Guiding Human Validation of LLM-Generated Code via Verifiable Literate Programming
Pith reviewed 2026-07-03 08:40 UTC · model grok-4.3
The pith
Verifiable literate programming inserts an unambiguous natural-language documentation layer so users can detect and repair mismatches between their intent and LLM-generated code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VLP improves the reliability of LLM-generated code by enabling end-to-end human validation and repair through an intermediate NL documentation layer that supports mismatch detection and derivation of verifiable properties.
What carries the argument
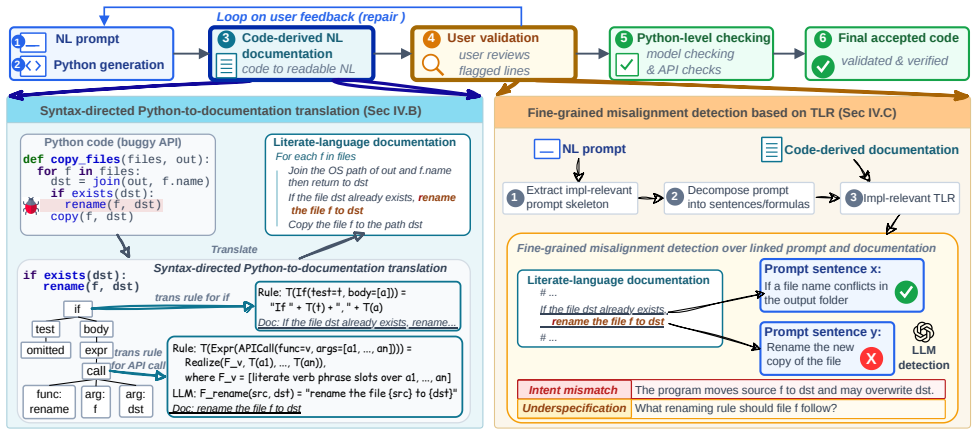
The NL-style literate language that supplies unambiguous syntax and a mostly deterministic code-to-documentation translation, serving as the readable intermediate layer for human feedback and subsequent verification.
If this is right
- Users can supply targeted feedback on specific documentation lines rather than on raw code or prompts alone.
- Trace links from prompts to documentation allow LLM mismatch detection to narrow review effort to suspicious sections.
- Validated documentation can be mechanically converted into API-usage checks and formal properties for model checking.
- The resulting process raises the fraction of code that passes functional tests while keeping human effort within practical bounds.
Where Pith is reading between the lines
- The same documentation layer could serve as a persistent artifact for later maintenance or reuse beyond the initial validation step.
- If the deterministic translation holds across more programming languages, the method might extend to non-Python codebases without new language-specific tooling.
- Integration with existing IDEs could allow the documentation to be edited inline, turning validation into a live editing session.
Load-bearing premise
The NL-style literate language has unambiguous syntax and admits a mostly deterministic translation from code back to documentation.
What would settle it
A controlled test in which users receive the generated documentation yet still fail to identify a documented semantic deviation that actually exists in the code, or in which the translation produces inconsistent documentation for the same code.
Figures




read the original abstract
Vibe coding democratizes software development by allowing users to generate code via natural-language (NL) interaction with large language models (LLMs). However, the code is reliable only when it faithfully implements the user's intent, which is difficult and labor-intensive for users to validate. Existing validation methods either rely on LLM-assisted automated testing, which suffers from prompt ambiguity and model fallibility, or involve users only in partial software artifacts such as prompts and test cases, which may overlook corner cases and program details. Motivated by a bug study of LLM-generated code, we find that detailed human feedback is essential, as failures often stem from underspecified requirements or subtle semantic deviations. This paper presents verifiable literate programming (VLP), a human-in-the-loop framework designed to make the review/validation process of LLM-generated code accessible to users at all programming levels. At its core, VLP proposes unambiguous NL-based documentation as a readable intermediate layer between prompts and code. The documentation demonstrates concrete program semantics and enables users to provide feedback on potential intent-code mismatches. It supports human-involved, end-to-end repair and validation via three techniques: (i) an NL-style literate language with unambiguous syntax and mostly deterministic code-to-documentation translation, (ii) LLM-based fine-grained mismatch detection that uses trace links between prompts and documentation to focus users' review effort on suspicious documentation lines, and (iii) a verification module that leverages user-validated documentation to derive API-usage checks and formal properties, which are then verified against the generated code using model checking. Our evaluation shows that VLP improves code pass@1 from 28.7%-73.2% to 65.4%-93.5% with reasonable user effort.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces verifiable literate programming (VLP) as a human-in-the-loop framework to validate LLM-generated code. It proposes three techniques: (i) an NL-style literate language with unambiguous syntax and mostly deterministic code-to-documentation translation serving as a readable intermediate layer, (ii) LLM-based fine-grained mismatch detection that uses trace links between prompts and documentation to focus review effort, and (iii) a verification module that derives API-usage checks and formal properties from user-validated documentation for model checking against the code. The central empirical claim is that VLP raises code pass@1 from 28.7%-73.2% to 65.4%-93.5% with reasonable user effort, motivated by a bug study showing the need for detailed human feedback on underspecified requirements and semantic deviations.
