Unlocking Speech-Text Compositional Powers: Instruction-Following Speech Language Models without Instruction Tuning
Pith reviewed 2026-07-03 14:32 UTC · model grok-4.3
The pith
Adding the instruction-tuning weight difference from a text LLM to a speech-pretrained model creates an instruction-following speech language model without any speech instruction tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
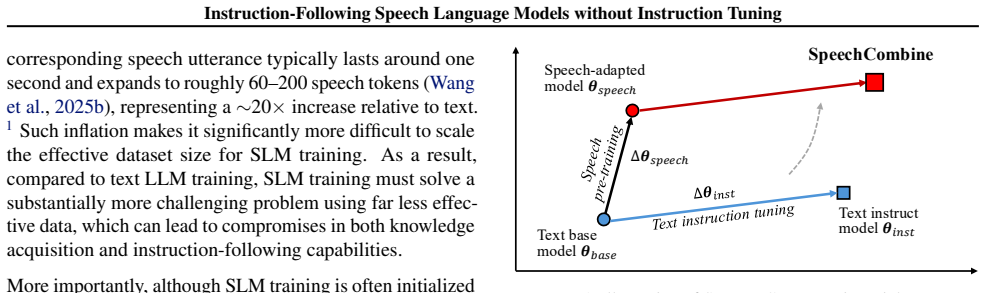
SpeechCombine obtains an instruction-following speech language model by performing one round of speech pre-training on a text LLM base model and then directly adding the weight difference between the instruction-tuned and base versions of that text LLM, without any further speech-specific instruction tuning.
What carries the argument
The weight difference obtained from instruction tuning a text LLM, which is added to the speech-adapted model to transfer instruction-following capabilities.
If this is right
- Instruction-following behavior transfers to the speech domain from the text domain via this addition.
- The original text LLM knowledge and capabilities are preserved in the resulting speech model.
- SLM training can avoid reliance on massive speech instruction datasets.
- Only a single round of speech pre-training on 30k hours is needed instead of extensive instruction tuning data synthesis.
Where Pith is reading between the lines
- Similar weight-delta transfer might work for other modalities like vision if a base model is adapted continuously.
- This suggests that instruction following may be a property largely independent of the input modality once the model has the right representations.
- Future work could test if scaling the speech pre-training data changes how well the delta transfers.
Load-bearing premise
The weight difference from text instruction tuning can be added directly to a speech-adapted model to produce the desired behavior without needing speech-specific adjustments or further training.
What would settle it
If the resulting speech model fails to follow instructions on speech inputs while still performing well on text, or if it loses text capabilities after the addition.
Figures

read the original abstract
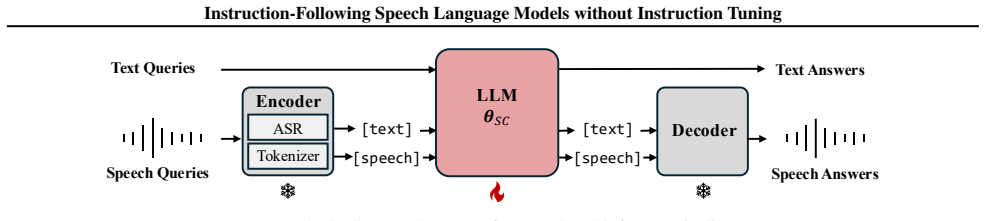
Instruction tuning for speech language models (SLMs) is substantially more challenging than for text-based large language models (LLMs), as it requires learning a new modality and a wide range of speech-specific instructions in addition to those supported by text LLMs. Existing SLM training approaches largely replicate the text LLM training paradigm by synthesizing large-scale speech pre-training and instruction-tuning datasets. However, this strategy is difficult to scale, since speech sequences are significantly longer than text sequences. In this paper, we propose SpeechCombine, an instruction-following speech language model trained without any instruction tuning, using only a single round of speech pre-training on 30k hours of data. Starting from a text LLM base model, we perform continuous pre-training on speech utterances to obtain a speech-adapted model, and then directly combine its weights with the weight difference between the instruction-tuned and base versions of the text LLM. Our results show that this simple combination strategy not only preserves the knowledge and capabilities of the original text LLM, but also effectively transfers them to the speech domain. These findings suggest a new direction for SLM training that avoids reliance on massive speech data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SpeechCombine, a method to obtain instruction-following speech language models without any speech-specific instruction tuning. The approach starts from a text LLM, performs a single round of continuous pre-training on 30k hours of speech data to produce a speech-adapted model, and then adds the weight difference between an instruction-tuned text LLM and its base version directly to the speech-adapted weights. The central claim is that this operation preserves the original text LLM's knowledge and capabilities while transferring instruction-following behavior to the speech domain.
