The Moving Eye: Enhancing VLA Spatial Generalization via Hybrid Dynamic Data Collection
Pith reviewed 2026-07-03 11:11 UTC · model grok-4.3
The pith
Hybrid moving and static camera views in data collection reduce spurious correlations and improve VLA generalization to unseen poses where more fixed views fail.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that a hybrid data distribution mixing continuous camera motion with diverse static viewpoints substantially reduces the model's reliance on spurious correlations between camera position and task elements. This enables VLAs to generalize effectively to novel camera poses and object configurations, a capability not achieved by multi-fixed viewpoint strategies. The benefit holds across ACT, Diffusion Policy, and VLA models such as Pi0 and Gr00t.
What carries the argument
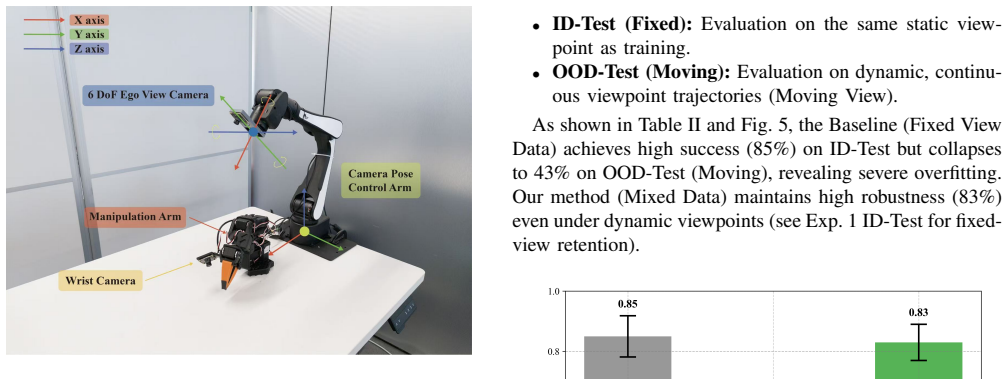
The hybrid dynamic data collection strategy using a mobile environmental camera arm in a dual-arm setup to generate mixed moving and static view distributions.
If this is right
- VLAs trained on hybrid data generalize to unseen camera poses and object configurations.
- Shortcut learning susceptibility is reduced while training stability is maintained.
- The improvement applies universally to different VLA architectures including ACT, Diffusion, Pi0, and Gr00t.
- Adding more static viewpoints alone does not achieve the same generalization gains.
Where Pith is reading between the lines
- Robotic data collection could use low-cost moving cameras to gain robustness without collecting far more total views.
- The hybrid motion strategy might apply to other tasks needing viewpoint-invariant perception beyond manipulation.
- Similar dynamic sampling could be tested for improving sim-to-real transfer on spatial reasoning problems.
Load-bearing premise
The dual-arm hardware and camera motion itself do not introduce new confounding factors or spurious correlations that could explain the observed generalization gains rather than the intended reduction in shortcut learning.
What would settle it
A test showing no generalization gain on unseen poses when the same viewpoint positions are captured statically instead of via continuous motion would falsify the claim that motion is necessary to break the shortcuts.
Figures




read the original abstract
Vision-Language-Action (VLA) models have shown remarkable promise in generalized robotic manipulation. However, their spatial generalization remains fragile. We argue that simply increasing the number of viewpoints is insufficient. Models often fall into the trap of Shortcut Learning, latching onto spurious correlations (e.g., fixed relative poses between objects or between the camera and robot base) rather than learning true spatial relationships. In this work, we propose a data-centric solution to enhance VLA spatial generalization. We utilize a dual-arm setup where one arm performs manipulation while the other serves as a mobile environmental camera. We systematically evaluate three data distribution patterns: Fixed, Multi-Fixed, and Moving Views. Our findings reveal that a hybrid strategy, combining continuous camera motion with diverse static viewpoints, yields the best performance by substantially reducing spurious correlations while maintaining training stability. Our experiments demonstrate that this strategy mitigates spurious correlations, enabling VLAs to generalize to unseen camera poses and object configurations where simply adding more static viewpoints fails. Crucially, we reveal that the susceptibility to shortcut learning and the struggle with spatial generalization are universal characteristics shared across diverse architectures. Consequently, all evaluated models (ACT, Diffusion, and VLA models including Pi0 and Gr00t) benefit significantly from our mixed data strategy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that Vision-Language-Action (VLA) models suffer from shortcut learning via spurious correlations (e.g., fixed camera-base or object poses) and that simply adding static viewpoints is insufficient. It proposes a dual-arm data collection setup in which one arm manipulates while the second provides camera motion, systematically comparing Fixed, Multi-Fixed, and Moving Views patterns. The central result is that a hybrid strategy (continuous motion plus diverse static viewpoints) yields the best spatial generalization to unseen camera poses and object configurations, with the benefit appearing universal across ACT, Diffusion Policy, Pi0, and Gr00t.
