounds, supported by state-of-the-art results on dynamic scene reconstruction and distractor-free benchmarks.
Significance. If the motion-variance signal proves robust and the temporal attention demonstrably reduces artifacts without introducing new ones, the approach could meaningfully advance dynamic novel-view synthesis by providing a principled way to separate motion intensity from deformation fitting. The explicit separation of long-term variance and short-term coherence is a clear conceptual contribution over prior deformation-field methods.
major comments (2)
- [Method (Motion-Variance Guided Refinement)] Method section (Motion-Variance Guided Refinement): the description of aggregating deformation statistics to produce the variance signal does not specify whether the statistics are taken from a fixed initial deformation field, an iterative bootstrap, or the jointly optimized network; without this, the separation signal and the deformation parameters can co-adapt, undermining the claim that explicit motion awareness improves foreground/background modeling.
- [Experiments] Experiments (dynamic scene reconstruction benchmarks): the reported gains are presented without ablation isolating the contribution of the variance-guided separation versus the temporal attention module, and without error bars or multiple random seeds, making it impossible to assess whether the SOTA claim is load-bearing or sensitive to initialization.
minor comments (2)
- [Abstract / §2] The abstract and introduction use the phrase 'distractor-free reconstruction' without a precise definition or citation to the benchmark protocol; this should be clarified in §2 or the experimental setup.
- [Method] Notation for the per-Gaussian deformation statistics (e.g., how variance is normalized across time) is introduced without an equation; adding a compact definition would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important points on methodological clarity and experimental rigor that we will address in the revision.
read point-by-point responses
-
Referee: [Method (Motion-Variance Guided Refinement)] Method section (Motion-Variance Guided Refinement): the description of aggregating deformation statistics to produce the variance signal does not specify whether the statistics are taken from a fixed initial deformation field, an iterative bootstrap, or the jointly optimized network; without this, the separation signal and the deformation parameters can co-adapt, undermining the claim that explicit motion awareness improves foreground/background modeling.
Authors: We agree that the current description leaves the source of the deformation statistics unspecified, which is a valid concern regarding potential co-adaptation. In the revised manuscript we will update Section 3.2 to explicitly state that the per-Gaussian deformation statistics are collected from a fixed initial deformation field obtained via a short bootstrap optimization phase; this field is then frozen when computing the motion-variance signal that guides the subsequent joint optimization. This change directly addresses the co-adaptation issue while preserving the overall architecture. revision: yes
-
Referee: [Experiments] Experiments (dynamic scene reconstruction benchmarks): the reported gains are presented without ablation isolating the contribution of the variance-guided separation versus the temporal attention module, and without error bars or multiple random seeds, making it impossible to assess whether the SOTA claim is load-bearing or sensitive to initialization.
Authors: We acknowledge that the experiments do not isolate the individual contributions of Motion-Variance Guided Refinement and MotionFormer Temporal Attention, nor do they report error bars or multi-seed statistics. In the revised version we will add a dedicated ablation table that evaluates each module independently on the dynamic reconstruction and distractor-free benchmarks. We will also rerun the primary quantitative results across three random seeds and report mean and standard deviation to substantiate the robustness of the SOTA claims. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces explicit motion-aware mechanisms (Motion-Variance Guided Refinement and MotionFormer Temporal Attention) as architectural additions to deformation networks, with performance claims supported by benchmark experiments rather than any reduction of outputs to inputs by definition, fitted parameters renamed as predictions, or load-bearing self-citations. No equations or sections in the provided text exhibit self-definitional loops, ansatzes smuggled via prior work, or renaming of known results. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Attal, B., Huang, J.B., Richardt, C., Zollhoefer, M., Kopf, J., O’Toole, M., Kim, C.: Hyperreel: High-fidelity 6-dof video with ray-conditioned sampling. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16610–16620 (2023)
