LongEgoRefer: A Benchmark for Long-Form Egocentric Video Referring Expression Comprehension
Pith reviewed 2026-07-03 15:38 UTC · model grok-4.3
The pith
Current state-of-the-art models struggle significantly on long-form egocentric video referring expression comprehension.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
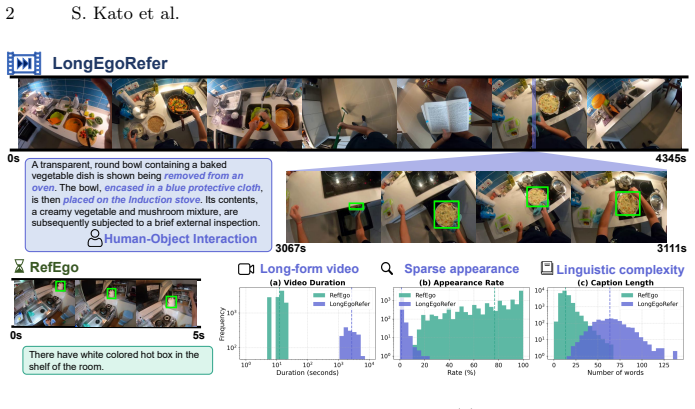
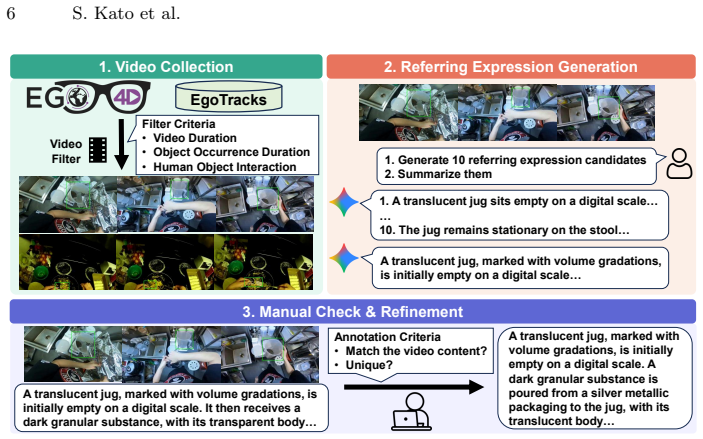
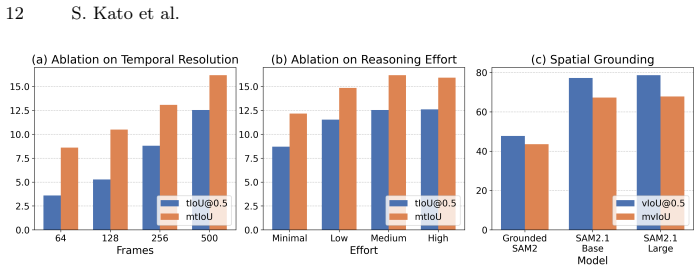
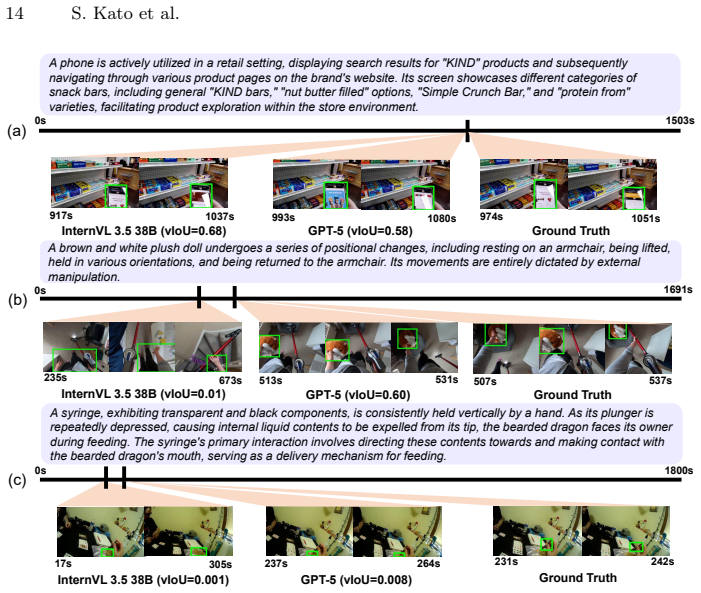
LongEgoRefer establishes a benchmark for Video REC on long untrimmed egocentric videos that exhibit extreme target sparsity, detailed linguistic descriptions, and complex human-object interactions. Existing Video REC approaches, including training-free baselines that combine vision-language models with Grounded SAM2 and current state-of-the-art models, perform poorly on the benchmark, thereby defining a demanding problem of identifying both when an event occurs and where the referred object appears within extended video sequences.
