VeriChat: An Agentic Conversational AI Assistant for Hardware Security Verification
Pith reviewed 2026-07-03 11:39 UTC · model grok-4.3
The pith
A multi-agent conversational system supplies context-aware security guidance on user RTL designs by integrating EDA tools for simulation and formal checks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
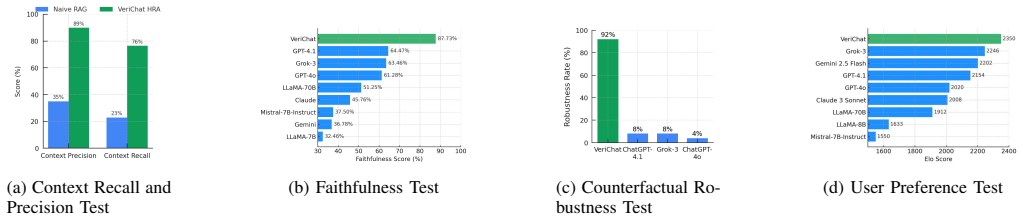
VeriChat employs a retrieval-augmented multi-agent workflow in which three specialized agents collaboratively minimize hallucinations while improving the transparency and reliability of the response. Beyond question answering, VeriChat integrates open-source EDA tools to perform syntax checking, synthesis analysis, simulation, and formal verification directly on user-provided RTL designs.
What carries the argument
The retrieval-augmented multi-agent workflow with three specialized agents that collaborate to ground responses and invoke EDA tools for direct analysis of RTL code.
If this is right
- Verification engineers receive on-demand guidance that incorporates live tool execution on their designs.
- Multi-turn conversations can carry out full identification, simulation, and formal proof of issues such as Trojans.
- Responses become more transparent because the workflow traces back to retrieved sources and tool results.
- The approach extends question answering into executable verification steps inside the same interface.
Where Pith is reading between the lines
- The same agent structure could be adapted to other verification domains that combine documentation lookup with tool calls.
- If agent coordination holds, the system might lower the barrier for smaller teams to perform security checks.
- Scaling the workflow to larger designs would test whether the three-agent division remains sufficient.
Load-bearing premise
The three agents will reliably coordinate to produce accurate security guidance on any user RTL design without requiring human review of every output.
What would settle it
An RTL design where the system returns a security assessment that misses an actual vulnerability or asserts a non-existent one, confirmed by independent manual review.
Figures






read the original abstract
Hardware security verification is a multi-stage process in which engineers must navigate complex design analyses, threat considerations, and verification strategies. They often need security-focused guidance, yet current verification environments provide little structured support for such assistance. Although conversational AI could offer such on-demand assistance, directly using general-purpose chatbots like ChatGPT or Gemini is risky due to their tendency to hallucinate and their reliance on static, outdated knowledge. We present VeriChat, a domain-specialized conversational assistant designed to support, rather than replace, existing verification workflows by providing context-aware security guidance. VeriChat employs a retrieval-augmented, multi-agent workflow in which three specialized agents collaboratively minimize hallucinations while improving the transparency and reliability of the response. Beyond question answering, VeriChat integrates open-source EDA tools, including Icarus Verilog, Yosys, and SymbiYosys, to perform syntax checking, synthesis analysis, simulation, and formal verification directly on user-provided RTL designs. Evaluated using a comprehensive methodology, VeriChat achieves a Faithfulness score of 87.73%, significantly outperforming the leading proprietary models. We demonstrate the framework through a hardware Trojan detection case study on an AES S-Box IP, where VeriChat autonomously identifies, simulates, and formally proves a covert key-leakage vulnerability through a multi-turn conversational workflow.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VeriChat, a retrieval-augmented multi-agent conversational AI assistant for hardware security verification. It employs three specialized agents to reduce hallucinations, integrates open-source EDA tools (Icarus Verilog, Yosys, SymbiYosys) for syntax checking, simulation, and formal verification on user RTL, reports a Faithfulness score of 87.73% that outperforms proprietary models, and demonstrates the system via a multi-turn case study autonomously identifying, simulating, and formally proving a key-leakage Trojan in an AES S-Box IP.
