AGVBench: A Reliability-Oriented Benchmark of Data Augmentation for Vein Recognition
Pith reviewed 2026-07-03 15:41 UTC · model grok-4.3
The pith
Mixing data augmentations improve vein recognition but increase vulnerability to adversarial attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
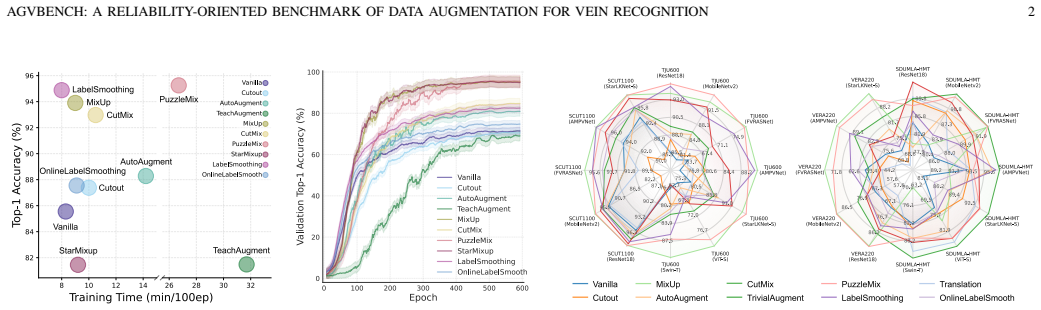
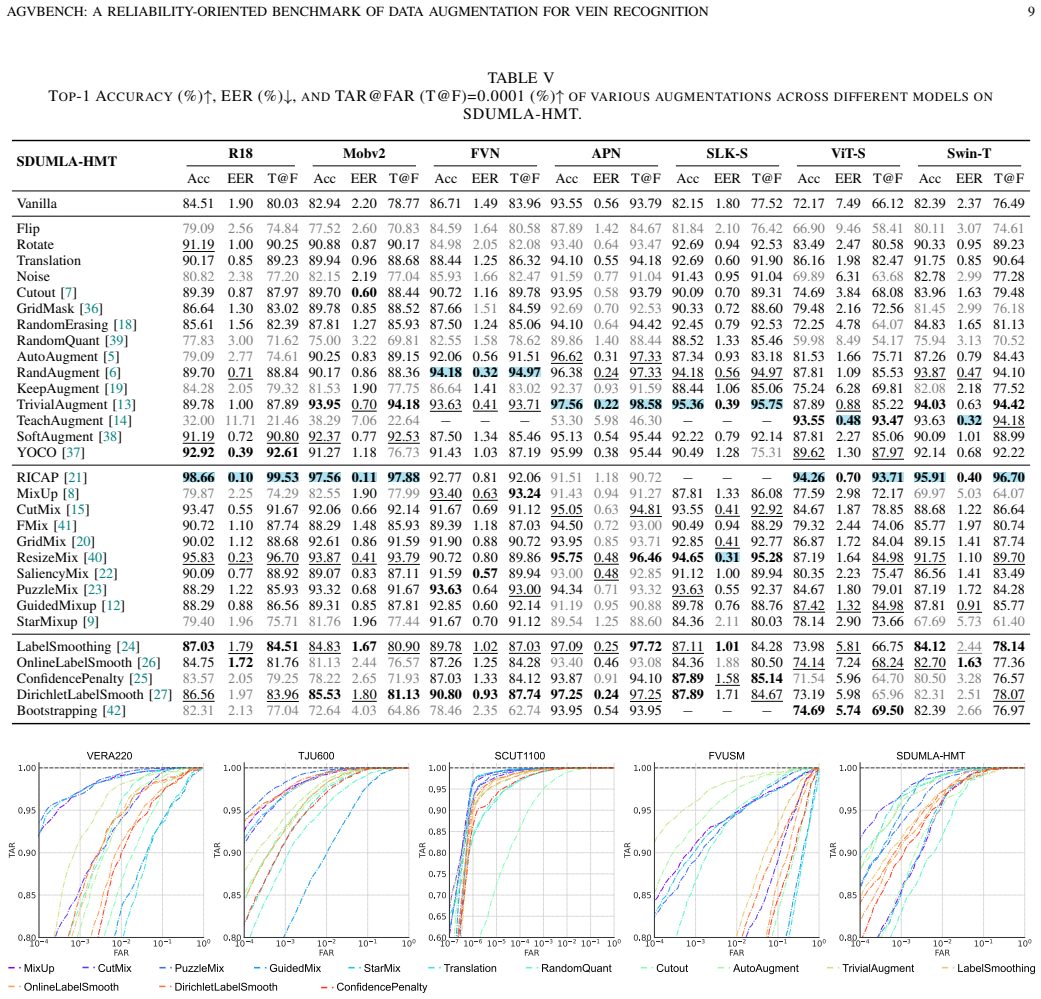
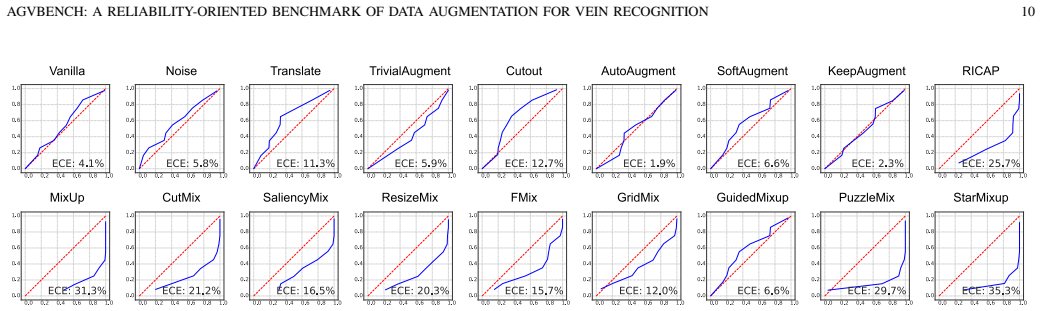
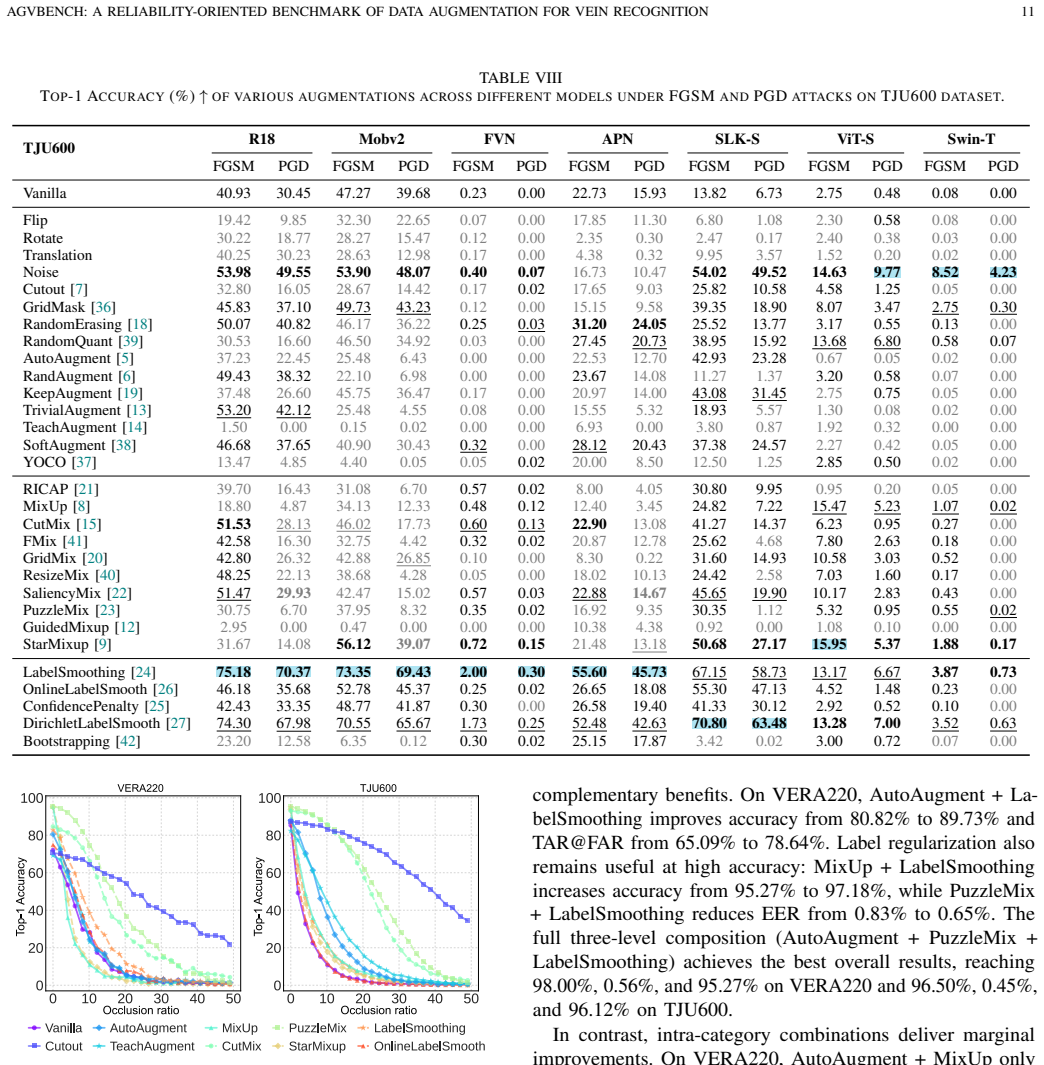
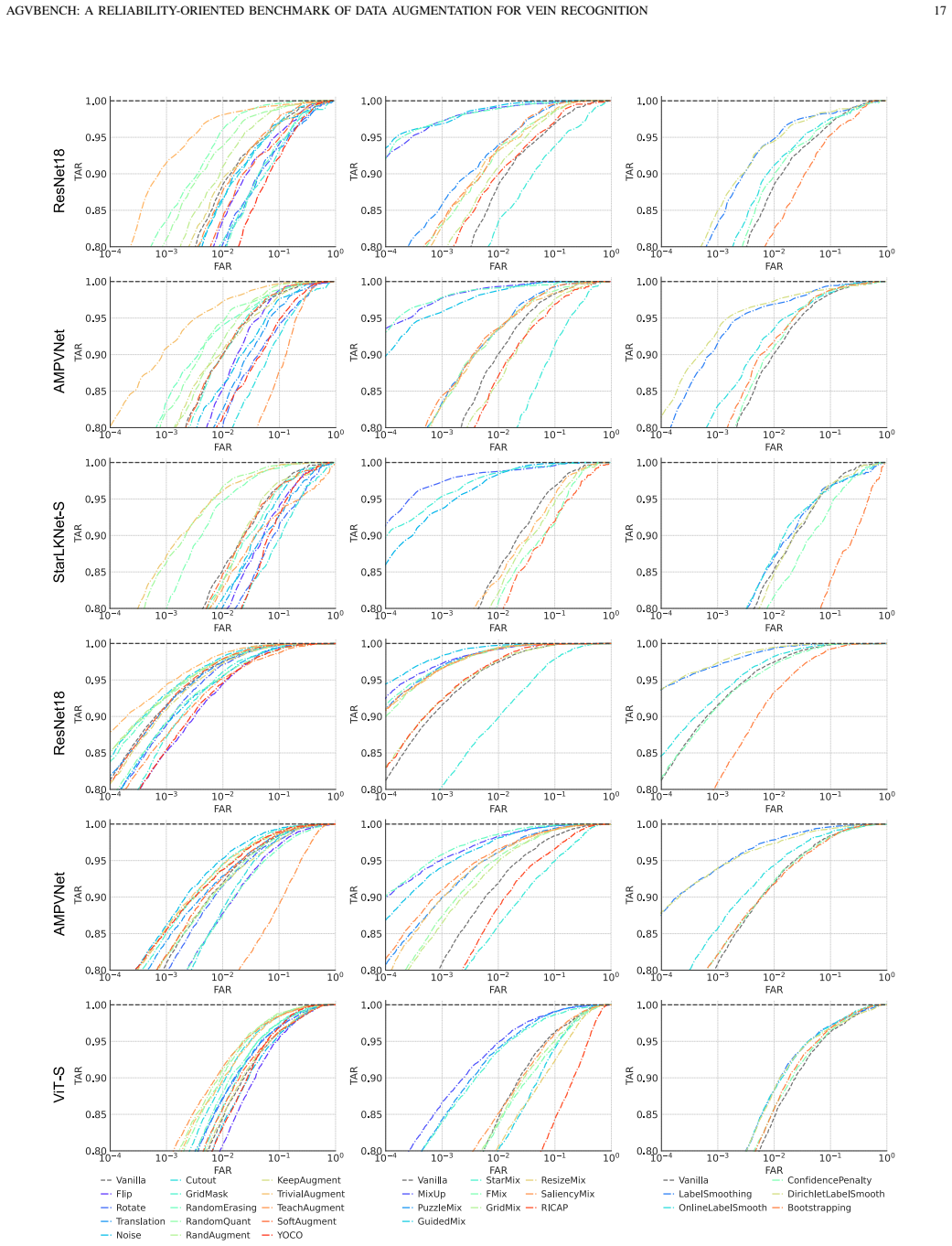
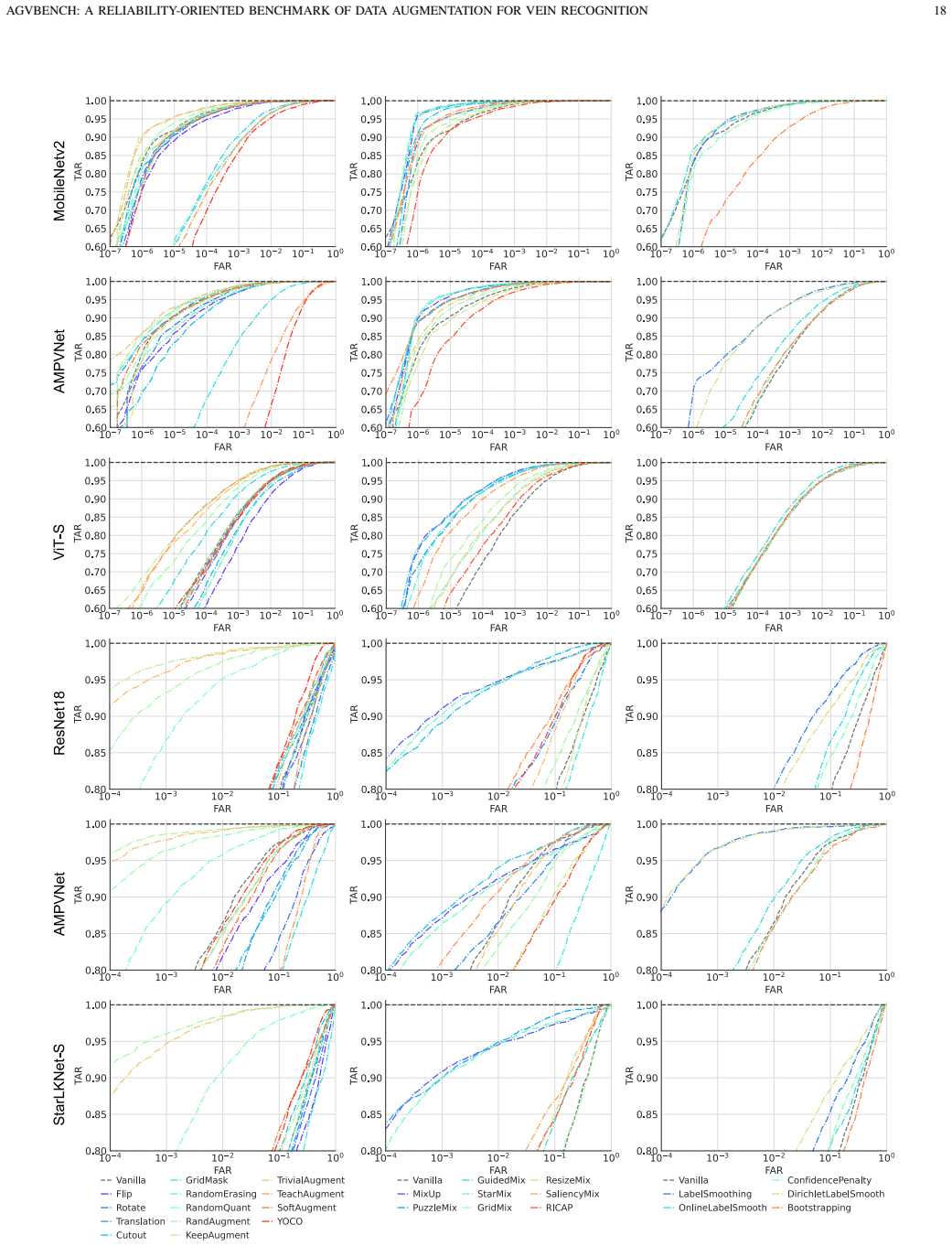
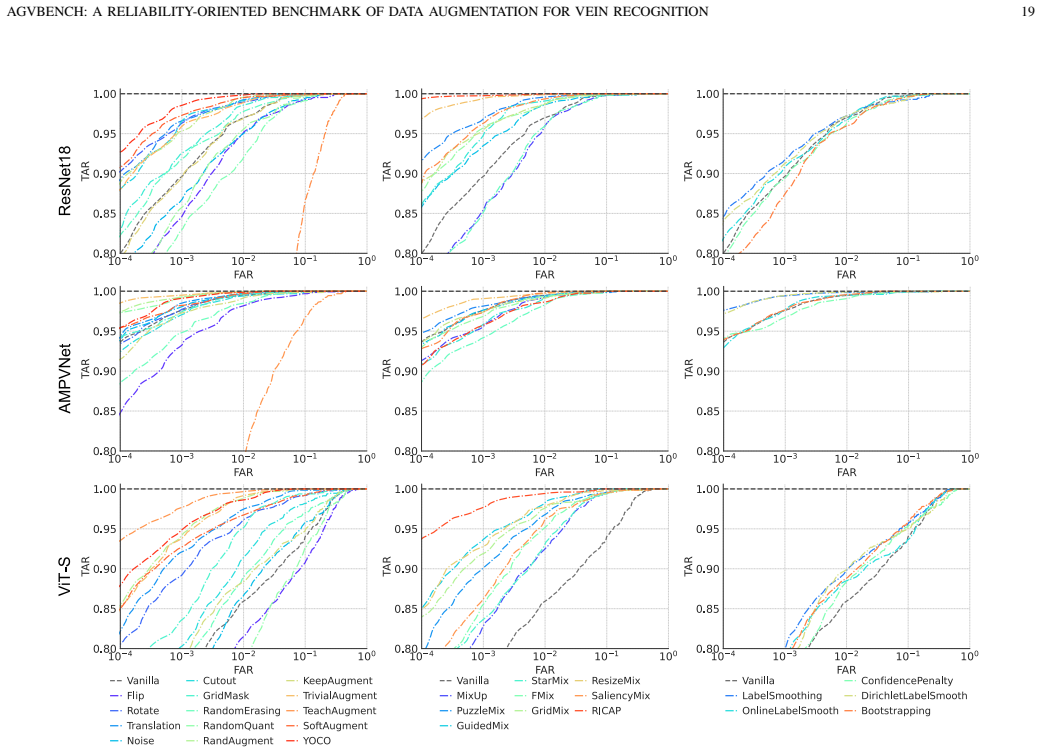
