Diversity-aware View Partitioning for Scalable VGGT
Pith reviewed 2026-07-03 16:09 UTC · model grok-4.3
The pith
Partitioning input views by visual dissimilarity and spatial dispersion lets VGGT scale to large collections with better accuracy and lower memory cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
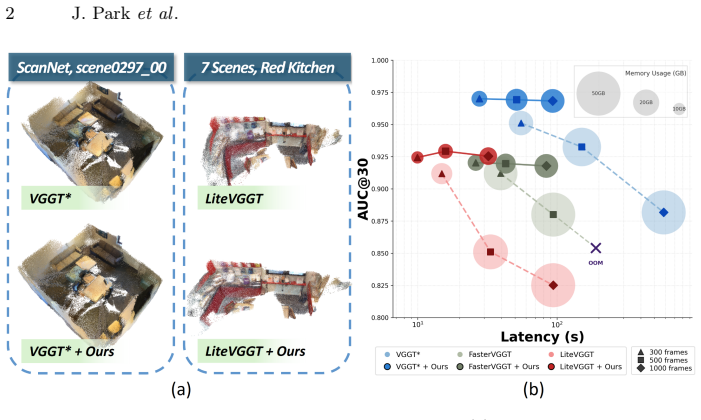
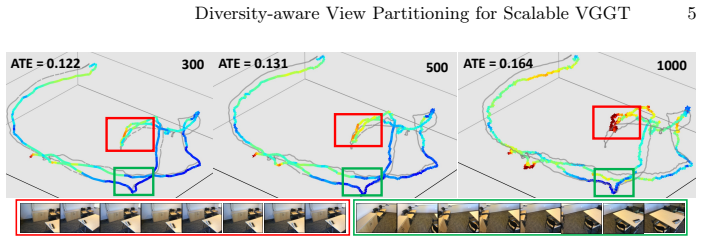
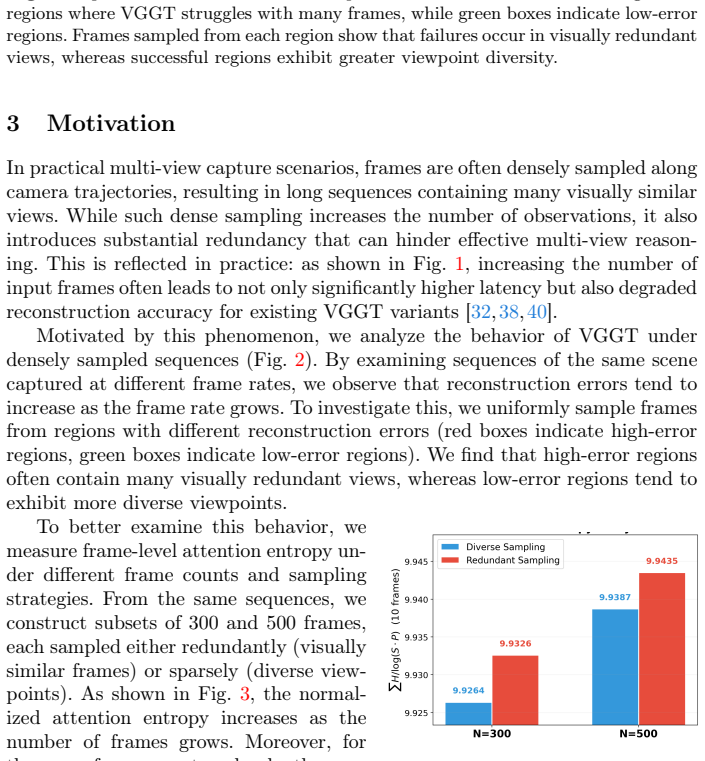
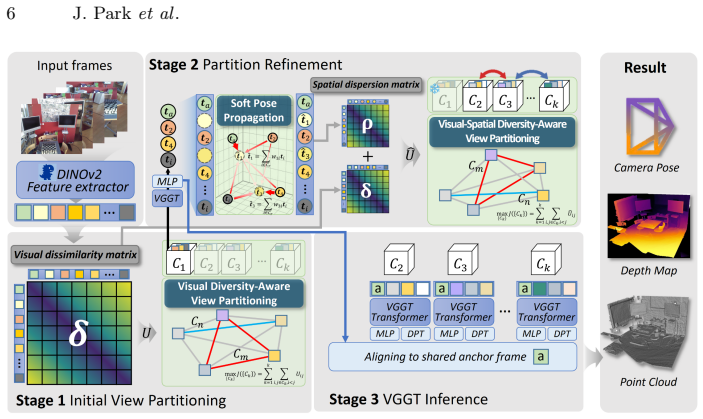
The central claim is that constructing diversity-aware balanced chunks through combinatorial graph partitioning over visual dissimilarity and approximated spatial dispersion allows the transformer to focus attention on geometrically informative views, reduces redundant interactions, and thereby improves camera pose estimation, multi-view depth prediction, and 3D reconstruction while lowering memory usage and inference latency, all in a training-free plug-and-play manner.
