Hierarchical Anti-Aesthetics: Protecting Facial Privacy against Customized Diffusion Models
Pith reviewed 2026-07-03 16:01 UTC · model grok-4.3
The pith
The Hierarchical Anti-Aesthetics framework protects facial privacy by degrading the quality of images from customized diffusion models at global and local levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
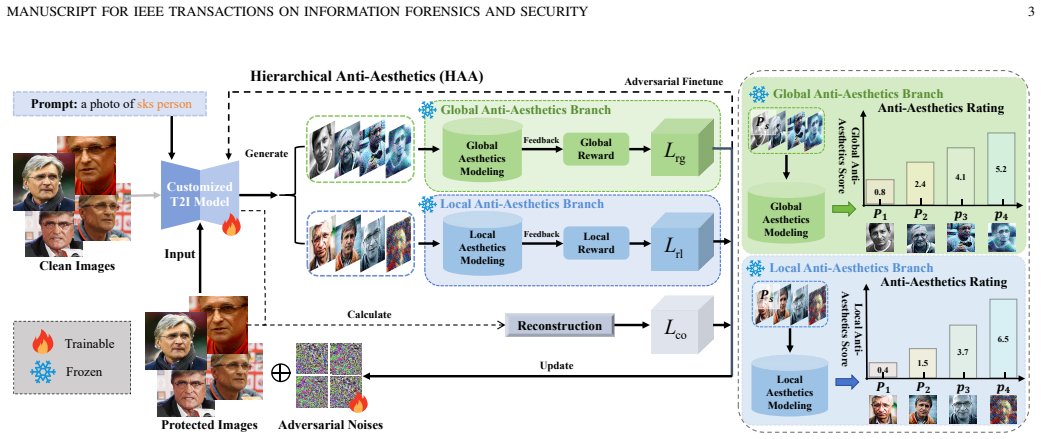
The paper claims that the Hierarchical Anti-Aesthetics (HAA) framework, built from global and local anti-aesthetic branches each using dedicated reward mechanisms and losses, reduces facial identity leakage by degrading overall and region-specific aesthetics in images produced by customized diffusion models.
What carries the argument
The Hierarchical Anti-Aesthetics (HAA) framework consisting of a Global Anti-Aesthetics branch and a Local Anti-Aesthetics branch, each driven by an anti-aesthetic reward mechanism and corresponding loss to direct degradation.
Load-bearing premise
Degrading aesthetic quality at both global and local perceptual levels will reliably reduce facial identity leakage in images from customized diffusion models.
What would settle it
A controlled test in which customized diffusion models trained on HAA-protected images still output faces with high identity similarity scores even after aesthetic quality has been measurably lowered.
Figures







read the original abstract
The rise of customized diffusion models has fueled a boom in personalized visual content creation, but it also introduces serious risks of malicious misuse, thereby posing threats to personal privacy. Image aesthetics are strongly correlated with human perception of image quality. Motivated by this observation, we address facial