The central claim is that multi-image mixing methods such as MixUp, PuzzleMix, and StarMixup deliver the strongest recognition performance on palm- and finger-vein data, yet they are typically poorly calibrated and vulnerable to adversarial perturbations, which reveals an inconsistency between clean accuracy and adversarial security that makes accuracy-centric evaluation insufficient for biometric augmentation.
What carries the argument
AGVBench, the benchmark that applies thirty augmentation strategies to five public vein datasets across seven backbone architectures while measuring recognition accuracy, calibration quality, and adversarial robustness.
If this is right
- Multi-image mixing methods generally provide the strongest recognition performance.
- These methods are often poorly calibrated.
- They are vulnerable to adversarial perturbations.
- Severe geometric transformations frequently degrade recognition performance.
- Augmentation effectiveness varies across palm and finger vein datasets.
Where Pith is reading between the lines
- Designers of vein recognition systems should consider adversarial security when choosing augmentations rather than accuracy alone.
- The accuracy-security inconsistency may apply to other recognition tasks that depend on fine topological features.
- The evaluation protocols could be extended to additional biometric modalities to test the generality of the findings.
Load-bearing premise
The five public palm- and finger-vein datasets together with the seven backbone architectures are sufficiently representative to support general conclusions about augmentation effectiveness and the accuracy-security trade-off across vein recognition.
What would settle it
Running the same evaluation protocol on new independent vein datasets where the top mixing methods achieve high accuracy without increased adversarial vulnerability or calibration problems would falsify the claimed inconsistency.