Significance. If the central claim is substantiated by rigorous experiments, the result would be significant because it offers a data-efficient alternative to the standard SLM pipeline that requires synthesizing large-scale speech instruction datasets, which are difficult to scale given longer sequence lengths. The method exploits existing text instruction-tuned models via a direct weight-space operation and avoids additional speech instruction tuning rounds.
major comments (2)
- [Abstract and Experimental Results section] Abstract and Experimental Results section: the claim that 'our results show that this simple combination strategy not only preserves the knowledge and capabilities of the original text LLM, but also effectively transfers them to the speech domain' is presented without any quantitative metrics, baselines, ablation studies, or error analysis, which is load-bearing for the central claim of effective transfer and preservation.
- [Method section (weight combination step)] Method section (weight combination step): the direct addition of Δ = (text-instruct − text-base) to the speech-adapted model obtained after continuous pre-training assumes that the text-derived delta remains effective and correctly scaled on speech token/embedding paths, but no derivation, scaling analysis, or ablation is provided to justify modality invariance after the speech adaptation shifts parameters.
minor comments (1)
- [Abstract] The abstract would be strengthened by a brief mention of the evaluation tasks or metrics used to support the preservation and transfer claims.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each major comment point by point below. Revisions have been made to strengthen the presentation of results and the justification of the method.
read point-by-point responses
-
Referee: [Abstract and Experimental Results section] Abstract and Experimental Results section: the claim that 'our results show that this simple combination strategy not only preserves the knowledge and capabilities of the original text LLM, but also effectively transfers them to the speech domain' is presented without any quantitative metrics, baselines, ablation studies, or error analysis, which is load-bearing for the central claim of effective transfer and preservation.
Authors: We agree that the abstract and experimental results would be strengthened by explicit quantitative support. The revised manuscript updates the abstract to reference key metrics from our evaluations on speech instruction-following benchmarks. The Experimental Results section has been expanded with baseline comparisons, ablation studies on the combination operation, and error analysis to directly substantiate the claims of preservation and transfer. revision: yes
-
Referee: [Method section (weight combination step)] Method section (weight combination step): the direct addition of Δ = (text-instruct − text-base) to the speech-adapted model obtained after continuous pre-training assumes that the text-derived delta remains effective and correctly scaled on speech token/embedding paths, but no derivation, scaling analysis, or ablation is provided to justify modality invariance after the speech adaptation shifts parameters.
Authors: The referee is correct that the original method section provides limited justification for the cross-modal transfer of the delta. We have revised the Method section to include an empirical scaling analysis, ablation results demonstrating the effect of the combination on speech-adapted parameters, and a discussion of the underlying assumption that the shared transformer backbone permits approximate transfer after speech pre-training. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper proposes an empirical method consisting of continuous pre-training on 30k hours of speech data followed by direct addition of a text-derived instruction weight delta. No equations, fitted parameters, or self-citations are presented that reduce the central construction or its claimed transferability to the inputs by definition. The result is asserted via external experimental validation rather than any self-referential derivation, making the approach self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The instruction-tuning weight difference learned on text can be linearly combined with a speech-pretrained model to confer equivalent instruction-following capability in the speech modality.