privacy protection from a novel aesthetic perspective by degrading the generation quality of maliciously customized models, thus reducing facial identity leakage. Specifically, we propose a Hierarchical Anti-Aesthetics (HAA) framework that exploits aesthetic cues at multiple perceptual levels. HAA consists of two key branches: (1) Global Anti-Aesthetics, which degrades overall aesthetics and generation quality by constructing a global anti-aesthetic reward mechanism and a corresponding loss; and (2) Local Anti-Aesthetics, which disrupts facial identity by using a local anti-aesthetic reward mechanism and loss to guide adversarial perturbations toward facial regions. By integrating both branches, HAA achieves anti-aesthetic degradation from a global to a local level during customized generation. Extensive experiments show that HAA outperforms existing methods in identity removal, providing an effective tool for protecting facial privacy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
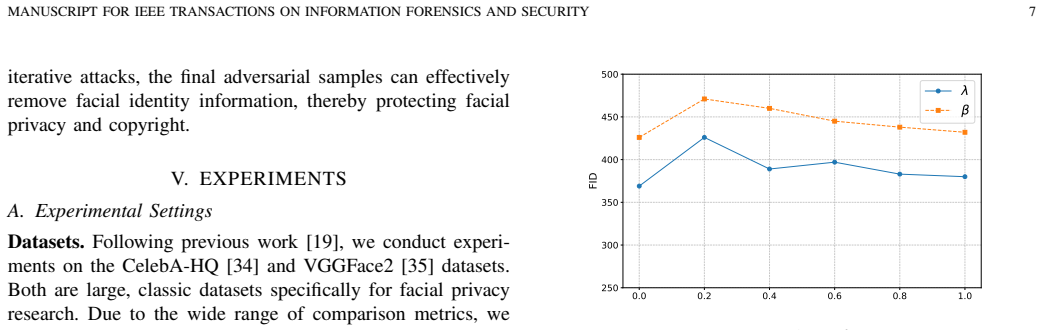
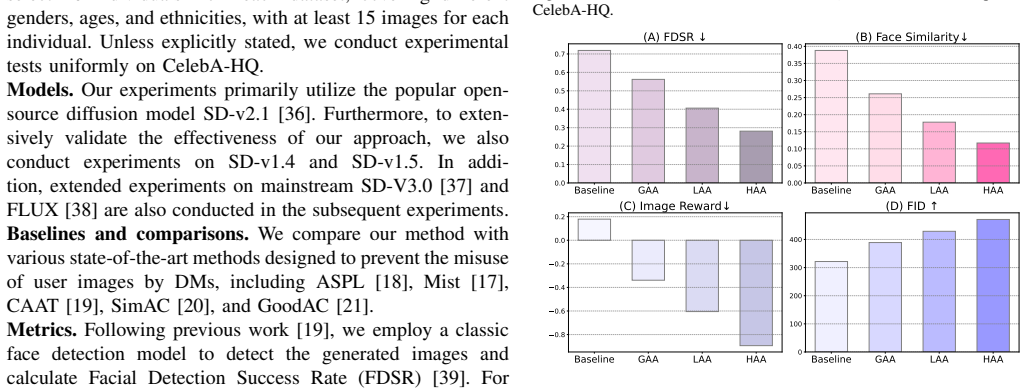
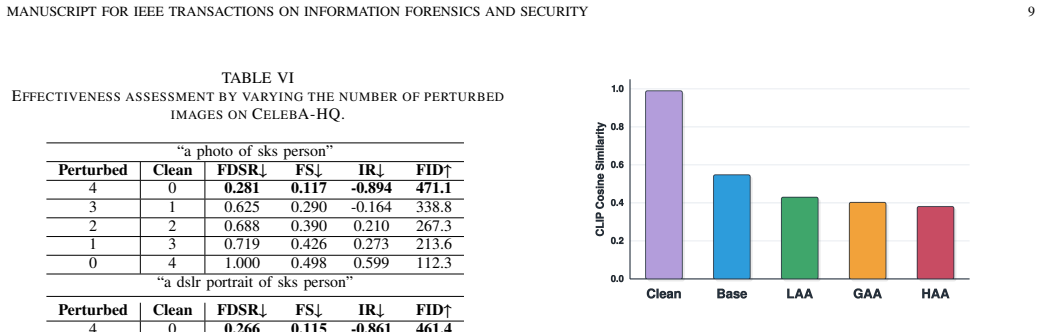
Summary. The paper proposes Hierarchical Anti-Aesthetics (HAA), a two-branch framework for facial privacy protection against customized diffusion models. Global Anti-Aesthetics constructs a reward mechanism and loss to degrade overall image aesthetics and generation quality; Local Anti-Aesthetics applies a separate reward and loss to drive adversarial perturbations specifically into facial regions. The central claim is that integrating the branches produces hierarchical anti-aesthetic degradation that reduces facial identity leakage, with extensive experiments asserted to show outperformance over prior methods.
Significance. If the causal link between aesthetic degradation and identity removal is validated, the work would introduce a new aesthetic-based axis for adversarial defense in personalized generative models. It could inform privacy tools that operate without direct access to model weights. The absence of any parameter-free derivation, machine-checked proof, or falsifiable prediction in the presented material limits the immediate technical contribution.
major comments (2)
- [Abstract] Abstract: the claim that 'HAA outperforms existing methods in identity removal' is stated without reference to any quantitative metrics, baselines, datasets, or ablation results. Because this is the sole empirical support for the central privacy-protection claim, the absence of evidence prevents assessment of whether the method actually succeeds.
- [Abstract] Abstract: the motivation equates correlation ('Image aesthetics are strongly correlated with human perception of image quality') with the causal claim that deliberately lowering aesthetic scores will preferentially disrupt identity manifolds rather than merely reducing perceptual quality metrics. No derivation, auxiliary experiment, or analysis is supplied to show that identity-specific features are more sensitive to the proposed global/local anti-aesthetic losses than other structural cues.
minor comments (1)
- [Abstract] The abstract introduces 'global anti-aesthetic reward mechanism' and 'local anti-aesthetic reward mechanism' without even a one-sentence definition or reference to the equations that implement them, making the high-level description difficult to follow.
Simulated Author's Rebuttal
We thank the referee for the detailed comments on the abstract. We respond to each major comment below and indicate where revisions will be made to improve clarity and support for the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'HAA outperforms existing methods in identity removal' is stated without reference to any quantitative metrics, baselines, datasets, or ablation results. Because this is the sole empirical support for the central privacy-protection claim, the absence of evidence prevents assessment of whether the method actually succeeds.
Authors: The abstract is intended as a high-level summary; the quantitative metrics, baselines (e.g., existing adversarial and privacy-protection methods), datasets, and ablation studies are presented in detail in the experiments section of the full manuscript. To directly address the concern and allow readers to assess the claim from the abstract itself, we will revise the abstract to include specific quantitative results, such as identity similarity scores or removal rates relative to baselines on standard facial datasets. revision: yes
-
Referee: [Abstract] Abstract: the motivation equates correlation ('Image aesthetics are strongly correlated with human perception of image quality') with the causal claim that deliberately lowering aesthetic scores will preferentially disrupt identity manifolds rather than merely reducing perceptual quality metrics. No derivation, auxiliary experiment, or analysis is supplied to show that identity-specific features are more sensitive to the proposed global/local anti-aesthetic losses than other structural cues.
Authors: The manuscript is an empirical study motivated by the established correlation between aesthetics and perceived quality; the hierarchical losses are designed and validated through experiments to reduce identity leakage in customized diffusion outputs. No theoretical derivation or formal proof of preferential sensitivity of identity features is provided, as the contribution centers on the practical effectiveness of the two-branch framework rather than a causal mechanistic analysis. We will add a brief clarifying sentence in the introduction or discussion to explicitly note the empirical basis of the approach. revision: partial
Circularity Check
No circularity: method proposal is self-contained and independent of its motivational assumption.
full rationale
The paper motivates HAA from the observed correlation between aesthetics and perceived quality, then defines global and local anti-aesthetic reward mechanisms plus losses to degrade generation. This construction does not reduce to the correlation by definition, nor does any equation or branch rename a fitted input as a prediction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes imported from prior author work appear in the abstract or described framework. The derivation chain consists of an independent engineering proposal whose effectiveness is tested experimentally rather than forced by its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Image aesthetics are strongly correlated with human perception of image quality.
