Understanding Software Defect Prediction: A Large-scale Empirical Study Across Uncertainty Quantification and Performance Evaluation
Pith reviewed 2026-07-03 09:16 UTC · model grok-4.3
The pith
Uncertainty quantification in software defect prediction correlates inconsistently with performance and fails to transfer reliably across projects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
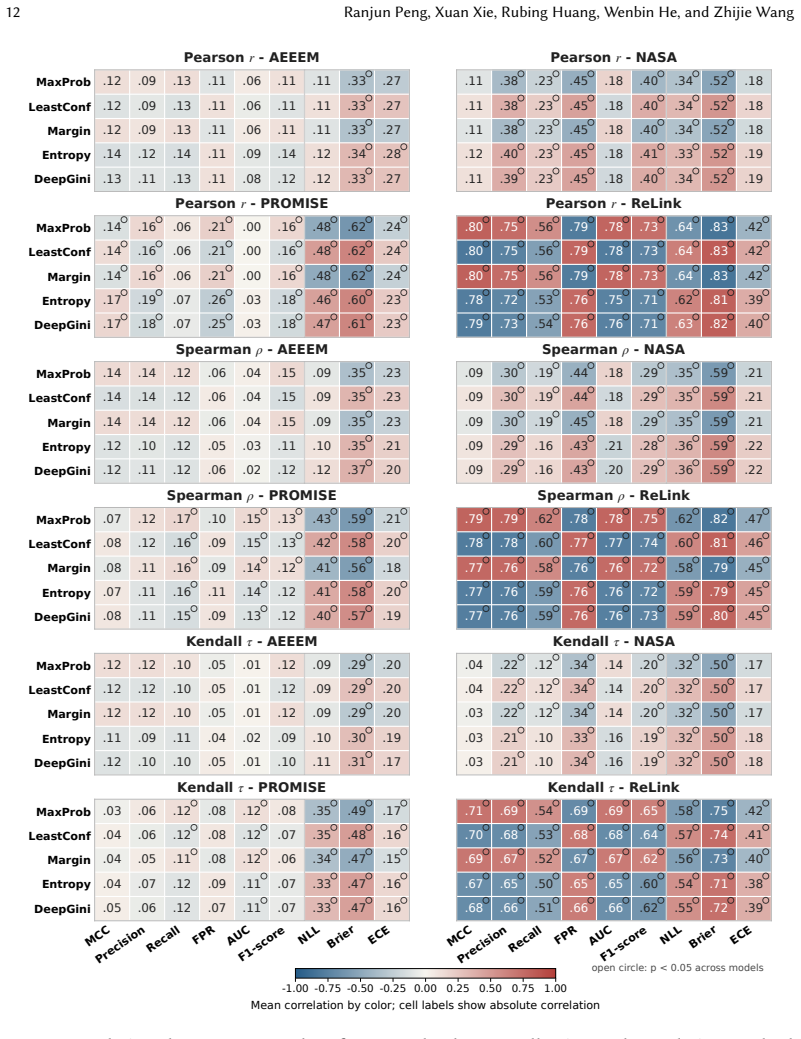
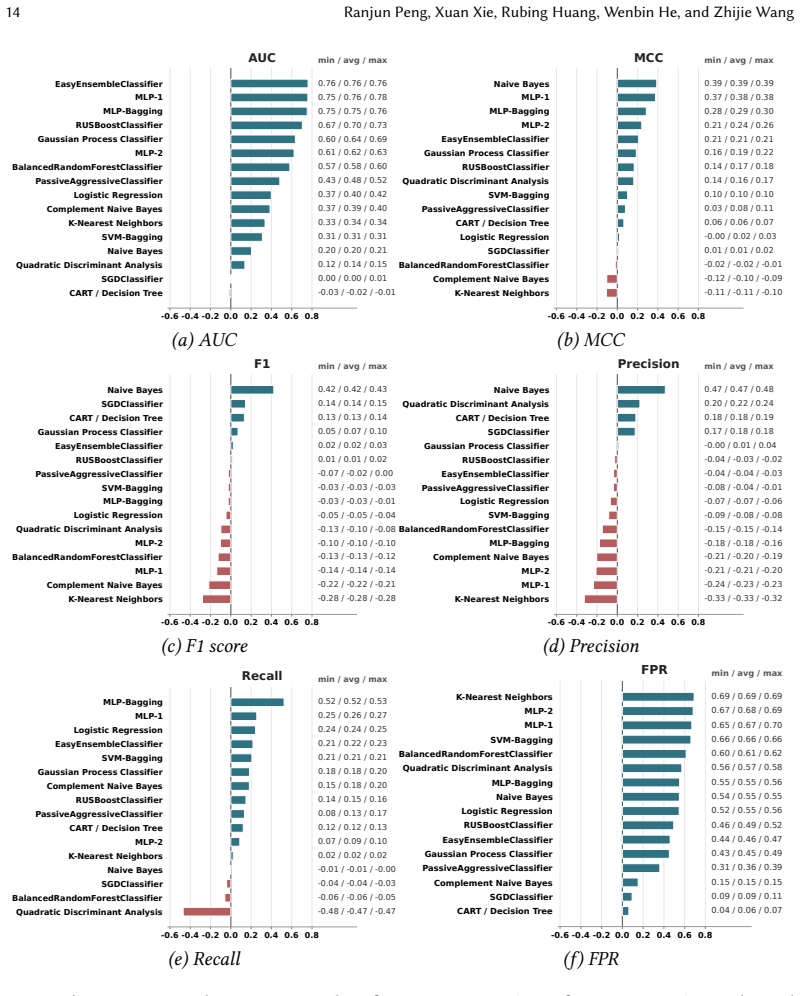
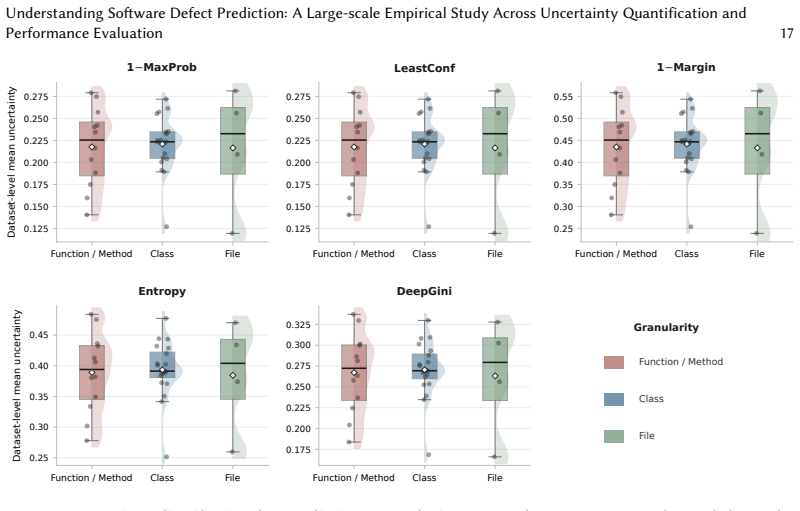
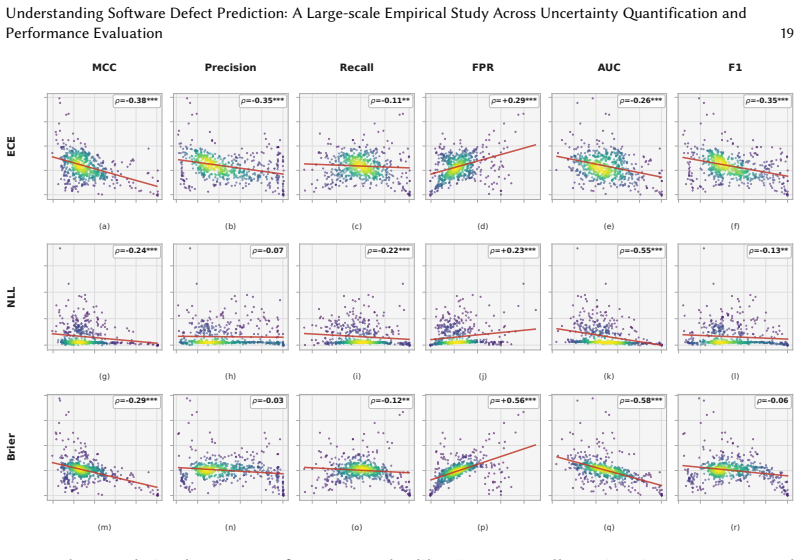
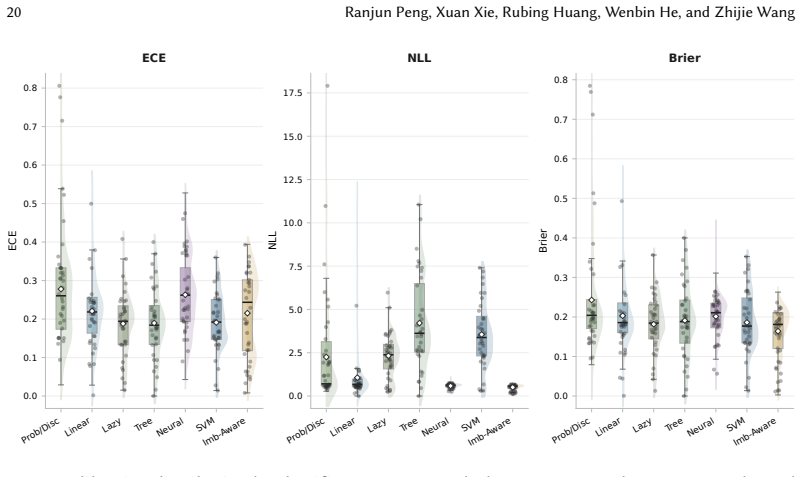
Through experiments on 16 classifiers, the study establishes that uncertainty quantification is highly context-dependent in software defect prediction. In within-project defect prediction, uncertainty metrics correlate more consistently with false positive rate and AUC than with MCC or F1 score, with these patterns also differing across classifier types and dataset collections. Classifiers can achieve strong discrimination while still showing large calibration error. In cross-project defect prediction, several uncertainty-performance and uncertainty-calibration correlations weaken or reverse, demonstrating that uncertainty signals do not reliably transfer across projects.