Significance. If the evaluation holds under rigorous controls, VLP could meaningfully lower the barrier for non-expert users to validate and repair LLM-generated code by combining readable documentation, targeted mismatch highlighting, and automated verification. The approach extends literate programming concepts to NL settings and integrates them with model checking, potentially addressing a practical pain point in LLM-assisted development.
major comments (2)
- [Evaluation section] Evaluation section (abstract and §4): the headline pass@1 gains (28.7%-73.2% to 65.4%-93.5%) are stated without any description of the benchmark suite, number of tasks, user-study protocol, participant selection, statistical controls, error bars, or how 'reasonable user effort' was quantified. This information is load-bearing for assessing whether the reported improvement is robust or subject to post-hoc selection.
- [§3.1] §3.1 (technique i): the core assumption that the NL-style literate language 'possesses unambiguous syntax and admits a mostly deterministic code-to-documentation translation' is asserted as a design goal but lacks a formal grammar, determinism proof, or counter-example analysis; violation of this assumption would undermine both mismatch detection and the downstream verification module.
minor comments (2)
- [Introduction] The motivating bug study is referenced in the abstract but not described or cited with concrete findings or methodology.
- [§3.2] Notation for trace links between prompts and documentation is introduced without an explicit definition or example in the early sections.
Simulated Author's Rebuttal
We thank the referee for their constructive comments and recommendation for major revision. We address each major comment below and will incorporate the requested clarifications and formalizations into the revised manuscript.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section (abstract and §4): the headline pass@1 gains (28.7%-73.2% to 65.4%-93.5%) are stated without any description of the benchmark suite, number of tasks, user-study protocol, participant selection, statistical controls, error bars, or how 'reasonable user effort' was quantified. This information is load-bearing for assessing whether the reported improvement is robust or subject to post-hoc selection.
Authors: We agree that the evaluation details are insufficiently described. In the revised manuscript we will expand §4 (and update the abstract as needed) to fully specify the benchmark suite, number of tasks, user-study protocol, participant selection, statistical controls, error bars, and the quantification of user effort. revision: yes
-
Referee: [§3.1] §3.1 (technique i): the core assumption that the NL-style literate language 'possesses unambiguous syntax and admits a mostly deterministic code-to-documentation translation' is asserted as a design goal but lacks a formal grammar, determinism proof, or counter-example analysis; violation of this assumption would undermine both mismatch detection and the downstream verification module.
Authors: We acknowledge that the current text asserts these properties without formal support. We will revise §3.1 to include an explicit grammar definition and a determinism analysis with discussion of potential counter-examples. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper's central claim is an empirical evaluation result (pass@1 improvement from 28.7%-73.2% to 65.4%-93.5%) obtained via user studies and benchmarks on the three VLP techniques. No equations, fitted parameters, self-citations, or derivations are present that reduce the reported outcome to an input by construction. The assumption of unambiguous NL syntax is explicitly a design goal of technique (i), not a derived or fitted quantity. The derivation chain is therefore self-contained against external evaluation data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The NL-style literate language has unambiguous syntax and mostly deterministic code-to-documentation translation.
invented entities (1)
-
Verifiable literate programming (VLP)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2026 agentic coding trends report,
Anthropic, “2026 agentic coding trends report,” https: //resources.anthropic.com/hubfs/2026%20Agentic%20Coding% 20Trends%20Report.pdf?hsLang=en, 2026
2026
-
[2]
Top vibe coding statistics & trends,
Li, Matt, “Top vibe coding statistics & trends,” https://www.secondtalent. com/resources/vibe-coding-statistics/, 2026
2026
-
[3]
Building software by rolling the dice: A qualitative study of vibe coding,
Y .-H. Chou, B. Jiang, Y . W. Chen, M. Weng, V . Jackson, T. Zimmermann, and J. A. Jones, “Building software by rolling the dice: A qualitative study of vibe coding,”arXiv preprint arXiv:2512.22418, 2025
- [4]
-
[5]
Intent formalization: A grand challenge for reliable coding in the age of ai agents,
S. K. Lahiri, “Intent formalization: A grand challenge for reliable coding in the age of ai agents,”arXiv preprint arXiv:2603.17150, 2026
-
[6]
State of code developer survey report,
Sonar, “State of code developer survey report,” https://www.sonarsource. com/state-of-code-developer-survey-report.pdf, 2026