What carries the argument
The LongEgoRefer benchmark itself, whose construction from Ego4D enforces long duration, extreme target sparsity, and the need for joint temporal and spatial localization under complex activity transitions.
If this is right
- Video REC systems must incorporate mechanisms that maintain object identity across dozens of minutes of sparse appearances.
- Linguistic detail in queries must be resolved jointly with long-range temporal context rather than frame-level or short-clip features.
- Models will need explicit handling of activity transitions that interrupt object visibility in egocentric narratives.
- Training regimes for spatio-temporal grounding must shift from dense short clips to long, sparsely labeled sequences.
- Progress on real-world egocentric applications will require architectures that scale beyond current temporal windows.
Where Pith is reading between the lines
- Similar long-form benchmarks could be built for other video domains such as surveillance or instructional footage to expose comparable sparsity issues.
- The performance gap suggests that simply scaling current transformer-based video models may not close the task without new mechanisms for long-term memory and sparse attention.
- Deployment in wearable devices or robotics would likely remain limited until models demonstrate reliable localization over multi-minute horizons.
- The benchmark could serve as a stress test for future video-language models that claim general long-context understanding.
Load-bearing premise
The referring expressions and video segments chosen from Ego4D accurately represent the sparsity, linguistic detail, and activity transitions of real-world long-form egocentric recordings without systematic annotation bias or selection effects.
What would settle it
A new model that achieves substantially higher accuracy than the reported baselines on the LongEgoRefer test set, or independent re-annotation of a subset of the expressions that reveals consistent selection bias, would directly test the central claim.
Figures


read the original abstract
Egocentric videos capture rich and diverse human-object interactions and have emerged as a fundamental resource for understanding human activities related to objects. In this context, Video Referring Expression Comprehension (Video REC), the task of localizing the temporal and spatial extent of a referred object in video frames given a natural language query, plays a key role in linking textual descriptions to observed objects in untrimmed egocentric recordings. However, existing egocentric Video REC benchmarks primarily focus on short video clips, where some target object appears densely within frames. Such settings do not reflect real-world egocentric recordings, which are long-form, untrimmed, and characterized by sparse object occurrences and complex activity transitions. To address this limitation, we introduce LongEgoRefer, a novel and challenging benchmark constructed from long-form videos in the Ego4D dataset. LongEgoRefer contains 1,498 referring expressions with an average video duration of 45 minutes. The benchmark exhibits extreme target sparsity, detailed linguistic descriptions, and complex human-object interactions embedded in long, dynamic egocentric narratives. Consequently, it defines a demanding spatio-temporal grounding problem that requires models to identify both when an event occurs and where the referred object appears within extended video sequences. We evaluate existing Video REC approaches, including training-free baselines based on vision-language models combined with Grounded SAM2. Extensive experiments show that even advanced baselines and current state-of-the-art models struggle significantly on LongEgoRefer. These results highlight the intrinsic difficulty of long-form egocentric spatio-temporal grounding and emphasize the need for more robust video understanding models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LongEgoRefer, a benchmark for long-form egocentric Video Referring Expression Comprehension derived from Ego4D. It comprises 1,498 referring expressions across videos averaging 45 minutes, featuring extreme target sparsity, detailed linguistic descriptions, and complex activity transitions. The authors evaluate training-free baselines (vision-language models with Grounded SAM2) and existing Video REC methods, claiming that even advanced and state-of-the-art models struggle significantly, thereby highlighting the intrinsic difficulty of spatio-temporal grounding in long untrimmed egocentric videos.
