Hidden Forgetting in Continual Multimodal Learning: When Accuracy Survives but Grounding Fails
Pith reviewed 2026-07-03 13:35 UTC · model grok-4.3
The pith
Multimodal models can retain old answers during continual learning while silently shifting which evidence channels they actually use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
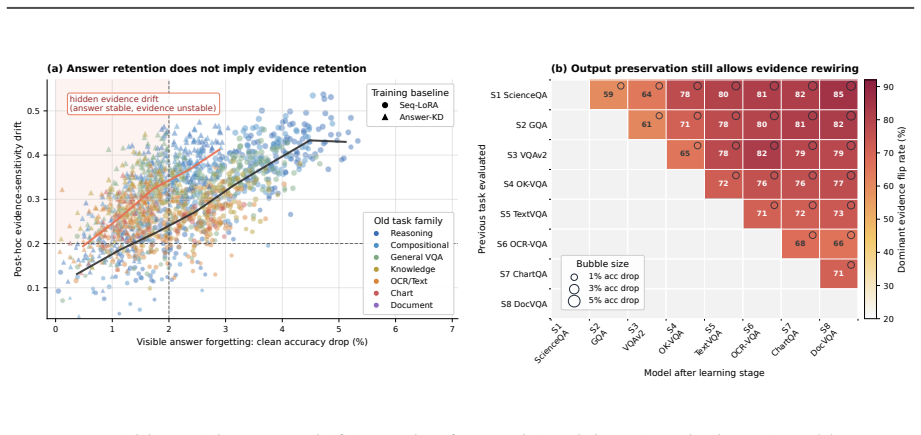
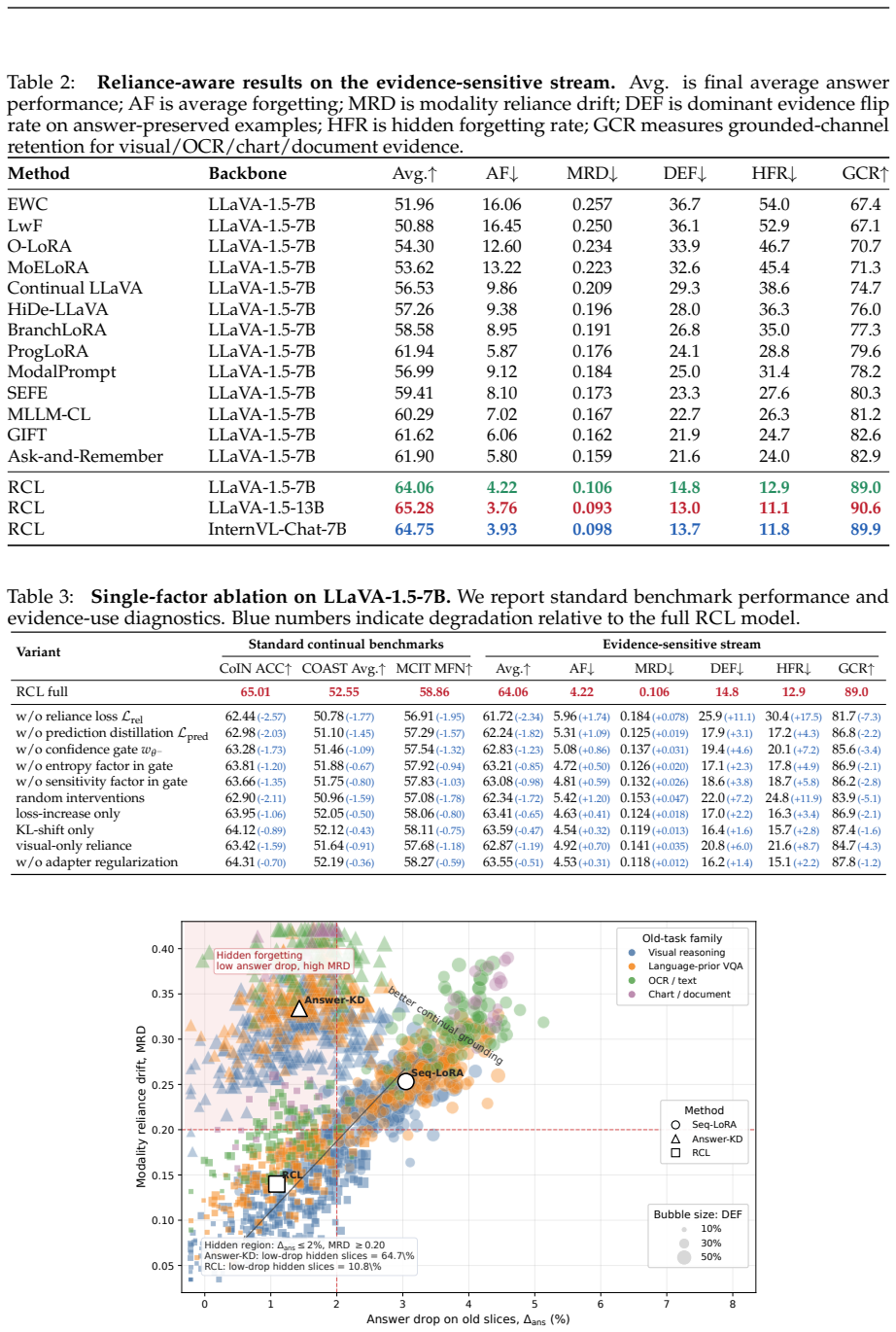
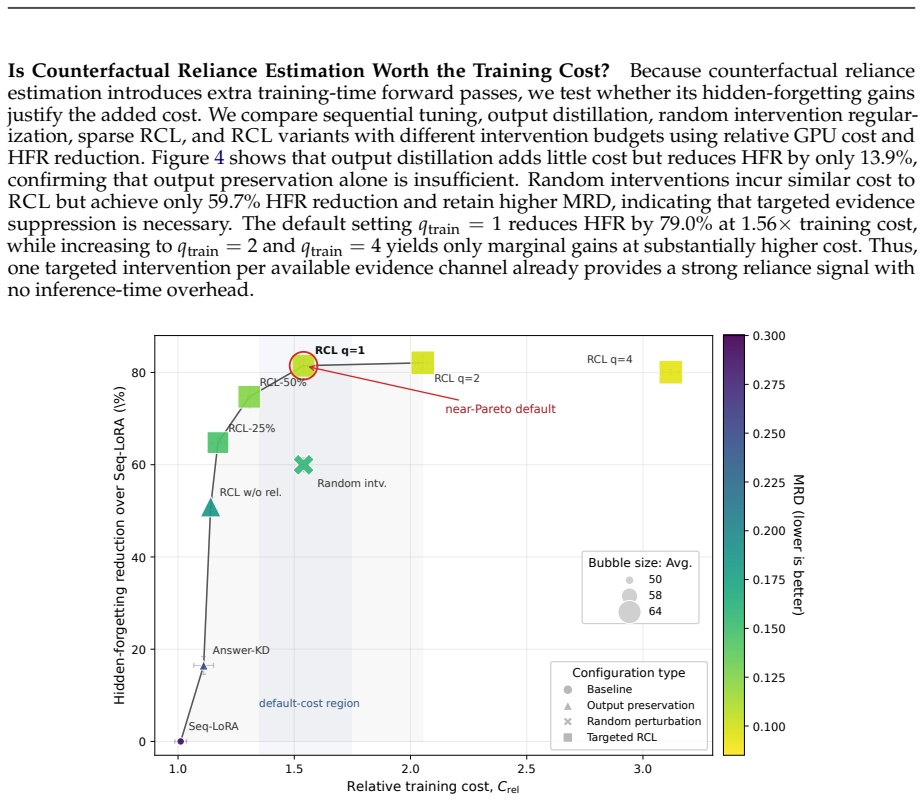
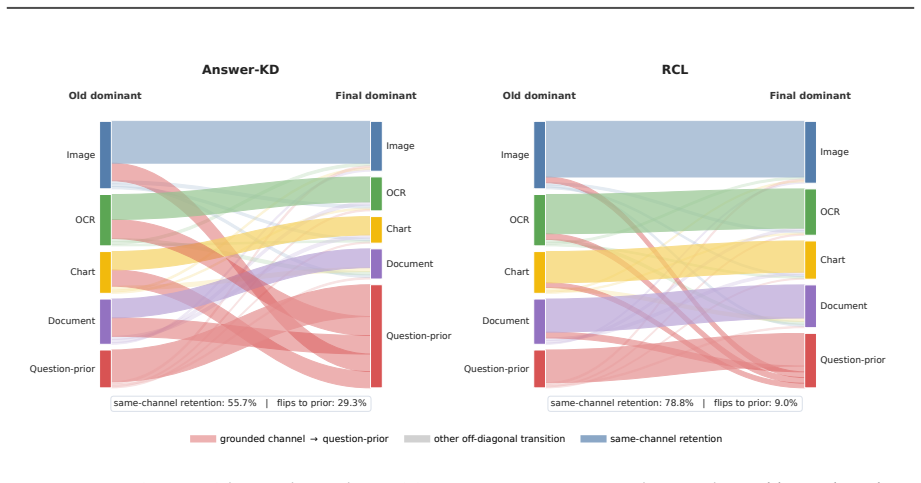
The paper claims that answer accuracy can be preserved while the model's internal reliance on different evidence modalities drifts or flips entirely, a failure mode called hidden evidence-use forgetting. It shows that a framework which freezes the previous checkpoint, estimates reliance profiles via counterfactual channel interventions, and jointly optimizes task learning with both prediction and reliance preservation reduces modality drift, dominant evidence flips, and hidden forgetting rates on CoIN, COAST, MCITlib, and an evidence-sensitive stream, outperforming replay-free, PEFT, routing, and memory-assisted baselines.
What carries the argument
RCL, a framework that freezes the prior checkpoint as behavioral reference, derives evidence-reliance profiles by intervening on input channels, and adds reliance-preservation terms to the training objective.
If this is right
- Standard accuracy-only metrics are insufficient to certify stability in continual multimodal learning.
- Preserving evidence reliance reduces hidden forgetting without replay or added inference cost.
- RCL improves final performance and lowers drift rates over PEFT, routing, and memory baselines across tested streams.
- The evidence path behind a correct answer must be treated as an explicit optimization target.
Where Pith is reading between the lines
- The same hidden shift could appear in continual learning settings that use only text or only images if reliance on different input features is not monitored.
- One testable extension is whether reliance preservation also stabilizes longer reasoning chains that depend on the preserved evidence.
- If interventions are cheap, the same measurement could be added to other continual-learning algorithms as a diagnostic rather than only as a training constraint.
Load-bearing premise
Counterfactual channel interventions produce reliable estimates of a model's true evidence-reliance profile without altering its internal behavior or introducing measurement artifacts.
What would settle it
Measure reliance profiles on the same inputs before and after adaptation on a held-out stream; if accuracy stays high while dominant evidence channel or reliance weights change substantially, the claim of hidden forgetting is supported.
Figures

read the original abstract
Multimodal large language models must continually adapt to evolving tasks and domains, yet standard continual learning metrics mainly measure whether old answers remain correct, leaving the stability of multimodal grounding largely unexamined. We study this overlooked failure mode and ask whether a continually adapted MLLM can preserve not only what it answers, but also how it uses visual, textual, OCR, chart, and document evidence. We identify \emph{hidden evidence-use forgetting}, where answer accuracy is retained while the model silently shifts toward different or less grounded evidence channels, and propose \textsc{RCL}, a replay-free reliance-constrained continual learning framework. \textsc{RCL} freezes the previous checkpoint as a behavioral reference, estimates teacher and student evidence-reliance profiles through counterfactual channel interventions, and jointly optimizes task learning, prediction preservation, and reliance preservation without adding inference-time cost. Across CoIN, COAST, MCITlib, and an evidence-sensitive multimodal stream, \textsc{RCL} consistently improves final performance and reduces forgetting over replay-free, PEFT, routing, and memory-assisted baselines, while substantially lowering modality reliance drift, dominant evidence flips, and hidden forgetting rates. These results suggest that robust continual multimodal learning requires preserving the evidence path behind correct answers, not merely the answers themselves.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies an overlooked failure mode called hidden evidence-use forgetting in continual multimodal learning, where models retain answer accuracy on old tasks but silently shift their reliance on evidence channels (visual, textual, OCR, chart, document). It proposes RCL, a replay-free framework that freezes the prior checkpoint as reference, estimates teacher/student evidence-reliance profiles via counterfactual channel interventions, and jointly optimizes task learning, prediction preservation, and reliance preservation. Experiments across CoIN, COAST, MCITlib, and an evidence-sensitive stream report improved final performance, reduced forgetting, and lower modality reliance drift, dominant evidence flips, and hidden forgetting rates versus replay-free, PEFT, routing, and memory-assisted baselines.
