Archer: Towards Agentic Review for Compiler Optimizations
Pith reviewed 2026-07-03 08:54 UTC · model grok-4.3
The pith
Archer finds semantic bugs in 21% of open LLVM optimization pull requests and 11% of closed ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Archer constrains agentic review with obligations and a deterministic validation guard that requires executable evidence, and its application to recent LLVM PRs shows that 21% of open PRs and 11% of closed PRs introduce semantic bugs such as miscompilations.
What carries the argument
Archer, the agentic review system that applies obligations to guide analysis and a deterministic validation guard to accept only executable-evidence-backed findings.
If this is right
- A substantial fraction of compiler optimization changes may enter the codebase with undetected semantic errors.
- Expert review capacity in large compiler projects is insufficient to catch all such issues before integration.
- An automated tool using obligations and executable validation can serve as a scalable additional reviewer for optimization PRs.
Where Pith is reading between the lines
- The same constrained agentic approach might be adapted to review changes in other large, correctness-critical codebases such as operating system kernels.
- The reported bug rates suggest that existing test suites and continuous integration for LLVM may leave certain semantic properties under-checked.
- If the validation guard can be made more general, Archer-style review could shorten the time between patch submission and safe merge while reducing bug escape.
Load-bearing premise
The validation guard and agentic analysis correctly identify actual semantic bugs without substantial false positives or missed cases.
What would settle it
Independent manual verification or re-testing of the specific PRs flagged by Archer to confirm whether they actually introduce miscompilations or other semantic changes.
Figures







read the original abstract
Modern compilers are frequently updated, but expert review capacity is highly limited, leading to delayed integration and, in some cases, subtle semantic bugs entering the compiler codebase. Automating the code review process with modern general code review agents may be feasible, but it faces critical challenges due to compiler complexity. In this paper, we use LLVM as our target compiler and present Archer, the first automated agentic code review tool for compiler optimizations. Archer constrains the agentic review process from both ends by using obligations to guide analysis and a deterministic validation guard to admit only findings backed by executable evidence. We evaluated Archer on 70 open PRs and 328 closed PRs in LLVM from the last two months. The review results are shocking and concerning: Archer discovers that 21% of open PRs and 11% of closed PRs are buggy, i.e, introducing semantic bugs such as miscompilations in LLVM. Our findings expose a critical gap in the capacity for critical review in large compiler projects and demonstrate the practical value of Archer as an additional reviewer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Archer, the first automated agentic code review tool for compiler optimizations in LLVM. It constrains the agentic process using obligations to guide analysis and a deterministic validation guard to admit only findings backed by executable evidence. Evaluation on 70 open PRs and 328 closed PRs from the last two months finds that 21% of open PRs and 11% of closed PRs introduce semantic bugs such as miscompilations.
Significance. If the empirical claims are substantiated with transparent validation, the work would be significant for highlighting the limited capacity for critical review in large compiler projects and demonstrating a practical agentic approach that combines obligations with deterministic guards to reduce false positives in complex domains. The scale of the evaluation (398 PRs) and the focus on real LLVM changes provide a concrete testbed for such tools.