What carries the argument
Comparative correlation analysis of five uncertainty quantification metrics against six performance metrics and three calibration metrics under within-project and cross-project defect prediction settings.
If this is right
- Uncertainty quantification must be assessed against specific performance objectives rather than assumed to indicate performance in general.
- Calibration requires independent evaluation with multiple metrics because it is not interchangeable with discrimination performance.
- Probabilities transferred from one project to another should be revalidated before guiding quality-assurance decisions.
- Classifier category and dataset collection influence the strength of uncertainty-to-performance links.
- Context-specific checks replace any assumption of universal properties for uncertainty measures.
Where Pith is reading between the lines
- Teams could test adaptive recalibration techniques on target projects to see whether they restore reliable uncertainty signals.
- The observed pattern suggests similar evaluation needs may exist for uncertainty measures in other transferred prediction tasks.
- Practitioners might collect limited target-project data specifically to validate uncertainty metrics before model deployment.
- Methods that detect when a new project diverges enough to break existing uncertainty correlations could be developed.
Load-bearing premise
The chosen 36 benchmark datasets for within-project prediction, 32 feature-compatible datasets for cross-project prediction, and 16 representative classifiers capture sufficient real-world variability to support general claims about context-dependence.
What would settle it
A follow-up study that finds stable correlations between uncertainty quantification metrics and performance metrics when tested on a fresh, diverse collection of projects outside the original 68 datasets would challenge the context-dependence finding.
Figures
read the original abstract
Software defect prediction (SDP) classifiers produce probabilities used for inspection prioritization, threshold tuning, and risk communication. Probability-based uncertainty quantification (UQ) characterizes prediction confidence, but whether common UQ metrics reliably indicate performance and calibration remains unclear. We conducted a large-scale empirical study of probability-based UQ for SDP. We evaluated five UQ metrics, six performance metrics, and three calibration metrics for 16 representative classifiers. We analyzed these relationships under two prediction settings: within-project defect prediction (WPDP), using 36 benchmark datasets, and cross-project defect prediction (CPDP), using 32 feature-compatible datasets. Results showed that UQ was highly context-dependent. Under WPDP, UQ correlated more consistently with false positive rate and AUC than with MCC, F1 score, and other metrics; these correlations also varied across classifier categories and dataset collections. Performance and calibration were related but not interchangeable; classifiers with strong discrimination could still exhibit large calibration error. Under CPDP, several UQ-performance and UQ-calibration correlations weakened or reversed, indicating that uncertainty signals do not reliably transfer across projects. Thus, UQ should be evaluated against specific performance objectives. Calibration should be assessed independently using multiple metrics. Transferred probabilities should be revalidated before guiding quality-assurance decisions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a large-scale empirical study of probability-based uncertainty quantification (UQ) in software defect prediction (SDP). It evaluates five UQ metrics against six performance and three calibration metrics across 16 classifiers on 36 within-project (WPDP) and 32 cross-project (CPDP) datasets, concluding that UQ-performance and UQ-calibration correlations are highly context-dependent: they vary by setting (WPDP vs. CPDP), classifier category, and metric; performance and calibration are related but not interchangeable; and UQ signals weaken or reverse under CPDP, so they should be evaluated against specific objectives and revalidated when transferred.
Significance. If the results hold, the work provides a broad empirical basis for caution against assuming that UQ metrics reliably indicate performance or transfer across projects in SDP applications such as inspection prioritization. The experimental scale (36+32 datasets, 16 classifiers, multiple metric families, two settings) is a clear strength that supports observing systematic variation rather than isolated effects.
major comments (2)
- [§3.1] §3.1 (Datasets): The selection and diversity criteria for the 36 WPDP and 32 CPDP datasets (e.g., stratification by project size, language, defect density, or preprocessing steps) are not described in sufficient detail to evaluate whether the observed weakening/reversal of correlations under CPDP is a general property of uncertainty signals or specific to the chosen collections.