Reference graph
Works this paper leans on
-
[1]
The Emotional Voices Database: Towards Controlling the Emotion Dimension in Voice Generation Systems
Adigwe, A., Tits, N., Haddad, K. E., Ostadabbas, S., and Du- toit, T. The emotional voices database: Towards control- ling the emotion dimension in voice generation systems. arXiv preprint arXiv:1806.09514,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
gpt-oss-120b & gpt-oss-20b Model Card
Agarwal, S., Ahmad, L., Ai, J., Altman, S., Applebaum, A., Arbus, E., Arora, R. K., Bai, Y ., Baker, B., Bao, H., et al. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Chen, D., Zhang, X., Wang, Y ., Dai, K., Ma, L., and Wu, Z. Flexivoice: Enabling flexible style control in zero- shot tts with natural language instructions.arXiv preprint arXiv:2601.04656,
-
[4]
Fun-audio-chat technical report,
Chen, Q., Cheng, L., Deng, C., Li, X., Liu, J., Tan, C.-H., Wang, W., Xu, J., Ye, J., Zhang, Q., et al. Fun-audio-chat technical report.arXiv preprint arXiv:2512.20156,
-
[5]
VoiceBench: Benchmarking LLM-Based Voice Assistants
Chen, Y ., Yue, X., Zhang, C., Gao, X., Tan, R. T., and Li, H. V oicebench: Benchmarking llm-based voice assistants. arXiv preprint arXiv:2410.17196,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Dai, Z., Chen, Y ., Xu, J., Xie, L., Wang, Y ., Yang, Z., Bai, B., Gao, Y ., Zhou, W., Zhao, W., et al. Deep dub- bing: End-to-end auto-audiobook system with text-to- timbre and context-aware instruct-tts.arXiv preprint arXiv:2509.15845,
-
[7]
Emphassess: a prosodic benchmark on assessing empha- sis transfer in speech-to-speech models
de Seyssel, M., D’Avirro, A., Williams, A., and Dupoux, E. Emphassess: a prosodic benchmark on assessing empha- sis transfer in speech-to-speech models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 495–507,
2024
-
[8]
Moshi: a speech-text foundation model for real-time dialogue
D´efossez, A., Mazar ´e, L., Orsini, M., Royer, A., P ´erez, P., J ´egou, H., Grave, E., and Zeghidour, N. Moshi: a speech-text foundation model for real-time dialogue. arXiv preprint arXiv:2410.00037,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Ding, D., Ju, Z., Leng, Y ., Liu, S., Liu, T., Shang, Z., Shen, K., Song, W., Tan, X., Tang, H., et al. Kimi-audio techni- cal report.arXiv preprint arXiv:2504.18425,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Llama-omni: Seamless speech interaction with large lan- guage models
Fang, Q., Guo, S., Zhou, Y ., Ma, Z., Zhang, S., and Feng, Y . Llama-omni: Seamless speech interaction with large lan- guage models. InInternational Conference on Learning Representations, volume 2025, pp. 57607–57624,
2025
-
[11]
Audiochatllama: Towards general-purpose speech abilities for llms
Fathullah, Y ., Wu, C., Lakomkin, E., Li, K., Jia, J., Shang- guan, Y ., Mahadeokar, J., Kalinli, O., Fuegen, C., and Seltzer, M. Audiochatllama: Towards general-purpose speech abilities for llms. InProceedings of the 2024 Conference of the North American Chapter of the Associ- ation for Computational Linguistics: Human Language Technologies (Volume 1: Lo...
2024
-
[12]
Feng, T., Lee, J., Xu, A., Lee, Y ., Lertpetchpun, T., Shi, X., Wang, H., Thebaud, T., Moro-Velazquez, L., Byrd, D., et al. V ox-profile: A speech foundation model benchmark for characterizing diverse speaker and speech traits.arXiv preprint arXiv:2505.14648,
-
[13]
Osum-echat: Enhancing end-to-end empathetic spoken chatbot via understanding-driven spoken dialogue,
Geng, X., Shao, Q., Xue, H., Wang, S., Xie, H., Guo, Z., Zhao, Y ., Li, G., Tian, W., Wang, C., et al. Osum-echat: Enhancing end-to-end empathetic spoken chatbot via understanding-driven spoken dialogue.arXiv preprint arXiv:2508.09600,
