InterCMDM: Block-Causal Diffusion for Autoregressive Human Interaction Generation
Pith reviewed 2026-07-03 16:40 UTC · model grok-4.3
The pith
InterCMDM generates two-person interactions autoregressively using block-causal diffusion and dual-stream attention masks that enforce causality while enabling controllable coordination.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
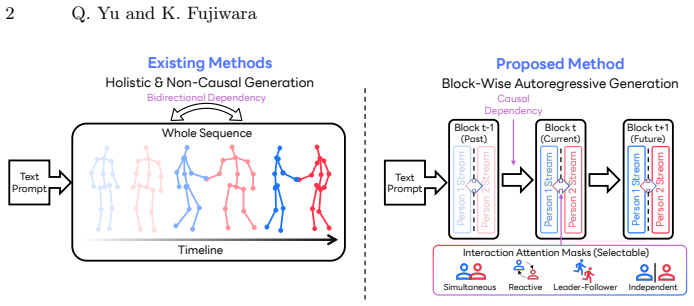
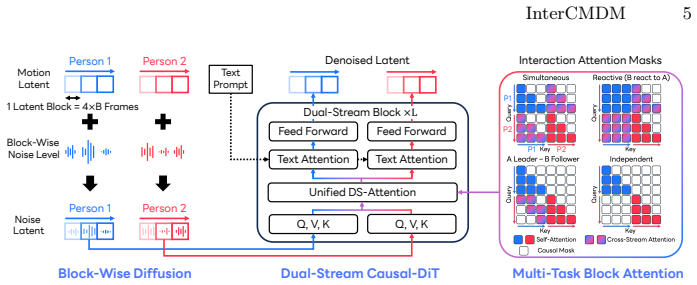
InterCMDM is a block-causal latent diffusion model built around a Dual-Stream Causal Diffusion Transformer that keeps separate causal streams per person, routes inter-person dependencies through a shared attention mechanism controlled by multi-task masks, trains the model once across mask variants to support mask-selected control at inference, and replaces full-sequence denoising with block-wise diffusion to permit repeated latent rollout without repeated encode-decode cycles.
What carries the argument
Dual-Stream Causal Diffusion Transformer with multi-task attention masks that unify interaction modeling and support simultaneous, reactive, leader-follower, and independent coordination within one attention pass.
If this is right
- Selecting different attention masks at inference time produces controllable interaction styles without retraining.
- Block-wise diffusion permits stable autoregressive rollout over arbitrarily long sequences without repeated full-sequence encode-decode steps.
- A single trained model covers multiple coordination regimes that previously required separate models or post-processing.
- Causality is preserved inside each person's stream while inter-person coupling remains learnable, enabling both streaming and offline generation.
Where Pith is reading between the lines
- The mask-augmentation trick may transfer to other multi-agent sequence tasks where different relational modes must be learned from one dataset.
- The same dual-stream causal structure could be tested on three-or-more-person interactions by extending the mask set rather than redesigning the architecture.
- If the block-wise objective truly prevents drift, similar block-causal diffusion may improve long-horizon single-person motion generation where current autoregressive models still accumulate error.
Load-bearing premise
The block-wise diffusion objective together with dual-stream causal attention and multi-task masks is sufficient to stop temporal drift and coordination degradation over long horizons.
What would settle it
Generate interaction sequences substantially longer than the training horizon and measure whether inter-person coordination metrics remain stable or degrade monotonically with length.
Figures
read the original abstract
Text-conditioned human interaction generation must capture both long-range temporal causality within each individual and tightly coupled coordination between partners. Existing interaction diffusion models typically denoise full sequences using bidirectional attention, which obscures causality and hinders streaming and long-horizon generation. Autoregressive alternatives enforce causality but often suffer from temporal drift, leading to coordination degradation and unstable interaction dynamics over time. We propose InterCMDM, a block-causal latent diffusion framework for autoregressive two-person interaction generation. InterCMDM introduces a Dual-Stream Causal Diffusion Transformer that maintains separate causal streams for each person while modeling inter-person dependencies via unified dual-stream attention with multi-task attention masks. These masks unify interaction modeling within a single attention mechanism and support diverse coordination behaviors, including simultaneous actions, reactive responses, leader-follower dynamics, and independent motion. By training a single model across these mask configurations as a form of data augmentation, InterCMDM enables controllable interaction generation by simply selecting the desired attention mask at inference time. Finally, a block-wise diffusion objective enables stable latent rollout over long sequences without repeated decode-encode cycles. InterCMDM achieves state-of-the-art performance on InterHuman and Inter-X, improving text-motion alignment, realism, and long-horizon continuity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes InterCMDM, a block-causal latent diffusion framework for autoregressive two-person human interaction generation conditioned on text. It introduces a Dual-Stream Causal Diffusion Transformer that uses separate causal streams per person and unified dual-stream attention with multi-task attention masks to model inter-person dependencies and support behaviors such as simultaneous actions, reactive responses, leader-follower dynamics, and independent motion. Training across mask configurations acts as data augmentation for controllable generation at inference. A block-wise diffusion objective is used to enable stable latent rollout over long sequences. The authors claim state-of-the-art performance on InterHuman and Inter-X, with gains in text-motion alignment, realism, and long-horizon continuity.
Significance. If the empirical results hold, the work offers a practical autoregressive alternative to bidirectional diffusion models for interactive motion, potentially enabling streaming generation and better long-horizon stability. The multi-task mask approach for controllability without retraining is a clear strength that could generalize. The block-wise objective directly targets a known failure mode in autoregressive diffusion rollouts.
major comments (1)
- [Abstract] Abstract: The central claim of SOTA performance and improved long-horizon continuity on InterHuman and Inter-X is asserted without any quantitative metrics, error bars, ablation studies, dataset statistics, or references to specific tables/figures showing per-frame coordination errors or comparisons against non-block baselines on sequences exceeding training length. This is load-bearing for the claim that the block-causal objective plus multi-task masks suffice to prevent temporal drift and coordination degradation, as autoregressive diffusion rollouts are known to accumulate inconsistencies.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for clearer linkage between the abstract claims and the supporting evidence in the manuscript. We address this point directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of SOTA performance and improved long-horizon continuity on InterHuman and Inter-X is asserted without any quantitative metrics, error bars, ablation studies, dataset statistics, or references to specific tables/figures showing per-frame coordination errors or comparisons against non-block baselines on sequences exceeding training length. This is load-bearing for the claim that the block-causal objective plus multi-task masks suffice to prevent temporal drift and coordination degradation, as autoregressive diffusion rollouts are known to accumulate inconsistencies.
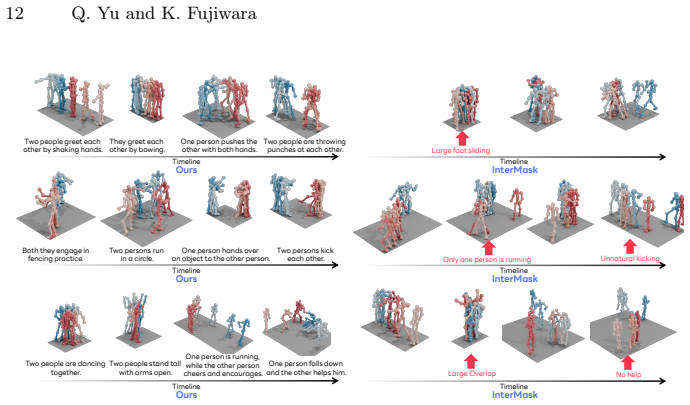
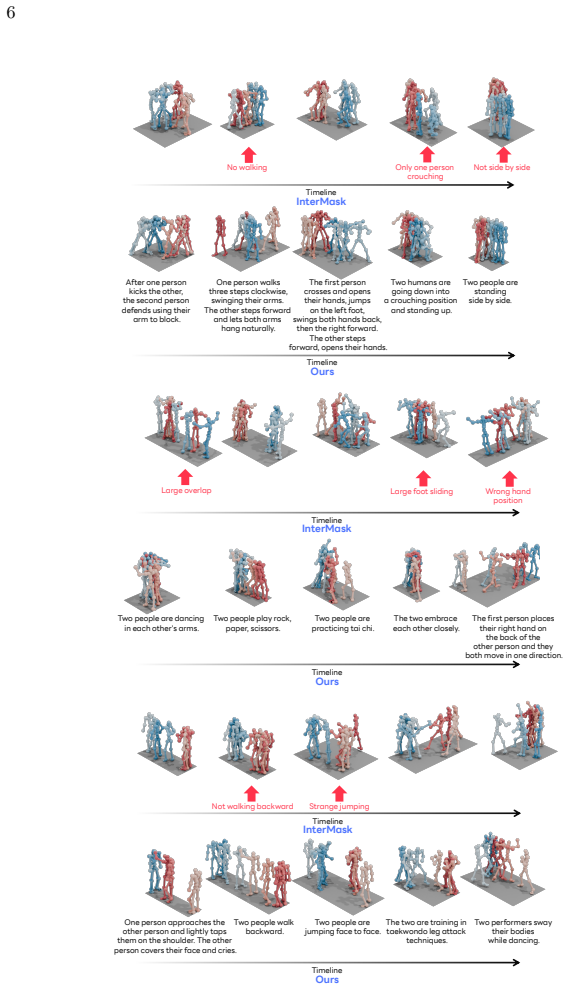
Authors: We agree that the abstract would be strengthened by explicit references to the quantitative evidence. The manuscript reports SOTA results with error bars in Table 1 (InterHuman and Inter-X metrics), long-horizon evaluations exceeding training length in Figure 5 and Section 4.2 (including per-frame coordination errors and non-block baseline comparisons), ablation studies in Section 4.3, and dataset statistics in Section 3.1. We will revise the abstract to include targeted pointers (e.g., 'achieving SOTA as shown in Table 1 with improved long-horizon continuity in Figure 5') while respecting length constraints. This directly addresses the concern about temporal drift by pointing readers to the block-wise objective results and mask ablations that demonstrate stability. revision: yes
Circularity Check
No circularity; architectural proposal lacks derivation chain
full rationale
The paper presents InterCMDM as a block-causal latent diffusion framework with dual-stream causal attention and multi-task masks. No equations, derivations, or first-principles results are described that reduce to fitted parameters, self-citations, or definitional loops. The SOTA claims rest on empirical evaluation of the proposed components rather than any mathematical reduction to inputs. This is a standard model-architecture contribution with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
TMR: Text-to-Motion Retrieval Using Contrastive 3D Human Motion Synthesis , author=
-
[2]
Motionclip: Exposing human motion generation to clip space , author=
-
[3]
AMASS: Archive of motion capture as surface shapes , author=
-
[4]
Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding , author=
-
[5]
A large-scale varying-view rgb-d action dataset for arbitrary-view human action recognition , author=
-
[6]
BABEL: Bodies, action and behavior with english labels , author=
-
[7]
Big data , year=
The KIT motion-language dataset , author=. Big data , year=
-
[8]
arXiv preprint arXiv:2311.16498 , year=
Magicanimate: Temporally consistent human image animation using diffusion model , author=. arXiv preprint arXiv:2311.16498 , year=
-
[9]
3DV , year=
Teach: Temporal action composition for 3d humans , author=. 3DV , year=
-
[10]
Action-conditioned 3D human motion synthesis with transformer VAE , author=
-
[11]
TEMOS: Generating diverse human motions from textual descriptions , author=
-
[12]
Hierarchical recurrent neural network for skeleton based action recognition , author=
-
[13]
Deep progressive reinforcement learning for skeleton-based action recognition , author=
-
[14]
Human action recognition by representing 3d skeletons as points in a lie group , author=
-
[15]
Spatial temporal graph convolutional networks for skeleton-based action recognition , author=
-
[16]
Two-stream adaptive graph convolutional networks for skeleton-based action recognition , author=
-
[17]
Attention is all you need , author=
-
[18]
Convolutional sequence generation for skeleton-based action synthesis , author=
-
[19]
Bayesian adversarial human motion synthesis , author=
-
[20]
Action2motion: Conditioned generation of 3d human motions , author=
-
[21]