Significance. If the central claims hold after addressing validation concerns, the work is significant for highlighting that standard accuracy-based continual learning metrics are insufficient for multimodal models and for offering a practical, inference-cost-free method to preserve grounding. The replay-free design and explicit focus on evidence paths address a real gap; however, the absence of independent verification of the intervention-derived profiles limits immediate impact.
major comments (2)
- [Abstract / Method description] The evaluation of reduced hidden forgetting, modality reliance drift, and dominant evidence flips relies on the same counterfactual channel interventions (e.g., masking vision or OCR) used both to train the reliance-preservation term and to compute the reported metrics. This risks self-referential results if interventions alter internal routing or induce compensatory behavior absent in the original forward pass; the abstract provides no independent checks such as attention maps, gradient attributions, or human grounding validation.
- [Experiments section (implied)] The soundness assessment is limited because the abstract (and available description) contains no experimental details, ablation studies on the reliance term, statistical significance tests, or derivation steps for how the joint optimization balances the three objectives; without these, it is impossible to verify whether the claimed reductions are supported by the data or method.
minor comments (1)
- [Method] Clarify early how the frozen checkpoint is used exactly as a behavioral reference without adding parameters or inference overhead.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment point by point below, providing clarifications on the evaluation design and experimental reporting while noting where revisions can strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Method description] The evaluation of reduced hidden forgetting, modality reliance drift, and dominant evidence flips relies on the same counterfactual channel interventions (e.g., masking vision or OCR) used both to train the reliance-preservation term and to compute the reported metrics. This risks self-referential results if interventions alter internal routing or induce compensatory behavior absent in the original forward pass; the abstract provides no independent checks such as attention maps, gradient attributions, or human grounding validation.
Authors: The counterfactual interventions define the evidence-reliance profiles by design, allowing the reliance-preservation term to directly optimize for stability in the same channels used for metric computation. This alignment ensures the metrics quantify exactly the hidden forgetting we study rather than introducing an independent axis. We acknowledge the referee's valid point on potential compensatory effects and will add a new subsection in the revised manuscript discussing intervention validity, along with gradient attribution comparisons on a subset of tasks to provide orthogonal evidence of preserved grounding. revision: partial
-
Referee: [Experiments section (implied)] The soundness assessment is limited because the abstract (and available description) contains no experimental details, ablation studies on the reliance term, statistical significance tests, or derivation steps for how the joint optimization balances the three objectives; without these, it is impossible to verify whether the claimed reductions are supported by the data or method.
Authors: The full manuscript contains the requested elements: Section 4 details the experimental protocol across all benchmarks, Section 5.3 presents ablations isolating the reliance term, Table 3 reports statistical significance via paired t-tests over five seeds, and Section 3.3 derives the joint objective with explicit weighting coefficients and sensitivity analysis. The abstract serves only as a concise overview; all verification components are in the main text. No changes are needed, though we can highlight these sections more explicitly in a revised abstract if the editor prefers. revision: no
Circularity Check
No circularity: derivation chain remains self-contained against external benchmarks
full rationale
The abstract and provided description outline RCL as using counterfactual channel interventions to estimate reliance profiles, then optimizing a joint loss that includes reliance preservation. No equations or sections are quoted that reduce the reported metrics (modality reliance drift, dominant evidence flips, hidden forgetting rates) to the same fitted parameters by construction. The interventions function as a measurement procedure whose outputs feed both training and evaluation, but this does not constitute a definitional loop or fitted-input prediction without explicit reduction shown in the paper's own math. The central claims rest on comparative results across multiple datasets and baselines rather than self-referential renaming or self-citation chains. This is the normal case of an independent empirical framework.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Climb: A continual learning benchmark for vision-and-language tasks , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
International Conference on Machine Learning , pages=
Continual vision-language representation learning with off-diagonal information , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[3]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Preventing zero-shot transfer degradation in continual learning of vision-language models , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[4]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Ctp: Towards vision-language continual pretraining via compatible momentum contrast and topology preservation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[5]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Decouple before interact: Multi-modal prompt learning for continual visual question answering , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[6]
Proceedings of the 31st ACM International Conference on Multimedia , pages=
Multi-domain lifelong visual question answering via self-critical distillation , author=. Proceedings of the 31st ACM International Conference on Multimedia , pages=
-
[7]
IEEE Transactions on Image Processing , year=
