DRDN: Decoupled Representation Dynamic Network for From-Scratch ViT Class-Incremental Learning
Pith reviewed 2026-07-03 16:56 UTC · model grok-4.3
The pith
Continuous masked image modeling on the backbone plus hierarchical task token expansion lets Vision Transformers learn new classes from scratch while retaining old ones better.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
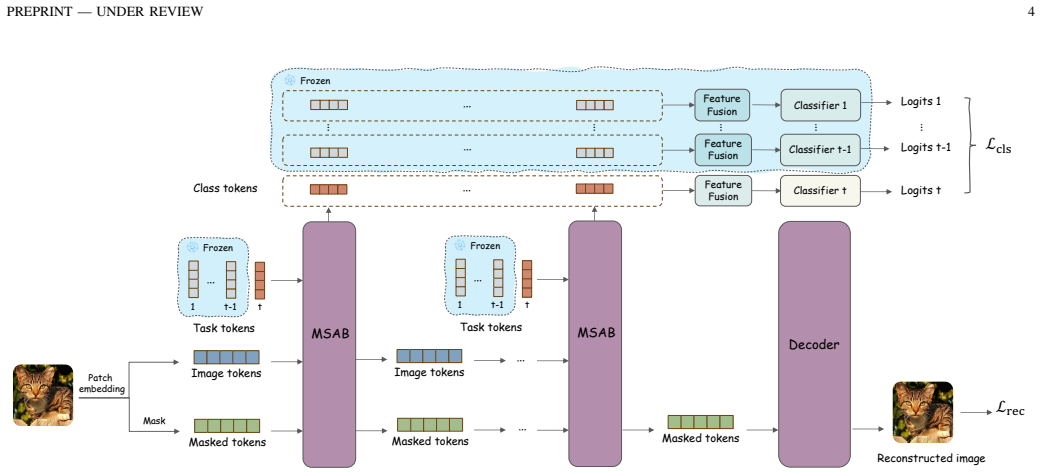
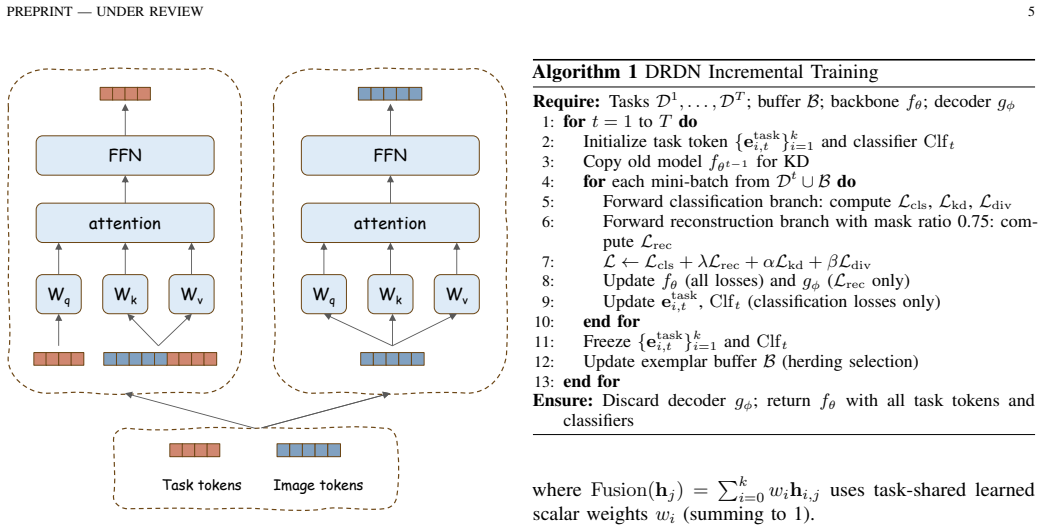
DRDN continuously applies masked image modeling at every incremental step with reconstruction gradients routed exclusively through the backbone to retain general visual structure, while employing hierarchical task token expansion across all transformer layers with a modified per-task attention rule to reduce inter-task interference; this yields higher average accuracy than token-expansion baselines on from-scratch ViT CIL benchmarks, with the gap widening on longer sequences.
