A More Accurate Algorithm Comparison through A/B Testing using Offline Evaluation Methods
Pith reviewed 2026-07-03 17:24 UTC · model grok-4.3
The pith
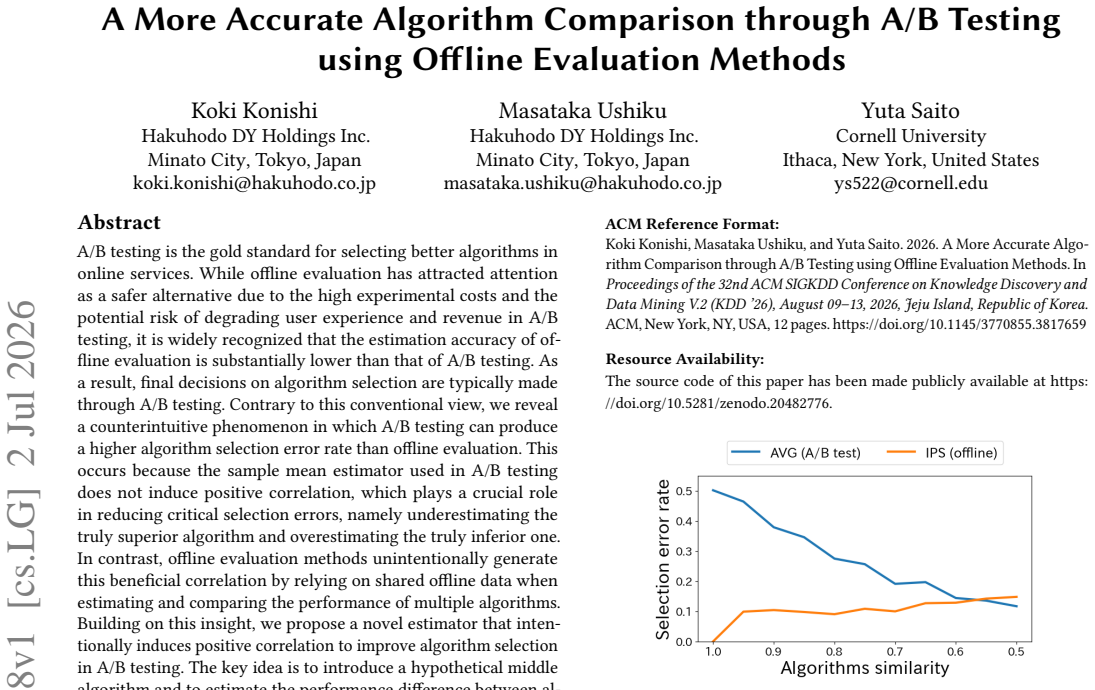
A/B testing can produce higher algorithm selection errors than offline evaluation because its sample mean estimator lacks the positive correlation that reduces critical mistakes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
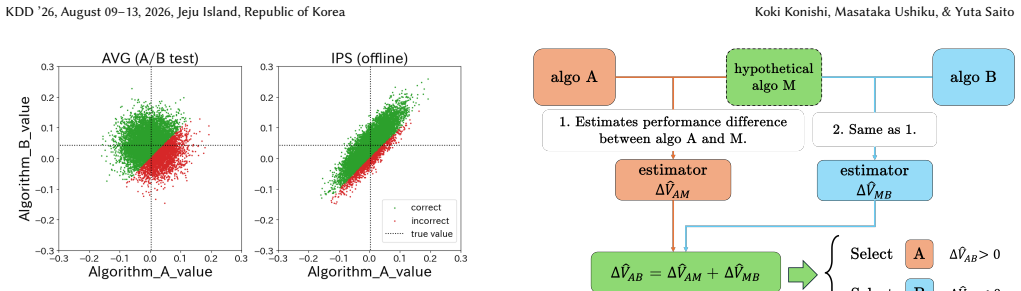
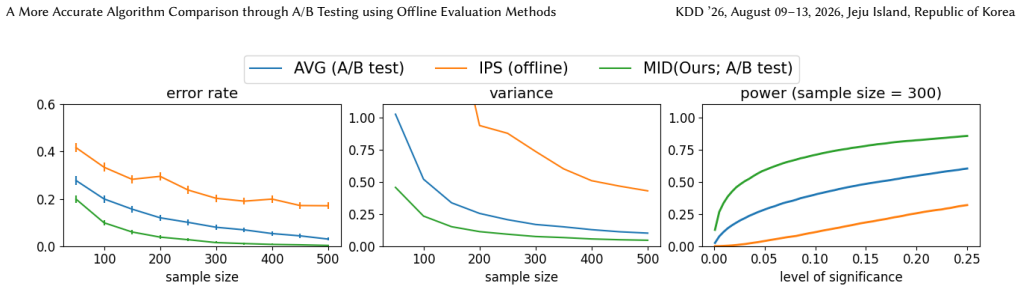
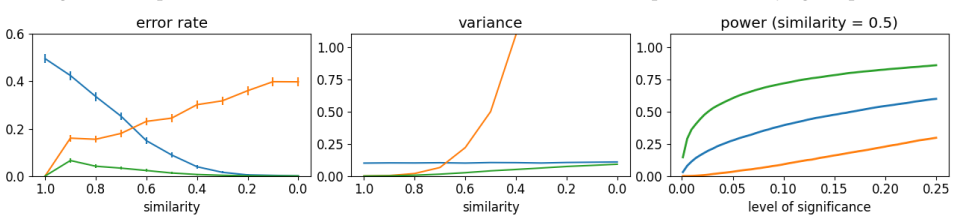
A/B testing can yield higher selection error rates than offline evaluation because the sample mean does not induce positive correlation between estimates, which is key to minimizing critical errors of underestimating the superior algorithm and overestimating the inferior one. By introducing a hypothetical middle algorithm M and estimating differences between A, M, and B in a stepwise manner using shared data at each step, the proposed estimator induces the beneficial correlation. Bias-variance analysis identifies the optimal middle algorithm, and experiments confirm the method achieves equivalent selection accuracy to existing approaches with only half the A/B testing data.
What carries the argument
Stepwise estimator that introduces a hypothetical middle algorithm M and applies offline evaluation techniques to pairwise differences (A vs M, then M vs B) using shared data to induce positive correlation.
If this is right
- The estimator reduces critical selection errors by forcing positive correlation into A/B testing estimates.
- It achieves the same selection error rate as existing approaches while using only half the A/B testing data.
- Bias-variance analysis yields an optimal choice for the middle algorithm that minimizes variance.
- The method enables safer final algorithm decisions in online services by lowering error without raising experimental costs.
Where Pith is reading between the lines
- The correlation-inducing idea could extend to sequential testing or multi-armed bandit problems where data sharing is possible.
- In practice, selecting the middle algorithm without knowing true performances may require adaptive or conservative heuristics.
- Similar stepwise correlation techniques might improve comparisons in domains like clinical trials or recommendation systems.
Load-bearing premise
Introducing a hypothetical middle algorithm and stepwise shared-data estimation will create the needed positive correlation without new biases or variance increases that erase the gain.
What would settle it
Run the proposed estimator and standard A/B testing on the same real-world dataset split into varying sample sizes, then measure whether the new method's selection error rate equals existing methods at half the sample size.
Figures


read the original abstract
A/B testing is the gold standard for selecting the better algorithm in online services. While offline evaluation has attracted attention as a safer alternative due to the high experimental costs and the potential risk of degrading user experience and revenue in A/B testing, it is widely recognized that the estimation accuracy of offline evaluation is substantially lower. As a result, final selection decisions are typically made through A/B testing. Contrary to this conventional view, we reveal a counterintuitive phenomenon in which A/B testing can produce a higher algorithm selection error rate than offline evaluation. This occurs because the sample mean estimator used in A/B testing does not induce positive correlation, which is crucial for reducing critical selection errors, namely underestimating the truly superior algorithm and overestimating the truly inferior one. In contrast, offline evaluation methods unintentionally generate this beneficial correlation by relying on shared offline data when estimating and comparing the performance of multiple algorithms. Building on this insight, we propose an estimator that intentionally induces positive correlation to improve algorithm selection in A/B testing. The key idea is to introduce a hypothetical middle algorithm and to estimate the performance difference between algorithms A, M, and B in a stepwise manner using shared data at each step. This approach enables the application of offline evaluation techniques in each step, thereby inducing positive correlation and reducing critical selection errors. Furthermore, we derive the optimal middle algorithm regarding the resulting variance and analyze its advantages over existing methods through bias-variance analysis. Experiments on real-world data demonstrate that our estimator achieves the same selection error rate as existing approaches while using only one half of the A/B testing data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that A/B testing can yield higher algorithm selection error rates than offline evaluation because the sample-mean estimator induces no positive correlation between performance estimates, whereas offline methods do so unintentionally via shared data. The authors propose a stepwise estimator that introduces a hypothetical middle algorithm M and applies offline-style estimation to the pairs (A,M) and (M,B) using shared A/B data, thereby inducing beneficial positive correlation. They derive the variance-minimizing choice of M, perform a bias-variance analysis showing advantages over standard A/B and offline baselines, and report that the method matches existing selection error rates while using only half the A/B data.