Reference graph
Works this paper leans on
-
[1]
Vector quantized diffusion model for text-to-image synthesis,
S. Gu, D. Chen, J. Bao, F. Wen, B. Zhang, D. Chen, L. Yuan, and B. Guo, “Vector quantized diffusion model for text-to-image synthesis,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 696–10 706
2022
-
[2]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695
2022
-
[3]
Hierarchical Text-Conditional Image Generation with CLIP Latents
A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen, “Hierarchical text-conditional image generation with clip latents,”arXiv preprint arXiv:2204.06125, vol. 1, no. 2, p. 3, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in neural information processing systems, vol. 33, pp. 6840– 6851, 2020
2020
-
[5]
Denoising Diffusion Implicit Models
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[6]
Text2live: Text-driven layered image and video editing,
O. Bar-Tal, D. Ofri-Amar, R. Fridman, Y . Kasten, and T. Dekel, “Text2live: Text-driven layered image and video editing,” inEuropean conference on computer vision. Springer, 2022, pp. 707–723
2022
-
[7]
Diffusionclip: Text-guided diffusion models for robust image manipulation,
G. Kim, T. Kwon, and J. C. Ye, “Diffusionclip: Text-guided diffusion models for robust image manipulation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 2426–2435
2022
-
[8]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
R. Gal, Y . Alaluf, Y . Atzmon, O. Patashnik, A. H. Bermano, G. Chechik, and D. Cohen-Or, “An image is worth one word: Person- alizing text-to-image generation using textual inversion,”arXiv preprint arXiv:2208.01618, 2022. MANUSCRIPT FOR IEEE TRANSACTIONS ON INFORMATION FORENSICS AND SECURITY 16
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
Dreambooth: Fine tuning text-to-image diffusion models for subject- driven generation,
N. Ruiz, Y . Li, V . Jampani, Y . Pritch, M. Rubinstein, and K. Aberman, “Dreambooth: Fine tuning text-to-image diffusion models for subject- driven generation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 22 500–22 510
2023
-
[10]
Multi- concept customization of text-to-image diffusion,
N. Kumari, B. Zhang, R. Zhang, E. Shechtman, and J.-Y . Zhu, “Multi- concept customization of text-to-image diffusion,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 1931–1941
2023
-
[11]
Svdiff: Compact parameter space for diffusion fine-tuning,
L. Han, Y . Li, H. Zhang, P. Milanfar, D. Metaxas, and F. Yang, “Svdiff: Compact parameter space for diffusion fine-tuning,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 7323–7334
2023
-
[12]
Bagm: A backdoor attack for manipulating text-to-image generative models,
J. Vice, N. Akhtar, R. Hartley, and A. Mian, “Bagm: A backdoor attack for manipulating text-to-image generative models,”IEEE Transactions on Information Forensics and Security, 2024
2024
-
[13]
Personalization as a shortcut for few-shot backdoor attack against text-to-image diffusion models,
Y . Huang, F. Juefei-Xu, Q. Guo, J. Zhang, Y . Wu, M. Hu, T. Li, G. Pu, and Y . Liu, “Personalization as a shortcut for few-shot backdoor attack against text-to-image diffusion models,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 19, 2024, pp. 21 169– 21 178
2024
-
[14]
Leveraging frequency analysis for deep fake image recogni- tion,
J. Frank, T. Eisenhofer, L. Sch ¨onherr, A. Fischer, D. Kolossa, and T. Holz, “Leveraging frequency analysis for deep fake image recogni- tion,” inInternational conference on machine learning. PMLR, 2020, pp. 3247–3258
2020
-
[15]
A comprehensive overview of deepfake: Generation, detection, datasets, and opportuni- ties,
J. W. Seow, M. K. Lim, R. C. Phan, and J. K. Liu, “A comprehensive overview of deepfake: Generation, detection, datasets, and opportuni- ties,”Neurocomputing, vol. 513, pp. 351–371, 2022
2022
-
[16]
Deepfake detection by analyz- ing convolutional traces,