Significance. If the benchmark construction is shown to be representative of Ego4D without curation bias, the work would usefully expose gaps in current models' ability to handle sparse object occurrences and long temporal contexts in egocentric video, providing a concrete testbed that could drive progress in robust video understanding.
major comments (1)
- [Benchmark construction] Benchmark construction section: the manuscript provides no sampling protocol for selecting the 1,498 expressions and 45-minute segments, no inter-annotator agreement statistics, and no distributional comparisons (e.g., object sparsity histograms or query complexity metrics) against the full Ego4D corpus. This directly undermines the central claim that poor model performance reflects intrinsic long-form difficulty rather than selection effects favoring extreme cases.
minor comments (1)
- [Abstract] Abstract: the statement that models 'struggle significantly' is not accompanied by any quantitative metrics, baseline implementation details, or performance numbers, which reduces the abstract's informativeness even though the full experiments section presumably contains them.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment on benchmark construction below and will incorporate the necessary revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction section: the manuscript provides no sampling protocol for selecting the 1,498 expressions and 45-minute segments, no inter-annotator agreement statistics, and no distributional comparisons (e.g., object sparsity histograms or query complexity metrics) against the full Ego4D corpus. This directly undermines the central claim that poor model performance reflects intrinsic long-form difficulty rather than selection effects favoring extreme cases.
Authors: We agree that the manuscript would benefit from greater transparency in the benchmark construction process. In the revised version, we will expand the relevant section to explicitly describe the sampling protocol used to select the 1,498 referring expressions and associated 45-minute video segments from Ego4D. We will also include inter-annotator agreement statistics for the annotations and add distributional comparisons (including object sparsity histograms and query complexity metrics) relative to the full Ego4D corpus. These additions will help demonstrate that the observed model difficulties arise from the inherent challenges of long-form egocentric spatio-temporal grounding rather than from selection bias. revision: yes
Circularity Check
No circularity: empirical benchmark with no derivation chain
full rationale
The paper introduces LongEgoRefer as a new benchmark constructed by selecting referring expressions and segments from the external Ego4D dataset, then reports direct model evaluations on it. No equations, fitted parameters, predictions, or self-citation load-bearing steps exist. The construction and results are empirical and self-contained against external data; no claim reduces to its own inputs by definition or construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Ego4D provides representative long-form egocentric videos suitable for constructing a referring-expression benchmark.