-
[14]
N., Mallidi, H., Huang, J.-H., Bellur, A., Chandak, C., Maruf, M., and Ravichandran, V
He, X., Ray, S. N., Mallidi, H., Huang, J.-H., Bellur, A., Chandak, C., Maruf, M., and Ravichandran, V . Continuous-token diffusion for speaker-referenced tts in multimodal llms.arXiv preprint arXiv:2510.12995,
-
[15]
Editing Models with Task Arithmetic
10 Instruction-Following Speech Language Models without Instruction Tuning Ilharco, G., Ribeiro, M. T., Wortsman, M., Gururangan, S., Schmidt, L., Hajishirzi, H., and Farhadi, A. Editing mod- els with task arithmetic.arXiv preprint arXiv:2212.04089,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Libri-light: A benchmark for asr with limited or no supervision
Kahn, J., Riviere, M., Zheng, W., Kharitonov, E., Xu, Q., Mazar´e, P.-E., Karadayi, J., Liptchinsky, V ., Collobert, R., Fuegen, C., et al. Libri-light: A benchmark for asr with limited or no supervision. InICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 7669–7673. IEEE,
2020
-
[17]
Kang, W., Jia, J., Wu, C., Zhou, W., Lakomkin, E., Gaur, Y ., Sari, L., Kim, S., Li, K., Mahadeokar, J., et al. Frozen large language models can perceive paralinguistic aspects of speech.arXiv preprint arXiv:2410.01162,
-
[18]
Continuous speech tokenizer in text to speech
Li, Y ., Xie, R., Sun, X., Cheng, Y ., and Kang, Z. Continuous speech tokenizer in text to speech. InFindings of the Association for Computational Linguistics: NAACL 2025, pp. 3341–3347,
2025
-
[19]
Liang, R.-W., Hsu, C.-T., Yu, C.-H., Agrawal, S., Huang, S.-C., Chen, S.-T., Huang, K.-H., and Sun, S.-H. Adap- tive helpfulness-harmlessness alignment with preference vectors.arXiv preprint arXiv:2504.20106,
-
[20]
Parastyletts: Toward efficient and robust paralinguistic style control for expressive text-to-speech generation
Lou, H., Paik, H.-Y ., Hu, W., and Yao, L. Parastyletts: Toward efficient and robust paralinguistic style control for expressive text-to-speech generation. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, pp. 1979–1988,
1979
-
[21]
H., Huang, S.-F., Yang, C.-K., Yu, C.-E., Chen, C.-W., Chen, W.-C., Huang, C.-y., et al
Lu, K.-H., Chen, Z., Fu, S.-W., Yang, C.-H. H., Huang, S.-F., Yang, C.-K., Yu, C.-E., Chen, C.-W., Chen, W.-C., Huang, C.-y., et al. Desta2. 5-audio: Toward general- purpose large audio language model with self-generated cross-modal alignment.arXiv preprint arXiv:2507.02768,
-
[22]
Nguyen, T. A., Hsu, W.-N., d’Avirro, A., Shi, B., Gat, I., Fazel-Zarani, M., Remez, T., Copet, J., Synnaeve, G., Hassid, M., et al. Expresso: A benchmark and analysis of discrete expressive speech resynthesis.arXiv preprint arXiv:2308.05725,
-
[23]
Pai, T.-M., Wang, J.-I., Lu, L.-C., Sun, S.-H., Lee, H.-Y ., and Chang, K.-W. Billy: Steering large language models via merging persona vectors for creative generation.arXiv preprint arXiv:2510.10157,
-
[24]
Qian, K., Fan, X., Ni, J., Shechtman, S., Hasegawa-Johnson, M., Gan, C., and Zhang, Y
URL https://doi.org/ 10.5683/SP2/E8H2MF. Qian, K., Fan, X., Ni, J., Shechtman, S., Hasegawa-Johnson, M., Gan, C., and Zhang, Y . Prosodylm: Uncovering the emerging prosody processing capabilities in speech lan- guage models.arXiv preprint arXiv:2507.20091,
-
[25]
Ov-instructtts: Towards open-vocabulary instruct text-to-speech.arXiv preprint arXiv:2601.01459,
Ren, Y ., Yi, J., Tao, J., Sun, H., Wen, Z., Gu, H., Xu, L., and Bai, Y . Ov-instructtts: Towards open-vocabulary instruct text-to-speech.arXiv preprint arXiv:2601.01459,
-
[26]
Shao, Y ., Liu, W., Li, J., Wang, T., Wei, K., Yu, M., and Yu, D. Azeros: Extending llm to speech with self-generated instruction-free tuning.arXiv preprint arXiv:2601.06086,
-
[27]