Figures

read the original abstract
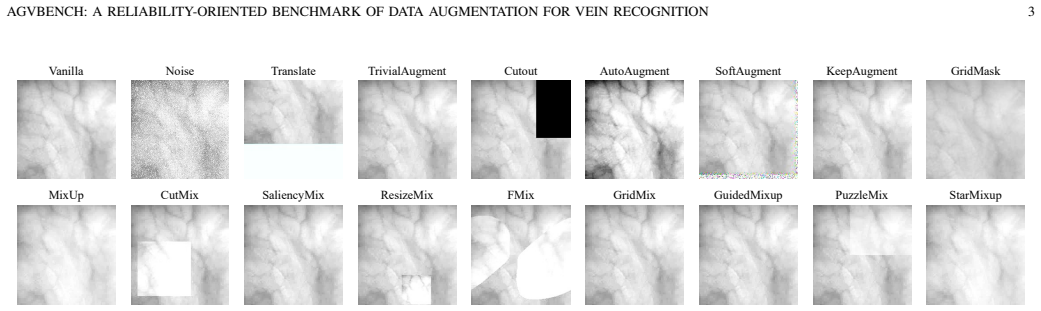
Vein recognition is a secure biometric technology often constrained by limited annotated data and imaging variations. While data augmentation mitigates this, strategies designed for natural images may disrupt the fine-grained topology and textures essential for identity discrimination. We present AGVBench, which evaluates 30 representative augmentation strategies on five public palm- and finger-vein datasets with seven backbone architectures, covering classic CNNs, vision transformers, and vein-specific recognition models. Our results show that multi-image mixing methods (e.g., MixUp, PuzzleMix, StarMixup) generally provide the strongest recognition performance. However, they are often poorly calibrated and vulnerable to adversarial perturbations, revealing a clear inconsistency between clean accuracy and adversarial security. We also find that severe geometric transformations frequently degrade recognition, which is potentially due to feature misalignment or spatial cropping, and that augmentation effectiveness varies across palm and finger vein datasets. These findings prove that accuracy-centric evaluation is insufficient for biometric augmentation. AGVBench provides standardized protocols to support reproducible research and guide the design of reliable, secure, and robust vein recognition systems. Our codebase is available at https://github.com/Advance-VeinTech-Innovators/AGVBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AGVBench, an empirical benchmark evaluating 30 data augmentation strategies across five public palm- and finger-vein datasets and seven backbone architectures (CNNs, vision transformers, and vein-specific models). It reports that multi-image mixing methods (MixUp, PuzzleMix, StarMixup) achieve the highest clean recognition accuracy but exhibit poor calibration and high vulnerability to adversarial perturbations, demonstrating an inconsistency between clean accuracy and adversarial security. Additional findings include degradation from severe geometric transformations and variation in augmentation effectiveness between palm and finger vein data. The work provides standardized protocols and open code to support reliability-oriented evaluation in vein recognition.
Significance. If the empirical results hold under broader conditions, the benchmark supplies concrete evidence that accuracy-centric augmentation evaluation is insufficient for biometric systems and identifies a systematic accuracy-security trade-off in mixing-based methods. The release of reproducible code and protocols is a clear strength that enables follow-on work.
major comments (2)
- [§3] §3 (Datasets and Models): The central claim of a 'clear inconsistency between clean accuracy and adversarial security' for multi-image mixing methods rests on results from only five public datasets and seven backbones. The manuscript does not demonstrate that these collections adequately sample the range of sensor resolutions, cross-session variability, and demographic factors typical in vein imaging; if they under-represent low-contrast or cross-session regimes, the observed trade-off may not generalize.
- [§4.3] §4.3 (Adversarial Evaluation): The vulnerability findings for mixing methods are load-bearing for the headline inconsistency result, yet the text provides no explicit values for attack parameters (e.g., PGD step size, number of iterations, or ε bounds) or confirmation that the same attack configuration was applied uniformly across all augmentation strategies and models.
minor comments (2)
- [Abstract] The abstract states that 'severe geometric transformations frequently degrade recognition' but does not quantify the degradation (e.g., accuracy drop percentages) or link it to specific tables/figures.
- [Tables] Table captions and axis labels should explicitly state the number of runs or random seeds used to compute reported means and standard deviations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below and note the planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Datasets and Models): The central claim of a 'clear inconsistency between clean accuracy and adversarial security' for multi-image mixing methods rests on results from only five public datasets and seven backbones. The manuscript does not demonstrate that these collections adequately sample the range of sensor resolutions, cross-session variability, and demographic factors typical in vein imaging; if they under-represent low-contrast or cross-session regimes, the observed trade-off may not generalize.
Authors: We agree that the five public datasets used represent the standard, reproducible collections available in the literature rather than a comprehensive sampling of all possible vein imaging conditions. While these datasets span palm and finger veins with documented variations in resolution and acquisition, they do not explicitly cover the full range of demographic factors or cross-session variability. We will add a dedicated Limitations subsection to the discussion that states this scope explicitly and notes that the released codebase is designed to support extension to new datasets. This revision will qualify the generalizability of the observed accuracy-security trade-off without altering the reported empirical results. revision: partial
-
Referee: [§4.3] §4.3 (Adversarial Evaluation): The vulnerability findings for mixing methods are load-bearing for the headline inconsistency result, yet the text provides no explicit values for attack parameters (e.g., PGD step size, number of iterations, or ε bounds) or confirmation that the same attack configuration was applied uniformly across all augmentation strategies and models.
Authors: We thank the referee for identifying this omission. The adversarial evaluations used PGD with ε = 0.03, step size 0.01, and 20 iterations, applied uniformly to every augmentation strategy and backbone. We will revise §4.3 to state these parameters explicitly and add a sentence confirming uniform application across all experiments. revision: yes
Circularity Check
Pure empirical benchmark with no derivations or self-referential predictions
full rationale
The paper conducts a direct empirical evaluation of 30 augmentation strategies across five public datasets and seven standard backbones, reporting observed accuracy, calibration, and adversarial robustness metrics. No equations, fitted parameters, uniqueness theorems, or ansatzes are introduced; all claims reduce to tabulated experimental outcomes on external data rather than any internal construction or self-citation chain. This is the expected non-circular outcome for a benchmark study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The five public palm- and finger-vein datasets are representative of real-world vein recognition conditions.