Reference graph
Works this paper leans on
-
[1]
LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training
An, X., Xie, Y., Yang, K., Zhang, W., Zhao, X., Cheng, Z., Wang, Y., Xu, S., Chen, C., Zhu, D., et al.: Llava-onevision-1.5: Fully open framework for democratized multimodal training. arXiv preprint arXiv:2509.23661 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Bai, Z., He, T., Mei, H., Wang, P., Gao, Z., Chen, J., Liu, L., Zhang, Z., Shou, M.Z.: One token to seg them all: Language instructed reasoning segmentation in videos. In: Adv. Neural Inform. Process. Syst. pp. 6833–6859 (2024)
2024
-
[4]
In: IEEE Conf
Bärmann, L., Waibel, A.: Where did i leave my keys? — episodic-memory-based question answering on egocentric videos. In: IEEE Conf. Comput. Vis. Pattern Recog. Worksh. pp. 1560–1568 (2022)
2022
-
[5]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Bjorck, J., Castañeda, F., Cherniadev, N., Da, X., Ding, R., Fan, L., Fang, Y., Fox, D., Hu, F., Huang, S., et al.: Gr00t n1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv:2503.14734 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
SAM 3: Segment Anything with Concepts
Carion, N., Gustafson, L., Hu, Y.T., Debnath, S., Hu, R., Suris, D., Ryali, C., Al- wala, K.V., Khedr, H., Huang, A., et al.: SAM 3: Segment anything with concepts. arXiv preprint arXiv:2511.16719 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Chandrasegaran, K., Gupta, A., Hadzic, L.M., Kota, T., He, J., Eyzaguirre, C., Durante, Z., Li, M., Wu, J., Li, F.F.: Hourvideo: 1-hour video-language under- standing. In: Adv. Neural Inform. Process. Syst. pp. 53168–53197 (2024)
2024
-
[8]
Chen, Y., Xue, F., Li, D., Hu, Q., Zhu, L., Li, X., Fang, Y., Tang, H., Yang, S., Liu, Z., He, E., Yin, H., Molchanov, P., Kautz, J., Fan, L., Zhu, Y., Lu, Y., Han, S.: Longvila: Scaling long-context visual language models for long videos. In: Int. Conf. Learn. Represent. (2025)
2025
-
[9]
Damen, D., Doughty, H., Farinella, G.M., Fidler, S., Furnari, A., Kazakos, E., Moltisanti, D., Munro, J., Perrett, T., Price, W., Wray, M.: Scaling egocentric vision: The epic-kitchens dataset. In: Eur. Conf. Comput. Vis. pp. 720–736 (2018) 16 S. Kato et al
2018
-
[10]
In: IEEE Conf
Di, S., Xie, W.: Grounded question-answering in long egocentric videos. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 12934–12943 (2024)
2024
-
[11]
Ding, H., Liu, C., He, S., Jiang, X., Loy, C.C.: Mevis: A large-scale benchmark for video segmentation with motion expressions. In: Int. Conf. Comput. Vis. pp. 2694–2703 (2023)
2023
-
[12]
Project Aria: A New Tool for Egocentric Multi-Modal AI Research
Engel, J., Somasundaram, K., Goesele, M., Sun, A., Gamino, A., Turner, A., Ta- lattof, A., Yuan, A., Souti, B., Meredith, B., et al.: Project aria: A new tool for egocentric multi-modal ai research. arXiv preprint arXiv:2308.13561 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
In: IEEE Conf
Fu, C., Dai, Y., Luo, Y., Li, L., Ren, S., Zhang, R., Wang, Z., Zhou, C., Shen, Y., Zhang, M., Chen, P., Li, Y., Lin, S., Zhao, S., Li, K., Xu, T., Zheng, X., Chen, E., Shan, C., He, R., Sun, X.: Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 24108–24118 (2025)
2025
-
[14]
In: IEEE Conf
Gavrilyuk, K., Ghodrati, A., Li, Z., Snoek, C.G.: Actor and action video segmenta- tion from a sentence. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 5958–5966 (2018)
2018
-
[15]
Gemini Team: Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
In: IEEE Conf
Grauman, K., Westbury, A., Byrne, E., Chavis, Z., Furnari, A., Girdhar, R., Ham- burger, J., Jiang, H., Liu, M., Liu, X., et al.: Ego4d: Around the world in 3,000 hours of egocentric video. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 18995– 19012 (2022)
2022
-
[17]
In: IEEE Conf
Grauman, K., Westbury, A., Torresani, L., Kitani, K., Malik, J., Afouras, T., Ashutosh, K., Baiyya, V., Bansal, S., Boote, B., et al.: Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 19383–19400 (2024)
2024
-
[18]
Huang,D.A.,Liao,S.,Radhakrishnan,S.,Yin,H.,Molchanov,P.,Yu,Z.,Kautz,J.: Lita: Language instructed temporal-localization assistant. In: Eur. Conf. Comput. Vis. pp. 202–218 (2024)
2024
-
[19]
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
In: IEEE Conf
Jang, Y., Song, Y., Yu, Y., Kim, Y., Kim, G.: Tgif-qa: Toward spatio-temporal rea- soning in visual question answering. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 2758–2766 (2017)
2017
-
[21]
In: Conference on Empirical Methods in Natural Language Processing
Kazemzadeh, S., Ordonez, V., Matten, M., Berg, T.: ReferItGame: Referring to objects in photographs of natural scenes. In: Conference on Empirical Methods in Natural Language Processing. pp. 787–798 (2014)
2014
-
[22]
In: Asian Conf
Khoreva, A., Rohrbach, A., Schiele, B.: Video object segmentation with language referring expressions. In: Asian Conf. Comput. Vis. pp. 123–141 (2018)
2018
-
[23]
Kurita, S., Katsura, N., Onami, E.: Refego: Referring expression comprehension dataset from first-person perception of ego4d. In: Int. Conf. Comput. Vis. pp. 15214–15224 (2023)
2023
-
[24]
Li, K., Wang, Y., He, Y., Li, Y., Wang, Y., Liu, Y., Wang, Z., Xu, J., Chen, G., Luo, P., Wang, L., Qiao, Y.: Mvbench: A comprehensive multi-modal video understandingbenchmark.In:IEEEConf.Comput.Vis.PatternRecog.pp.22195– 22206 (2024)
2024
-
[25]
Li, X., Wang, Y., Yu, J., Zeng, X., Zhu, Y., Huang, H., Gao, J., Li, K., He, Y., Wang, C., Qiao, Y., Wang, Y., Wang, L.: Videochat-flash: Hierarchical compression for long-context video modeling. In: Int. Conf. Learn. Represent. (2026) LongEgoRefer 17
2026
-
[26]
In: IEEE Conf
Li, Z., Tao, R., Gavves, E., Snoek, C.G.M., Smeulders, A.W.M.: Tracking by natu- ral language specification. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 6495– 6503 (2017)
2017
-
[27]
Liang, S., Zhong, Y., Hu, Z.Y., Tao, Y., Wang, L.: Fine-grained spatiotemporal grounding on egocentric videos. In: Int. Conf. Comput. Vis. pp. 9385–9395 (2025)
2025
-
[28]
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Jiang, Q., Li, C., Yang, J., Su, H., et al.: Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In: Eur. Conf. Comput. Vis. pp. 38–55 (2024)
2024
-
[29]
In: IEEE Conf
Liu, Y., Liu, Y., Jiang, C., Lyu, K., Wan, W., Shen, H., Liang, B., Fu, Z., Wang, H., Yi,L.:HOI4D:A4degocentricdatasetforcategory-levelhuman-objectinteraction. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 21013–21022 (2022)
