NAVER LABS Europe Submission to the Instruction-following 2026 Short Track
Pith reviewed 2026-07-03 15:01 UTC · model grok-4.3
The pith
An improved speech projector and synthetic scientific talks let a compact model with a weaker LLM backbone beat last year's top system on joint ASR, ST, and SQA tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The combination of an improved speech projection mechanism and domain-specific synthetic data allows our model to outperform last year's best short-track system, while being considerably more compact and relying on a weaker LLM backbone.
What carries the argument
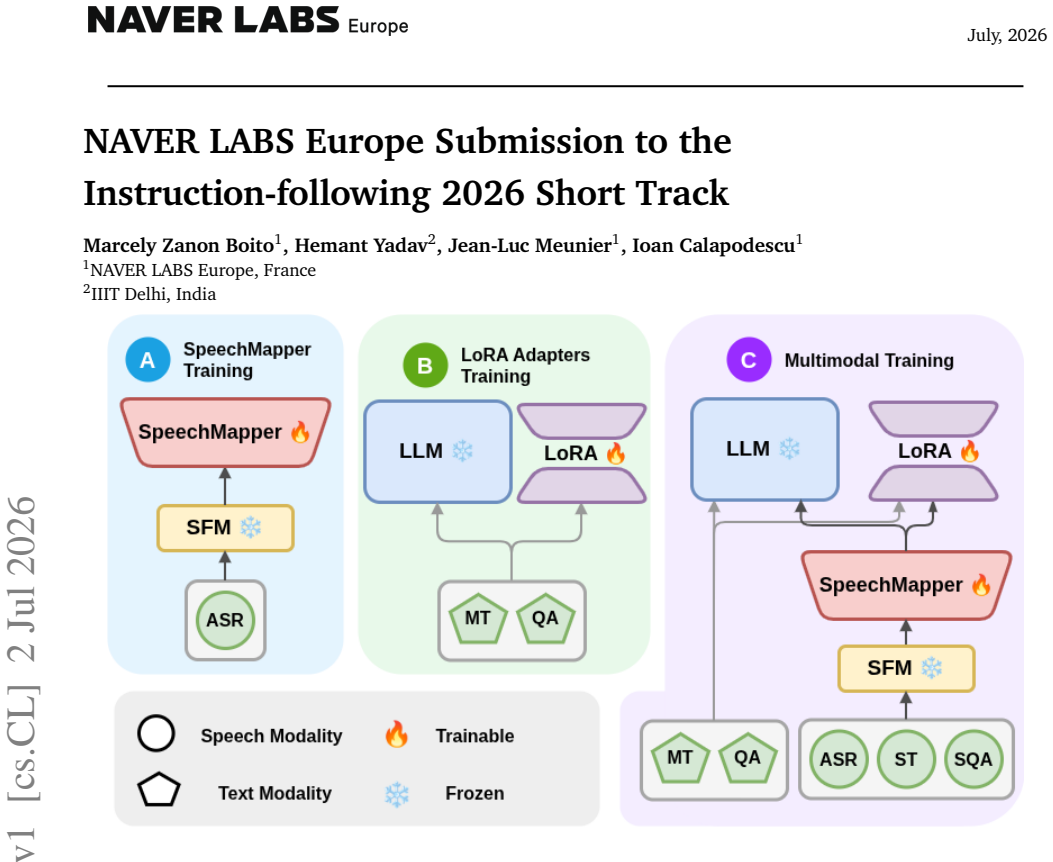
SpeechMapper, a method for learning a speech-to-LLM embedding projector using only ASR data, paired with the fakACL synthetic SQA dataset built by prompting the LLM backbone, segmenting the generated talks, and synthesizing speech with SeamlessM4T-large-v2.
If this is right
- Joint ASR, ST, and SQA systems can reach top performance with smaller size and weaker LLM backbones when the speech projector and training data are optimized.
- Synthetic data generated by prompting an LLM and synthesizing speech can supplement real data effectively for domain-specific instruction-following tasks.