What carries the argument
The decoupled representation mechanism that routes masked image modeling reconstruction gradients exclusively through the backbone while expanding task-specific tokens hierarchically across layers.
If this is right
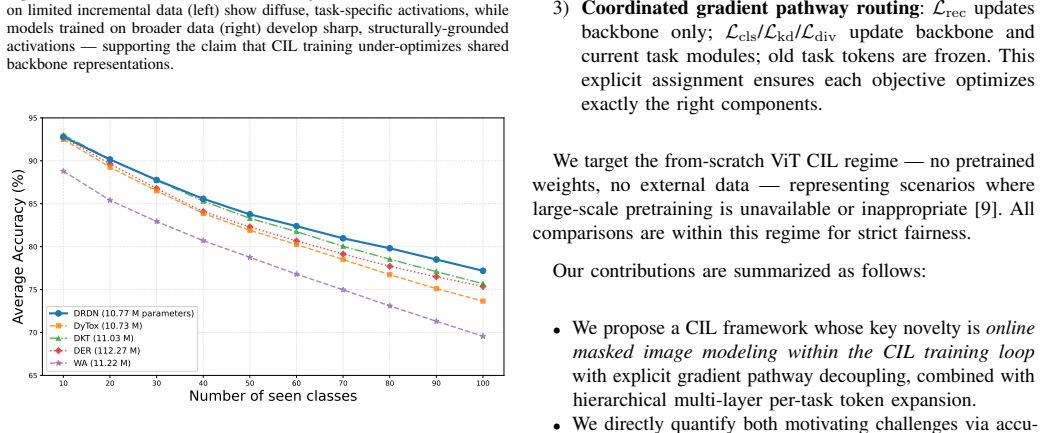
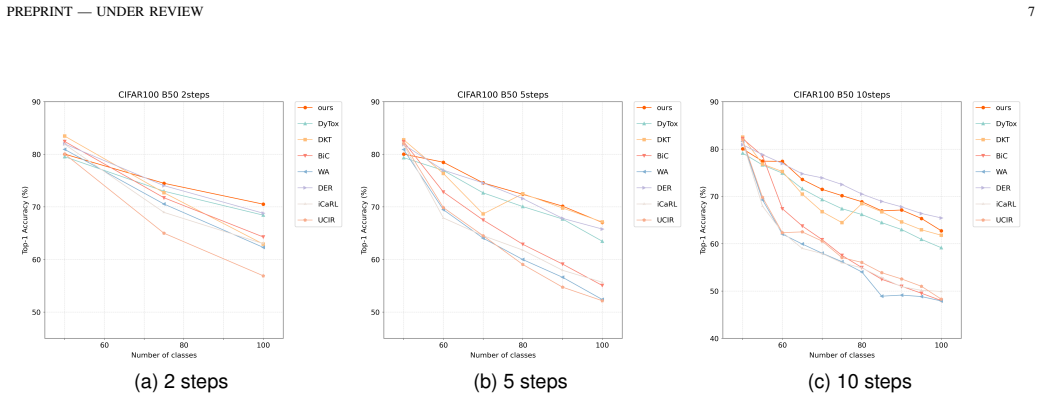
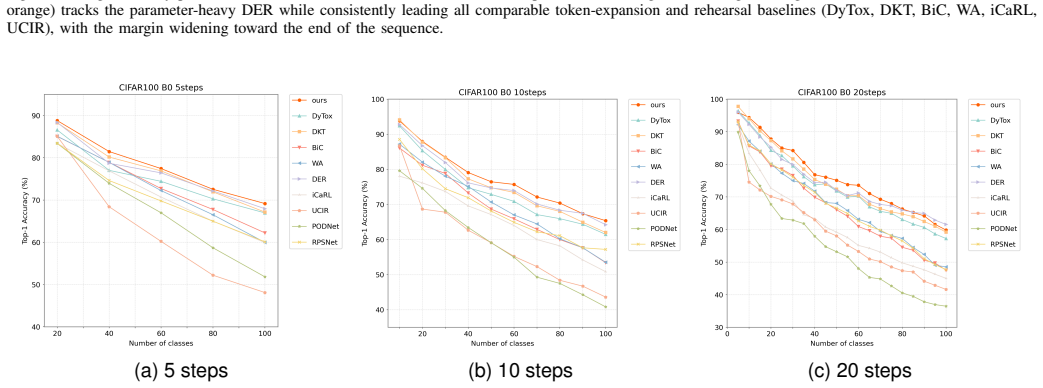
- On CIFAR100-B0 with 10 steps, average accuracy reaches 77.19 percent, exceeding DKT by 1.36 points and DyTox by 3.53 points.