2026
-
[7]
Lever: Learning to verify language-to-code generation with execution,
A. Ni, S. Iyer, D. Radev, V . Stoyanov, W.-t. Yih, S. Wang, and X. V . Lin, “Lever: Learning to verify language-to-code generation with execution,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 26 106–26 128
2023
-
[8]
Automated unit test improvement using large language models at meta,
N. Alshahwan, J. Chheda, A. Finogenova, B. Gokkaya, M. Harman, I. Harper, A. Marginean, S. Sengupta, and E. Wang, “Automated unit test improvement using large language models at meta,” inCompanion Pro- ceedings of the 32nd ACM International Conference on the Foundations of Software Engineering, 2024, pp. 185–196
2024
-
[9]
Rethinking verification for LLM code generation: From generation to testing,
Z. Ma, T. Zhang, Maosongcao, J. Liu, W. Zhang, M. Luo, S. Zhang, and K. Chen, “Rethinking verification for LLM code generation: From generation to testing,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. [Online]. Available: https://openreview.net/forum?id=Gp2vgxWROE
2025
-
[10]
Testeval: Benchmarking large language models for test case generation,
W. Wang, C. Yang, Z. Wang, Y . Huang, Z. Chu, D. Song, L. Zhang, A. R. Chen, and L. Ma, “Testeval: Benchmarking large language models for test case generation,” inFindings of the Association for Computational Linguistics: NAACL 2025, 2025, pp. 3547–3562
2025
-
[11]
Test case generation for requirements in natural language-an llm comparison study,
B. R. Korraprolu, P. Pinninti, and Y . R. Reddy, “Test case generation for requirements in natural language-an llm comparison study,” in Proceedings of the 18th Innovations in Software Engineering Conference, 2025, pp. 1–5
2025
-
[12]
Test-driven development and llm-based code generation,
N. S. Mathews and M. Nagappan, “Test-driven development and llm-based code generation,” inProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, 2024, pp. 1583–1594
2024
-
[13]
Automated program refinement: Guide and verify code large language model with refinement calculus,
Y . Cai, Z. Hou, D. Sanán, X. Luan, Y . Lin, J. Sun, and J. S. Dong, “Automated program refinement: Guide and verify code large language model with refinement calculus,”Proceedings of the ACM on Programming Languages, vol. 9, no. POPL, pp. 2057–2089, 2025
2057
-
[14]
Lemur: Integrating large language models in automated program verification,
H. Wu, C. Barrett, and N. Narodytska, “Lemur: Integrating large language models in automated program verification,”arXiv preprint arXiv:2310.04870, 2023
-
[15]
Clover: Clo sed-loop ver ifiable code generation,
C. Sun, Y . Sheng, O. Padon, and C. Barrett, “Clover: Clo sed-loop ver ifiable code generation,” inInternational Symposium on AI Verification. Springer, 2024, pp. 134–155
2024
-
[16]
Vecogen: Automating generation of formally verified c code with large language models,
M. Sevenhuijsen, K. Etemadi, and M. Nyberg, “Vecogen: Automating generation of formally verified c code with large language models,” in 2025 IEEE/ACM 13th International Conference on Formal Methods in Software Engineering (FormaliSE). IEEE, 2025, pp. 101–112
2025
-
[17]
Towards formal verification of llm-generated code from natural language prompts,
A. Councilman, D. J. Fu, A. Gupta, C. Wang, D. Grove, Y .-X. Wang, and V . Adve, “Towards formal verification of llm-generated code from natural language prompts,”arXiv preprint arXiv:2507.13290, 2025
-
[18]
Y . Wang, J. Zhou, H. Lyu, Z. Chao, T. Wang, and H. Li, “Deepassert: An llm-aided verification framework with fine-grained assertion generation for modules with extracted module specifications,”arXiv preprint arXiv:2509.14668, 2025
-
[19]
Certificates in ai: Learn but verify,
C. Barrett, T. A. Henzinger, and S. A. Seshia, “Certificates in ai: Learn but verify,”Commun. ACM, vol. 69, no. 1, p. 66–75, Dec. 2025. [Online]. Available: https://doi.org/10.1145/3737447
-
[20]
Code-aware prompting: A study of coverage-guided test generation in regression setting using llm,
G. Ryan, S. Jain, M. Shang, S. Wang, X. Ma, M. K. Ramanathan, and B. Ray, “Code-aware prompting: A study of coverage-guided test generation in regression setting using llm,”Proceedings of the ACM on Software Engineering, vol. 1, no. FSE, pp. 951–971, 2024
2024
-
[21]
Coverup: Effective high coverage test generation for python,
J. Altmayer Pizzorno and E. D. Berger, “Coverup: Effective high coverage test generation for python,”Proceedings of the ACM on Software Engineering, vol. 2, no. FSE, pp. 2897–2919, 2025
2025
-
[22]
Llm test generation via iterative hybrid program analysis,
S. Gu, N. Nashid, and A. Mesbah, “Llm test generation via iterative hybrid program analysis,”arXiv preprint arXiv:2503.13580, 2025
-
[23]
On the effectiveness of llm-as-a-judge for code generation and summarization,
G. Crupi, R. Tufano, A. Velasco, A. Mastropaolo, D. Poshyvanyk, and G. Bavota, “On the effectiveness of llm-as-a-judge for code generation and summarization,”IEEE Transactions on Software Engineering, 2025
2025
-
[24]
Clarifygpt: A framework for enhancing llm-based code generation via requirements clarification,
F. