Statistical Properties of k-means Clustering for Data Missing Completely at Random
Pith reviewed 2026-07-03 06:10 UTC · model grok-4.3
The pith
k-means cluster centers estimated from MCAR missing data achieve √n convergence and asymptotic normality, recovering true centers under a separation condition when centers differ in every dimension.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under the MCAR mechanism, the estimated cluster centers achieve the √n-convergence rate and asymptotic normality; moreover, they converge to the true cluster centers of the fully observed data when a sufficient condition on the missing probability and the separation among true clusters holds. The analysis shows both the rate and the convergence require the k true centers to be distinct in every dimension.
What carries the argument
The excess-risk analysis and asymptotic expansion of the k-means objective on incomplete observations under MCAR, which isolates the effect of dimension-wise center separation.
If this is right
- The estimated centers remain consistent under general missing mechanisms.
- A √n-excess risk bound holds for the incomplete-data k-means objective.
- Asymptotic normality of the centers follows under MCAR.
- Recovery of the original centers occurs once missing probability and cluster separation satisfy the stated sufficient condition.
Where Pith is reading between the lines
- In high dimensions the distinctness requirement will often fail, so the √n guarantees may not apply without dimension selection or projection.
- The results suggest comparing imputation-based k-means against the direct incomplete-data version by checking whether the former relaxes the per-dimension separation demand.
- Practitioners could test the condition by verifying pairwise center differences across all coordinates before relying on the asymptotic rates.
Load-bearing premise
The k true centers must be distinct in every dimension.
What would settle it
A data set or simulation in which two centers coincide in at least one coordinate yet the MCAR estimator still attains the √n rate and converges to the full-data centers would falsify the necessity of that condition.
Figures