- The performance edge increases as the number of incremental steps grows.
- Multi-seed runs show stability within plus or minus 0.31 percent.
- The MIM decoder adds parameters and computation only during training, leaving inference unchanged.
Where Pith is reading between the lines
- The separation of reconstruction and classification objectives could apply to other incremental settings where shared features degrade over time.
- Hierarchical token expansion might reduce interference in non-ViT architectures if adapted similarly.
- Longer task sequences would likely amplify the benefit, suggesting the method scales with problem size.
Load-bearing premise
Continuously applying masked image modeling with gradients routed only through the backbone will preserve task-agnostic shared representations sufficiently to improve discriminability as tasks accumulate.
What would settle it
A controlled ablation removing the masked image modeling component on CIFAR100-B0 with 20 steps, where the accuracy advantage over DKT and DyTox vanishes or reverses, would falsify the central claim.
Figures

read the original abstract
Dynamic expansion methods for class-incremental learning (CIL) protect task-specific knowledge by growing dedicated tokens or subnetworks, yet our analyses suggest that classification supervision alone does not sufficiently preserve task-agnostic shared backbone representations over long incremental sequences. We identify two intertwined challenges: cross-task confusion from sequential training on predominantly current-task data, which biases decision boundaries toward recent tasks; and under-optimized shared representations in the backbone that cap long-term discriminability as tasks accumulate. We propose the Decoupled Representation Dynamic Network (DRDN), which addresses these challenges via two orthogonal mechanisms. For shared backbone representations, DRDN continuously applies masked image modeling (MIM) at every incremental step, with reconstruction gradients routed exclusively through the backbone, encouraging it to retain general visual structure beyond class-discriminative cues. For task-specific discrimination, DRDN employs hierarchical task token expansion across all transformer layers, with a modified per-task attention rule that reduces inter-task interference. We support this design with accuracy degradation analysis and cross-task confusion rate measurements. In the from-scratch ViT CIL setting (no external pretraining), DRDN consistently improves over strong token-expansion baselines with comparable backbone scale. On CIFAR100-B0 (10 steps), DRDN achieves 77.19% average accuracy, outperforming DKT by 1.36 points and DyTox by 3.53 points, with an advantage that grows at longer incremental sequences. Multi-seed validation confirms stability (+/-0.31%). The MIM decoder is active only during training, adding no inference-time parameters or computation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in from-scratch ViT class-incremental learning, standard classification supervision fails to preserve task-agnostic shared backbone representations, causing cross-task confusion and degraded long-term discriminability. It proposes DRDN, which applies continuous masked image modeling (MIM) at each incremental step with reconstruction gradients routed only through the backbone, combined with hierarchical task token expansion across transformer layers and a modified per-task attention rule to reduce interference. Supported by accuracy degradation and cross-task confusion analyses, DRDN reports 77.19% average accuracy on CIFAR100-B0 (10 steps), outperforming DKT by 1.36 points and DyTox by 3.53 points, with larger gains on longer sequences, multi-seed stability, and no added inference cost.