Executing your Commands via Motion Diffusion in Latent Space , author=
-
[22]
Synthesis of compositional animations from textual descriptions , author=
-
[23]
arXiv preprint arXiv:2211.15603 , year=
Action-GPT: Leveraging Large-scale Language Models for Improved and Generalized Zero Shot Action Generation , author=. arXiv preprint arXiv:2211.15603 , year=
-
[24]
T2m-gpt: Generating human motion from textual descriptions with discrete representations , author=
-
[25]
3DV , year=
Language2pose: Natural language grounded pose forecasting , author=. 3DV , year=
-
[26]
High-resolution image synthesis with latent diffusion models , author=
-
[27]
Diffusion models beat gans on image synthesis , author=
-
[28]
ACM TOG , year=
A motion matching-based framework for controllable gesture synthesis from speech , author=. ACM TOG , year=
-
[29]
ACM TOG , year=
Learned motion matching , author=. ACM TOG , year=
-
[30]
Generating diverse and natural 3d human motions from text , author=
-
[31]
Mofusion: A framework for denoising-diffusion-based motion synthesis , author=
-
[32]
arXiv preprint arXiv:2208.15001 , year=
Motiondiffuse: Text-driven human motion generation with diffusion model , author=. arXiv preprint arXiv:2208.15001 , year=
-
[33]
NeurIPS , year=
Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks , author=. NeurIPS , year=
-
[34]
arXiv preprint arXiv:1908.08530 , year=
Vl-bert: Pre-training of generic visual-linguistic representations , author=. arXiv preprint arXiv:1908.08530 , year=
-
[35]
ECCV , year=
Uniter: Learning universal image-text representations , author=. ECCV , year=
-
[36]
ICML , year=
Learning transferable visual models from natural language supervision , author=. ICML , year=
-
[37]
Robotics and Autonomous Systems , year=
Learning a bidirectional mapping between human whole-body motion and natural language using deep recurrent neural networks , author=. Robotics and Autonomous Systems , year=
-
[38]
IEEE Robotics and Automation Letters , year=
Paired recurrent autoencoders for bidirectional translation between robot actions and linguistic descriptions , author=. IEEE Robotics and Automation Letters , year=
-
[39]
ICML , year=
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation , author=. ICML , year=
-
[40]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=
-
[41]
IJCV , year=
Imagenet large scale visual recognition challenge , author=. IJCV , year=
-
[42]
NeurIPS-W , year=
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter , author=. NeurIPS-W , year=
-
[43]
Adam: A method for stochastic optimization , author=
-
[44]
Representation Learning with Contrastive Predictive Coding
Representation learning with contrastive predictive coding , author=. arXiv preprint arXiv:1807.03748 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
ACM TOG , year=
SMPL: A skinned multi-person linear model , author=. ACM TOG , year=
-
[46]
CVPR , year=
Ntu rgb+ d: A large scale dataset for 3d human activity analysis , author=. CVPR , year=
-
[47]
6m: Large scale datasets and predictive methods for 3d human sensing in natural environments , author=
Human3. 6m: Large scale datasets and predictive methods for 3d human sensing in natural environments , author=. IEEE TPAMI , year=
-
[48]
WACV , year=
Learning 3D human pose estimation from dozens of datasets using a geometry-aware autoencoder to bridge between skeleton formats , author=. WACV , year=
-
[49]
Radiology , year=
Chest Radiograph Interpretation with Deep Learning Models: Assessment with Radiologist-adjudicated Reference Standards and Population-adjusted Evaluation , author=. Radiology , year=
-
[50]
JAMA , year=
Development and Validation of a Deep Learning Algorithm for Detection of Diabetic Retinopathy in Retinal Fundus Photographs , author=. JAMA , year=
-
[51]