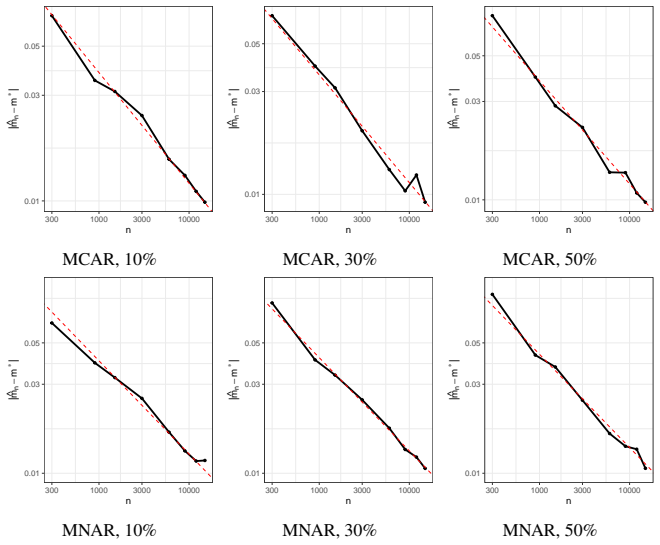
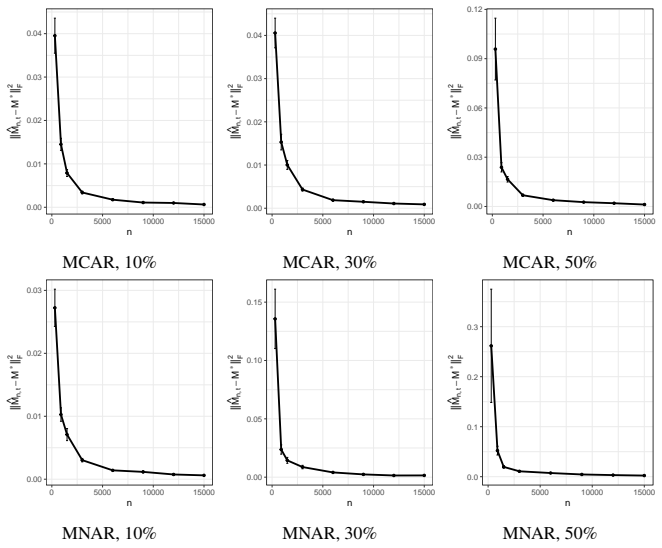
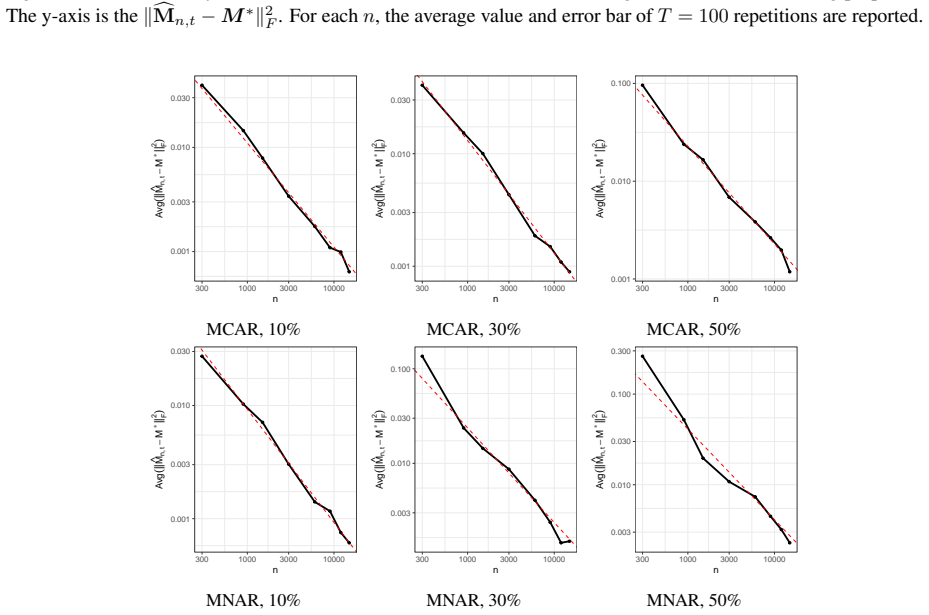
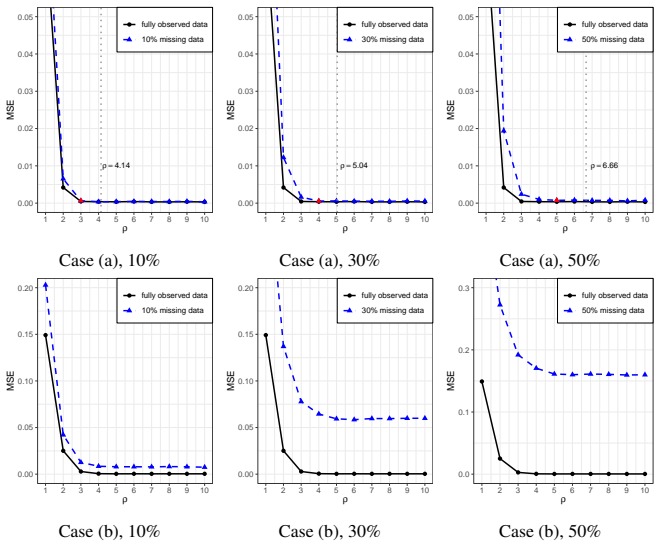
read the original abstract
The classical $k$-means clustering cannot be directly used to incomplete data, and existing $k$-means-based clustering for missing data primarily focus on improving the practical accuracy of clustering, whereas most of them lack theoretical guarantees in the asymptotic sense. In this paper, we investigate the statistical properties of $k$-means clustering in the presence of missing data. We first establish the $\sqrt{n}$-excess risk bound and prove the consistency of the estimated cluster centers under general missing mechanisms. For the Missing Completely at Random (MCAR) mechanism, we further derive the $\sqrt{n}$-convergence rate and asymptotic normality of the estimated cluster centers. Moreover, we study in what cases the cluster centers estimated by incomplete data converge to the true cluster centers of original fully observed data, and give a sufficient condition about the missing probability and the separation among true clusters. These results provide a theoretical guarantee for missing-data-$k$-means. Notably, our analysis reveal that under MCAR mechanism, both achieving the $\sqrt{n}$-rate and converging to the true cluster centers require $k$ true centers to be distinct in every dimension, highlighting the significant challenges of application in high-dimensional regimes. Finally, we conduct numerical simulations on synthetic incomplete datasets to support our theoretical analysis results.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to establish √n-excess risk bounds and consistency of estimated k-means cluster centers under general missing mechanisms. Under the MCAR mechanism it further derives √n-convergence rates and asymptotic normality of the centers, identifies a sufficient condition on the missing probability and cluster separation for convergence to the true fully-observed centers, and shows that both the rate and the convergence require the k true centers to be distinct in every dimension. The claims are supported by numerical simulations on synthetic incomplete data.