Significance. If the central attribution holds, the work would be significant for from-scratch ViT CIL by demonstrating that explicit MIM-based preservation of shared representations can complement token-expansion methods and improve scaling to longer task sequences. The zero-inference-overhead design and multi-seed validation (+/-0.31%) are concrete strengths. However, the significance is limited by the absence of component-isolation experiments, which leaves open whether the reported gains stem from the MIM mechanism, the attention modification, or their interaction.
major comments (1)
- [Abstract / method description] Abstract and method description: The central claim attributes the 1.36-point and 3.53-point gains (and the growing advantage on longer sequences) to continuous MIM preserving task-agnostic backbone representations. However, DRDN also introduces a modified per-task attention rule within the hierarchical token expansion. No ablation is described that disables only the MIM loss while retaining the modified attention and token expansion, so the improvements cannot be securely attributed to the decoupled-representation mechanism rather than the attention change.
minor comments (2)
- [Abstract] Abstract: The supporting analyses (accuracy degradation and cross-task confusion rates) are mentioned but not quantified or compared to baselines; explicit numbers, tables, or statistical significance tests for these diagnostics would strengthen the evidence.
- [Abstract] Abstract: Experimental details are absent (baseline re-implementation, fixed vs. tuned hyperparameters, data splits, number of runs beyond the multi-seed note). These are needed to assess whether the 1.36/3.53-point margins are robust.
Simulated Author's Rebuttal
We thank the referee for highlighting the need to more rigorously isolate the contribution of the continuous MIM mechanism from the modified per-task attention rule. We agree that the current experiments do not fully separate these components and will add the requested ablation in the revision to strengthen attribution of the reported gains.
read point-by-point responses
-
Referee: [Abstract / method description] Abstract and method description: The central claim attributes the 1.36-point and 3.53-point gains (and the growing advantage on longer sequences) to continuous MIM preserving task-agnostic backbone representations. However, DRDN also introduces a modified per-task attention rule within the hierarchical token expansion. No ablation is described that disables only the MIM loss while retaining the modified attention and token expansion, so the improvements cannot be securely attributed to the decoupled-representation mechanism rather than the attention change.
Authors: We acknowledge that the manuscript does not include an ablation that removes only the MIM loss while retaining the hierarchical token expansion and modified per-task attention rule. The modified attention rule is introduced specifically to reduce inter-task interference within the expanded token structure, but the central hypothesis concerns the MIM-driven preservation of shared backbone representations. In the revised version we will add an ablation study that trains the full DRDN architecture (including token expansion and modified attention) but disables the MIM reconstruction loss. This will directly compare performance with and without MIM under otherwise identical conditions, allowing clearer attribution of the gains on CIFAR100-B0 and longer sequences. We will also report the corresponding cross-task confusion rates for this variant. revision: yes
Circularity Check
No circularity in empirical method or reported results
full rationale