- Speech projectors trained solely on ASR data can replace prior mechanisms while supporting downstream translation and question-answering capabilities.
- The constrained-track setting permits competitive multilingual speech processing without access to the strongest available LLMs.
Where Pith is reading between the lines
- The same projector-plus-synthetic-data recipe could be tested on other language pairs or non-scientific domains to check transfer.
- If the evaluation distribution shifts away from scientific presentations, the reported gains from fakACL might shrink.
- Future constrained submissions could explore whether further reductions in model size remain possible while keeping the same tasks.
Load-bearing premise
The fakACL synthetic dataset produces training examples whose distribution matches the competition's evaluation data closely enough that performance gains transfer without overfitting to artifacts of the generation process.
What would settle it
Training an identical model on real rather than synthetic SQA data and measuring whether accuracy on the official evaluation set drops below the reported level would directly test whether the synthetic data is responsible for the gains.
Figures
read the original abstract
In this paper, we describe NAVER LABS Europe's submission to the instruction-following speech processing short track at IWSLT 2026. We participate again in the constrained setting, developing systems capable of jointly performing ASR, ST, and SQA from English speech into Chinese, Italian, and German. Building on our previous submission, ranked first in last year's short track, we update our multi-stage training pipeline by replacing the speech projector with SpeechMapper, a method for learning a speech-to-LLM embedding projector using only ASR data. In addition, we introduce a synthetic SQA dataset, fakACL, composed of artificially generated scientific presentations. This dataset is built by prompting the LLM backbone, segmenting the generated talks, and synthesizing speech with SeamlessM4T-large-v2. The combination of an improved speech projection mechanism and domain-specific synthetic data allows our model to outperform last year's best short-track system, while being considerably more compact and relying on a weaker LLM backbone. This year's results place our system tied for first place in the overall short track ranking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes NAVER LABS Europe's constrained submission to the IWSLT 2026 instruction-following speech processing short track. Building on their prior top-ranked system, the authors replace the speech projector with SpeechMapper (trained only on ASR data) and introduce the fakACL synthetic SQA dataset (LLM-prompted scientific talks synthesized via SeamlessM4T-large-v2). They claim the combination yields outperformance over last year's best short-track system, with a more compact model using a weaker LLM backbone, resulting in a tie for first place overall.
Significance. If the reported gains are robustly attributable to SpeechMapper and fakACL rather than unverified factors, the work would demonstrate practical value in using synthetic domain-specific data and lightweight projection mechanisms to improve multi-task (ASR/ST/SQA) instruction-following systems while reducing model size and backbone strength. This could inform efficient deployment in low-resource or constrained settings.
major comments (2)
- [Abstract and §4 (Results)] The central performance claim (outperformance via SpeechMapper + fakACL) is load-bearing but unsupported by ablations, error bars, or protocol details; the abstract and results sections provide only leaderboard rankings without quantitative validation that gains transfer from synthetic to real evaluation data.
- [§3.2] §3.2 (fakACL construction): no checks (e.g., embedding distances, perplexity, or error-pattern overlap) are reported to confirm the synthetic distribution matches IWSLT 2026 eval acoustics, topics, and instructions, leaving the attribution to domain-specific data vulnerable to generation artifacts from SeamlessM4T or the LLM.
minor comments (2)
- [§2] Clarify the exact architecture of SpeechMapper (e.g., layer count, training objective) and how it differs from the prior projector.
- [Table 1 or §4] Add a table comparing model sizes, LLM backbones, and training data volumes against the 2025 top system for the compactness claim.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on our IWSLT 2026 short-track system description. We address each major comment below and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and §4 (Results)] The central performance claim (outperformance via SpeechMapper + fakACL) is load-bearing but unsupported by ablations, error bars, or protocol details; the abstract and results sections provide only leaderboard rankings without quantitative validation that gains transfer from synthetic to real evaluation data.