Continual instruction tuning for large multimodal models , author=. IEEE Transactions on Image Processing , year=
-
[8]
Advances in neural information processing systems , volume=
Coin: A benchmark of continual instruction tuning for multimodel large language models , author=. Advances in neural information processing systems , volume=
-
[9]
Advances in Neural Information Processing Systems , volume=
A Practitioner's Guide to Real-World Continual Multimodal Pretraining , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
Proceedings of the 41st International Conference on Machine Learning , pages=
Model tailor: mitigating catastrophic forgetting in multi-modal large language models , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[11]
arXiv preprint arXiv:2411.02564 (2024)
Continual llava: Continual instruction tuning in large vision-language models , author=. arXiv preprint arXiv:2411.02564 , year=
-
[12]
The Thirteenth International Conference on Learning Representations , year=
C-CLIP: Multimodal continual learning for vision-language model , author=. The Thirteenth International Conference on Learning Representations , year=
-
[13]
International Conference on Machine Learning , pages=
LADA: Scalable Label-Specific CLIP Adapter for Continual Learning , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[14]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Synthetic data is an elegant gift for continual vision-language models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[15]
Proceedings of the computer vision and pattern recognition conference , pages=
Cl-moe: Enhancing multimodal large language model with dual momentum mixture-of-experts for continual visual question answering , author=. Proceedings of the computer vision and pattern recognition conference , pages=
-
[16]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Hide-llava: Hierarchical decoupling for continual instruction tuning of multimodal large language model , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[17]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Enhancing multimodal continual instruction tuning with branchlora , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[18]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Progressive lora for multimodal continual instruction tuning , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[19]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Modalprompt: Towards efficient multimodal continual instruction tuning with dual-modality guided prompt , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[20]
42nd International Conference on Machine Learning (ICML 2025) , pages=
SEFE: Superficial and Essential Forgetting Eliminator for Multimodal Continual Instruction Tuning , author=. 42nd International Conference on Machine Learning (ICML 2025) , pages=. 2025 , organization=
2025
-
[21]
arXiv preprint arXiv:2506.05453 , year=
Mllm-cl: Continual learning for multimodal large language models , author=. arXiv preprint arXiv:2506.05453 , year=
-
[22]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Instruction-Grounded Visual Projectors for Continual Learning of Generative Vision-Language Models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[23]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Ask and remember: A questions-only replay strategy for continual visual question answering , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[24]
arXiv preprint arXiv:2503.08064 , year=
Continual learning for multiple modalities , author=. arXiv preprint arXiv:2503.08064 , year=
-
[25]
arXiv preprint arXiv:2508.07307 , year=
Mcitlib: Multimodal continual instruction tuning library and benchmark , author=. arXiv preprint arXiv:2508.07307 , year=
-
[26]
International Conference on Learning Representations , year=
LoRA: Low-Rank Adaptation of Large Language Models , author=. International Conference on Learning Representations , year=
-
[27]
Proceedings of the National Academy of Sciences , volume=
Overcoming Catastrophic Forgetting in Neural Networks , author=. Proceedings of the National Academy of Sciences , volume=
-
[28]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Learning without Forgetting , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
-
[29]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Learning to Prompt for Continual Learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[30]
European Conference on Computer Vision , pages=
DualPrompt: Complementary Prompting for Rehearsal-Free Continual Learning , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[31]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
CODA-Prompt: COntinual Decomposed Attention-Based Prompting for Rehearsal-Free Continual Learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[32]
In: Findings of the Asso- ciation for Computational Linguistics: EMNLP 2023, pp
Orthogonal Subspace Learning for Language Model Continual Learning , author=. arXiv preprint arXiv:2310.14152 , year=
-
[33]
Proceedings of the European Conference on Computer Vision , pages=
Memory Aware Synapses: Learning What (Not) to Forget , author=. Proceedings of the European Conference on Computer Vision , pages=
-
[34]
Advances in Neural Information Processing Systems , volume=
Dark Experience for General Continual Learning: A Strong, Simple Baseline , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
On Tiny Episodic Memories in Continual Learning
On Tiny Episodic Memories in Continual Learning , author=. arXiv preprint arXiv:1902.10486 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[36]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Improved Baselines with Visual Instruction Tuning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[37]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[38]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Counterfactual vqa: A cause-effect look at language bias , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[39]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Don't just assume; look and answer: Overcoming priors for visual question answering , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[40]
arXiv preprint arXiv:2604.00677 , year=
CL-VISTA: Benchmarking Continual Learning in Video Large Language Models , author=. arXiv preprint arXiv:2604.00677 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.