The paper presents an empirical architecture (DRDN) for class-incremental learning and reports benchmark accuracies (e.g., 77.19% on CIFAR100-B0) without any equations, derivations, or parameter-fitting steps that reduce a claimed prediction to its own inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in the provided text to justify core claims; the design choices are motivated by analysis of cross-task confusion and then validated experimentally. The absence of any load-bearing mathematical reduction or fitted-input-as-prediction pattern makes the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Catastrophic interference in connec- tionist networks: The sequential learning problem,
M. McCloskey and N. J. Cohen, “Catastrophic interference in connec- tionist networks: The sequential learning problem,” inPsychology of Learning and Motivation. Elsevier, 1989, vol. 24, pp. 109–165
1989
-
[2]
An empirical investigation of catastrophic forgetting in gradient-based neural networks,
I. J. Goodfellow, M. Mirza, A. Courville, and Y . Bengio, “An empirical investigation of catastrophic forgetting in gradient-based neural networks,” inICLR Workshop, 2014
2014
-
[3]
Der: Dynamically expandable representation for class incremental learning,
S. Yan, J. Xie, and X. He, “Der: Dynamically expandable representation for class incremental learning,” inCVPR, 2021, pp. 3014–3023
2021
-
[4]
Dytox: Transformers for continual learning with dynamic token expansion,
A. Douillard, A. Ram ´e, G. Couairon, and M. Cord, “Dytox: Transformers for continual learning with dynamic token expansion,” inCVPR, 2022, pp. 9285–9295
2022
-
[5]
Dkt: Diverse knowledge transfer transformer for class incremental learning,
X. Gao, Y . He, S. Dong, J. Cheng, X. Wei, and Y . Gong, “Dkt: Diverse knowledge transfer transformer for class incremental learning,” inCVPR, 2023, pp. 24 236–24 245
2023
-
[6]
Resolving task confu- sion in dynamic expansion architectures for class incremental learning,
B. Huang, Z. Chen, P. Zhou, J. Chen, and Z. Wu, “Resolving task confu- sion in dynamic expansion architectures for class incremental learning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 1, 2023, pp. 908–916
2023
-
[7]
BEEF: Bi-compatible class-incremental learning via energy- based expansion and fusion,
F.-Y . Wang, D.-W. Zhou, L. Liu, H.-J. Ye, Y . Bian, D.-C. Zhan, and P. Zhao, “BEEF: Bi-compatible class-incremental learning via energy- based expansion and fusion,” inICLR, 2023
2023
-
[8]
Semantic relatedness emerges in deep convolutional neural networks designed for object recognition,
T. Huang, Z. Zhen, and J. Liu, “Semantic relatedness emerges in deep convolutional neural networks designed for object recognition,”Frontiers in Computational Neuroscience, vol. 15, p. 625804, 2021
2021
-
[9]
When prompt-based incremental learning does not meet strong pretraining,
Y .-M. Tang, Y .-X. Peng, and W.-S. Zheng, “When prompt-based incremental learning does not meet strong pretraining,” inICCV, 2023, pp. 1706–1716
2023
-
[10]
A. A. Rusu, N. C. Rabinowitz, G. Desjardins, H. Soyer, J. Kirkpatrick, K. Kavukcuoglu, R. Pascanu, and R. Hadsell, “Progressive neural networks,”arXiv preprint arXiv:1606.04671, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[11]
Lifelong Learning with Dynamically Expandable Networks
J. Yoon, E. Yang, J. Lee, and S. J. Hwang, “Lifelong learning with dynamically expandable networks,”arXiv preprint arXiv:1708.01547, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
Reinforced continual learning,
J. Xu and Z. Zhu, “Reinforced continual learning,”NeurIPS, vol. 31, 2018
2018
-
[13]
Dense network expansion for class incremental learning,
Z. Hu, Y . Li, J. Lyu, D. Gao, and N. Vasconcelos, “Dense network expansion for class incremental learning,” inCVPR, 2023, pp. 11 858– 11 867