Significance. If the attribution to shortcut mitigation holds, the work would be significant for robotics: it supplies a practical, hardware-leveraged data-collection recipe that improves generalization without architectural changes and demonstrates that shortcut learning is architecture-agnostic. The dual-arm mobile-camera idea is a concrete contribution to data-centric robotics.
major comments (2)
- [§4] §4 (Experimental Setup and Data Collection Strategies): the claim that gains in the hybrid Moving+Multi-Fixed condition arise specifically from reduced spurious correlations is underdetermined. All conditions share the same dual-arm platform; continuous motion necessarily couples camera trajectories to second-arm joint states, potential self-occlusions, and altered end-effector dynamics. No ablation is reported that holds viewpoint statistics fixed while removing motion (or vice versa), so alternative explanations for the observed generalization differences cannot be ruled out.
- [Abstract and §4] Abstract and §4 (Results): the manuscript states that systematic comparisons were performed and that the hybrid strategy "substantially reduc[es] spurious correlations," yet no quantitative metrics, error bars, statistical tests, or explicit measurements of spurious correlations (e.g., pose-distribution statistics or shortcut probes) are described. Without these, the magnitude, reliability, and cross-model universality of the claimed benefit cannot be verified.
minor comments (1)
- [§3] Clarify the exact sampling procedure and viewpoint distribution statistics for each of the three patterns (Fixed, Multi-Fixed, hybrid) so that readers can assess how closely the Multi-Fixed baseline matches the pose marginals induced by continuous motion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with clarifications on our experimental design and evidence. Where the comments identify gaps, we indicate planned revisions to strengthen the paper.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Setup and Data Collection Strategies): the claim that gains in the hybrid Moving+Multi-Fixed condition arise specifically from reduced spurious correlations is underdetermined. All conditions share the same dual-arm platform; continuous motion necessarily couples camera trajectories to second-arm joint states, potential self-occlusions, and altered end-effector dynamics. No ablation is reported that holds viewpoint statistics fixed while removing motion (or vice versa), so alternative explanations for the observed generalization differences cannot be ruled out.
Authors: We acknowledge that the current comparisons do not include an ablation that isolates continuous motion dynamics from viewpoint statistics while holding other factors constant. The Fixed and Multi-Fixed conditions use static viewpoints, while Moving Views and the hybrid introduce motion on the same platform, so confounding effects from joint coupling or occlusions cannot be fully excluded. We will add an explicit discussion of this limitation in the revised §4 and §6, and note that future work could include such controls. The hybrid strategy's empirical superiority across conditions remains as reported, but we agree the causal attribution to shortcut reduction is not definitive without further isolation. revision: partial
-
Referee: [Abstract and §4] Abstract and §4 (Results): the manuscript states that systematic comparisons were performed and that the hybrid strategy "substantially reduc[es] spurious correlations," yet no quantitative metrics, error bars, statistical tests, or explicit measurements of spurious correlations (e.g., pose-distribution statistics or shortcut probes) are described. Without these, the magnitude, reliability, and cross-model universality of the claimed benefit cannot be verified.