- [§4.3] §4.3 (CPDP results): The claim that several UQ-performance and UQ-calibration correlations 'weakened or reversed' lacks reporting of statistical significance tests, effect sizes, or multiple-comparison corrections; without these, it is unclear whether the changes are robust enough to support the non-transferability conclusion.
minor comments (2)
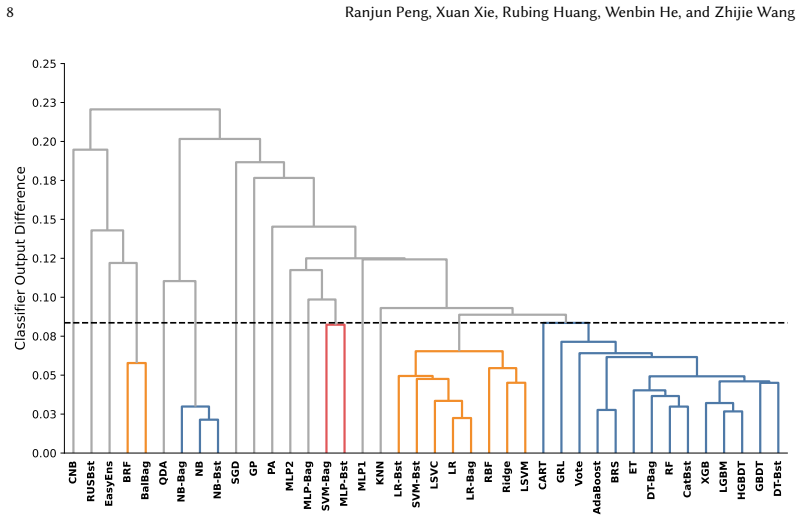
- [Table 1] Table 1: The mapping of the 16 classifiers to the four categories (e.g., which models fall under 'tree-based') should be listed explicitly for reproducibility.
- [Figure 3] Figure 3: Axis labels and color legends for the correlation heatmaps are too small to read without magnification, hindering interpretation of the WPDP vs. CPDP differences.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the positive evaluation of the study's scale and implications. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [§3.1] §3.1 (Datasets): The selection and diversity criteria for the 36 WPDP and 32 CPDP datasets (e.g., stratification by project size, language, defect density, or preprocessing steps) are not described in sufficient detail to evaluate whether the observed weakening/reversal of correlations under CPDP is a general property of uncertainty signals or specific to the chosen collections.
Authors: The datasets were selected from established public SDP benchmarks to ensure comparability with prior literature and to support feature compatibility in the CPDP setting. We agree that greater transparency on selection and diversity criteria would help readers evaluate the scope of the findings. In the revised manuscript we will expand §3.1 with an explicit description of the sources, any filtering applied for feature alignment, and summary characteristics (size, defect density, languages) of the collections. revision: yes
-
Referee: [§4.3] §4.3 (CPDP results): The claim that several UQ-performance and UQ-calibration correlations 'weakened or reversed' lacks reporting of statistical significance tests, effect sizes, or multiple-comparison corrections; without these, it is unclear whether the changes are robust enough to support the non-transferability conclusion.