What carries the argument
Combinatorial graph partitioning over visual dissimilarity and spatial dispersion, with spatial dispersion obtained via soft pose propagation from a small set of seed frames using visual similarity.
If this is right
- Camera pose estimation accuracy rises because attention operates on geometrically distinct rather than redundant views.
- Multi-view depth prediction improves as geometric signals are no longer diluted by near-duplicate tokens.
- 3D reconstruction quality increases while peak memory and inference latency decrease.
- The same partitioning works as a drop-in addition to existing VGGT variants without retraining.
- Collections of hundreds of views become computationally feasible without the quality drop previously observed from redundancy.
Where Pith is reading between the lines
- The same partitioning idea could be tested on other global-attention multi-view architectures to check whether the benefit is specific to VGGT or general.
- If the soft propagation proves reliable, it suggests that explicit pose estimation can sometimes be skipped for the narrower task of view selection.
- Iteratively refining the seed set during capture might further tighten the dispersion estimate in large or complex scenes.
- The method implies a possible online strategy: reject incoming frames whose visual similarity to existing chunks is too high.
Load-bearing premise
The soft pose propagation from a small set of seed frames based on visual similarity produces a sufficiently accurate approximation of spatial dispersion to guide effective partitioning.
What would settle it
Apply the partitioning on a dataset containing repetitive textures where the visual-similarity propagation visibly mismatches true camera positions, then compare reconstruction metrics against both random partitioning and the full unpartitioned baseline.
Figures



read the original abstract
Geometry transformers such as VGGT achieve strong performance by jointly reasoning over multiple views with global attention. However, scaling them to large view collections remains challenging due to the quadratic cost of attention. Moreover, our empirical analysis reveals that the reconstruction quality in VGGT is sensitive to the distribution of viewpoints. Simply increasing the number of views without sufficient viewpoint diversity can even degrade performance, as redundant views introduce highly similar tokens that dilute informative geometric signals in the attention mechanism. Motivated by this observation, we propose a training-free and plug-and-play VGGT inference framework that organizes views into diversity-aware balanced chunks. The chunks are constructed through combinatorial graph partitioning over visual dissimilarity and spatial dispersion. This view organization allows the transformer to focus attention on geometrically informative views while reducing redundant attention interactions. To estimate spatial dispersion without full pose estimation, we approximate spatial relationships via a soft pose propagation strategy based on visual similarity from a small set of seed frames. Extensive experiments demonstrate improved performance in camera pose estimation, multi-view depth prediction, and 3D reconstruction while reducing memory usage and inference latency. Our framework also complements existing VGGT variants, enabling scalable multi-view reconstruction without sacrificing geometric fidelity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a training-free, plug-and-play inference framework for VGGT that partitions input views into diversity-aware balanced chunks via combinatorial graph partitioning over visual dissimilarity plus an approximated spatial dispersion term. The spatial dispersion is obtained by soft pose propagation from a small set of seed frames using only visual similarity. The claimed benefit is that the resulting chunks let the transformer focus attention on geometrically informative views, yielding gains in camera pose estimation, multi-view depth prediction, and 3D reconstruction together with lower memory and latency.