Authors: The full manuscript reports success rates and generalization gaps for all conditions and models in §5 (with tables comparing Fixed, Multi-Fixed, Moving, and hybrid), but we agree that error bars, statistical tests, and direct measurements of spurious correlations (such as pose distribution overlap or shortcut probes) are not explicitly provided. We will revise the abstract, §4, and §5 to include error bars on all reported metrics, add statistical significance tests between conditions, and include quantitative analysis of viewpoint and pose distributions to support the reduction in spurious correlations. This will allow verification of the magnitude and cross-model consistency. revision: yes
Circularity Check
No circularity: purely empirical comparison of data-collection strategies
full rationale
The manuscript contains no equations, fitted parameters, predictions derived from prior fits, or self-citations used as load-bearing premises. All claims rest on direct experimental comparisons (Fixed vs. Multi-Fixed vs. Moving Views) across ACT, Diffusion, and VLA models. No derivation chain exists that could reduce to its own inputs by construction; the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Shortcut learning on spurious correlations such as fixed relative poses is the main cause of fragile spatial generalization in VLA models
Reference graph
Works this paper leans on
-
[1]
Libero-plus: A progressive robustness benchmark for visual-language-action models,
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, L. Ji, X. He, S. Zhang, Z. Fei, J. Fu, J. Gong, and X. Qiu, “Libero-plus: A progressive robustness benchmark for visual-language-action models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026, pp. 38 574–38 583
2026
-
[2]
LIBERO-PRO: Towards Robust and Fair Evaluation of Vision-Language-Action Models Beyond Memorization
X. Zhou, Y . Xu, G. Tie, Y . Chen, G. Zhang, D. Chu, P. Zhou, and L. Sun, “Libero-pro: Towards robust and fair evaluation of vision-language-action models beyond memorization,”arXiv preprint arXiv:2510.03827, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Decomposing the generalization gap in imitation learning for visual robotic manipulation,
A. Xie, L. Lee, T. Xiao, and C. Finn, “Decomposing the generalization gap in imitation learning for visual robotic manipulation,”arXiv preprint arXiv:2307.03659, 2023
-
[4]
Y . Chen, Z. Zhan, X. Lin, Z. Song, H. Liu, Q. Lyu, Y . Zu, X. Chen, Z. Liu, T. Puet al., “Radar: Benchmarking vision-language-action generalization via real-world dynamics, spatial-physical intelligence, and autonomous evaluation,”arXiv preprint arXiv:2602.10980, 2026
-
[5]
Project Aria: A New Tool for Egocentric Multi-Modal AI Research
J. Engel, K. Somasundaram, M. Goesele, A. Sun, A. Gamino, A. Turner, A. Talattof, A. Yuan, B. Souti, B. Meredithet al., “Project aria: A new tool for egocentric multi-modal ai research,”arXiv preprint arXiv:2308.13561, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Move: A simple motion-based data collection paradigm for spatial generalization in robotic manipulation,
H. Wang, C. B. Chen, Y . Yue, D. Tao, T. Guo, S. Xie, D. Huang, S. Song, G. Yao, and G. Huang, “Move: A simple motion-based data collection paradigm for spatial generalization in robotic manipulation,”
-
[7]
[Online]. Available: https://arxiv.org/abs/2512.04813
-
[8]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huanget al., “Gr00t n1: An open foundation model for generalist humanoid robots,”arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. V...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Spa: 3d spatial-awareness enables effective embodied representation,
H. Zhu, H. Yang, Y . Wang, J. Yang, L. Wang, and T. He, “Spa: 3d spatial-awareness enables effective embodied representation,”arXiv preprint arXiv:2410.08208, 2024
-
[11]
A. Abouzeid, M. Mansour, Z. Sun, and D. Song, “Geoaware-vla: Im- plicit geometry aware vision-language-action model,”arXiv preprint arXiv:2509.14117, 2025
-
[12]
Og- vla: 3d-aware vision language action model via orthographic image generation,
I. Singh, A. Goyal, S. Birchfield, D. Fox, A. Garg, and V . Blukis, “Og- vla: 3d-aware vision language action model via orthographic image generation,”arXiv e-prints, pp. arXiv–2506, 2025