Authors: We accept that formal statistical support would strengthen the comparison between settings. The current results are based on descriptive patterns across a large number of dataset-classifier combinations. In the revision we will add paired statistical tests (e.g., Wilcoxon signed-rank) on the correlation values between WPDP and CPDP, report effect sizes, and apply suitable multiple-comparison corrections to substantiate the observed weakening or reversal. revision: yes
Circularity Check
No circularity: purely empirical reporting of observed correlations on benchmark data
full rationale
This is a purely empirical study that evaluates five UQ metrics, six performance metrics, and three calibration metrics across 16 classifiers on 36 WPDP and 32 CPDP benchmark datasets, then reports the observed correlations and their variation by setting, classifier category, and metric. No derivations, equations, fitted parameters, or self-citations are invoked to support the central claims; all results follow directly from the controlled experiments on the chosen data. The representativeness assumption noted by the skeptic is a standard external-validity concern for empirical work, not a circularity issue in any derivation chain.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Statistical assumptions underlying correlation measures used to link UQ metrics with performance and calibration scores
- domain assumption The selected benchmark datasets and classifiers adequately represent the space of SDP tasks
Reference graph
Works this paper leans on
-
[1]
Moloud Abdar, Farhad Pourpanah, Sadiq Hussain, Dana Rezazadegan, Li Liu, Mohammad Ghavamzadeh, Paul Fieguth, Xiaochun Cao, Abbas Khosravi, U Rajendra Acharya, et al . 2021. A review of uncertainty quantification in deep learning: Techniques, applications and challenges.Information fusion76 (2021), 243–297
2021
-
[2]
better data
Amritanshu Agrawal and Tim Menzies. 2018. Is" better data" better than" better data miners"? on the benefits of tuning SMOTE for defect prediction. InProceedings of the 40th International Conference on Software engineering. 1050–1061
2018
-
[3]
Sousuke Amasaki. 2018. Cross-version defect prediction using cross-project defect prediction approaches: Does it work?. InProceedings of the 14th International Conference on predictive models and data analytics in software engineering. 32–41
2018
-
[4]
Rok Blagus and Lara Lusa. 2013. SMOTE for high-dimensional class-imbalanced data.BMC bioinformatics14, 1 (2013), 106
2013
-
[5]
David Bowes, Tracy Hall, and Jean Petrić. 2018. Software defect prediction: do different classifiers find the same defects?Software Quality Journal26, 2 (2018), 525–552
2018
-
[6]
Leo Breiman. 1996. Bagging predictors.Machine learning24, 2 (1996), 123–140
1996
-
[7]
Gerardo Canfora, Andrea De Lucia, Massimiliano Di Penta, Rocco Oliveto, Annibale Panichella, and Sebastiano Panichella. 2015. Defect prediction as a multiobjective optimization problem.Software Testing, Verification and Reliability25, 4 (2015), 426–459
2015
-
[8]
Cagatay Catal and Banu Diri. 2009. A systematic review of software fault prediction studies.Expert systems with applications36, 4 (2009), 7346–7354. , Vol. 1, No. 1, Article . Publication date: July 2026. Understanding Software Defect Prediction: A Large-scale Empirical Study Across Uncertainty Quantification and Performance Evaluation 27
2009
-
[9]
Andrea Dal Pozzolo, Olivier Caelen, Reid A Johnson, and Gianluca Bontempi. 2015. Calibrating Probability with Undersampling for Unbalanced Classification.. InSSCI. 159–166
2015
-
[10]
Marco D’Ambros, Michele Lanza, and Romain Robbes. 2010. An extensive comparison of bug prediction approaches. In2010 7th IEEE working conference on mining software repositories (MSR 2010). IEEE, 31–41
2010
-
[11]
Joost CF De Winter, Samuel D Gosling, and Jeff Potter. 2016. Comparing the Pearson and Spearman correlation coefficients across distributions and sample sizes: A tutorial using simulations and empirical data.Psychological methods21, 3 (2016), 273
2016
-
[12]
Ran El-Yaniv et al. 2010. On the Foundations of Noise-free Selective Classification.Journal of Machine Learning Research11, 5 (2010)
2010
-
[13]
T Elhassan, M Aljurf, et al. 2016. Classification of imbalance data using tomek link (t-link) combined with random under-sampling (rus) as a data reduction method.Global J Technol Optim S1, S1 (2016)
2016
-
[14]
Yuanrui Fan, Xin Xia, Daniel Alencar Da Costa, David Lo, Ahmed E Hassan, and Shanping Li. 2019. The impact of mislabeled changes by szz on just-in-time defect prediction.IEEE transactions on software engineering47, 8 (2019), 1559–1586
2019
-
[15]