Significance. If the evaluation holds, the work offers a practical contribution by combining domain-specific RAG with direct EDA tool invocation, potentially enabling more reliable on-demand security guidance than general-purpose LLMs. The explicit integration of formal verification tools is a concrete strength that could support reproducible workflows if the agent orchestration proves robust.
major comments (3)
- [§4] §4 (Evaluation): The reported Faithfulness score of 87.73% is presented without any definition of the metric, description of the test dataset or query corpus, baseline models and their scores, ground-truth construction, or statistical details such as variance or number of samples. This directly undermines the central claim of outperforming leading proprietary models.
- [§5] §5 (Case Study): The AES S-Box Trojan detection workflow claims autonomous identification, simulation, and formal proof via multi-turn interaction, yet supplies no information on agent分工, retrieval corpus contents, tool-call success/failure rates (e.g., SymbiYosys output validation), or any quantitative measure of autonomy versus human post-editing. These omissions leave the reliability of the three-agent workflow unverified.
- [§3] §3 (System Architecture): The description of the multi-agent RAG workflow asserts that the three agents 'collaboratively minimize hallucinations' but provides neither the retrieval corpus size or domain coverage nor any ablation showing the contribution of each agent or the RAG component to the faithfulness result.
minor comments (2)
- [Abstract] The abstract states 'evaluated using a comprehensive methodology' without foreshadowing what that methodology entails; a single sentence summarizing dataset size and metric definition would improve clarity.
- [§5] Figure captions for the case-study conversation traces should explicitly label which agent produced each response and which EDA tool was invoked at each step.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and for recognizing the practical potential of VeriChat. We address each major comment below and will revise the manuscript to supply the requested details where they were insufficiently described.
read point-by-point responses
-
Referee: [§4] §4 (Evaluation): The reported Faithfulness score of 87.73% is presented without any definition of the metric, description of the test dataset or query corpus, baseline models and their scores, ground-truth construction, or statistical details such as variance or number of samples. This directly undermines the central claim of outperforming leading proprietary models.
Authors: We agree the evaluation section requires expansion. In the revised manuscript we will add a dedicated subsection defining the Faithfulness metric, describing the test dataset and query corpus, listing the baseline models and their scores, explaining ground-truth construction, and reporting the number of samples together with any variance or statistical measures. This will directly support the comparison against proprietary models. revision: yes
-
Referee: [§5] §5 (Case Study): The AES S-Box Trojan detection workflow claims autonomous identification, simulation, and formal proof via multi-turn interaction, yet supplies no information on agent分工, retrieval corpus contents, tool-call success/failure rates (e.g., SymbiYosys output validation), or any quantitative measure of autonomy versus human post-editing. These omissions leave the reliability of the three-agent workflow unverified.
Authors: We acknowledge these omissions. The revised §5 will specify the division of responsibilities among the three agents, the contents and size of the retrieval corpus, tool-call success and failure rates drawn from our logs (including SymbiYosys output validation), and quantitative indicators of autonomy such as the fraction of steps executed without human post-editing. revision: yes
-
Referee: [§3] §3 (System Architecture): The description of the multi-agent RAG workflow asserts that the three agents 'collaboratively minimize hallucinations' but provides neither the retrieval corpus size or domain coverage nor any ablation showing the contribution of each agent or the RAG component to the faithfulness result.
Authors: We will augment §3 with the size and domain coverage of the retrieval corpus. The original manuscript did not contain ablation experiments; we will therefore add a qualitative discussion of each agent's contribution based on the design rationale while noting the absence of quantitative ablations. A full ablation study would require additional experiments beyond the current scope. revision: partial
Circularity Check
No circularity: evaluation score presented as external result with no derivations or self-referential reductions
full rationale
The paper describes a multi-agent RAG system and reports a Faithfulness score of 87.73% as the outcome of a comprehensive evaluation methodology, without any equations, fitted parameters, or claimed derivations that reduce to the system's own outputs by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes appear in the abstract or described claims. The case study is presented as a demonstration workflow rather than a mathematical prediction derived from fitted inputs. The central claims rest on external tool integrations and evaluation rather than self-definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Silver–statistical independence and leakage verification,
D. Knichel, P. Sasdrich, and A. Moradi, “Silver–statistical independence and leakage verification,” inInternational Conference on the Theory and Applica- tion of Cryptology and Information Security. Springer, 2020, pp. 787–816
2020
-
[2]
Rtl-psc: Automated power side-channel leakage assessment at register-transfer level,
M. He, J. Park, A. Nahiyan, A. Vassilev, Y . Jin, and M. Tehranipoor, “Rtl-psc: Automated power side-channel leakage assessment at register-transfer level,” in 2019 IEEE 37th VLSI Test Symposium (VTS), 2019, pp. 1–6
2019
-
[3]
Y . Dong, Y . L. Aung, S. Chattopadhyay, and J. Zhou, “Chatiot: Large language model-based security assistant for internet of things with retrieval-augmented generation,”arXiv preprint arXiv:2502.09896, 2025
-
[4]
Orassistant: A custom rag-based conversational assistant for openroad,
A. Kaintura, S. S. Luar, I. I. Almeidaet al., “Orassistant: A custom rag-based conversational assistant for openroad,”arXiv preprint arXiv:2410.03845, 2024
-
[5]
Eda-copilot: A rag-powered intelligent assistant for eda tools,
Z. Xiao, X. He, H. Wu, B. Yu, and Y . Guo, “Eda-copilot: A rag-powered intelligent assistant for eda tools,”ACM Transactions on Design Automation of Electronic Systems, 2025
2025
-
[6]
Chateda: A large language model powered autonomous agent for eda,
H. Wu, Z. He, X. Zhang, X. Yao, S. Zheng, H. Zheng, and B. Yu, “Chateda: A large language model powered autonomous agent for eda,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2024
2024
-
[7]
Ai-assisted hardware security verification: A survey and ai accelerator case study,
K. T. Hasan, M. A. Hasan, N. Alam, M. T. Islam, U. Das, and F. Farahmandi, “Ai-assisted hardware security verification: A survey and ai accelerator case study,” in2026 IEEE 44th VLSI Test Symposium (VTS). IEEE, 2026, pp. 1–7
2026
-
[8]
Sv-llm: An agentic approach for soc security verification using large language models,
D. Saha, S. Tarek, H. A. Shaikh, K. T. Hasan, P. S. Nalluri, M. A. Hasan, N. Alam, J. Zhou, S. K. Saha, M. Tehranipooret al., “Sv-llm: An agentic approach for soc security verification using large language models,”arXiv preprint arXiv:2506.20415, 2025
-
[9]
Llm for soc security: A paradigm shift,
D. Saha, S. Tarek, K. Yahyaei, S. K. Saha, J. Zhou, M. Tehranipoor, and F. Farahmandi, “Llm for soc security: A paradigm shift,”IEEe Access, vol. 12, pp. 155 498–155 521, 2024
2024
-
[10]
Empow- ering hardware security with llm: The development of a vulnerable hardware database,
D. Saha, K. Yahyaei, S. K. Saha, M. Tehranipoor, and F. Farahmandi, “Empow- ering hardware security with llm: The development of a vulnerable hardware database,” in2024 IEEE International Symposium on Hardware Oriented Security and Trust (HOST). IEEE, 2024, pp. 233–243
2024
-
[11]
Socurellm: An llm-driven approach for large-scale system-on- chip security verification and policy generation,
S. Tareket al., “Socurellm: An llm-driven approach for large-scale system-on- chip security verification and policy generation,” in2025 IEEE International Symposium on Hardware Oriented Security and Trust (HOST). IEEE, 2025, pp. 335–345
2025
-
[12]
Malls: Multi- agent llms for synthetic hardware vulnerability generation and detection,
J. Talukdar, A. Seth, S. Banerjee, F. Firouzi, and K. Chakrabarty, “Malls: Multi- agent llms for synthetic hardware vulnerability generation and detection,” in 2025 IEEE 43rd International Conference on Computer Design (ICCD), 2025, pp. 782–789