TernausNet: U-Net with VGG11 Encoder Pre-Trained on ImageNet for Image Segmentation
Ternausnet: U-net with vgg11 encoder pre-trained on imagenet for image segmentation , author=. arXiv preprint arXiv:1801.05746 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
CVPR , year=
Quo vadis, action recognition? a new model and the kinetics dataset , author=. CVPR , year=
-
[53]
arXiv preprint arXiv:2007.11154 , year=
Rethinking CNN models for audio classification , author=. arXiv preprint arXiv:2007.11154 , year=
-
[54]
CVPR , year=
Deep residual learning for image recognition , author=. CVPR , year=
-
[55]
ICML , year=
Efficientnet: Rethinking model scaling for convolutional neural networks , author=. ICML , year=
-
[56]
ACM TOG , year=
Motion puzzle: Arbitrary motion style transfer by body part , author=. ACM TOG , year=
-
[57]
arXiv preprint arXiv:2301.13360 , year=
Skeleton-based Human Action Recognition via Convolutional Neural Networks (CNN) , author=. arXiv preprint arXiv:2301.13360 , year=
-
[58]
Computer Animation and Virtual Worlds , year=
3D skeleton-based action recognition by representing motion capture sequences as 2D-RGB images , author=. Computer Animation and Virtual Worlds , year=
-
[59]
NAACL , year=
Exposing the limits of video-text models through contrast sets , author=. NAACL , year=
-
[60]
ICLR , year=
When and why vision-language models behave like bag-of-words models, and what to do about it? , author=. ICLR , year=
-
[61]
ACL , year=
Probing image-language transformers for verb understanding , author=. ACL , year=
-
[62]
ICCV , year=
Motionbert: Unified pretraining for human motion analysis , author=. ICCV , year=
-
[63]
CVPR , year=
Mage: Masked generative encoder to unify representation learning and image synthesis , author=. CVPR , year=
-
[64]
IEEE/ACM T-ASLP , year=
Psla: Improving audio tagging with pretraining, sampling, labeling, and aggregation , author=. IEEE/ACM T-ASLP , year=
-
[65]
ICLR , year=
Human motion diffusion model , author=. ICLR , year=
-
[66]
CVPR , year=
Generating diverse and natural 3d human motions from text , author=. CVPR , year=
-
[67]
2023 , booktitle =
ReMoDiffuse: Retrieval-Augmented Motion Diffusion Model , author =. 2023 , booktitle =
2023
-
[68]
NeurIPS , year=
Motiongpt: Human motion as a foreign language , author=. NeurIPS , year=
-
[69]
ECCV , year=
MotionLCM: Real-time Controllable Motion Generation via Latent Consistency Model , author=. ECCV , year=
-
[70]
CVPR , year=
Seamless human motion composition with blended positional encodings , author=. CVPR , year=
-
[71]
CVPR , year=
Optimizing diffusion noise can serve as universal motion priors , author=. CVPR , year=
-
[72]
ICLR , year=
Denoising Diffusion Implicit Models , author=. ICLR , year=
-
[73]
CVPR , year=
Guided motion diffusion for controllable human motion synthesis , author=. CVPR , year=
-
[74]
ICLR , year=
OmniControl: Control Any Joint at Any Time for Human Motion Generation , author=. ICLR , year=
-
[75]
SIGGRAPH , year=
Iterative motion editing with natural language , author=. SIGGRAPH , year=
-
[76]
CVPR , year=
Programmable Motion Generation for Open-Set Motion Control Tasks , author=. CVPR , year=
-
[77]
Language Models are Few-Shot Learners
Language models are few-shot learners , author=. arXiv preprint arXiv:2005.14165 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[78]
ICCV , year=
Adding conditional control to text-to-image diffusion models , author=. ICCV , year=
-
[79]
Auto-Encoding Variational Bayes
Auto-encoding variational bayes , author=. arXiv preprint arXiv:1312.6114 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[80]
CVPR , year=
Exploring Vision Transformers for 3D Human Motion-Language Models with Motion Patches , author=. CVPR , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.