2022
-
[30]
Mangalam, K., Akshulakov, R., Malik, J.: Egoschema: A diagnostic benchmark for very long-form video language understanding. In: Adv. Neural Inform. Process. Syst. pp. 46212–46244 (2023)
2023
-
[31]
In: IEEE Conf
Mao, J., Huang, J., Toshev, A., Camburu, O., Yuille, A., Murphy, K.: Generation and comprehension of unambiguous object descriptions. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 11–20 (2016)
2016
-
[32]
Pan, X., Charron, N., Yang, Y., Peters, S., Whelan, T., Kong, C., Parkhi, O., New- combe, R., Ren, Y.C.: Aria digital twin: A new benchmark dataset for egocentric 3d machine perception. In: Int. Conf. Comput. Vis. pp. 20133–20143 (2023)
2023
-
[33]
In: IEEE Conf
Perrett, T., Darkhalil, A., Sinha, S., Emara, O., Pollard, S., Parida, K.K., Liu, K., Gatti, P., Bansal, S., Flanagan, K., Chalk, J., Zhu, Z., Guerrier, R., Abdelazim, F., Zhu, B., Moltisanti, D., Wray, M., Doughty, H., Damen, D.: HD-EPIC: A highly- detailed egocentric video dataset. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 23901–23913 (2025)
2025
-
[34]
Plummer, B.A., Wang, L., Cervantes, C.M., Caicedo, J.C., Hockenmaier, J., Lazeb- nik, S.: Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. In: Int. Conf. Comput. Vis. pp. 2641–2649 (2015)
2015
-
[35]
In: IEEE Conf
Ramakrishnan, S.K., Al-Halah, Z., Grauman, K.: Naq: Leveraging narrations as queries to supervise episodic memory. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 6694–6703 (2023)
2023
-
[36]
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al.: SAM 2: Segment anything in images and videos. In: Int. Conf. Learn. Represent. (2025)
2025
-
[37]
arXiv preprint arXiv:2405.08813 (2024)
Rawal, R., Saifullah, K., Basri, R., Jacobs, D., Somepalli, G., Goldstein, T.: Cinepile: A long video question answering dataset and benchmark. arXiv preprint arXiv:2405.08813 (2024)
-
[38]
In: IEEE Conf
Ren, S., Yao, L., Li, S., Sun, X., Hou, L.: Timechat: A time-sensitive multimodal large language model for long video understanding. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 14313–14323 (2024)
2024
-
[39]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Ren, T., Liu, S., Zeng, A., Lin, J., Li, K., Cao, H., Chen, J., Huang, X., Chen, Y., Yan, F., et al.: Grounded sam: Assembling open-world models for diverse visual tasks. arXiv preprint arXiv:2401.14159 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Rohrbach, A., Rohrbach, M., Hu, R., Darrell, T., Schiele, B.: Grounding of textual phrases in images by reconstruction. In: Eur. Conf. Comput. Vis. pp. 817–834 (2016)
2016
-
[41]
In: IEEE Conf
Sener, F., Chatterjee, D., Shelepov, D., He, K., Singhania, D., Wang, R., Yao, A.: Assembly101: A large-scale multi-view video dataset for understanding procedural activities. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 21096–21106 (2022) 18 S. Kato et al
2022
-
[42]
Seo, S., Lee, J.Y., Han, B.: Urvos: Unified referring video object segmentation network with a large-scale benchmark. In: Eur. Conf. Comput. Vis. pp. 208–223 (2020)
2020
-
[43]
In: ACM Int