major comments (1)
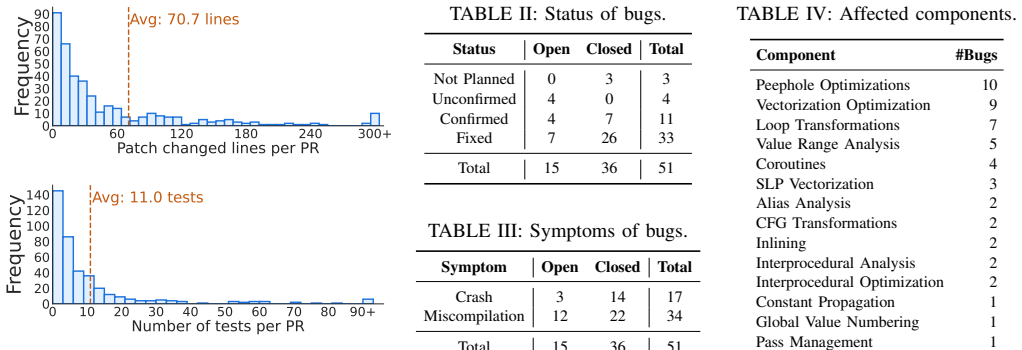
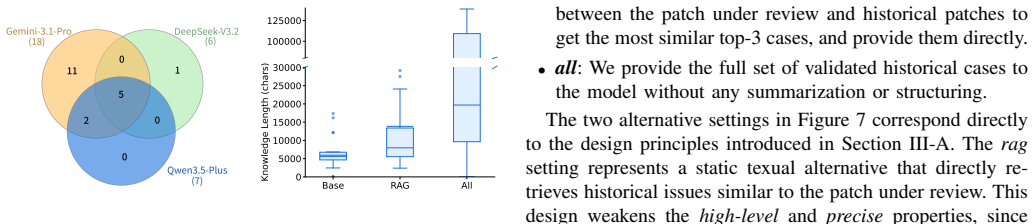
- [Abstract and Evaluation] Abstract and Evaluation section: the central claims that Archer discovers 21% of open PRs and 11% of closed PRs are buggy rest on the assertion that the deterministic validation guard 'admits only findings backed by executable evidence,' yet the manuscript supplies no description of the guard's decision procedure, no false-positive audit, no manual validation of the 70+328 cases, and no concrete example of any reported bug together with its executable evidence. This directly undermines the headline percentages.
minor comments (1)
- [Abstract] The abstract states the PRs are 'from the last two months' but does not give the exact date range or the selection criteria used to obtain the 398 PRs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the transparency of our evaluation. We address the major comment below and will revise the manuscript to strengthen the substantiation of our empirical claims.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation section: the central claims that Archer discovers 21% of open PRs and 11% of closed PRs are buggy rest on the assertion that the deterministic validation guard 'admits only findings backed by executable evidence,' yet the manuscript supplies no description of the guard's decision procedure, no false-positive audit, no manual validation of the 70+328 cases, and no concrete example of any reported bug together with its executable evidence. This directly undermines the headline percentages.
Authors: We agree that the manuscript would benefit from expanded detail on the deterministic validation guard to better support the reported percentages. In the revised version, we will add a precise description of the guard's decision procedure, including the criteria and mechanisms it uses to verify that each finding is backed by executable evidence. We will also include at least one concrete example of a reported bug, presenting the relevant PR change, the agent's analysis, and the specific executable evidence (e.g., test case or execution result) that caused the guard to admit the finding. Additionally, we will report a manual false-positive audit performed on a random sample of the admitted findings from both the open and closed PR sets. While a complete manual validation of all 398 PRs exceeds the practical scope of this work, the deterministic, evidence-based design of the guard provides the primary substantiation for the results; the added sample audit and example will further address concerns about the headline percentages. revision: yes
Circularity Check
No circularity: empirical rates from external PR evaluation
full rationale
The paper reports observed bug rates (21% open, 11% closed PRs) from applying Archer to a fixed set of real LLVM PRs. No equations, fitted parameters, predictions, or derivations appear. The central claim is an empirical measurement on external data rather than a self-referential reduction. No self-citation chains or ansatzes are invoked as load-bearing. This matches the default expectation of a non-circular empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Contributors to llvm/llvm-project,
LLVM, “Contributors to llvm/llvm-project,” 2026, accessed: 2026- 02-18. [Online]. Available: https://github.com/llvm/llvm-project/graphs/ contributors