L. Guarnera, O. Giudice, and S. Battiato, “Deepfake detection by analyz- ing convolutional traces,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, 2020, pp. 666– 667
2020
-
[17]
Understanding and im- proving adversarial attacks on latent diffusion model,
B. Zheng, C. Liang, X. Wu, and Y . Liu, “Understanding and im- proving adversarial attacks on latent diffusion model,”arXiv preprint arXiv:2310.04687, 2023
-
[18]
Anti-dreambooth: Protecting users from personalized text-to-image synthesis,
T. Van Le, H. Phung, T. H. Nguyen, Q. Dao, N. N. Tran, and A. Tran, “Anti-dreambooth: Protecting users from personalized text-to-image synthesis,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 2116–2127
2023
-
[19]
Perturbing attention gives you more bang for the buck: Subtle imaging perturbations that efficiently fool customized diffusion models,
J. Xu, Y . Lu, Y . Li, S. Lu, D. Wang, and X. Wei, “Perturbing attention gives you more bang for the buck: Subtle imaging perturbations that efficiently fool customized diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 24 534–24 543
2024
-
[20]
Simac: a simple anti-customization method for protecting face privacy against text-to- image synthesis of diffusion models,
F. Wang, Z. Tan, T. Wei, Y . Wu, and Q. Huang, “Simac: a simple anti-customization method for protecting face privacy against text-to- image synthesis of diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 12 047–12 056
2024
-
[21]
Harnessing global- local collaborative adversarial perturbation for anti-customization,
L. Xu, J. Wang, H. Hao, H. Qin, J. Zhao, and X. Liu, “Harnessing global- local collaborative adversarial perturbation for anti-customization,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025, pp. 13 414–13 423
2025
-
[22]
Image quality and the aesthetic judgment of photographs: Contrast, sharpness, and grain teased apart and put together
P. P. Tinio, H. Leder, and M. Strasser, “Image quality and the aesthetic judgment of photographs: Contrast, sharpness, and grain teased apart and put together.”Psychology of Aesthetics, Creativity, and the Arts, vol. 5, no. 2, p. 165, 2011
2011
-
[23]
Visual aesthetics and human preference,
S. E. Palmer, K. B. Schloss, and J. Sammartino, “Visual aesthetics and human preference,”Annual review of psychology, vol. 64, no. 1, pp. 77–107, 2013
2013
-
[24]
Rating image aesthetics using deep learning,
X. Lu, Z. Lin, H. Jin, J. Yang, and J. Z. Wang, “Rating image aesthetics using deep learning,”IEEE Transactions on Multimedia, vol. 17, no. 11, pp. 2021–2034, 2015
2021
-
[25]
Personalizing text-to-image generation via aesthetic gradi- ents,
V . Gallego, “Personalizing text-to-image generation via aesthetic gradi- ents,”arXiv preprint arXiv:2209.12330, 2022
-
[26]
Vmix: Improving text- to-image diffusion model with cross-attention mixing control,
S. Wu, F. Ding, M. Huang, W. Liu, and Q. He, “Vmix: Improving text- to-image diffusion model with cross-attention mixing control,”arXiv preprint arXiv:2412.20800, 2024
-
[27]
Cascaded diffusion models for high fidelity image generation,
J. Ho, C. Saharia, W. Chan, D. J. Fleet, M. Norouzi, and T. Salimans, “Cascaded diffusion models for high fidelity image generation,”Journal of Machine Learning Research, vol. 23, no. 47, pp. 1–33, 2022
2022
-
[28]
Repaint: Inpainting using denoising diffusion probabilistic models,
A. Lugmayr, M. Danelljan, A. Romero, F. Yu, R. Timofte, and L. Van Gool, “Repaint: Inpainting using denoising diffusion probabilistic models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 11 461–11 471
2022
-
[29]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. M ¨uller, J. Penna, and R. Rombach, “Sdxl: Improving latent diffusion models for high-resolution image synthesis,”arXiv preprint arXiv:2307.01952, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PMLR, 2021, pp. 8748–8763
2021
-
[31]