Significance. If the central claims hold, the work would meaningfully revise the conventional view that A/B testing is required for final algorithm selection, by showing how correlation can be deliberately engineered inside A/B testing to reduce critical selection errors. The explicit bias-variance derivation and the factor-of-two data-efficiency claim are the load-bearing contributions; experiments on real-world data provide supporting evidence but do not yet address robustness of the optimal-M choice.
major comments (2)
- [§4] §4 (Bias-Variance Analysis), derivation of optimal middle-algorithm performance: the closed-form expression for the variance-minimizing M appears to depend on the unknown true means μ_A and μ_B. If a data-dependent or plug-in estimator for M is used in practice, the analysis does not bound the additional variance or bias introduced by that choice, which directly undermines the claimed factor-of-two data saving.
- [§5] §5 (Experiments), real-world data results: the reported selection-error curves compare the proposed estimator against baselines, but no ablation or sensitivity plot is shown for misspecification of M around the theoretically optimal value. Because the half-data claim rests on achieving the derived variance reduction, this omission leaves the practical utility unverified.
minor comments (2)
- [§3] Notation for the stepwise estimator (e.g., the shared-data terms in the difference estimators) is introduced without an explicit equation reference in the main text; a single displayed equation would improve readability.
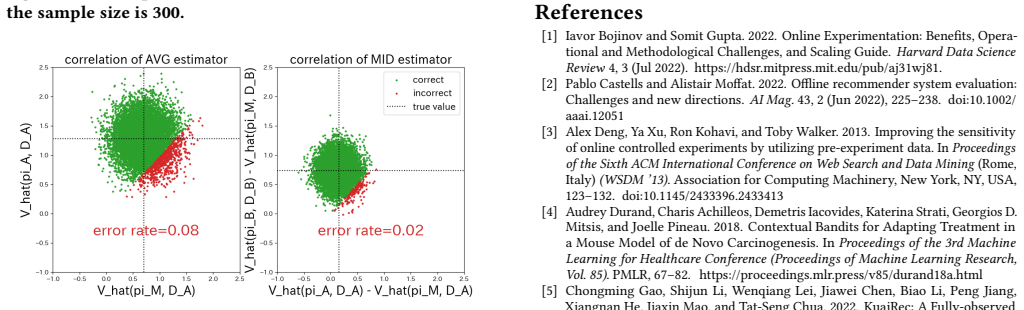
- [Abstract / §5] The abstract states that the method 'achieves the same selection error rate … while using only one half of the A/B testing data,' but the corresponding experimental figure caption does not indicate the exact sample-size ratio used; clarify this in the figure or caption.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. The points raised about the dependence of the optimal M on unknown parameters and the need for sensitivity analysis are well-taken. We address each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [§4] §4 (Bias-Variance Analysis), derivation of optimal middle-algorithm performance: the closed-form expression for the variance-minimizing M appears to depend on the unknown true means μ_A and μ_B. If a data-dependent or plug-in estimator for M is used in practice, the analysis does not bound the additional variance or bias introduced by that choice, which directly undermines the claimed factor-of-two data saving.
Authors: The referee is correct that the closed-form expression for the variance-minimizing M in §4 is derived assuming knowledge of the true means μ_A and μ_B. This establishes the theoretical upper bound on variance reduction achievable by the stepwise estimator. The manuscript presents this as the ideal case to derive the factor-of-two data efficiency relative to standard A/B testing. We acknowledge that no explicit bound is provided on the additional variance or bias incurred when replacing the unknown means with a data-dependent (plug-in) estimator. In the revised version we will add a subsection analyzing the plug-in estimator, including a decomposition of the total variance and either analytic bounds (under mild assumptions on the pilot sample size) or supporting simulations that quantify the degradation. This will clarify the conditions under which the claimed data savings remain approximately intact. revision: yes
-
Referee: [§5] §5 (Experiments), real-world data results: the reported selection-error curves compare the proposed estimator against baselines, but no ablation or sensitivity plot is shown for misspecification of M around the theoretically optimal value. Because the half-data claim rests on achieving the derived variance reduction, this omission leaves the practical utility unverified.