2026
-
[2]
Contributors to llvm/llvm-project,
——, “Contributors to llvm/llvm-project,” 2026, accessed: 2026- 03-11. [Online]. Available: https://insights.linuxfoundation.org/project/ llvm-llvm-project
2026
-
[3]
Llvm: The bad parts,
N. Popov, “Llvm: The bad parts,” 2026, accessed: 2026-02-18. [Online]. Available: https://www.npopov.com/2026/01/11/LLVM-The-bad-parts. html
2026
-
[4]
Facilitating vulnerability assessment through poc migration,
X. Zhu and M. Böhme, “Regression greybox fuzzing,” inProceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’21, 2021, p. 2169–2182. [Online]. Available: https://doi.org/10.1145/3460120.3484596
-
[5]
J. Chen, J. Patra, M. Pradel, Y . Xiong, H. Zhang, D. Hao, and L. Zhang, “A survey of compiler testing,”ACM Comput. Surv., vol. 53, no. 1, 2020. [Online]. Available: https://doi.org/10.1145/3363562
-
[6]
Fuzzing: A survey for roadmap,
X. Zhu, S. Wen, S. Camtepe, and Y . Xiang, “Fuzzing: A survey for roadmap,”ACM Comput. Surv., vol. 54, no. 11s, 2022. [Online]. Available: https://doi.org/10.1145/3512345
-
[7]
Automated code review in practice,
U. Cihan, V . Haratian, A. ˙Içöz, M. K. Gül, Ö. Devran, E. F. Bayendur, B. M. Uçar, and E. Tüzün, “Automated code review in practice,” in2025 IEEE/ACM 47th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP), 2025, pp. 425–436
2025
-
[8]
Codex | ai assistant work and code,
OpenAI, “Codex | ai assistant work and code,” 2026, accessed: 2026-06-25. [Online]. Available: https://chatgpt.com/codex
2026
-
[9]
Githhub copilot - your ai pair programmer,
GitHub, “Githhub copilot - your ai pair programmer,” 2026, accessed: 2026-06-25. [Online]. Available: https://github.com/features/copilot
2026
-
[10]
Ai code reviews | coderabbit,
C. Inc, “Ai code reviews | coderabbit,” 2026, accessed: 2026-03-26. [Online]. Available: https://www.coderabbit.ai
2026
-
[11]
Laura: Enhanc- ing code review generation with context-enriched retrieval-augmented llm,
Y . Zhang, Y . Zhang, Z. Sun, Y . Jiang, and H. Liu, “Laura: Enhanc- ing code review generation with context-enriched retrieval-augmented llm,” in2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2025, pp. 2983–2995
2025
-
[12]
Alive2: bounded translation validation for llvm,
N. P. Lopes, J. Lee, C.-K. Hur, Z. Liu, and J. Regehr, “Alive2: bounded translation validation for llvm,” inProceedings of the 42nd ACM SIGPLAN International Conference on Programming Language Design and Implementation, ser. PLDI 2021, 2021, p. 65–79. [Online]. Available: https://doi.org/10.1145/3453483.3454030
-
[13]
Bitsai-cr: Automated code review via llm in practice,
T. Sun, J. Xu, Y . Li, Z. Yan, G. Zhang, L. Xie, L. Geng, Z. Wang, Y . Chen, Q. Lin, W. Duan, K. Sui, and Y . Zhu, “Bitsai-cr: Automated code review via llm in practice,” inProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering, ser. FSE Companion ’25, 2025, p. 274–285. [Online]. Available: https://doi.org/10.1145/...
-
[14]
Language models don’t always say what they think: unfaithful explanations in chain-of- thought prompting,
M. Turpin, J. Michael, E. Perez, and S. R. Bowman, “Language models don’t always say what they think: unfaithful explanations in chain-of- thought prompting,” inProceedings of the 37th International Conference on Neural Information Processing Systems, ser. NIPS ’23, 2023
2023
-
[15]
Are self-explanations from large language models faithful?