Yang Feng, Qingkai Shi, Xinyu Gao, Jun Wan, Chunrong Fang, and Zhenyu Chen. 2020. Deepgini: prioritizing massive tests to enhance the robustness of deep neural networks. InProceedings of the 29th ACM SIGSOFT international symposium on software testing and analysis. 177–188
2020
-
[16]
Yarin Gal and Zoubin Ghahramani. 2016. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. Ininternational conference on machine learning. PMLR, 1050–1059
2016
-
[17]
Baljinder Ghotra, Shane McIntosh, and Ahmed E Hassan. 2015. Revisiting the impact of classification techniques on the performance of defect prediction models. In2015 IEEE/ACM 37th IEEE International Conference on Software Engineering, Vol. 1. IEEE, 789–800
2015
-
[18]
W Brier Glenn et al. 1950. Verification of forecasts expressed in terms of probability.Monthly weather review78, 1 (1950), 1–3
1950
-
[19]
Tilmann Gneiting and Adrian E Raftery. 2007. Strictly proper scoring rules, prediction, and estimation.Journal of the American statistical Association102, 477 (2007), 359–378
2007
-
[20]
Lina Gong, Haoxiang Zhang, Jingxuan Zhang, Mingqiang Wei, and Zhiqiu Huang. 2022. A comprehensive investigation of the impact of class overlap on software defect prediction.IEEE transactions on software engineering49, 4 (2022), 2440–2458
2022
-
[21]
Somya R Goyal. 2025. Current Trends in Class Imbalance Learning for Software Defect Prediction.IEEE Access(2025)
2025
-
[22]
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. 2017. On calibration of modern neural networks. In International conference on machine learning. PMLR, 1321–1330
2017
-
[23]
Tracy Hall, Sarah Beecham, David Bowes, David Gray, and Steve Counsell. 2011. A systematic literature review on fault prediction performance in software engineering.IEEE Transactions on Software Engineering38, 6 (2011), 1276–1304
2011
-
[24]
Hui Han, Wen-Yuan Wang, and Bing-Huan Mao. 2005. Borderline-SMOTE: a new over-sampling method in imbalanced data sets learning. InInternational conference on intelligent computing. Springer, 878–887
2005
-
[25]
Ahmed E Hassan. 2009. Predicting faults using the complexity of code changes. In2009 IEEE 31st international conference on software engineering. IEEE, 78–88
2009
-
[26]
Haibo He, Yang Bai, Edwardo A Garcia, and Shutao Li. 2008. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In2008 IEEE international joint conference on neural networks (IEEE world congress on computational intelligence). Ieee, 1322–1328
2008
-
[27]
Wenchong He, Zhe Jiang, Tingsong Xiao, Zelin Xu, and Yukun Li. 2025. A survey on uncertainty quantification methods for deep learning.Comput. Surveys(2025)
2025
-
[28]
Dan Hendrycks and Kevin Gimpel. 2016. A baseline for detecting misclassified and out-of-distribution examples in neural networks.arXiv preprint arXiv:1610.02136(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[29]
Eyke Hüllermeier and Willem Waegeman. 2021. Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods.Machine learning110, 3 (2021), 457–506
2021
-
[30]
Xiaolin Ju, Yi Cao, Xiang Chen, Lina Gong, Vaskar Chakma, and Xin Zhou. 2025. JIT-CF: Integrating contrastive learning with feature fusion for enhanced just-in-time defect prediction.Information and Software Technology182 (2025), 107706
2025
-
[31]
Marian Jureczko and Lech Madeyski. 2010. Towards identifying software project clusters with regard to defect prediction. InProceedings of the 6th international conference on predictive models in software engineering. 1–10
2010
-
[32]
Maurice G Kendall. 1938. A new measure of rank correlation.Biometrika30, 1-2 (1938), 81–93
1938
-
[33]
Sunghun Kim, Hongyu Zhang, Rongxin Wu, and Liang Gong. 2011. Dealing with noise in defect prediction. In Proceedings of the 33rd international conference on software engineering. 481–490
2011
-
[34]
Ludmila I Kuncheva and Christopher J Whitaker. 2003. Measures of diversity in classifier ensembles and their relationship with the ensemble accuracy.Machine learning51, 2 (2003), 181–207. , Vol. 1, No. 1, Article . Publication date: July 2026. 28 Ranjun Peng, Xuan Xie, Rubing Huang, Wenbin He, and Zhijie Wang
2003
-
[35]
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. 2017. Simple and scalable predictive uncertainty estimation using deep ensembles.Advances in neural information processing systems30 (2017)
2017
-
[36]
Issam H Laradji, Mohammad Alshayeb, and Lahouari Ghouti. 2015. Software defect prediction using ensemble learning on selected features.Information and Software Technology58 (2015), 388–402
2015
-
[37]
Stefan Lessmann, Bart Baesens, Christophe Mues, and Swantje Pietsch. 2008. Benchmarking classification models for software defect prediction: A proposed framework and novel findings.IEEE transactions on software engineering34, 4 (2008), 485–496