Significance. If the empirical results hold and the partitioning is shown to be robust, the work would provide a practical way to scale global-attention geometry transformers beyond small view counts without retraining, addressing both quadratic cost and the observed degradation from redundant viewpoints.
major comments (2)
- [Abstract / method description of soft pose propagation] The central claim that the diversity-aware chunks produce the reported gains rests on the soft pose propagation strategy yielding a sufficiently accurate proxy for spatial dispersion. The manuscript must supply ablations that compare the full method against (i) visual-similarity-only partitioning and (ii) random balanced chunks on the same backbones and datasets; without these controls it is impossible to attribute improvements to the spatial-dispersion term rather than to chunking in general.
- [Abstract / experimental section] No quantitative results, error bars, dataset statistics, or ablation tables appear in the abstract, and the provided text supplies none of the concrete numbers needed to evaluate the claimed improvements in pose estimation, depth, or reconstruction. The load-bearing experimental evidence must be presented with direct comparisons to the unpartitioned VGGT baseline.
minor comments (1)
- [Method] Clarify whether the combinatorial graph partitioning introduces any tunable hyperparameters (e.g., relative weighting between dissimilarity and dispersion terms) and, if so, how they are set across experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below, clarifying the experimental support in the full manuscript and committing to targeted revisions.
read point-by-point responses
-
Referee: [Abstract / method description of soft pose propagation] The central claim that the diversity-aware chunks produce the reported gains rests on the soft pose propagation strategy yielding a sufficiently accurate proxy for spatial dispersion. The manuscript must supply ablations that compare the full method against (i) visual-similarity-only partitioning and (ii) random balanced chunks on the same backbones and datasets; without these controls it is impossible to attribute improvements to the spatial-dispersion term rather than to chunking in general.
Authors: We agree that isolating the contribution of the approximated spatial dispersion term is important for validating the central claim. The current experiments focus on the complete diversity-aware partitioning pipeline, but we will add the requested ablations in the revised manuscript: direct comparisons of the full method against (i) visual-similarity-only partitioning and (ii) random balanced chunks, evaluated on the same backbones and datasets. These will be presented alongside the existing results to attribute gains specifically to the spatial dispersion component. revision: yes
-
Referee: [Abstract / experimental section] No quantitative results, error bars, dataset statistics, or ablation tables appear in the abstract, and the provided text supplies none of the concrete numbers needed to evaluate the claimed improvements in pose estimation, depth, or reconstruction. The load-bearing experimental evidence must be presented with direct comparisons to the unpartitioned VGGT baseline.
Authors: The full manuscript contains quantitative results, including direct comparisons to the unpartitioned VGGT baseline, along with dataset statistics in the experimental section. To address the concern about accessibility, we will revise the abstract to incorporate key quantitative improvements (with error bars where reported), dataset statistics, and explicit mention of the baseline comparisons. This will make the load-bearing evidence visible at the abstract level without altering the core claims. revision: partial
Circularity Check
No circularity detected in the proposed framework
full rationale
The manuscript describes a training-free plug-and-play inference method that partitions views via combinatorial graph partitioning on visual dissimilarity plus an approximated spatial dispersion term obtained from soft pose propagation on seed frames. No equations, derivations, or fitted parameters are shown that reduce the claimed performance gains (in pose estimation, depth prediction, or reconstruction) to quantities defined by the method itself or to self-citations whose validity depends on the present work. The approach is presented as a heuristic organization strategy whose value is asserted through external experiments rather than by algebraic identity or load-bearing self-reference; therefore the derivation chain remains self-contained against the listed circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: CVPR (2022) 10, 12, 13, 14, 19, 21, 22, 23, 24, 26, 27, 28, 29, 30
Azinović, D., Martin-Brualla, R., Goldman, D.B., Nießner, M., Thies, J.: Neural rgb-d surface reconstruction. In: CVPR (2022) 10, 12, 13, 14, 19, 21, 22, 23, 24, 26, 27, 28, 29, 30
2022
-
[2]
In: CVPR Work- shop
Berton, G., Masone, C.: Megaloc: One retrieval to place them all. In: CVPR Work- shop. pp. 2861–2867 (2025) 21
2025
-
[3]
In: ICLR (2023) 2
Bolya, D., Fu, C.Y., Dai, X., Zhang, P., Feichtenhofer, C., Hoffman, J.: Token merging: Your vit but faster. In: ICLR (2023) 2
2023
-
[4]
In: CVPR
Cabon, Y., Stoffl, L., Antsfeld, L., Csurka, G., Chidlovskii, B., Revaud, J., Leroy, V.: Must3r: Multi-view network for stereo 3d reconstruction. In: CVPR. pp. 1050– 1060 (2025) 12, 13
2025
-
[5]
In: CVPR
Chen, X., Li, Q., Wang, T., Xue, T., Pang, J.: Gennbv: Generalizable next-best- view policy for active 3d reconstruction. In: CVPR. pp. 16436–16445 (2024) 4
2024
-
[6]
In: ICRA (1985) 4
Connolly, C.: The determination of next best views. In: ICRA (1985) 4
1985
-
[7]
In: CVPR (2017) 10, 12, 19, 27, 28, 29, 31, 32
Dai,A.,Chang,A.X.,Savva,M.,Halber,M.,Funkhouser,T.,Nießner,M.:Scannet: Richly-annotated 3d reconstructions of indoor scenes. In: CVPR (2017) 10, 12, 19, 27, 28, 29, 31, 32
2017
-
[8]
In: ICRA (2026) 2, 4, 12, 13, 25
Deng, K., Ti, Z., Xu, J., Yang, J., Xie, J.: Vggt-long: Chunk it, loop it, align it – pushing vggt’s limits on kilometer-scale long rgb sequences. In: ICRA (2026) 2, 4, 12, 13, 25
2026
-
[9]
In: ECCV
Izquierdo, S., Civera, J.: Close, but not there: Boosting geographic distance sensi- tivity in visual place recognition. In: ECCV. pp. 240–257. Springer (2024) 23
2024
-
[10]
In: CVPR (June 2024) 21
Izquierdo,S.,Civera,J.:Optimaltransportaggregationforvisualplacerecognition. In: CVPR (June 2024) 21
2024
-
[11]
arXiv preprint arXiv:2510.23928 (2025) 4
Jha, R., Zhou, Y., Loianno, G.: Adaptive keyframe selection for scalable 3d scene reconstruction in dynamic environments. arXiv preprint arXiv:2510.23928 (2025) 4
-
[12]
In: CVPR (2026) 2
Kang, G., Yang, S., Nam, S., Lee, Y., Kim, J., Park, E.: Multi-view pyramid transformer: Look coarser to see broader. In: CVPR (2026) 2
2026
-
[13]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Keetha, N., Karhade, J., Jatavallabhula, K.M., Yang, G., Scherer, S., Ramanan, D., Luiten, J.: Splatam: Splat track & map 3d gaussians for dense rgb-d slam. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 21357–21366 (2024) 4
2024
-
[14]