2023
-
[14]
Loss decoupling for task-agnostic continual learning,
Y .-S. Liang and W.-J. Li, “Loss decoupling for task-agnostic continual learning,” inNeurIPS, vol. 36, 2023, pp. 11 151–11 167
2023
-
[15]
On the stability-plasticity dilemma of class- incremental learning,
D. Kim and B. Han, “On the stability-plasticity dilemma of class- incremental learning,” inCVPR, 2023, pp. 20 196–20 205
2023
-
[16]
Masked autoencoders are efficient class incremental learners,
J.-T. Zhai, X. Liu, J. van de Weijer, and M.-M. Cheng, “Masked autoencoders are efficient class incremental learners,” inICCV, 2023
2023
-
[17]
Masked autoencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick, “Masked autoencoders are scalable vision learners,” inCVPR, 2022, pp. 16 000– 16 009
2022
-
[18]
BEiT: BERT Pre-Training of Image Transformers
H. Bao, L. Dong, S. Piao, and F. Wei, “Beit: Bert pre-training of image transformers,”arXiv preprint arXiv:2106.08254, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[19]
Image bert pre-training with online tokenizer,
J. Zhou, C. Wei, H. Wang, W. Shen, C. Xie, A. Yuille, and T. Kong, “Image bert pre-training with online tokenizer,” inICLR, 2022
2022
-
[20]
Convnext v2: Co-designing and scaling convnets with masked autoencoders,
S. Woo, S. Debnath, R. Hu, X. Chen, Z. Liu, I. S. Kweon, and S. Xie, “Convnext v2: Co-designing and scaling convnets with masked autoencoders,” inCVPR, 2023, pp. 16 133–16 142
2023
-
[21]
icarl: Incremental classifier and representation learning,
S.-A. Rebuffi, A. Kolesnikov, G. Sperl, and C. H. Lampert, “icarl: Incremental classifier and representation learning,” inCVPR, 2017, pp. 2001–2010. PREPRINT — UNDER REVIEW 10
2017
-
[22]
Rainbow memory: Continual learning with a memory of diverse samples,
J. Bang, H. Kim, Y . Yoo, J.-W. Ha, and J. Choi, “Rainbow memory: Continual learning with a memory of diverse samples,” inCVPR, 2021, pp. 8218–8227
2021
-
[23]
Gradient based sample selection for online continual learning,
R. Aljundi, M. Lin, B. Goujaud, and Y . Bengio, “Gradient based sample selection for online continual learning,”NeurIPS, vol. 32, 2019
2019
-
[24]
Large scale incremental learning,
Y . Wu, Y . Chen, L. Wang, Y . Ye, Z. Liu, Y . Guo, and Y . Fu, “Large scale incremental learning,” inCVPR, 2019, pp. 374–382
2019
-
[25]
Maintaining discrimination and fairness in class incremental learning,
B. Zhao, X. Xiao, G. Gan, B. Zhang, and S.-T. Xia, “Maintaining discrimination and fairness in class incremental learning,” inCVPR, 2020, pp. 13 208–13 217
2020
-
[26]
Continual learning with deep generative replay,
H. Shin, J. K. Lee, J. Kim, and J. Kim, “Continual learning with deep generative replay,” vol. 30, 2017
2017
-
[27]
Class-incremental learning using diffusion model for distillation and replay,
Q. Jodelet, X. Liu, Y . J. Phua, and T. Murata, “Class-incremental learning using diffusion model for distillation and replay,” inICCV, 2023, pp. 3425–3433
2023
-
[28]
Ddgr: Continual learning with deep diffusion-based generative replay,
R. Gao and W. Liu, “Ddgr: Continual learning with deep diffusion-based generative replay,” inICML, 2023, pp. 10 744–10 763
2023
-
[29]
Overcoming catastrophic forgetting in neural networks,
J. Kirkpatricket al., “Overcoming catastrophic forgetting in neural networks,”Proceedings of the National Academy of Sciences, vol. 114, no. 13, pp. 3521–3526, 2017
2017
-
[30]
Continual learning through synaptic intelligence,
F. Zenke, B. Poole, and S. Ganguli, “Continual learning through synaptic intelligence,” inICML, 2017, pp. 3987–3995
2017
-
[31]
Memory aware synapses: Learning what (not) to forget,
R. Aljundi, F. Babiloni, M. Elhoseiny, M. Rohrbach, and T. Tuytelaars, “Memory aware synapses: Learning what (not) to forget,” inECCV, 2018, pp. 139–154