2008
-
[38]
David D Lewis. 1995. A sequential algorithm for training text classifiers: Corrigendum and additional data. InAcm sigir forum, Vol. 29. ACM New York, NY, USA, 13–19
1995
-
[39]
Ke Li, Zilin Xiang, Tao Chen, Shuo Wang, and Kay Chen Tan. 2020. Understanding the automated parameter optimization on transfer learning for cross-project defect prediction: an empirical study. InProceedings of the ACM/IEEE 42nd International Conference on Software Engineering. 566–577
2020
-
[40]
Zhiqiang Li, Xiao-Yuan Jing, and Xiaoke Zhu. 2018. Progress on approaches to software defect prediction.Iet Software 12, 3 (2018), 161–175
2018
-
[41]
Wangshu Liu, Ye Yue, Xiang Chen, Qing Gu, Pengzhan Zhao, Xuejun Liu, and Jianjun Zhao. 2024. SeDPGK: Semi- supervised software defect prediction with graph representation learning and knowledge distillation.Information and Software Technology174 (2024), 107510
2024
-
[42]
Ana C Lorena, Luís PF Garcia, Jens Lehmann, Marcilio CP Souto, and Tin Kam Ho. 2019. How complex is your classification problem? a survey on measuring classification complexity.ACM Computing Surveys (CSUR)52, 5 (2019), 1–34
2019
-
[43]
Wei Ma, Mike Papadakis, Anestis Tsakmalis, Maxime Cordy, and Yves Le Traon. 2021. Test selection for deep learning systems.ACM Transactions on Software Engineering and Methodology (TOSEM)30, 2 (2021), 1–22
2021
-
[44]
Faseeha Matloob, Taher M Ghazal, Nasser Taleb, Shabib Aftab, Munir Ahmad, Muhammad Adnan Khan, Sagheer Abbas, and Tariq Rahim Soomro. 2021. Software defect prediction using ensemble learning: A systematic literature review.IEEe Access9 (2021), 98754–98771
2021
-
[45]
Tim Menzies, Jeremy Greenwald, and Art Frank. 2007. Data mining static code attributes to learn defect predictors. IEEE transactions on software engineering33, 1 (2007), 2–13
2007
-
[46]
Tim Menzies, Zach Milton, Burak Turhan, Bojan Cukic, Yue Jiang, and Ayse Bener. 2010. Defect prediction from static code features: current results, limitations, new approaches.Automated Software Engineering17, 4 (2010), 375–407
2010
-
[47]
Matthias Minderer, Josip Djolonga, Rob Romijnders, Frances Hubis, Xiaohua Zhai, Neil Houlsby, Dustin Tran, and Mario Lucic. 2021. Revisiting the calibration of modern neural networks.Advances in neural information processing systems34 (2021), 15682–15694
2021
-
[48]
Raimund Moser, Witold Pedrycz, and Giancarlo Succi. 2008. A comparative analysis of the efficiency of change metrics and static code attributes for defect prediction. InProceedings of the 30th international conference on Software engineering. 181–190
2008
-
[49]
Nachiappan Nagappan and Thomas Ball. 2005. Use of relative code churn measures to predict system defect density. InProceedings of the 27th international conference on Software engineering. 284–292
2005
-
[50]
Jaechang Nam and Sunghun Kim. 2015. Heterogeneous defect prediction. InProceedings of the 2015 10th joint meeting on foundations of software engineering. 508–519
2015
-
[51]
Jaechang Nam, Sinno Jialin Pan, and Sunghun Kim. 2013. Transfer defect learning. In2013 35th international conference on software engineering (ICSE). IEEE, 382–391
2013
-
[52]
Alexandru Niculescu-Mizil and Rich Caruana. 2005. Predicting good probabilities with supervised learning. In Proceedings of the 22nd international conference on Machine learning. 625–632
2005
-
[53]
Jeremy Nixon, Michael W Dusenberry, Linchuan Zhang, Ghassen Jerfel, and Dustin Tran. 2019. Measuring calibration in deep learning.. InCVPR workshops, Vol. 2
2019
-
[54]
Safa Omri and Carsten Sinz. 2020. Deep learning for software defect prediction: A survey. InProceedings of the IEEE/ACM 42nd international conference on software engineering workshops. 209–214
2020
-
[55]
Yaniv Ovadia, Emily Fertig, Jie Ren, Zachary Nado, David Sculley, Sebastian Nowozin, Joshua Dillon, Balaji Lakshmi- narayanan, and Jasper Snoek. 2019. Can you trust your model’s uncertainty? evaluating predictive uncertainty under dataset shift.Advances in neural information processing systems32 (2019)
2019
-
[56]
Muhammed Maruf Öztürk. 2017. Which type of metrics are useful to deal with class imbalance in software defect prediction?Information and Software Technology92 (2017), 17–29
2017
-
[57]
John Platt et al. 1999. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods.Advances in large margin classifiers10, 3 (1999), 61–74
1999
-
[58]
Shaoming Qiu, Bicong E, and Jingjie He. 2025. Features extraction and fusion by attention mechanism for software defect prediction.PloS one20, 4 (2025), e0320808. , Vol. 1, No. 1, Article . Publication date: July 2026. Understanding Software Defect Prediction: A Large-scale Empirical Study Across Uncertainty Quantification and Performance Evaluation 29