K., Arnab, A., Iscen, A., Cas- tro, P
Sokar, G., Dziugaite, G. K., Arnab, A., Iscen, A., Cas- tro, P. S., and Schmid, C. Continual learning in vision- language models via aligned model merging.arXiv preprint arXiv:2506.03189,
-
[28]
Wang, X., Li, Y ., Fu, C., Shen, Y ., Xie, L., Li, K., Sun, X., and Ma, L. Freeze-omni: A smart and low latency speech-to-speech dialogue model with frozen llm.arXiv preprint arXiv:2411.00774,
-
[29]
Wang, Y ., Chen, D., Zhang, X., Zhang, J., Li, J., and Wu, Z. Tadicodec: Text-aware diffusion speech tok- enizer for speech language modeling.arXiv preprint arXiv:2508.16790, 2025b. Wei, H., Cao, X., Dan, T., and Chen, Y . Rmvpe: A robust model for vocal pitch estimation in polyphonic music. arXiv preprint arXiv:2306.15412,
-
[30]
Wu, B., Yan, C., Hu, C., Yi, C., Feng, C., Tian, F., Shen, F., Yu, G., Zhang, H., Li, J., et al. Step-audio 2 technical report.arXiv preprint arXiv:2507.16632,
work page internal anchor Pith review Pith/arXiv arXiv
- [31]
-
[32]
Xu, J., Guo, Z., He, J., Hu, H., He, T., Bai, S., Chen, K., Wang, J., Fan, Y ., Dang, K., Zhang, B., Wang, X., Chu, Y ., and Lin, J. Qwen2.5-omni technical report.arXiv preprint arXiv:2503.20215, 2025a. Xu, J., Guo, Z., Hu, H., Chu, Y ., Wang, X., He, J., Wang, Y ., Shi, X., He, T., Zhu, X., et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.177...
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025a. Yang, S.-w., Kim, B., Huang, K.-P., Tang, Q., Phan, H., Lu, B.-R., Sundar, H., Ghosh, S., Lee, H.-y., Kao, C.-C., et al. Generative audio language modeling with continuous- valued tokens and m...
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Yu, Z. and Ananiadou, S. Locate-then-merge: Neuron-level parameter fusion for mitigating catastrophic forgetting in multimodal llms.arXiv preprint arXiv:2505.16703,
-
[35]
GLM-4-Voice: Towards Intelligent and Human-Like End-to-End Spoken Chatbot
Zeng, A., Du, Z., Liu, M., Wang, K., Jiang, S., Zhao, L., Dong, Y ., and Tang, J. Glm-4-voice: Towards intelli- gent and human-like end-to-end spoken chatbot.arXiv preprint arXiv:2412.02612,
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Speechgpt: Empowering large language models with intrinsic cross-modal conversational abili- ties
Zhang, D., Li, S., Zhang, X., Zhan, J., Wang, P., Zhou, Y ., and Qiu, X. Speechgpt: Empowering large language models with intrinsic cross-modal conversational abili- ties. InFindings of the Association for Computational Linguistics: EMNLP 2023, pp. 15757–15773,
2023
-
[37]
Zhao, X., Xiang, H., Ye, S., Li, S., Tian, Z., Chen, G., Ding, K., and Wan, G. Longcat-audio-codec: An audio tokenizer and detokenizer solution designed for speech large language models, 2025.URL https://arxiv. org/abs/2510.15227. Zhao, X., Xiang, H., Ye, S., Li, S., Tian, Z., Chen, G., Ding, K., and Wan, G. Longcat-audio-codec: An audio tokenizer and det...
-
[38]
How are you?
12 Instruction-Following Speech Language Models without Instruction Tuning A. Additional Algorithm Details A.1. Speech Pre-training Special Tokens.Certain special tokens play a crucial role during instruction-following, but they do not appear in the data for the speech continuous pre-training. As a result, SPEECHCOMBINEwill forget the ability to output th...
2023
-
[39]
The correct answer is:
A complete explanation of the tokenization scheme can be found in Qian et al. (2025). A.4. Inference System Prompt.Since our method is designed for building an audio assistant, a system prompt will help the text-based LLM better understand its role and task. We therefore adopt the following system prompt: You are a helpful assistant. Always follow the use...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.