Significance. If the derivations hold, the results supply the first asymptotic guarantees for k-means under missing data and isolate a concrete high-dimensional obstruction (distinctness in every coordinate) that is likely to be practically relevant. The asymptotic normality result would also enable downstream inference procedures on incomplete data.
minor comments (2)
- [Abstract / MCAR section] The abstract states that proofs exist for the √n bounds and normality but the manuscript should include a short proof sketch or key steps in the main text (rather than relegating all details to an appendix) so that the distinct-in-every-dimension necessity can be verified without external material.
- [Numerical experiments] The simulation section should report the precise dimensions, missing probabilities, and number of Monte Carlo replications used, together with quantitative checks (e.g., empirical rates or QQ plots) that directly corroborate the claimed √n rate and normality.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No major comments were raised, so we have no specific points to address point-by-point. We will perform a careful proofreading and minor polishing pass for the revised version.
Circularity Check
No significant circularity identified
full rationale
The paper derives √n-excess risk bounds, consistency, √n-convergence rates, asymptotic normality, and a sufficient condition for convergence to true centers under MCAR via standard concentration and asymptotic arguments. The distinct-in-every-dimension requirement is presented as an output of the analysis (necessary for both the rate and true-center convergence), not an input definition or fitted parameter. No self-citations, ansatzes smuggled via prior work, or predictions that reduce to the fitted inputs by construction are indicated in the provided material; the central claims remain independent of the inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Standard concentration inequalities and central limit theorem apply to the incomplete-data objective
- domain assumption Missing completely at random mechanism
Reference graph
Works this paper leans on
-
[1]
Journal of statistical software , volume=
mice: Multivariate imputation by chained equations in R , author=. Journal of statistical software , volume=
-
[2]
Journal of statistical software , volume=
Amelia II: A program for missing data , author=. Journal of statistical software , volume=
-
[3]
The American Statistician , volume=
k-pod: A method for k-means clustering of missing data , author=. The American Statistician , volume=. 2016 , publisher=
2016
-
[4]
IEEE Access , volume=
K-means clustering with incomplete data , author=. IEEE Access , volume=. 2019 , publisher=
2019
-
[5]
The annals of statistics , volume =
Strong consistency of k-means clustering , author=. The annals of statistics , volume =
-
[6]
Pollard, David , journal =
-
[7]
The Annals of Statistics , volume=
Trimmed k -means: an attempt to robustify quantizers , author=. The Annals of Statistics , volume=
-
[8]
Scandinavian Journal of Statistics , volume=
Strong consistency of reduced k-means clustering , author=. Scandinavian Journal of Statistics , volume=
-
[9]
Annals of the Institute of Statistical Mathematics , volume=
Strong consistency of factorial k-means clustering , author=. Annals of the Institute of Statistical Mathematics , volume=
-
[10]
Electronic Journal of Statistics , pages =
Regularized k-means clustering of high-dimensional data and its asymptotic consistency , author=. Electronic Journal of Statistics , pages =. 2012 , volume =
2012
-
[11]
Journal of Machine Learning Research , volume=
Regularized k-means through hard-thresholding , author=. Journal of Machine Learning Research , volume=
-
[12]
Advances in Neural Information Processing Systems , volume=
Robust k-means: a theoretical revisit , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Stat , volume=
On the strong consistency of feature-weighted k-means clustering in a nearmetric space , author=. Stat , volume=. 2019 , publisher=
2019
-
[14]
The Annals of Statistics , pages=
Consistency of spectral clustering , author=. The Annals of Statistics , pages=
-