Shang, X., Li, Y., Xiao, J., Ji, W., Chua, T.S.: Video visual relation detection via iterative inference. In: ACM Int. Conf. Multimedia. pp. 3654–3663 (2021)
2021
-
[44]
In: ACM Int
Shang, X., Ren, T., Guo, J., Zhang, H., Chua, T.S.: Video visual relation detection. In: ACM Int. Conf. Multimedia. pp. 1300–1308 (2017)
2017
-
[45]
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al.: OpenAI GPT-5 system card. arXiv preprint arXiv:2601.03267 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
In: IEEE Conf
Song, E., Chai, W., Wang, G., Zhang, Y., Zhou, H., Wu, F., Chi, H., Guo, X., Ye, T., Zhang, Y., Lu, Y., Hwang, J.N., Wang, G.: Moviechat: From dense token to sparse memory for long video understanding. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 18221–18232 (2024)
2024
-
[47]
In: AAAI
Tan,X.,Luo,Y.,Ye,Y.,Liu,F.,Cai,Z.:Allvb:All-in-onelongvideounderstanding benchmark. In: AAAI. pp. 7211–7219 (2025)
2025
-
[48]
Tang, H., Liang, K.J., Grauman, K., Feiszli, M., Wang, W.: Egotracks: A long-term egocentric visual object tracking dataset. In: Adv. Neural Inform. Process. Syst. pp. 75716–75739 (2023)
2023
-
[49]
IEEE Trans
Tang, Z., Liao, Y., Liu, S., Li, G., Jin, X., Jiang, H., Yu, Q., Xu, D.: Human- centric spatio-temporal video grounding with visual transformers. IEEE Trans. Circuit Syst. Video Technol.32(12), 8238–8249 (2021)
2021
-
[50]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al.: InternVL3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Wang,X.,Zhao,K.,Liu,F.,Wang,J.,Zhao,G.,Bao,X.,Zhu,Z.,Zhang,Y.,Wang, X.: Egovid-5m: A large-scale video-action dataset for egocentric video generation. In: Adv. Neural Inform. Process. Syst. (2025)
2025
-
[52]
Wang, X., Kwon, T., Rad, M., Pan, B., Chakraborty, I., Andrist, S., Bohus, D., Feniello, A., Tekin, B., Frujeri, F.V., Joshi, N., Pollefeys, M.: Holoassist: an ego- centric human interaction dataset for interactive ai assistants in the real world. In: Int. Conf. Comput. Vis. pp. 20270–20281 (2023)
2023
-
[53]
InternVideo2.5: Empowering Video MLLMs with Long and Rich Context Modeling
Wang, Y., Li, X., Yan, Z., He, Y., Yu, J., Zeng, X., Wang, C., Ma, C., Huang, H., Gao, J., Dou, M., Chen, K., Wang, W., Qiao, Y., Wang, Y., Wang, L.: Intern- Video2.5: Empowering video mllms with long and rich context modeling. arXiv preprint arXiv:2501.12386 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Wu, H., Li, D., Chen, B., Li, J.: Longvideobench: A benchmark for long-context interleaved video-language understanding. In: Adv. Neural Inform. Process. Syst. pp. 28828–28857 (2024)
2024
-
[55]
In: IEEE Conf
Xiao,J.,Shang,X.,Yao,A.,Chua,T.S.:Next-qa:Nextphaseofquestion-answering to explaining temporal actions. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 9777–9786 (2021)
2021
-
[56]
arXiv preprint arXiv:2506.03569 (2025)
Xiaomi LLM-Core Team: Mimo-vl technical report. arXiv preprint arXiv:2506.03569 (2025)
-
[57]
In: ACM Int
Xu, D., Zhao, Z., Xiao, J., Wu, F., Zhang, H., He, X., Zhuang, Y.: Video question answering via gradually refined attention over appearance and motion. In: ACM Int. Conf. Multimedia. pp. 1645–1653 (2017)
2017
-
[58]