2023
-
[2]
In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR)
Cao, A., Johnson, J.: HexPlane: A fast representation for dynamic scenes. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR). pp. 130–141 (June 2023)
2023
-
[3]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Chen, Z., Funkhouser, T., Hedman, P., Tagliasacchi, A.: MobileNeRF: Exploiting the polygon rasterization pipeline for efficient neural field rendering on mobile architectures. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 16569–16578 (2023)
2023
-
[4]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Fridovich-Keil, S., Meanti, G., Warburg, F.R., Recht, B., Kanazawa, A.: K-planes: Explicit radiance fields in space, time, and appearance. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12479– 12488 (2023)
2023
-
[5]
In: ACM SIGGRAPH 2024 Conference Papers
Huang,B.,Yu,Z.,Chen,A.,Geiger,A.,Gao,S.:2dgaussiansplattingforgeometri- cally accurate radiance fields. In: ACM SIGGRAPH 2024 Conference Papers. SIG- GRAPH ’24, Association for Computing Machinery, New York, NY, USA (2024). https://doi.org/10.1145/3641519.3657428
-
[6]
In: The Fourteenth International Conference on Learning Representations
Huang, T., Zhu, H., Yong, J.H., Pan, H., Wang, B.: Mango-GS: Enhancing spatio- temporal consistency in dynamic scenes reconstruction using multi-frame node- guided 4d gaussian splatting. In: The Fourteenth International Conference on Learning Representations
-
[7]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Huang, Y.H., Sun, Y.T., Yang, Z., Lyu, X., Cao, Y.P., Qi, X.: SC-GS: Sparse- controlled gaussian splatting for editable dynamic scenes. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4220–4230 (2024)
2024
-
[8]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Jiang, D., Hou, Z., Ke, Z., Yang, X., Zhou, X., Qiu, T.: Timeformer: Capturing temporal relationships of deformable 3d gaussians for robust reconstruction. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 8721–8732 (2025)
2025
-
[9]
ACM Transactions on Graphics42(4) (2023), https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics42(4) (2023), https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
2023
-
[10]
In: Proceedings of the 38th International Conference on Neural Information Processing Systems (2024)
Kulhanek, J., Peng, S., Kukelova, Z., Pollefeys, M., Sattler, T.: WildGaussians: 3D gaussian splatting in the wild. In: Proceedings of the 38th International Conference on Neural Information Processing Systems (2024)
2024
-
[11]
In: ACM SIGGRAPH2024ConferencePapers(2024).https://doi.org/10.1145/3641519
Li, D., Huang, S.S., Lu, Z., Duan, X., Huang, H.: ST-4DGS: Spatial-temporally consistent 4d gaussian splatting for efficient dynamic scene rendering. In: ACM SIGGRAPH2024ConferencePapers(2024).https://doi.org/10.1145/3641519. 3657520
-
[12]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, T., Slavcheva, M., Zollhöfer, M., Green, S., Lassner, C., Kim, C., Schmidt, T., Lovegrove, S., Goesele, M., Newcombe, R., Lv, Z.: Neural 3d video synthesis from multi-view video. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5521–5531 (June 2022)
2022
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Li, Z., Chen, Z., Li, Z., Xu, Y.: Spacetime gaussian feature splatting for real- time dynamic view synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 8508–8520 (June 2024) MVFusion-GS for High-Quality Dynamic Gaussian Splatting 17
2024
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Lu, T., Yu, M., Xu, L., Xiangli, Y., Wang, L., Lin, D., Dai, B.: Scaffold-gs: Struc- tured 3d gaussians for view-adaptive rendering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 20654–20664 (2024)
2024
-
[15]
In: CVPR (2021)
Martin-Brualla, R., Radwan, N., Sajjadi, M.S.M., Barron, J.T., Dosovitskiy, A., Duckworth, D.: NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections. In: CVPR (2021)
2021
-
[16]
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: representing scenes as neural radiance fields for view synthesis. Commun. ACM65(1), 99–106 (Dec 2021).https://doi.org/10.1145/3503250
-
[17]
ACM Transactions on Graphics41(4), 102:1– 102:15 (2022).https://doi.org/10.1145/3528223.3530127
Müller,T.,Evans,A.,Schied,C.,Keller,A.:Instantneuralgraphicsprimitiveswith a multiresolution hash encoding. ACM Transactions on Graphics41(4), 102:1– 102:15 (2022).https://doi.org/10.1145/3528223.3530127
-
[18]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Park, J.J., Florence, P., Straub, J., Newcombe, R., Lovegrove, S.: DeepSDF: Learn- ing continuous signed distance functions for shape representation. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 165–174 (2019)
2019
-
[19]
In: Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR)