2025
-
[59]
Tobias Scheffer, Christian Decomain, and Stefan Wrobel. 2001. Active hidden markov models for information extraction. InInternational symposium on intelligent data analysis. Springer, 309–318
2001
-
[60]
Patrick Schober, Christa Boer, and Lothar A Schwarte. 2018. Correlation coefficients: appropriate use and interpretation. Anesthesia & analgesia126, 5 (2018), 1763–1768
2018
-
[61]
Xhulja Shahini, Jone Bartel, and Klaus Pohl. 2025. On the calibration of Just-in-time Defect Prediction. In2025 IEEE/ACM 22nd International Conference on Mining Software Repositories (MSR). IEEE, 14–26
2025
-
[62]
Xhulja Shahini, Andreas Metzger, and Klaus Pohl. 2024. An Empirical Study on Just-in-time Conformal Defect Prediction. InProceedings of the 21st International Conference on Mining Software Repositories. 88–99
2024
-
[63]
Claude Elwood Shannon. 1948. A mathematical theory of communication.The Bell system technical journal27, 3 (1948), 379–423
1948
-
[64]
Martin Shepperd, Qinbao Song, Zhongbin Sun, and Carolyn Mair. 2013. Data quality: Some comments on the nasa software defect datasets.IEEE Transactions on software engineering39, 9 (2013), 1208–1215
2013
-
[65]
Michael R Smith, Tony Martinez, and Christophe Giraud-Carrier. 2014. An instance level analysis of data complexity. Machine learning95, 2 (2014), 225–256
2014
-
[66]
Charles Spearman. 1961. The proof and measurement of association between two things. (1961)
1961
-
[67]
Chakkrit Tantithamthavorn, Shane McIntosh, Ahmed E Hassan, and Kenichi Matsumoto. 2016. Automated parameter optimization of classification techniques for defect prediction models. InProceedings of the 38th international conference on software engineering. 321–332
2016
-
[68]
Chakkrit Tantithamthavorn, Shane McIntosh, Ahmed E Hassan, and Kenichi Matsumoto. 2016. An empirical comparison of model validation techniques for defect prediction models.IEEE Transactions on Software Engineering43, 1 (2016), 1–18
2016
-
[69]
Chakkrit Tantithamthavorn, Shane McIntosh, Ahmed E Hassan, and Kenichi Matsumoto. 2018. The impact of automated parameter optimization on defect prediction models.IEEE Transactions on Software Engineering45, 7 (2018), 683–711
2018
-
[70]
Ruben Van den Goorbergh, Maarten Van Smeden, Dirk Timmerman, and Ben Van Calster. 2022. The harm of class imbalance corrections for risk prediction models: illustration and simulation using logistic regression.Journal of the American Medical Informatics Association29, 9 (2022), 1525–1534
2022
-
[71]
Xiaohui Wan, Zheng Zheng, Fangyun Qin, and Xuhui Lu. 2024. Data complexity: a new perspective for analyzing the difficulty of defect prediction tasks.ACM Transactions on Software Engineering and Methodology33, 6 (2024), 1–45
2024
-
[72]
Shuo Wang and Xin Yao. 2013. Using class imbalance learning for software defect prediction.IEEE Transactions on Reliability62, 2 (2013), 434–443
2013
-
[73]
Michael Weiss and Paolo Tonella. 2022. Simple techniques work surprisingly well for neural network test prioritization and active learning (replicability study). InProceedings of the 31st ACM SIGSOFT international symposium on software testing and analysis. 139–150
2022
-
[74]
Rongxin Wu, Hongyu Zhang, Sunghun Kim, and Shing-Chi Cheung. 2011. Relink: recovering links between bugs and changes. InProceedings of the 19th ACM SIGSOFT symposium and the 13th European conference on Foundations of software engineering. 15–25
2011
-
[75]
Ting-Fan Wu, Chih-Jen Lin, and Ruby C Weng. 2004. Probability estimates for multi-class classification by pairwise coupling.Journal of Machine Learning Research5, Aug (2004), 975–1005
2004
- [76]
-
[77]
Chunqiu Steven Xia, Yuxiang Wei, and Lingming Zhang. 2023. Automated program repair in the era of large pre-trained language models. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 1482–1494
2023
-
[78]
Aidan ZH Yang, Sophia Kolak, Vincent Hellendoorn, Ruben Martins, and Claire Le Goues. 2025. Revisiting unnaturalness for automated program repair in the era of large language models. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE, 2561–2573
2025
-
[79]
Zezhi Ye, Chenghai Yu, and Zhilong Lu. 2025. Software Defect Prediction Model Based on AST and Deep Learning. Scalable Computing: Practice and Experience26, 5 (2025), 2183–2195
2025
-
[80]
Xiao Yu, Jiqing Rao, Lei Liu, Guancheng Lin, Wenhua Hu, Jacky Wai Keung, Junwei Zhou, and Jianwen Xiang. 2024. Improving effort-aware defect prediction by directly learning to rank software modules.Information and Software Technology165 (2024), 107250
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.