Reference graph
Works this paper leans on
-
[1]
El-Yacoubi, and Dexing Zhong
Huafeng Qin, Yuming Fu, Jing Chen, Qun Song, Yantao Li, Mounim A. El-Yacoubi, and Dexing Zhong. Wtxgrn: Wavelet transform-based extended gated recurrent network for palm vein recognition.IEEE Transactions on Information Forensics and Security, 20:7911–7926, 2025
2025
-
[2]
Palm vein recognition under unconstrained and weak-cooperative con- ditions.IEEE Transactions on Information Forensics and Security, 19:4601–4614, 2024
Dacan Luo, Yitao Qiao, Di Xie, Shifeng Zhang, and Wenxiong Kang. Palm vein recognition under unconstrained and weak-cooperative con- ditions.IEEE Transactions on Information Forensics and Security, 19:4601–4614, 2024
2024
-
[3]
Multi-scale and multi-direction gan for cnn-based single palm-vein identification.IEEE Transactions on Information Forensics and Security, 16:2652–2666, 2021
Huafeng Qin, Mounim A El-Yacoubi, Yantao Li, and Chongwen Liu. Multi-scale and multi-direction gan for cnn-based single palm-vein identification.IEEE Transactions on Information Forensics and Security, 16:2652–2666, 2021
2021
-
[4]
A new filter generation method in pcanet for finger vein recognition.IEEE Access, 7:132966–132978, 2019
Nurul Maisarah Kamaruddin and Bakhtiar Affendi Rosdi. A new filter generation method in pcanet for finger vein recognition.IEEE Access, 7:132966–132978, 2019
2019
-
[5]
Autoaugment: Learning augmentation strategies from data
Ekin D Cubuk, Barret Zoph, Dandelion Mane, Vijay Vasudevan, and Quoc V Le. Autoaugment: Learning augmentation strategies from data. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 113–123, 2019
2019
-
[6]
Randaugment: Practical automated data augmentation with a reduced search space
Ekin D Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V Le. Randaugment: Practical automated data augmentation with a reduced search space. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 702–703, 2020
2020
-
[7]
Improved Regularization of Convolutional Neural Networks with Cutout
Terrance DeVries and Graham W Taylor. Improved regularization of con- volutional neural networks with cutout.arXiv preprint arXiv:1708.04552, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[8]
mixup: Beyond empirical risk minimization
Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization. InInternational Conference on Learning Representations, 2018
2018
-
[9]
Starmixup: A more suitable mixup method for palm-vein identification
Xin Jin, Hongyu Zhu, Simon Fong, João Alexandre Lobo Marques, Huafeng Qin, and Yun Jiang. Starmixup: A more suitable mixup method for palm-vein identification. In2025 7th International Symposium on Computational and Business Intelligence (ISCBI), pages 83–87. IEEE, 2025
2025
-
[10]
Automix: Unveiling the power of mixup for stronger classifiers
Zicheng Liu, Siyuan Li, Di Wu, Zihan Liu, Zhiyuan Chen, Lirong Wu, and Stan Z Li. Automix: Unveiling the power of mixup for stronger classifiers. InEuropean Conference on Computer Vision, pages 441–458. Springer, 2022
2022
-
[11]
Adversarial automixup
Huafeng Qin, Xin Jin, Yun Jiang, Mounîm El-Yacoubi, and Xinbo Gao. Adversarial automixup. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[12]
Guidedmixup: an efficient mixup strategy guided by saliency maps
Minsoo Kang and Suhyun Kim. Guidedmixup: an efficient mixup strategy guided by saliency maps. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 1096–1104, 2023
2023
-
[13]
Trivialaugment: Tuning-free yet state-of-the-art data augmentation
Samuel G Müller and Frank Hutter. Trivialaugment: Tuning-free yet state-of-the-art data augmentation. InProceedings of the IEEE/CVF international conference on computer vision, pages 774–782, 2021
2021
-
[14]
Teachaugment: Data augmentation optimization using teacher knowledge
Teppei Suzuki. Teachaugment: Data augmentation optimization using teacher knowledge. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10904–10914, 2022
2022
-
[15]
Cutmix: Regularization strategy to train strong classifiers with localizable features
Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, and Youngjoon Yoo. Cutmix: Regularization strategy to train strong classifiers with localizable features. InInternational Conference on Computer Vision (ICCV), pages 6023–6032, 2019
2019
-
[16]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016
2016
-
[17]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weis- senborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Represen- tations (ICLR), 2021
2021
-
[18]
Random erasing data augmentation
Zhun Zhong, Liang Zheng, Guoliang Kang, Shaozi Li, and Yi Yang. Random erasing data augmentation. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 13001–13008, 2020
2020
-
[19]
Keepaugment: A simple information-preserving data augmentation approach
Chengyue Gong, Dilin Wang, Meng Li, Vikas Chandra, and Qiang Liu. Keepaugment: A simple information-preserving data augmentation approach. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1055–1064, 2021
2021
-
[20]
Gridmix: Strong regularization through local context mapping.Pattern Recognition, 109:107594, 2021
Kyungjune Baek, Duhyeon Bang, and Hyunjung Shim. Gridmix: Strong regularization through local context mapping.Pattern Recognition, 109:107594, 2021