2025
-
[13]
Can agents secure hardware? evaluating agentic llm-driven obfuscation for ip protection,
S. Ghimire, P. Mirfasihi, M. A. Chowdhury, V . Pugazhenthi, H. K. Dharavath, F. Firouzi, R. Yasaei, P. Satam, and S. Salehi, “Can agents secure hardware? evaluating agentic llm-driven obfuscation for ip protection,” in2026 IEEE 44th VLSI Test Symposium (VTS), 2026, pp. 1–5
2026
-
[14]
Lasset: An llm-assisted security asset identification framework for system-on-chip (soc) verification,
M. A. Hasan, D. Saha, K. T. Hasan, N. Alam, A. Uddin, S. K. Saha, M. Tehra- nipoor, and F. Farahmandi, “Lasset: An llm-assisted security asset identification framework for system-on-chip (soc) verification,” in2026 Design, Automation & Test in Europe Conference (DATE), 2026, pp. 1–7
2026
-
[15]
Assertain: Automated security assertion generation using large language mod- els,
S. Tarek, D. Saha, K. T. Hasan, S. K. Saha, M. Tehranipoor, and F. Farahmandi, “Assertain: Automated security assertion generation using large language mod- els,”arXiv preprint arXiv:2604.01583, 2026
-
[16]
Lasso: Llm- aided security property generation for assertion-based soc verification,
D. R. Ankireddy, S. Paria, A. Dasgupta, S. Ray, and S. Bhunia, “Lasso: Llm- aided security property generation for assertion-based soc verification,” in2025 ACM/IEEE 7th Symposium on Machine Learning for CAD (MLCAD). IEEE, 2025, pp. 1–10
2025
-
[17]
Enhancing large language models for hardware verification: A novel systemverilog assertion dataset,
A. Menon, S. Miftah, S. Kundu, S. Kundu, A. Srivastava, A. Raha, G. Sonnenschien, S. Banerjee, D. Mathaikutty, and K. Basu, “Enhancing large language models for hardware verification: A novel systemverilog assertion dataset,”ACM Trans. Des. Autom. Electron. Syst., vol. 31, no. 6, Jun. 2026. [Online]. Available: https://doi.org/10.1145/3764934
-
[18]
Threatlens: Llm-guided threat modeling and test plan generation for hardware security verification,
D. Saha, H. Al Shaikh, S. Tarek, and F. Farahmandi, “Threatlens: Llm-guided threat modeling and test plan generation for hardware security verification,” Cryptology ePrint Archive, 2025
2025
-
[19]
A surprisingly simple yet effective multi-query rewriting method for conversational passage retrieval,
I. Kostric and K. Balog, “A surprisingly simple yet effective multi-query rewriting method for conversational passage retrieval,” inProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2024, pp. 2271–2275
2024
-
[20]
Improving Multi-turn Dialogue Modelling with Utterance ReWriter
H. Su, X. Shen, R. Zhang, F. Sun, P. Hu, C. Niu, and J. Zhou, “Improv- ing multi-turn dialogue modelling with utterance rewriter,”arXiv preprint arXiv:1906.07004, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[21]
Query rewriting in retrieval- augmented large language models,
X. Ma, Y . Gong, P. He, H. Zhao, and N. Duan, “Query rewriting in retrieval- augmented large language models,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 5303–5315
2023
-
[22]
Reciprocal rank fusion outperforms condorcet and individual rank learning methods,
G. V . Cormack, C. L. Clarke, and S. Buettcher, “Reciprocal rank fusion outperforms condorcet and individual rank learning methods,” inProceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval, 2009, pp. 758–759
2009
-
[23]
Scar: Power side-channel analysis at rtl level,
A. Srivastava, S. Das, N. Choudhury, R. Psiakis, P. H. Silva, D. Pal, and K. Basu, “Scar: Power side-channel analysis at rtl level,”IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2024
2024
-
[24]
Z3: An Efficient SMT Solver,
L. de Moura and N. Bjørner, “Z3: An Efficient SMT Solver,” inProceedings of the 14th International Conference on Tools and Algorithms for the Construction and Analysis of Systems (TACAS). Springer, 2008, pp. 337–340
2008
-
[25]
Deepeval: The open-source llm evaluation framework,
DeepEval, “Deepeval: The open-source llm evaluation framework,” https://de epeval.com, 2024, accessed: 2025-07-12
2024
-
[26]
Judging llm-as-a-judge with mt-bench and chatbot arena,
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. Xinget al., “Judging llm-as-a-judge with mt-bench and chatbot arena,” Advances in neural information processing systems, vol. 36, pp. 46 595–46 623, 2023
2023
-
[27]
Chatbot arena: An open platform for evaluating llms by human preference,
W.-L. Chiang, L. Zheng, Y . Sheng, A. N. Angelopoulos, T. Li, D. Li, B. Zhu, H. Zhang, M. Jordan, J. E. Gonzalezet al., “Chatbot arena: An open platform for evaluating llms by human preference,” inForty-first International Confer- ence on Machine Learning, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.