C. Liang, X. Wu, Y . Hua, J. Zhang, Y . Xue, T. Song, Z. Xue, R. Ma, and H. Guan, “Adversarial example does good: Preventing painting im- itation from diffusion models via adversarial examples,”arXiv preprint arXiv:2302.04578, 2023
-
[32]
Imagereward: Learning and evaluating human preferences for text-to- image generation,
J. Xu, X. Liu, Y . Wu, Y . Tong, Q. Li, M. Ding, J. Tang, and Y . Dong, “Imagereward: Learning and evaluating human preferences for text-to- image generation,”Advances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[33]
The surprising effectiveness of ppo in cooperative multi-agent games,
C. Yu, A. Velu, E. Vinitsky, J. Gao, Y . Wang, A. Bayen, and Y . Wu, “The surprising effectiveness of ppo in cooperative multi-agent games,” Advances in neural information processing systems, vol. 35, pp. 24 611– 24 624, 2022
2022
-
[34]
Celebv-hq: A large-scale video facial attributes dataset,
H. Zhu, W. Wu, W. Zhu, L. Jiang, S. Tang, L. Zhang, Z. Liu, and C. C. Loy, “Celebv-hq: A large-scale video facial attributes dataset,” in European conference on computer vision. Springer, 2022, pp. 650–667
2022
-
[35]
Vggface2: A dataset for recognising faces across pose and age,
Q. Cao, L. Shen, W. Xie, O. M. Parkhi, and A. Zisserman, “Vggface2: A dataset for recognising faces across pose and age,” in2018 13th IEEE international conference on automatic face & gesture recognition (FG 2018). IEEE, 2018, pp. 67–74
2018
-
[36]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” 2021
2021
-
[37]
Scaling rectified flow transformers for high-resolution image synthesis,
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. M ¨uller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boeselet al., “Scaling rectified flow transformers for high-resolution image synthesis,” inForty-first international conference on machine learning, 2024
2024
-
[38]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
B. F. Labs, S. Batifol, A. Blattmann, F. Boesel, S. Consul, C. Diagne, T. Dockhorn, J. English, Z. English, P. Esser, S. Kulal, K. Lacey, Y . Levi, C. Li, D. Lorenz, J. M ¨uller, D. Podell, R. Rombach, H. Saini, A. Sauer, and L. Smith, “Flux.1 kontext: Flow matching for in-context image generation and editing in latent space,” 2025. [Online]. Available: h...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
From facial parts responses to face detection: A deep learning approach,
S. Yang, P. Luo, C.-C. Loy, and X. Tang, “From facial parts responses to face detection: A deep learning approach,” inProceedings of the IEEE international conference on computer vision, 2015, pp. 3676–3684
2015
-
[40]
Arcface: Additive angular margin loss for deep face recognition,
J. Deng, J. Guo, N. Xue, and S. Zafeiriou, “Arcface: Additive angular margin loss for deep face recognition,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 4690– 4699
2019
-
[41]
Gans trained by a two time-scale update rule converge to a local nash equilibrium,
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[42]
Retinaface: Single-shot multi-level face localisation in the wild,
J. Deng, J. Guo, E. Ververas, I. Kotsia, and S. Zafeiriou, “Retinaface: Single-shot multi-level face localisation in the wild,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 5203–5212
2020
-
[43]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 586–595
2018
-
[44]
Image quality assessment: from error visibility to structural similarity,
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,”IEEE transactions on image processing, vol. 13, no. 4, pp. 600–612, 2004
2004
-
[45]
Laion- 5b: An open large-scale dataset for training next generation image-text models,
C. Schuhmann, R. Beaumont, R. Vencu, C. Gordon, R. Wightman, M. Cherti, T. Coombes, A. Katta, C. Mullis, M. Wortsmanet al., “Laion- 5b: An open large-scale dataset for training next generation image-text models,”Advances in neural information processing systems, vol. 35, pp. 25 278–25 294, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.