2025
-
[13]
Rvt: Robotic view transformer for 3d object manipulation,
A. Goyal, J. Xu, Y . Guo, V . Blukis, Y .-W. Chao, and D. Fox, “Rvt: Robotic view transformer for 3d object manipulation,” inConference on Robot Learning. PMLR, 2023, pp. 694–710
2023
-
[14]
Manivid-3d: Generalizable view-invariant reinforcement learning for robotic manipulation via disentangled 3d representations,
Z. Li, P. Qu, Y . Jia, S. Zhou, H. Ge, J. Cao, J. Zhou, G. Zhou, and J. Ma, “Manivid-3d: Generalizable view-invariant reinforcement learning for robotic manipulation via disentangled 3d representations,” IEEE Robotics and Automation Letters, 2026
2026
-
[15]
Vla models are more generalizable than you think: Revisiting physical and spatial modeling,
W. Li, Q. Zhang, R. Zhai, L. Lin, and G. Wang, “Vla models are more generalizable than you think: Revisiting physical and spatial modeling,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026, pp. 35 025–35 035
2026
-
[16]
Visual-policy learning through multi-camera view to single-camera view knowledge distil- lation for robot manipulation tasks,
C. Acar, K. Binici, A. Tekirda ˘g, and Y . Wu, “Visual-policy learning through multi-camera view to single-camera view knowledge distil- lation for robot manipulation tasks,”IEEE Robotics and Automation Letters, vol. 9, no. 1, pp. 691–698, 2023
2023
-
[17]
Do you know where your camera is? View-invariant policy learning with camera conditioning,
T. Jiang, J. Ji, X. Tan, J. Fang, A. Bhattad, V . Guizilini, and M. R. Walter, “Do you know where your camera is? View-invariant policy learning with camera conditioning,” inIEEE International Conference on Robotics and Automation, 2026
2026
-
[18]
Agnostic manip- ulation policies with strategic vantage selection,
S. Vasudevan, S. Sagar, and R. Senanayake, “Agnostic manip- ulation policies with strategic vantage selection,”arXiv preprint arXiv:2506.12261, 2025
-
[19]
Multi-view masked world models for visual robotic manipulation,
Y . Seo, J. Kim, S. James, K. Lee, J. Shin, and P. Abbeel, “Multi-view masked world models for visual robotic manipulation,” inInterna- tional Conference on Machine Learning. PMLR, 2023, pp. 30 613– 30 632
2023
-
[20]
W. Cui, C. Zhao, Y . Chen, H. Li, Z. Zhang, D. Zhao, and H. Wang, “Cl3r: 3d reconstruction and contrastive learning for enhanced robotic manipulation representations,”arXiv preprint arXiv:2507.08262, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
View-invariant policy learning via zero-shot novel view synthesis,
S. Tian, B. Wulfe, K. Sargent, K. Liu, S. Zakharov, V . C. Guizilini, and J. Wu, “View-invariant policy learning via zero-shot novel view synthesis,” inConference on Robot Learning, 2024
2024
-
[22]
Novel demonstration generation with gaussian splatting enables ro- bust one-shot manipulation,
S. Yang, W. Yu, J. Zeng, J. Lv, K. Ren, C. Lu, D. Lin, and J. Pang, “Novel demonstration generation with gaussian splatting enables ro- bust one-shot manipulation,” inProceedings of Robotics: Science and Systems, 2025
2025
-
[23]
Invariance co-training for robot visual generalization,
J. Yang, C. Finn, and D. Sadigh, “Invariance co-training for robot visual generalization,”arXiv preprint arXiv:2512.05230, 2025
-
[24]
S. Huang, Y . Liao, S. Feng, S. Jiang, S. Liu, H. Li, M. Yao, and G. Ren, “Adversarial data collection: Human-collaborative perturba- tions for efficient and robust robotic imitation learning,”arXiv preprint arXiv:2503.11646, 2025
-
[25]
Vision in action: Learning active perception from human demonstrations,
H. Xiong, X. Xu, J. Wu, Y . Hou, J. Bohg, and S. Song, “Vision in action: Learning active perception from human demonstrations,” in Conference on Robot Learning, 2025
2025
-
[26]
Activeumi: Robotic manipulation with active perception from robot-free human demonstrations,
Q. Zeng, C. Li, J. St. John, Z. Zhou, J. Wen, G. Feng, Y . Zhu, and Y . Xu, “Activeumi: Robotic manipulation with active perception from robot-free human demonstrations,”arXiv preprint arXiv:2510.01607, 2025
-
[27]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,” 2023. [Online]. Available: https://arxiv.org/abs/2304.13705
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,” in Proceedings of Robotics: Science and Systems, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.