Authors: We agree that the absence of sensitivity analysis for the choice of M limits verification of robustness and therefore the practical relevance of the half-data claim. The current experiments in §5 evaluate the estimator at the theoretically optimal M to demonstrate the potential improvement. In the revision we will add ablation and sensitivity plots on the real-world datasets that vary M around the optimal value (both in absolute terms and relative to the range of observed means). These plots will report selection-error curves for several misspecification levels, allowing readers to assess how much deviation from optimality can be tolerated while still outperforming standard A/B testing. revision: yes
Circularity Check
No circularity: derivation is independent bias-variance analysis
full rationale
The paper derives the benefit of positive correlation for selection error reduction from the properties of shared data in offline methods, then proposes a stepwise estimator with hypothetical middle algorithm M and performs a separate bias-variance analysis to identify its optimal choice. No equation or claim reduces the resulting selection error rate, variance expression, or optimal M back to a fitted parameter, self-citation, or definitional identity; the analysis treats the true means as fixed unknowns and derives variance expressions from the estimator structure itself. Experiments are presented as external validation rather than part of the derivation. This is a self-contained first-principles argument with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- middle algorithm performance level
axioms (1)
- domain assumption Positive correlation between performance estimates reduces the rate of critical selection errors (underestimating the superior algorithm and overestimating the inferior one).
invented entities (1)
-
hypothetical middle algorithm
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Iavor Bojinov and Somit Gupta. 2022. Online Experimentation: Benefits, Opera- tional and Methodological Challenges, and Scaling Guide.Harvard Data Science Review4, 3 (Jul 2022). https://hdsr.mitpress.mit.edu/pub/aj31wj81
2022
-
[2]
Pablo Castells and Alistair Moffat. 2022. Offline recommender system evaluation: Challenges and new directions.AI Mag.43, 2 (Jun 2022), 225–238. doi:10.1002/ aaai.12051
2022
-
[3]
Alex Deng, Ya Xu, Ron Kohavi, and Toby Walker. 2013. Improving the sensitivity of online controlled experiments by utilizing pre-experiment data. InProceedings of the Sixth ACM International Conference on Web Search and Data Mining(Rome, Italy)(WSDM ’13). Association for Computing Machinery, New York, NY, USA, 123–132. doi:10.1145/2433396.2433413
-
[4]
Mitsis, and Joelle Pineau
Audrey Durand, Charis Achilleos, Demetris Iacovides, Katerina Strati, Georgios D. Mitsis, and Joelle Pineau. 2018. Contextual Bandits for Adapting Treatment in a Mouse Model of de Novo Carcinogenesis. InProceedings of the 3rd Machine Learning for Healthcare Conference (Proceedings of Machine Learning Research, Vol. 85). PMLR, 67–82. https://proceedings.ml...
2018
-
[5]
Chongming Gao, Shijun Li, Wenqiang Lei, Jiawei Chen, Biao Li, Peng Jiang, Xiangnan He, Jiaxin Mao, and Tat-Seng Chua. 2022. KuaiRec: A Fully-observed Dataset and Insights for Evaluating Recommender Systems. InProceedings of the 31st ACM International Conference on Information & Knowledge Management (Atlanta, GA, USA)(CIKM ’22). Association for Computing M...
-
[6]
Alexandre Gilotte, Clément Calauzènes, Thomas Nedelec, Alexandre Abraham, and Simon Dollé. 2018. Offline A/B Testing for Recommender Systems. InProceed- ings of the Eleventh ACM International Conference on Web Search and Data Mining (Marina Del Rey, CA, USA)(WSDM ’18). Association for Computing Machinery, KDD ’26, August 09–13, 2026, Jeju Island, Republic...