A. Madsen, S. Chandar, and S. Reddy, “Are self-explanations from large language models faithful?” inFindings of the Association for Computational Linguistics: ACL 2024. Association for Computational Linguistics, 2024, pp. 295–337. [Online]. Available: https://aclanthology. org/2024.findings-acl.19/
2024
-
[16]
Instcombine contributor guide,
LLVM, “Instcombine contributor guide,” 2026, ac- cessed: 2026-03-26. [Online]. Available: https://llvm.org/docs/ InstCombineContributorGuide.html#proofs
2026
-
[17]
Llvm ai tool use policy,
——, “Llvm ai tool use policy,” 2026, accessed: 2026-03-23. [Online]. Available: https://llvm.org/docs/AIToolPolicy.html
2026
-
[18]
Swe-agent: agent-computer interfaces enable automated soft- ware engineering,
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “Swe-agent: agent-computer interfaces enable automated soft- ware engineering,” inProceedings of the 38th International Conference on Neural Information Processing Systems, ser. NIPS ’24, 2024
2024
-
[19]
Autoreview: An llm-based multi-agent system for security issue-oriented code review,
Y . Chen, “Autoreview: An llm-based multi-agent system for security issue-oriented code review,” inProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering, ser. FSE Companion ’25, 2025, p. 1022–1024. [Online]. Available: https://doi.org/10.1145/3696630.3728618
-
[20]
Rethinking code review workflows with llm assis- tance: An empirical study,
F. S. Aðalsteinsson, B. B. Magnússon, M. Milicevic, A. N. Davidsson, and C.-H. Cheng, “Rethinking code review workflows with llm assis- tance: An empirical study,” in2025 ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM), 2025, pp. 488–497
2025
-
[21]
Retrieval-augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive nlp tasks,” in Proceedings of the 34th International Conference on Neural Information Processing Systems, ser. NIPS ’20, 2020
2020
-
[22]
Training large language models to comprehend llvm ir via feedback-driven optimization,
Y . Zhang and K. Leach, “Training large language models to comprehend llvm ir via feedback-driven optimization,” inProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering, ser. FSE Companion ’25, 2025, p. 1477–1478. [Online]. Available: https://doi.org/10.1145/3696630.3731662
-
[23]
Llvm language reference manual,
LLVM, “Llvm language reference manual,” 2026, accessed: 2026-03-23. [Online]. Available: https://llvm.org/docs/LangRef.html
2026
-
[24]
Contributing to llvm - how to submit a patch,
——, “Contributing to llvm - how to submit a patch,” 2026, accessed: 2026-06-25. [Online]. Available: https://llvm.org/docs/Contributing. html#how-to-submit-a-patch
2026
-
[25]
Llvm ub-aware interpreter,
Y . Zheng, “Llvm ub-aware interpreter,” 2024. [Online]. Available: https://github.com/dtcxzyw/llvm-ub-aware-interpreter
2024
-
[26]
Githhub rest api documentation - github docs,
GitHub, “Githhub rest api documentation - github docs,” 2026, accessed: 2026-06-25. [Online]. Available: https://docs.github.com/en/ rest?apiVersion=2026-03-10
2026
-
[27]
Process-Centric Analysis of Agentic Software Systems
S. Liu, Y . Chen, R. Krishna, S. Sinha, J. Ganhotra, and R. Jabbarvand, “Process-centric analysis of agentic software systems,” 2026. [Online]. Available: https://arxiv.org/abs/2512.02393
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Google: Gemini 3.1 pro preview custom tools,
OpenRouter, “Google: Gemini 3.1 pro preview custom tools,” 2026, accessed: 2026-03-29. [Online]. Available: https://openrouter.ai/google/ gemini-3.1-pro-preview-customtools
2026
-
[29]
Deepseek-v3.2 release,