Park, J., Bui, M.Q.V., Bello, J.L.G., Moon, J., Oh, J., Kim, M.: SplineGS: Ro- bust motion-adaptive spline for real-time dynamic 3d gaussians from monocular video. In: Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR). pp. 26866–26875 (June 2025)
2025
-
[20]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Ren, W., Zhu, Z., Sun, B., Chen, J., Pollefeys, M., Peng, S.: NeRF On-the-go: Exploiting uncertainty for distractor-free nerfs in the wild. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 8931–8940 (June 2024)
2024
-
[21]
ACM Trans
Sabour, S., Goli, L., Kopanas, G., Matthews, M., Lagun, D., Guibas, L., Jacobson, A., Fleet, D., Tagliasacchi, A.: Spotlesssplats: Ignoring distractors in 3d gaussian splatting. ACM Trans. Graph.44(2) (Apr 2025).https://doi.org/10.1145/ 3727143
2025
-
[22]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Sabour, S., Vora, S., Duckworth, D., Krasin, I., Fleet, D.J., Tagliasacchi, A.: RobustNeRF: Ignoring distractors with robust losses. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 20626–20636 (June 2023)
2023
-
[23]
In: European Conference on Computer Vision
Shaw, R., Nazarczuk, M., Song, J., Moreau, A., Catley-Chandar, S., Dhamo, H., Pérez-Pellitero, E.: Swings: sliding windows for dynamic 3d gaussian splatting. In: European Conference on Computer Vision. pp. 37–54. Springer (2024)
2024
-
[24]
IEEE Transactions on Visualization and Computer Graphics29(5), 2732–2742 (2023)
Song, L., Chen, A., Li, Z., Chen, Z., Chen, L., Yuan, J., Xu, Y., Geiger, A.: Nerf- player: A streamable dynamic scene representation with decomposed neural radi- ance fields. IEEE Transactions on Visualization and Computer Graphics29(5), 2732–2742 (2023)
2023
-
[25]
In: SIGGRAPH Asia 2024 Conference Papers
Stearns, C., Harley, A.W., Uy, M., Dubost, F., Tombari, F., Wetzstein, G., Guibas, L.: Dynamic gaussian marbles for novel view synthesis of casual monocular videos. In: SIGGRAPH Asia 2024 Conference Papers. pp. 1–11 (2024)
2024
-
[26]
Advances in neural information pro- cessing systems30(2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information pro- cessing systems30(2017)
2017
-
[27]
19706–19716 (2023)
Wang, F., Tan, S., Li, X., Tian, Z., Song, Y., Liu, H.: Mixed neural voxels for fast multi-view video synthesis pp. 19706–19716 (2023)
2023
-
[28]
In: International Conference on Computer Vision (ICCV) (2025) 18 Jianwei Hu*, Tingxuan Huang*, et al
Wang, Q., Ye, V., Gao, H., Zeng, W., Austin, J., Li, Z., Kanazawa, A.: Shape of motion: 4d reconstruction from a single video. In: International Conference on Computer Vision (ICCV) (2025) 18 Jianwei Hu*, Tingxuan Huang*, et al
2025
-
[29]
In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Wang, R., Lohmeyer, Q., Meboldt, M., Tang, S.: DeGauss: Dynamic-static decom- position with gaussian splatting for distractor-free 3d reconstruction. In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 6294–6303 (October 2025)
2025
-
[30]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Wang, Y., Yang, P., Xu, Z., Sun, J., Zhang, Z., Chen, Y., Bao, H., Peng, S., Zhou, X.: FreeTimeGS: Free gaussian primitives at anytime anywhere for dynamic scene reconstruction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 21750–21760 (2025)
2025
-
[31]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Wang, Y., Klasson, M., Turkulainen, M., Wang, S., Kannala, J., Solin, A.: DeSplat: Decomposed gaussian splatting for distractor-free rendering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 722–732 (June 2025)
2025
-
[32]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Wu, G., Yi, T., Fang, J., Xie, L., Zhang, X., Wei, W., Liu, W., Tian, Q., Wang, X.: 4d gaussian splatting for real-time dynamic scene rendering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 20310–20320 (June 2024)
2024
-
[33]
In: Proceedings of the 36th International Conference on Neural Information Processing Systems
Wu, T., Zhong, F., Tagliasacchi, A., Cole, F., Oztireli, C.: D2NeRF: self-supervised decoupling of dynamic and static objects from a monocular video. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. NIPS ’22, Curran Associates Inc., Red Hook, NY, USA (2022)
2022
-
[34]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Yang, Z., Gao, X., Zhou, W., Jiao, S., Zhang, Y., Jin, X.: Deformable 3d gaussians for high-fidelity monocular dynamic scene reconstruction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 20331–20341 (2024)
2024
-
[35]
Yariv, L., Gu, J., Kasten, Y., Lipman, Y.: Volume rendering of neural implicit surfaces. In: Advances in Neural Information Processing Systems (NeurIPS) (2021) MVFusion-GS for High-Quality Dynamic Gaussian Splatting 19 Supplementary Material In this supplementary material, we provide additional implementation details, experiments and analyses to complemen...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.