-
[7]
Carlos A. Gomez-Uribe and Neil Hunt. 2016. The Netflix Recommender System: Algorithms, Business Value, and Innovation.ACM Trans. Manage. Inf. Syst.6, 4, Article 13 (Dec 2016), 19 pages. doi:10.1145/2843948
-
[8]
Alois Gruson, Praveen Chandar, Christophe Charbuillet, James McInerney, Samantha Hansen, Damien Tardieu, and Ben Carterette. 2019. Offline Evaluation to Make Decisions About PlaylistRecommendation Algorithms. InProceedings of the Twelfth ACM International Conference on Web Search and Data Mining (Melbourne VIC, Australia)(WSDM ’19). Association for Comput...
-
[9]
Yongyi Guo, Dominic Coey, Mikael Konutgan, Wenting Li, Chris Schoener, and Matt Goldman. 2021. Machine learning for variance reduction in online experi- ments. InProceedings of the 35th International Conference on Neural Information Processing Systems (NIPS ’21). Curran Associates Inc., Red Hook, NY, USA, Article 661, 12 pages
2021
-
[10]
D. G. Horvitz and D. J. Thompson. 1952. A Generalization of Sampling Without Replacement from a Finite Universe.J. Amer. Statist. Assoc.47, 260 (1952), 663–685. doi:10.1080/01621459.1952.10483446
-
[11]
Olivier Jeunen and Aleksei Ustimenko. 2024. Δ-OPE: Off-Policy Estimation with Pairs of Policies. InProceedings of the 18th ACM Conference on Recommender Systems(Bari, Italy)(RecSys ’24). Association for Computing Machinery, New York, NY, USA, 878–883. doi:10.1145/3640457.3688162
-
[12]
Olivier Jeunen and Aleksei Ustimenko. 2024. Learning Metrics that Max- imise Power for Accelerated A/B-Tests. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining(Barcelona, Spain)(KDD ’24). Association for Computing Machinery, New York, NY, USA, 5183–5193. doi:10.1145/3637528.3671512
-
[13]
Ron Kohavi, Alex Deng, Brian Frasca, Roger Longbotham, Toby Walker, and Ya Xu. 2012. Trustworthy online controlled experiments: five puzzling outcomes explained. InProceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining(Beijing, China)(KDD ’12). Association for Computing Machinery, New York, NY, USA, 786–794. doi...
-
[14]
Ron Kohavi, Alex Deng, Brian Frasca, Toby Walker, Ya Xu, and Nils Pohlmann
-
[15]
Online controlled experiments at large scale. InProceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (Chicago, Illinois, USA)(KDD ’13). Association for Computing Machinery, New York, NY, USA, 1168–1176. doi:10.1145/2487575.2488217
-
[16]
2020.Online Controlled Experiments and A/B Tests
Ron Kohavi and Roger Longbotham. 2020.Online Controlled Experiments and A/B Tests. Springer US, New York, NY, 1–13. doi:10.1007/978-1-4899-7502-7_891-2
-
[17]
Ksenia Konyushkova, Yutian Chen, Tom Le Paine, Caglar Gulcehre, Cosmin Paduraru, Daniel J Mankowitz, Misha Denil, and Nando de Freitas. 2021. Active Offline Policy Selection.Advances in Neural Information Processing Systems34 (Dec 2021), 24631–24644
2021
-
[18]
Nicholas Larsen, Jonathan Stallrich, Srijan Sengupta, Alex Deng, Ron Kohavi, and Nathaniel T. Stevens. 2024. Statistical Challenges in Online Controlled Experiments: A Review of A/B Testing Methodology.The American Statistician 78, 2 (2024), 135–149. doi:10.1080/00031305.2023.2257237
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1080/00031305.2023.2257237 2024
-
[19]
Lihong Li, Wei Chu, John Langford, and Xuanhui Wang. 2011. Unbiased offline evaluation of contextual-bandit-based news article recommendation algorithms. InProceedings of the Fourth ACM International Conference on Web Search and Data Mining(Hong Kong, China)(WSDM ’11). Association for Computing Machinery, New York, NY, USA, 297–306. doi:10.1145/1935826.1935878
- [20]
-
[21]
Alberto Maria Metelli, Alessio Russo, and Marcello Restelli. 2021. Subgaussian and Differentiable Importance Sampling for Off-Policy Evaluation and Learning. InAdvances in Neural Information Processing Systems, Vol. 34. Curran Asso- ciates, Inc., 8119–8132. https://proceedings.neurips.cc/paper_files/paper/2021/ file/4476b929e30dd0c4e8bdbcc82c6ba23a-Paper.pdf
2021
-
[22]
Sutton, and Satinder P
Doina Precup, Richard S. Sutton, and Satinder P. Singh. 2000. Eligibility Traces for Off-Policy Policy Evaluation. InProceedings of the Seventeenth International Conference on Machine Learning (ICML ’00). Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 759–766
2000
-
[23]
Noveen Sachdeva, Yi Su, and Thorsten Joachims. 2020. Off-policy Bandits with Deficient Support. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining(Virtual Event, CA, USA) (KDD ’20). Association for Computing Machinery, New York, NY, USA, 965–975. doi:10.1145/3394486.3403139
-
[24]
Yuta Saito and Thorsten Joachims. 2022. Counterfactual Evaluation and Learning for Interactive Systems: Foundations, Implementations, and Recent Advances. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining(Washington DC, USA)(KDD ’22). Association for Computing Machinery, New York, NY, USA, 4824–4825. doi:10.1145/35346...