[15]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Implicit annealing in kernel spaces: A strongly consistent clustering approach , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2022 , publisher=
2022
-
[16]
International Conference on Machine Learning , pages=
Consistency of multiple kernel clustering , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[17]
The Annals of Statistics , volume=
Asymptotic theory of geometric and adaptive k-means clustering , author=. The Annals of Statistics , volume=
-
[18]
Annals of statistics , pages=
A central limit theorem for multivariate generalized trimmed k-means , author=. Annals of statistics , pages=. 1999 , publisher=
1999
-
[19]
International Journal Of General System , volume=
On asymptotic normality of a class of fuzzy c-means clustering procedures , author=. International Journal Of General System , volume=. 1994 , publisher=
1994
-
[20]
Jason Van Hulse and Taghi M. Khoshgoftaar. Incomplete--case nearest neighbor imputation in software measurement data. Information Sciences. 2014. doi:https://doi.org/10.1016/j.ins.2010.12.017
-
[21]
Adaptive imputation of missing values for incomplete pattern classification
Zhunga Liu and Quan Pan and Jean Dezert and Arnaud Martin. Adaptive imputation of missing values for incomplete pattern classification. Pattern Recognition. 2016
2016
-
[22]
MissForest--non--parametric missing value imputation for mixed--type data
Stekhoven, Daniel J and B \"u hlmann, Peter. MissForest--non--parametric missing value imputation for mixed--type data. Bioinformatics. 2012
2012
-
[23]
Gain: Missing data imputation using generative adversarial nets
Yoon, Jinsung and Jordon, James and Schaar, Mihaela. Gain: Missing data imputation using generative adversarial nets. International conference on machine learning. 2018
2018
-
[24]
Suvra Jyoti Choudhury and Nikhil R. Pal. Imputation of missing data with neural networks for classification. Knowledge--Based Systems. 2019
2019
-
[25]
Missing data imputation with adversarially--trained graph convolutional networks
Indro Spinelli and Simone Scardapane and Aurelio Uncini. Missing data imputation with adversarially--trained graph convolutional networks. Neural Networks. 2020
2020
-
[26]
Mean shift clustering algorithm for data with missing values
AbdAllah, Loai and Shimshoni, Ilan. Mean shift clustering algorithm for data with missing values. International Conference on Data Warehousing and Knowledge Discovery. 2014
2014
-
[27]
Machine Learning , volume=
Clustering with missing features: a penalized dissimilarity measure based approach , author=. Machine Learning , volume=. 2018 , publisher=
2018
-
[28]
Mesquita and João P.P
Diego P.P. Mesquita and João P.P. Gomes and Amauri H. Souza Junior and Juvêncio S. Nobre. Euclidean distance estimation in incomplete datasets. Neurocomputing. 2017
2017
-
[29]
Statistical Analysis and Data Mining: The ASA Data Science Journal , volume=
An efficient k-means-type algorithm for clustering datasets with incomplete records , author=. Statistical Analysis and Data Mining: The ASA Data Science Journal , volume=
-
[30]
Journal of Classification , volume=
Imputation strategies for clustering mixed-type data with missing values , author=. Journal of Classification , volume=
-
[31]
Advanced Machine Learning and Data Science , year=
Joint dimensionality reduction and clustering with missing data , author=. Advanced Machine Learning and Data Science , year=
-
[32]
Van Der Vaart, Aad W and Wellner, Jon A , title =
-
[33]
2018 , publisher=
Foundations of machine learning , author=. 2018 , publisher=
2018
-
[34]
Journal of machine learning research , volume=
Rademacher and gaussian complexities: Risk bounds and structural results , author=. Journal of machine learning research , volume=
-
[35]
Transactions on Machine Learning Research , year=
A note on the k -means clustering for missing data , author=. Transactions on Machine Learning Research , year=
-
[36]
Statistical and Computational Guarantees of Lloyd's Algorithm and its Variants
Statistical and computational guarantees of lloyd's algorithm and its variants , author=. arXiv preprint arXiv:1612.02099 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.