The Bell System Technical Journal49(2), 291–307 (1970) 4, 8, 14, 20
Kernighan, B.W., Lin, S.: An efficient heuristic procedure for partitioning graphs. The Bell System Technical Journal49(2), 291–307 (1970) 4, 8, 14, 20
1970
-
[15]
In: CVPR
Kim, Y., Song, W., Lew, J., Hwangbo, H., Lee, J., Yoon, S.: Hess: Head sensitivity score for sparsity redistribution in vggt. In: CVPR. pp. 36509–36517 (2026) 2
2026
-
[16]
ACM Transactions on Graphics36(4) (2017) 10, 12, 13, 20, 24
Knapitsch, A., Park, J., Zhou, Q.Y., Koltun, V.: Tanks and temples: Benchmarking large-scale scene reconstruction. ACM Transactions on Graphics36(4) (2017) 10, 12, 13, 20, 24
2017
-
[17]
arXiv preprint arXiv:2511.18290 (2025) 2, 4
Lee, J., Lee, M., Yang, S., Kang, M., Lee, S.: Swiftvggt: A scalable visual geom- etry grounded transformer for large-scale scenes. arXiv preprint arXiv:2511.18290 (2025) 2, 4
-
[18]
In: ECCV (2024) 4
Leroy, V., Cabon, Y., Revaud, J.: Grounding image matching in 3d with mast3r. In: ECCV (2024) 4
2024
-
[19]
In: ICCV
Li, X., Rao, T., Pan, C.: Edm: Efficient deep feature matching. In: ICCV. pp. 26198–26208 (2025) 4
2025
-
[20]
In: ICCV (2023) 4 Diversity-aware View Partitioning for Scalable VGGT 17
Lindenberger, P., Sarlin, P.E., Pollefeys, M.: LightGlue: Local Feature Matching at Light Speed. In: ICCV (2023) 4 Diversity-aware View Partitioning for Scalable VGGT 17
2023
-
[21]
IEEE transactions on robotics31(5), 1147–1163 (2015) 4
Mur-Artal, R., Montiel, J.M.M., Tardos, J.D.: Orb-slam: A versatile and accurate monocular slam system. IEEE transactions on robotics31(5), 1147–1163 (2015) 4
2015
-
[22]
TMLR (2024) 4, 7, 21, 23
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. TMLR (2024) 4, 7, 21, 23
2024
-
[23]
In: IROS (2019) 10, 11, 19, 26, 27
Palazzolo, E., Behley, J., Lottes, P., Giguere, P., Stachniss, C.: Refusion: 3d re- construction in dynamic environments for rgb-d cameras exploiting residuals. In: IROS (2019) 10, 11, 19, 26, 27
2019
-
[24]
In: ECCV (2024) 4
Pan, L., Barath, D., Pollefeys, M., Schönberger, J.L.: Global Structure-from- Motion Revisited. In: ECCV (2024) 4
2024
-
[25]
In: ICCV (2021) 7
Ranftl, R., Bochkovskiy, A., Koltun, V.: Vision transformers for dense prediction. In: ICCV (2021) 7
2021
-
[26]
In: CVPR
Sarlin, P.E., DeTone, D., Malisiewicz, T., Rabinovich, A.: Superglue: Learning feature matching with graph neural networks. In: CVPR. pp. 4938–4947 (2020) 4
2020
-
[27]
In: CVPR (2016) 4, 19
Schönberger, J.L., Frahm, J.M.: Structure-from-motion revisited. In: CVPR (2016) 4, 19
2016
-
[28]
Psychometrika31(1), 1–10 (1966) 25
Schönemann, P.H.: A generalized solution of the orthogonal procrustes problem. Psychometrika31(1), 1–10 (1966) 25
1966
-
[29]
ACM Computing Surveys35(1), 64–96 (2003) 4
Scott, W.R., Roth, G., Rivest, J.F.: View planning for automated three- dimensional object reconstruction and inspection. ACM Computing Surveys35(1), 64–96 (2003) 4
2003
-
[30]
In: ICLR (2026),https://openreview.net/forum? id=asl8NJlIMe2, 3, 4, 10, 13, 19
Shen, Y., Zhang, Z., Qu, Y., Zheng, X., Ji, J., Zhang, S., Cao, L.: FastVGGT: Fast visual geometry transformer. In: ICLR (2026),https://openreview.net/forum? id=asl8NJlIMe2, 3, 4, 10, 13, 19
2026
-
[31]
In: CVPR (2013) 10, 11, 12, 14, 15, 19, 20, 22, 23, 27, 34
Shotton, J., Glocker, B., Zach, C., Izadi, S., Criminisi, A., Fitzgibbon, A.: Scene coordinate regression forests for camera relocalization in rgb-d images. In: CVPR (2013) 10, 11, 12, 14, 15, 19, 20, 22, 23, 27, 34
2013
-
[32]
In: CVPR
Shu, Z., Lin, C., Xie, T., Yin, W., Li, B., Pu, Z., Li, W., Yao, Y., Cao, X., Guo, X., Long, X.X.: Litevggt: Boosting vanilla vggt via geometry-aware cached token merging. In: CVPR. pp. 36422–36432 (June 2026) 2, 3, 4, 5, 10, 11, 12, 13, 26, 27, 28