2018
-
[32]
Riemannian walk for incremental learning,
A. Chaudhry, P. K. Dokania, T. Ajanthan, and P. H. Torr, “Riemannian walk for incremental learning,” inECCV, 2018, pp. 532–547
2018
-
[33]
Learning to prompt for continual learning,
Z. Wang, Z. Zhang, C.-Y . Lee, H. Zhang, R. Sun, X. Ren, G. Su, V . Perot, J. Dy, and T. Pfister, “Learning to prompt for continual learning,” in CVPR, 2022, pp. 139–149
2022
-
[34]
Dualprompt: Complementary prompting for rehearsal-free continual learning,
Z. Wang, Z. Zhang, S. Ebrahimi, R. Sun, H. Zhang, C.-Y . Lee, X. Ren, G. Su, V . Perot, J. Dyet al., “Dualprompt: Complementary prompting for rehearsal-free continual learning,” inECCV, 2022, pp. 631–648
2022
-
[35]
Self-supervised models are continual learners,
E. Fini, V . G. T. da Costa, X. Alameda-Pineda, E. Ricci, K. Alahari, and J. Mairal, “Self-supervised models are continual learners,” inCVPR, 2022, pp. 9621–9630
2022
-
[36]
Lump: A framework for continual learning with large pretrained models,
W. Sun, Q. Li, H. Zhang, Y . Li, and S. Liu, “Lump: A framework for continual learning with large pretrained models,” inICLR, 2024
2024
-
[37]
Scale: Online self- supervised lifelong learning without prior knowledge,
J.-Q. Yu, Z.-Q. Chen, Y .-X. Mu, and J.-H. Li, “Scale: Online self- supervised lifelong learning without prior knowledge,” inCVPR, 2023, pp. 19 090–19 099
2023
-
[38]
Learning multiple layers of features from tiny images,
A. Krizhevsky, G. Hintonet al., “Learning multiple layers of features from tiny images,” 2009
2009
-
[39]
Imagenet large scale visual recognition challenge,
O. Russakovskyet al., “Imagenet large scale visual recognition challenge,” IJCV, vol. 115, no. 3, pp. 211–252, 2015
2015
-
[40]
Convit: Improving vision transformers with soft convolutional inductive biases,
S. d’Ascoli, H. Touvron, M. L. Leavitt, A. S. Morcos, G. Biroli, and L. Sagun, “Convit: Improving vision transformers with soft convolutional inductive biases,” inICML, 2021, pp. 2286–2296
2021
-
[41]
Foster: Feature boosting and compression for class-incremental learning,
F.-Y . Wang, D.-W. Zhou, H.-J. Ye, and D.-C. Zhan, “Foster: Feature boosting and compression for class-incremental learning,” inECCV, 2022, pp. 398–414
2022
-
[42]
Adaptive aggregation networks for class-incremental learning,
Y . Liu, B. Schiele, and Q. Sun, “Adaptive aggregation networks for class-incremental learning,” inCVPR, 2021, pp. 2544–2553
2021
-
[43]
Memo: A unified framework for exemplar-free class-incremental learning,
D.-W. Zhou, Q.-W. Wang, Z.-H. Qi, H.-J. Ye, D.-C. Zhan, and Z. Liu, “Memo: A unified framework for exemplar-free class-incremental learning,” inICLR, 2023
2023
-
[44]
Learning a unified classifier incrementally via rebalancing,
S. Hou, X. Pan, C. C. Loy, Z. Wang, and D. Lin, “Learning a unified classifier incrementally via rebalancing,” inCVPR, 2019, pp. 831–839
2019
-
[45]
Podnet: Pooled outputs distillation for small-tasks incremental learning,
A. Douillard, M. Cord, C. Ollion, T. Robert, and E. Valle, “Podnet: Pooled outputs distillation for small-tasks incremental learning,” inECCV, 2020, pp. 86–102
2020
-
[46]
Overcoming catastrophic forgetting in incremental object detection via elastic response distillation,
T. Feng, M. Wang, and H. Yuan, “Overcoming catastrophic forgetting in incremental object detection via elastic response distillation,” inCVPR, 2022, pp. 9427–9436
2022
-
[47]
Endpoints weight fusion for class incremental semantic segmentation,
J.-W. Xiao, C.-B. Zhang, J. Feng, X. Liu, J. van de Weijer, and M.- M. Cheng, “Endpoints weight fusion for class incremental semantic segmentation,” inCVPR, 2023, pp. 7204–7213
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.