-
[25]
Otmane Sakhi, Imad Aouali, Pierre Alquier, and Nicolas Chopin. 2024. Logarith- mic smoothing for pessimistic off-policy evaluation, selection and learning. In Proceedings of the 38th International Conference on Neural Information Processing Systems(Vancouver, BC, Canada)(NIPS ’24). Curran Associates Inc., Red Hook, NY, USA, Article 2566, 50 pages
2024
-
[26]
Otmane Sakhi, Alexandre Gilotte, and David Rohde. 2025. Practical Improvements of A/B Testing with Off-Policy Estimation. arXiv:2506.10677 https://arxiv.org/ abs/2506.10677
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Yi Su, Maria Dimakopoulou, Akshay Krishnamurthy, and Miroslav Dudik. 2020. Doubly robust off-policy evaluation with shrinkage. InProceedings of the 37th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 119). PMLR, 9167–9176. https://proceedings.mlr.press/v119/su20a. html
2020
-
[28]
Adith Swaminathan and Thorsten Joachims. 2015. The self-normalized estimator for counterfactual learning. InProceedings of the 29th International Conference on Neural Information Processing Systems - Volume 2(Montreal, Canada)(NIPS’15). MIT Press, Cambridge, MA, USA, 3231–3239
2015
-
[29]
Runzhe Wan, Branislav Kveton, and Rui Song. 2022. Safe Exploration for Efficient Policy Evaluation and Comparison. InProceedings of the 39th International Con- ference on Machine Learning (Proceedings of Machine Learning Research, Vol. 162). PMLR, 22491–22511. https://proceedings.mlr.press/v162/wan22b.html
2022
-
[30]
Yu Wang, Somit Gupta, Jiannan Lu, Ali Mahmoudzadeh, and Sophia Liu. 2019. On Heavy-user Bias in A/B Testing. InProceedings of the 28th ACM International Conference on Information and Knowledge Management(Beijing, China)(CIKM ’19). Association for Computing Machinery, New York, NY, USA, 2425–2428. doi:10.1145/3357384.3358143
-
[31]
Mengjiao Yang, Bo Dai, Ofir Nachum, George Tucker, and Dale Schuurmans
-
[32]
InProceedings of The 25th International Conference on Artificial Intelligence and Statistics (Proceedings of Machine Learning Research, Vol
Offline Policy Selection under Uncertainty. InProceedings of The 25th International Conference on Artificial Intelligence and Statistics (Proceedings of Machine Learning Research, Vol. 151). PMLR, 4376–4396. https://proceedings.mlr. press/v151/yang22a.html
-
[33]
Qing Zhang, Alex Deng, Michelle Du, Huiji Gao, Liwei He, and Sanjeev Katariya
-
[34]
Harnessing the Power of Interleaving and Counterfactual Evaluation for Airbnb Search Ranking. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2(Toronto ON, Canada)(KDD ’25). Association for Computing Machinery, New York, NY, USA, 5205–5214. doi:10. 1145/3711896.3737232
-
[35]
Siyuan Zhang and Nan Jiang. 2021. Towards Hyperparameter-free Policy Selection for Offline Reinforcement Learning. InAdvances in Neural Information Processing Systems, Vol. 34. Curran Associates, Inc., 12864–12875. https://proceedings.neurips.cc/paper_files/paper/2021/file/ 6add07cf50424b14fdf649da87843d01-Paper.pdf A More Accurate Algorithm Comparison th...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.