2026
-
[33]
Splatt3R: Zero-shot Gaussian Splatting from Uncalibrated Image Pairs
Smart, B., Zheng, C., Laina, I., Prisacariu, V.A.: Splatt3r: Zero-shot gaussian splatting from uncalibrated image pairs. arXiv preprint arXiv:2408.13912 (2024) 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
In: IROS (Oct 2012) 10, 12, 13, 19, 21, 24
Sturm, J., Engelhard, N., Endres, F., Burgard, W., Cremers, D.: A benchmark for the evaluation of rgb-d slam systems. In: IROS (Oct 2012) 10, 12, 13, 19, 21, 24
2012
-
[35]
In: SIGGRAPH (2022) 19, 25
Sun, J., Chen, X., Wang, Q., Li, Z., Averbuch-Elor, H., Zhou, X., Snavely, N.: Neural 3D reconstruction in the wild. In: SIGGRAPH (2022) 19, 25
2022
-
[36]
In: CVPR
Sun, J., Shen, Z., Wang, Y., Bao, H., Zhou, X.: Loftr: Detector-free local feature matching with transformers. In: CVPR. pp. 8922–8931 (June 2021) 4
2021
-
[37]
In: CVPR
Sun, X., Zhu, Z., Lou, Z., Yang, B., Tang, J., Zhang, L., Wang, H., Zhang, J.: Avggt: Rethinking global attention for accelerating vggt. In: CVPR. pp. 251–260 (June 2026) 2, 4
2026
-
[38]
Block-Sparse Global Attention for Efficient Multi-View Geometry Transformers
Wang, C.S.B., Schmidt, C., Piekenbrinck, J., Leibe, B.: Faster vggt with block- sparse global attention. arXiv preprint arXiv:2509.07120 (2025) 2, 3, 4, 5, 10, 11, 12, 13, 26, 27, 28
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Wang, H., Agapito, L.: 3d reconstruction with spatial memory. In: 3DV. pp. 78–89. IEEE (2025) 12, 13
2025
-
[40]
In: CVPR (2025) 1, 2, 4, 5, 7, 10, 11, 12, 13, 14, 15, 21, 24, 25, 26, 27, 28 18 J
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. In: CVPR (2025) 1, 2, 4, 5, 7, 10, 11, 12, 13, 14, 15, 21, 24, 25, 26, 27, 28 18 J. Parket al
2025
-
[41]
In: CVPR (2024) 4
Wang, J., Karaev, N., Rupprecht, C., Novotny, D.: Vggsfm: Visual geometry grounded deep structure from motion. In: CVPR (2024) 4
2024
-
[42]
In: CVPR (2024) 4
Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B., Revaud, J.: Dust3r: Geometric 3d vision made easy. In: CVPR (2024) 4
2024
-
[43]
In: CVPR
Wang, W., Meiner, L., Shubham, R., De La Parra, C., Kumar, A.: Httm: Head- wise temporal token merging for faster vggt. In: CVPR. pp. 26379–26388 (June
-
[44]
In: ICLR (2026) 10, 12, 13
Wang, Y., Zhou, J., Zhu, H., Chang, W., Zhou, Y., Li, Z., Chen, J., Pang, J., Shen, C., He, T.:π3: Permutation-equivariant visual geometry learning. In: ICLR (2026) 10, 12, 13
2026
-
[45]
In: CVPR
Wang, Z., Xu, D.: Flashvggt: Efficient and scalable visual geometry transformers with compressed descriptor attention. In: CVPR. pp. 21826–21835 (June 2026) 2, 4
2026
-
[46]
In: NeurIPS (2022) 4
Weinzaepfel, P., Leroy, V., Lucas, T., BRÉGIER, R., Cabon, Y., ARORA, V., Antsfeld, L., Chidlovskii, B., Csurka, G., Revaud, J.: Croco: Self-supervised pre- training for 3d vision tasks by cross-view completion. In: NeurIPS (2022) 4
2022
-
[47]
In: CVPR
Wilson, J., Almeida, M., Mahajan, S., Labrie, M., Ghaffari, M., Ghasemalizadeh, O., Sun, M., Kuo, C.H., Sen, A.: Pop-gs: Next best view in 3d-gaussian splatting with p-optimality. In: CVPR. pp. 3646–3655 (2025) 4
2025
-
[48]
Yang, J., Sax, A., Liang, K.J., Henaff, M., Tang, H., Cao, A., Chai, J., Meier, F., Feiszli, M.: Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass. In: CVPR (2025) 2 Diversity-aware View Partitioning for Scalable VGGT 19 Supplementary Materials Diversity-aware View Partitioning for Scalable VGGT A Additional Implementation Details A.1 ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.