DeepSeek, “Deepseek-v3.2 release,” 2026, accessed: 2026-03-29. [Online]. Available: https://api-docs.deepseek.com/news/news251201
2026
-
[30]
Qwen3.5-plus,
A. C. M. Studio, “Qwen3.5-plus,” 2026, accessed: 2026-03-
2026
-
[31]
Available: https://modelstudio.console.alibabacloud
[Online]. Available: https://modelstudio.console.alibabacloud. com/ap-southeast-1/?tab=doc#/doc/?type=model&url=2840914_2& modelId=group-qwen3.5-plus
-
[32]
Ai code review | greptile,
I. Tabnam, “Ai code review | greptile,” 2026, accessed: 2026-03-29. [Online]. Available: https://www.greptile.com
2026
-
[33]
Gpt-5.5 | openai,
OpenAI, “Gpt-5.5 | openai,” 2026, accessed: 2026-06-28. [Online]. Available: https://openai.com/index/introducing-gpt-5-5/
2026
-
[34]
An empirical study of optimization bugs in gcc and llvm,
Z. Zhou, Z. Ren, G. Gao, and H. Jiang, “An empirical study of optimization bugs in gcc and llvm,”Journal of Systems and Software, vol. 174, p. 110884, 2021. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0164121220302740
2021
-
[35]
Optimization-directed compiler fuzzing for continuous translation validation,
J. Kwon, B. Jang, J. Lee, and K. Heo, “Optimization-directed compiler fuzzing for continuous translation validation,”Proc. ACM Program. Lang., vol. 9, no. PLDI, 2025. [Online]. Available: https://doi.org/10.1145/3729275
-
[36]
Cl-bench: A benchmark for context learning,
S. Dou, M. Zhang, Z. Yin, C. Huang, Y . Shen, J. Wang, J. Chen, Y . Ni, J. Ye, C. Zhang, H. Xie, J. Hu, S. Wang, W. Wang, Y . Xiao, Y . Liu, Z. Xu, Z. Guo, P. Zhou, T. Gui, Z. Wu, X. Qiu, Q. Zhang, X. Huang, Y .-G. Jiang, D. Wang, and S. Yao, “Cl-bench: A benchmark for context learning,” 2026. [Online]. Available: https://arxiv.org/abs/2602.03587
-
[37]
Finding and understanding bugs in c compilers,
X. Yang, Y . Chen, E. Eide, and J. Regehr, “Finding and understanding bugs in c compilers,” inProceedings of the 32nd ACM SIGPLAN Conference on Programming Language Design and Implementation, ser. PLDI ’11, 2011, p. 283–294. [Online]. Available: https: //doi.org/10.1145/1993498.1993532
-
[38]
C. Lidbury, A. Lascu, N. Chong, and A. F. Donaldson, “Many-core compiler fuzzing,” inProceedings of the 36th ACM SIGPLAN Conference on Programming Language Design and Implementation, ser. PLDI ’15, 2015, pp. 65–76. [Online]. Available: https://doi.org/10. 1145/2813885.2737986
-
[39]
Compiler testing via a theory of sound optimisations in the c11/c++11 memory model,
R. Morisset, P. Pawan, and F. Zappa Nardelli, “Compiler testing via a theory of sound optimisations in the c11/c++11 memory model,” in Proceedings of the 34th ACM SIGPLAN Conference on Programming Language Design and Implementation, ser. PLDI ’13, 2013, p. 187–196. [Online]. Available: https://doi.org/10.1145/2491956.2491967
-
[40]
Random testing for c and c++ compilers with yarpgen,
V . Livinskii, D. Babokin, and J. Regehr, “Random testing for c and c++ compilers with yarpgen,”Proc. ACM Program. Lang., vol. 4, no. OOPSLA, 2020. [Online]. Available: https://doi.org/10.1145/3428264
-
[41]
Fuzzing loop optimizations in compilers for c++ and data- parallel languages,
——, “Fuzzing loop optimizations in compilers for c++ and data- parallel languages,”Proc. ACM Program. Lang., vol. 7, no. PLDI,
-
[42]
Available: https://doi.org/10.1145/3591295
[Online]. Available: https://doi.org/10.1145/3591295
-
[43]
Compiler validation via equivalence modulo inputs,
V . Le, M. Afshari, and Z. Su, “Compiler validation via equivalence modulo inputs,” inProceedings of the 35th ACM SIGPLAN Conference on Programming Language Design and Implementation, ser. PLDI’ 14, 2014, pp. 216–226. [Online]. Available: https: //doi.org/10.1145/2666356.2594334
-
[44]