2021
-
[21]
Data augmen- tation using random image cropping and patching for deep cnns.IEEE Transactions on Circuits and Systems for Video Technology, 30(9):2917– 2931, 2019
Ryo Takahashi, Takashi Matsubara, and Kuniaki Uehara. Data augmen- tation using random image cropping and patching for deep cnns.IEEE Transactions on Circuits and Systems for Video Technology, 30(9):2917– 2931, 2019
2019
-
[22]
Saliencymix: A saliency guided data augmen- tation strategy for better regularization
AFM Shahab Uddin, Mst Sirazam Monira, Wheemyung Shin, TaeChoong Chung, and Sung-Ho Bae. Saliencymix: A saliency guided data augmen- tation strategy for better regularization. InInternational Conference on Learning Representations, 2020
2020
-
[23]
Puzzle mix: Exploiting saliency and local statistics for optimal mixup
Jang-Hyun Kim, Wonho Choo, and Hyun Oh Song. Puzzle mix: Exploiting saliency and local statistics for optimal mixup. InInternational Conference on Machine Learning, pages 5275–5285. PMLR, 2020
2020
-
[24]
Rethinking the inception architecture for computer vision
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2818–2826, 2016
2016
-
[25]
Regularizing neural networks by penalizing confident output distributions
Gabriel Pereyra, George Tucker, Jan Chorowski, Łukasz Kaiser, and Geof- frey Hinton. Regularizing neural networks by penalizing confident output distributions. InInternational Conference on Learning Representations, 2017
2017
-
[26]
Delving deep into label smoothing
Chang-Bin Zhang, Peng-Tao Jiang, Qibin Hou, Yunchao Wei, Qi Han, Zhen Li, and Ming-Ming Cheng. Delving deep into label smoothing. IEEE Transactions on Image Processing, 30:5984–5996, 2021
2021
-
[27]
Self-progressing robust training
Minhao Cheng, Pin-Yu Chen, Sijia Liu, Shiyu Chang, Cho-Jui Hsieh, and Payel Das. Self-progressing robust training. InProceedings of the AAAI conference on artificial intelligence, volume 35, pages 7107–7115, 2021
2021
-
[28]
Enhancement of finger-vein image by vein line tracking and adaptive gabor filtering for finger-vein recognition.Applied Mechanics and Materials, 145:219–223, 2012
So Ra Cho, Young Ho Park, Gi Pyo Nam, Kwang Youg Shin, Hyeon Chang Lee, Kang Ryoung Park, Sung Min Kim, and Ho Chul AGVBENCH: A RELIABILITY-ORIENTED BENCHMARK OF DATA AUGMENTATION FOR VEIN RECOGNITION 14 Kim. Enhancement of finger-vein image by vein line tracking and adaptive gabor filtering for finger-vein recognition.Applied Mechanics and Materials, 145...
2012
-
[29]
Contactless palm vein recognition using a mutual foreground-based local binary pattern.IEEE transactions on Information Forensics and Security, 9(11):1974–1985, 2014
Wenxiong Kang and Qiuxia Wu. Contactless palm vein recognition using a mutual foreground-based local binary pattern.IEEE transactions on Information Forensics and Security, 9(11):1974–1985, 2014
1974
-
[30]
Enhanced maximum curvature descriptors for finger vein verification
Munalih Ahmad Syarif, Thian Song Ong, Andrew BJ Teoh, and Connie Tee. Enhanced maximum curvature descriptors for finger vein verification. Multimedia Tools and Applications, 76(5):6859–6887, 2017
2017
-
[31]
A palm vein recognition system based on a support vector machine.IEIE Transactions on Smart Processing & Computing, 8(1):1–7, 2019
Vijayakumar Ponnusamy, Abhijit Sridhar, Arun Baalaaji, and M Sangeetha. A palm vein recognition system based on a support vector machine.IEIE Transactions on Smart Processing & Computing, 8(1):1–7, 2019
2019
-
[32]
Finger vein recognition using mutual sparse representation classification.IET biometrics, 8(1):49– 58, 2019
Shazeeda Shazeeda and Bakhtiar Affendi Rosdi. Finger vein recognition using mutual sparse representation classification.IET biometrics, 8(1):49– 58, 2019
2019
-
[33]
Fvras-net: An embedded finger-vein recognition and antispoofing system using a unified cnn.IEEE Transactions on Instrumentation and Measurement, 69(11):8690–8701, 2020
Weili Yang, Wei Luo, Wenxiong Kang, Zhixing Huang, and Qiuxia Wu. Fvras-net: An embedded finger-vein recognition and antispoofing system using a unified cnn.IEEE Transactions on Instrumentation and Measurement, 69(11):8690–8701, 2020
2020
-
[34]
Finger vein recognition algorithm based on lightweight deep convolutional neural network.IEEE Transactions on Instrumentation and Measurement, 71:1–13, 2021
Jiaquan Shen, Ningzhong Liu, Chenglu Xu, Han Sun, Yushun Xiao, Deguang Li, and Yongxin Zhang. Finger vein recognition algorithm based on lightweight deep convolutional neural network.IEEE Transactions on Instrumentation and Measurement, 71:1–13, 2021
2021
-
[35]
Saad Shakeel, and Wenxiong Kang
Dacan Luo, Junduan Huang, Weili Yang, M. Saad Shakeel, and Wenxiong Kang. Rsnet: Region-specific network for contactless palm vein authentication.IEEE Transactions on Information Forensics and Security, 20:2734–2747, 2025
2025
-
[36]
Gridmask data augmentation.arXiv preprint arXiv:2001.04086, 2020
Pengguang Chen, Shu Liu, Hengshuang Zhao, Xingquan Wang, and Jiaya Jia. Gridmask data augmentation.arXiv preprint arXiv:2001.04086, 2020
-
[37]
You only cut once: Boosting data augmentation with a single cut