Authors: In shared-task system papers the official leaderboard on real evaluation data constitutes the primary and required evidence of performance. Our submission achieved a tie for first place while using a more compact model and weaker LLM backbone than the prior best system. We acknowledge that component-level ablations and error bars would strengthen causal attribution to SpeechMapper and fakACL individually; such experiments were not feasible within the shared-task timeline. The transfer from synthetic training data to real evaluation is evidenced by the end-to-end ranking on the official IWSLT test set. We will revise the abstract and §4 to clarify the evaluation protocol and explicitly note the absence of internal ablations. revision: yes
-
Referee: [§3.2] §3.2 (fakACL construction): no checks (e.g., embedding distances, perplexity, or error-pattern overlap) are reported to confirm the synthetic distribution matches IWSLT 2026 eval acoustics, topics, and instructions, leaving the attribution to domain-specific data vulnerable to generation artifacts from SeamlessM4T or the LLM.
Authors: fakACL was generated by prompting the LLM backbone with ACL-style scientific topics and synthesizing speech via SeamlessM4T-large-v2 to approximate the target domain. No quantitative distribution-matching analyses (embedding distances, perplexity, or error-pattern overlap) were conducted against the IWSLT 2026 evaluation acoustics or instructions. We will add a limitations paragraph in §3.2 acknowledging this gap and the possibility of synthesizer or LLM artifacts, while noting that final performance on real data provides indirect support for the approach. revision: yes
Circularity Check
No circularity: empirical leaderboard results with no derivations
full rationale
The paper is a competition system description reporting ASR/ST/SQA performance on the external IWSLT 2026 short-track leaderboard. It describes architectural changes (SpeechMapper projector) and a synthetic dataset (fakACL) but presents no equations, fitted parameters, predictions, or mathematical derivations. The outperformance claim rests on external benchmark numbers rather than any internal construction that reduces to its own inputs. A passing reference to the authors' prior submission exists but carries no load for any derivation or uniqueness argument. This matches the default case of a self-contained empirical report against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (2)
-
SpeechMapper
no independent evidence
-
fakACL
no independent evidence
Reference graph
Works this paper leans on
-
[1]
McCrae, Yasmin Moslem, Satoshi Nakamura, Matteo Negri, Jan Niehues, Atul Kr
David Ifeoluwa Adelani, Antonios Anastasopoulos, Vic- tor Agostinelli, Luisa Bentivogli, Ondřej Bojar, Sebastien Bratières, Marine Carpuat, Roldano Cattoni, Mauro Cet- tolo, Lizhong Chen, Marcello Federico, Marco Gaido, Mahendra Gupta, HyoJung Han, Ali Hatami, David Javorský, Yejin Jeon, Marek Kasztelnik, Danni Liu, Nam Luu, Min Ma, Dominik Macháček, Mari...
2026
-
[2]
Kshitij Ambilduke, Ben Peters, Sonal Sannigrahi, Anil Keshwani, Tsz Kin Lam, Bruno Martins, Marcely Zanon Boito, and André FT Martins. From tower to spire: Adding the speech modality to a text-only llm.arXiv preprint arXiv:2503.10620, 2025. 1
-
[3]
Loïc Barrault, Yu-An Chung, Mariano Cora Meglioli, David Dale, NingDong, Paul-Ambroise Duquenne, Hady Elsahar, Hongyu Gong, Kevin Heffernan, John Hoff- man, et al. Seamlessm4t: Massively multilingual & multimodal machine translation.arXiv preprint arXiv:2308.11596, 2023. 2
-
[4]
Moshi: a speech-text foundation model for real-time dialogue
Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave, and Neil Zeghidour. Moshi: a speech-text foun- dation model for real-time dialogue.arXiv preprint arXiv:2410.00037, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Connectionist temporal classi- fication: Labelling unsegmented sequence data with recurrent neural networks
Alex Graves, Santiago Fernández, Faustino Gomez, and Jürgen Schmidhuber. Connectionist temporal classi- fication: Labelling unsegmented sequence data with recurrent neural networks. InProceedings of the 23rd International Conference on Machine Learning, pages 369–376, 2006. 4
2006
-
[6]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Repre- sentations, 2022. 2, 5
2022
-
[7]
Shujie Hu, Long Zhou, Shujie Liu, Sanyuan Chen, Ling- wei Meng, Hongkun Hao, Jing Pan, Xunying Liu, Jinyu Li, Sunit Sivasankaran, et al. Wavllm: Towards ro- 7 NAVER LABS Europe Submission to the Instruction-following 2026 Short Track bust and adaptive speech large language model.arXiv preprint arXiv:2404.00656, 2024. 1
-
[8]
Audiogpt: Understand- ing and generating speech, music, sound, and talking head
Rongjie Huang, Mingze Li, Dongchao Yang, Jiatong Shi, Xuankai Chang, Zhenhui Ye, Yuning Wu, Zhiqing Hong, Jiawei Huang, Jinglin Liu, et al. Audiogpt: Understand- ing and generating speech, music, sound, and talking head. InProceedings of the AAAI Conference on Artificial Intelligence, pages 23802–23804, 2024. 1
2024
-
[9]
Iranzo-Sánchez, J
J. Iranzo-Sánchez, J. A. Silvestre-Cerdà, J. Jorge, N. Roselló, A. Giménez, A. Sanchis, J. Civera, and A. Juan. Europarl-st: A multilingual corpus for speech transla- tion of parliamentary debates. InICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 8229–8233, 2020. 2
2020
-
[10]
NAVER LABS Europe submis- sion to the instruction-following track
Beomseok Lee, Marcely Zanon Boito, Laurent Besacier, and Ioan Calapodescu. NAVER LABS Europe submis- sion to the instruction-following track. InProceedings of the 22nd International Conference on Spoken Language Translation (IWSLT 2025), pages 186–200, Vienna, Aus- tria (in-person and online), 2025. Association for Com- putational Linguistics. 2, 3, 4, 5, 7
2025
-
[11]
Guerreiro, Ricardo Rei, Duarte M
Pedro Henrique Martins, Patrick Fernandes, João Alves, Nuno M. Guerreiro, Ricardo Rei, Duarte M. Alves, José Pombal, Amin Farajian, Manuel Faysse, Mateusz Kli- maszewski, Pierre Colombo, Barry Haddow, José G. C. de Souza, Alexandra Birch, and André F. T. Martins. Eu- rollm: Multilingual language models for europe, 2024. 5
2024
-
[12]
Speechmapper: Speech-to-text embed- ding projector for llms
Biswesh Mohapatra, Marcely Zanon Boito, and Ioan Calapodescu. Speechmapper: Speech-to-text embed- ding projector for llms. InICASSP 2026 - 2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2026. 1, 2, 3, 4, 5, 7
2026
-
[13]
Spirit-lm: Interleaved spoken and written language model.Transactions of the Association for Computational Linguistics, 13:30–52, 2025
Tu Anh Nguyen, Benjamin Muller, Bokai Yu, Marta R Costa-Jussa, Maha Elbayad, Sravya Popuri, Christophe Ropers, Paul-Ambroise Duquenne, Robin Algayres, Rus- lan Mavlyutov, et al. Spirit-lm: Interleaved spoken and written language model.Transactions of the Association for Computational Linguistics, 13:30–52, 2025. 1
2025
-
[14]
Librispeech: An asr corpus based on public domain audio books
Vassil Panayotov, Guoguo Chen, Daniel Povey, and San- jeev Khudanpur. Librispeech: An asr corpus based on public domain audio books. In2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5206–5210, 2015. 2
2015
-
[15]
MCIF: Multimodal crosslingual instruction- following benchmark from scientific talks
Sara Papi, Maike Züfle, Marco Gaido, Beatrice Savoldi, Danni Liu, Ioannis Douros, Luisa Bentivogli, and Jan Niehues. MCIF: Multimodal crosslingual instruction- following benchmark from scientific talks. InThe Four- teenth International Conference on Learning Representa- tions, 2026. 2