Xu, N., Yang, L., Fan, Y., Yang, J., Yue, D., Liang, Y., Price, B., Cohen, S., Huang, T.S.: Youtube-vos: Sequence-to-sequence video object segmentation. In: Eur. Conf. Comput. Vis. pp. 585–601 (2018) LongEgoRefer 19
2018
-
[59]
Ye, J., Xu, H., Liu, H., Hu, A., Yan, M., Qian, Q., Zhang, J., Huang, F., Zhou, J.: mplug-owl3: Towards long image-sequence understanding in multi-modal large language models. In: Int. Conf. Learn. Represent. (2025)
2025
-
[60]
Yu, L., Poirson, P., Yang, S., Berg, A.C., Berg, T.L.: Modeling context in referring expressions. In: Eur. Conf. Comput. Vis. pp. 69–85 (2016)
2016
-
[61]
In: AAAI
Yu, Z., Xu, D., Yu, J., Yu, T., Zhao, Z., Zhuang, Y., Tao, D.: Activitynet-qa: A dataset for understanding complex web videos via question answering. In: AAAI. pp. 9127–9134 (2019)
2019
-
[62]
Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos
Yuan, H., Li, X., Zhang, T., Sun, Y., Huang, Z., Xu, S., Ji, S., Tong, Y., Qi, L., Feng, J., Yang, M.H.: Sa2va: Marrying sam2 with llava for dense grounded understanding of images and videos. arXiv preprint arXiv:2501.04001 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Zhang, B., Li, K., Cheng, Z., Hu, Z., Yuan, Y., Chen, G., Leng, S., Jiang, Y., Zhang, H., Li, X., et al.: Videollama 3: Frontier multimodal foundation models for image and video understanding. arXiv preprint arXiv:2501.13106 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Long Context Transfer from Language to Vision
Zhang, P., Zhang, K., Li, B., Zeng, G., Yang, J., Zhang, Y., Wang, Z., Tan, H., Li, C., Liu, Z.: Long context transfer from language to vision. arXiv preprint arXiv:2406.16852 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[65]
Zhang, Z., Zhao, Z., Zhao, Y., Wang, Q., Liu, H., Gao, L.: Where does it exist: Spatio-temporalvideogroundingformulti-formsentences.In:IEEEConf.Comput. Vis. Pattern Recog. pp. 10668–10677 (2020)
2020
-
[66]
In: IEEE Conf
Zhou, J., Shu, Y., Zhao, B., Wu, B., Liang, Z., Xiao, S., Qin, M., Yang, X., Xiong, Y., Zhang, B., Huang, T., Liu, Z.: Mlvu: Benchmarking multi-task long video un- derstanding. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 13691–13701 (2025)
2025
-
[67]
placed,” “lifted,
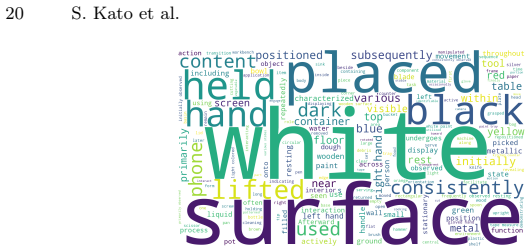
Zhou, W., Cao, K., Zheng, H., Liu, Y., Zheng, X., Liu, M., Kristensson, P.O., Mayol-Cuevas, W.W., Zhang, F., Lin, W., Shen, J.: X-LeBench: A benchmark for extremely long egocentric video understanding. In: Findings of the Association for Computational Linguistics: EMNLP 2025. pp. 15206–15222 (2025) 20 S. Kato et al. Fig.5:Word cloud visualization of refer...
2025
-
[68]
‘start_time‘: The timestamp (in MM:SS format) when the described event begins
-
[69]
IMPORTANT: Do not use or process any audio information from the video
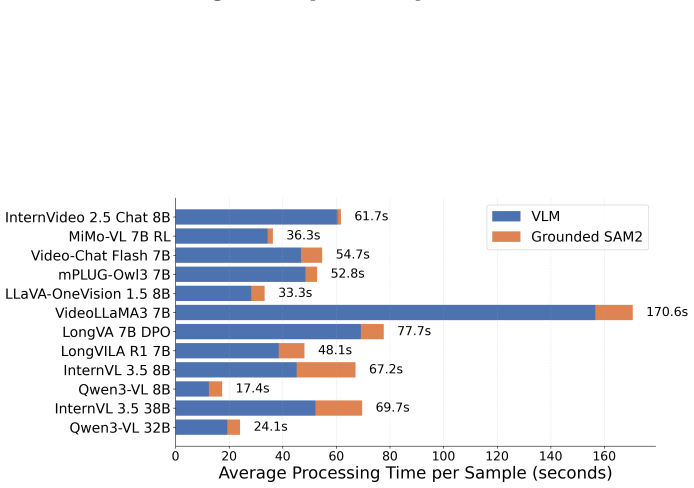
‘end_time‘: The timestamp (in MM:SS format) when the described event concludes. IMPORTANT: Do not use or process any audio information from the video. Only analyze the visual content (video frames/images) to identify temporal segments. Ignore all audio tracks completely. Fig.10:Prompt used in experiments. Fig.11:Time consumption over the baselines
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.