Junlin Han, Pengfei Fang, Weihao Li, Jie Hong, Mohammad Ali Armin, Ian Reid, Lars Petersson, and Hongdong Li. You only cut once: Boosting data augmentation with a single cut. InInternational Conference on Machine Learning, pages 8196–8212. PMLR, 2022
2022
-
[38]
Soft augmentation for image classification
Yang Liu, Shen Yan, Laura Leal-Taixé, James Hays, and Deva Ramanan. Soft augmentation for image classification. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16241–16250, 2023
2023
-
[39]
Randomized quantization: A generic augmentation for data agnostic self-supervised learning
Huimin Wu, Chenyang Lei, Xiao Sun, Peng-Shuai Wang, Qifeng Chen, Kwang-Ting Cheng, Stephen Lin, and Zhirong Wu. Randomized quantization: A generic augmentation for data agnostic self-supervised learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16305–16316, 2023
2023
-
[40]
Jie Qin, Jiemin Fang, Qian Zhang, Wenyu Liu, Xingang Wang, and Xinggang Wang. Resizemix: Mixing data with preserved object information and true labels.arXiv preprint arXiv:2012.11101, 2020
-
[41]
Fmix: Enhancing mixed sample data augmentation.arXiv preprint arXiv:2002.12047, 2020
Ethan Harris, Antonia Marcu, Matthew Painter, Mahesan Niranjan, and Adam Prügel-Bennett Jonathon Hare. Fmix: Enhancing mixed sample data augmentation.arXiv preprint arXiv:2002.12047, 2020
-
[42]
Training Deep Neural Networks on Noisy Labels with Bootstrapping
Scott Reed, Honglak Lee, Dragomir Anguelov, Christian Szegedy, Dumitru Erhan, and Andrew Rabinovich. Training deep neural networks on noisy labels with bootstrapping.arXiv preprint arXiv:1412.6596, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[43]
Mobilenetv2: Inverted residuals and linear bottlenecks
Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. In2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4510–4520, 2018
2018
-
[44]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. InInternational Conference on Computer Vision (ICCV), 2021
2021
-
[45]
Palmprint and palmvein recognition based on dcnn and a new large-scale contactless palmvein dataset.Symmetry, 10(4):78, 2018
Lin Zhang, Zaixi Cheng, Ying Shen, and Dongqing Wang. Palmprint and palmvein recognition based on dcnn and a new large-scale contactless palmvein dataset.Symmetry, 10(4):78, 2018
2018
-
[46]
On the vulnerability of palm vein recognition to spoofing attacks
Pedro Tome and Sébastien Marcel. On the vulnerability of palm vein recognition to spoofing attacks. In2015 International Conference on Biometrics (ICB), pages 319–325. IEEE, 2015
2015
-
[47]
Fusion of band limited phase only correlation and width centroid contour distance for finger based biometrics.Expert Systems with Applications, 41(7):3367–3382, 2014
Mohd Shahrimie Mohd Asaari, Shahrel A Suandi, and Bakhtiar Affendi Rosdi. Fusion of band limited phase only correlation and width centroid contour distance for finger based biometrics.Expert Systems with Applications, 41(7):3367–3382, 2014
2014
-
[48]
Sdumla-hmt: A multimodal biometric database
Yilong Yin, Lili Liu, and Xiwei Sun. Sdumla-hmt: A multimodal biometric database. InChinese conference on biometric recognition, pages 260–268. Springer, 2011
2011
-
[49]
Cubuk, Barret Zoph, Justin Gilmer, and Balaji Lakshminarayanan
Dan Hendrycks, Norman Mu, Ekin D. Cubuk, Barret Zoph, Justin Gilmer, and Balaji Lakshminarayanan. AugMix: A simple data processing method to improve robustness and uncertainty.Proceedings of the International Conference on Learning Representations (ICLR), 2020
2020
-
[50]
Benchmarking neural network robustness to common corruptions and perturbations.Proceedings of the International Conference on Learning Representations, 2019
Dan Hendrycks and Thomas Dietterich. Benchmarking neural network robustness to common corruptions and perturbations.Proceedings of the International Conference on Learning Representations, 2019
2019
-
[51]
Explaining and harnessing adversarial examples
Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. InInternational Conference on Learning Representations, 2015
2015
-
[52]
Towards deep learning models resistant to adversarial attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. InInternational Conference on Learning Representations, 2018
2018
-
[53]
SGDR: Stochastic Gradient Descent with Warm Restarts
Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts.arXiv preprint arXiv:1608.03983, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[54]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019
2019
-
[55]
Manifold mixup: Better representations by interpolating hidden states
Vikas Verma, Alex Lamb, Christopher Beckham, Amir Najafi, Ioannis Mitliagkas, David Lopez-Paz, and Yoshua Bengio. Manifold mixup: Better representations by interpolating hidden states. InInternational Conference on Machine Learning, pages 6438–6447, 2019
2019
-
[56]
Diffusemix: Label-preserving data augmentation with diffusion models
Khawar Islam, Muhammad Zaigham Zaheer, Arif Mahmood, and Karthik Nandakumar. Diffusemix: Label-preserving data augmentation with diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27621–27630, 2024. APPENDIX A. Additional Full Results This appendix reports the more complete experimental tables that...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.