2026
-
[16]
Scaling speech technology to 1,000+ languages.Jour- nal of Machine Learning Research, 25(97):1–52, 2024
Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhao- heng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, et al. Scaling speech technology to 1,000+ languages.Jour- nal of Machine Learning Research, 25(97):1–52, 2024. 5
2024
-
[17]
BERGEN: A benchmarking library for retrieval-augmented generation
David Rau, Hervé Déjean, Nadezhda Chirkova, Thibault Formal, Shuai Wang, Stéphane Clinchant, and Vas- silina Nikoulina. BERGEN: A benchmarking library for retrieval-augmented generation. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 7640–7663, Miami, Florida, USA, 2024. Associa- tion for Computational Linguistics. 5
2024
-
[18]
Ricardo Rei, José G. C. de Souza, Duarte Alves, Chrysoula Zerva, Ana C Farinha, Taisiya Glushkova, Alon Lavie, Luisa Coheur, and André F. T. Martins. COMET-22: Unbabel-IST 2022 submission for the met- rics shared task. InProceedings of the Seventh Conference on Machine Translation (WMT), pages 578–585, Abu Dhabi, United Arab Emirates (Hybrid), 2022. Assoc...
2022
-
[19]
AudioPaLM: A Large Language Model That Can Speak and Listen
Paul K Rubenstein, Chulayuth Asawaroengchai, Duc Dung Nguyen, Ankur Bapna, Zalán Borsos, Félix de Chaumont Quitry, Peter Chen, Dalia El Badawy, Wei Han, Eugene Kharitonov, et al. Audiopalm: A large language model that can speak and listen.arXiv preprint arXiv:2306.12925, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Evaluating multilingual speech translation under realistic condi- tions with resegmentation and terminology
Elizabeth Salesky, Kareem Darwish, Mohamed Al- Badrashiny, Mona Diab, and Jan Niehues. Evaluating multilingual speech translation under realistic condi- tions with resegmentation and terminology. InProceed- ings of the 20th International Conference on Spoken Lan- guage Translation (IWSLT 2023), pages 62–78, Toronto, Canada (in-person and online), 2023. As...
2023
-
[21]
SALMONN: Towards Generic Hearing Abilities for Large Language Models
Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, and Chao Zhang. Salmonn: Towardsgenerichearingabilitiesforlargelan- guage models.arXiv preprint arXiv:2310.13289, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Per- rin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, Gaël Liu, Francesco Visin, Kathleen Kenealy, Lucas B...
2026
-
[23]
Qwen3 technical report, 2025
Qwen Team. Qwen3 technical report, 2025. 2
2025
-
[24]
torchtune: Py- torch’s finetuning library, 2024
torchtune maintainers and contributors. torchtune: Py- torch’s finetuning library, 2024. 5
2024
-
[25]
Covost 2: A massively multilingual speech-to-text translation corpus, 2020
Changhan Wang, Anne Wu, and Juan Pino. Covost 2: A massively multilingual speech-to-text translation corpus, 2020. 2
2020
-
[26]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
GigaST:A10,000- hour Pseudo Speech Translation Corpus
Rong Ye, Chengqi Zhao, Tom Ko, Chutong Meng, Tao Wang, MingxuanWang, andJunCao. GigaST:A10,000- hour Pseudo Speech Translation Corpus. InInterspeech 2023, pages 2168–2172, 2023. 2
2023
-
[28]
List about 1000 conversation topics, without numbering or adding any comment of explana- tion
Zihan Zhao, Yiyang Jiang, Heyang Liu, Yu Wang, and YanfengWang. Librisqa: Anoveldatasetandframework forspokenquestionansweringwithlargelanguagemod- els.IEEE Transactions on Artificial Intelligence, 6(11): 2884–2895, 2025. 2 9 NAVER LABS Europe Submission to the Instruction-following 2026 Short Track A. Appendix A.1. Qwen-based SQA Invalid Split We aim to ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.