Finding deep compiler bugs via guided stochastic program mutation,
V . Le, C. Sun, and Z. Su, “Finding deep compiler bugs via guided stochastic program mutation,” inProceedings of the 2015 ACM SIGPLAN International Conference on Object-Oriented Programming, Systems, Languages, and Applications, ser. OOPSLA’ 15, 2015, pp. 386–399. [Online]. Available: https://doi.org/10.1145/2858965.2814319
-
[45]
Grayc: Greybox fuzzing of compilers and analysers for c,
K. Even-Mendoza, A. Sharma, A. F. Donaldson, and C. Cadar, “Grayc: Greybox fuzzing of compilers and analysers for c,” inProceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis, ser. ISSTA ’23, 2023, p. 1219–1231. [Online]. Available: https://doi.org/10.1145/3597926.3598130
-
[46]
Coverage-directed differential testing of jvm implementations,
Y . Chen, T. Su, C. Sun, Z. Su, and J. Zhao, “Coverage-directed differential testing of jvm implementations,” inproceedings of the 37th ACM SIGPLAN Conference on Programming Language Design and Implementation, ser. PLDI’ 16, 2016, pp. 85–99. [Online]. Available: https://doi.org/10.1145/2980983.2908095
-
[47]
Fuzzing with code fragments,
C. Holler, K. Herzig, and A. Zeller, “Fuzzing with code fragments,” in Proceedings of the 21st USENIX Conference on Security Symposium, ser. Security’12, 2012, p. 38
2012
-
[48]
Boosting compiler testing by injecting real-world code,
S. Li, T. Theodoridis, and Z. Su, “Boosting compiler testing by injecting real-world code,”Proc. ACM Program. Lang., vol. 8, no. PLDI, 2024. [Online]. Available: https://doi.org/10.1145/3656386
-
[49]
Targeted testing of compiler optimizations via grammar-level composition styles,
Z. Zhou, B. Limpanukorn, H. J. Kang, J. Wang, Y . Wu, A. Kiss, R. Hodovan, and M. Kim, “Targeted testing of compiler optimizations via grammar-level composition styles,” 2025. [Online]. Available: https://arxiv.org/abs/2512.04344
-
[50]
Validating jvm compilers via maximizing optimization interactions,
Z. Xie, M. Wen, S. Qiu, and H. Jin, “Validating jvm compilers via maximizing optimization interactions,” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 4, ser. ASPLOS ’24, 2025, p. 345–360. [Online]. Available: https://doi.org/10.1145/3622781.3674188
-
[51]
An empirical study on code review activity prediction and its impact in practice,
D. Olewicki, S. Habchi, and B. Adams, “An empirical study on code review activity prediction and its impact in practice,”Proc. ACM Softw. Eng., vol. 1, no. FSE, 2024. [Online]. Available: https://doi.org/10.1145/3660806
-
[52]
Can llms replace human evaluators? an empirical study of llm-as-a-judge in software engineering,
R. Wang, J. Guo, C. Gao, G. Fan, C. Y . Chong, and X. Xia, “Can llms replace human evaluators? an empirical study of llm-as-a-judge in software engineering,”Proc. ACM Softw. Eng., vol. 2, no. ISSTA,
-
[53]
Available: https://doi.org/10.1145/3728963
[Online]. Available: https://doi.org/10.1145/3728963
-
[54]
Code review automation: Strengths and weaknesses of the state of the art,
R. Tufano, O. Dabi ´c, A. Mastropaolo, M. Ciniselli, and G. Bavota, “Code review automation: Strengths and weaknesses of the state of the art,”IEEE Transactions on Software Engineering, vol. 50, no. 2, pp. 338–353, 2024
2024
-
[55]
CodeAgent: Autonomous communicative agents for code review,
X. Tang, K. Kim, Y . Song, C. Lothritz, B. Li, S. Ezzini, H. Tian, J. Klein, and T. F. Bissyandé, “CodeAgent: Autonomous communicative agents for code review,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 11 279–11 313. [Online]. Available: https://aclanthology.org/2024.emnlp-main.632/
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.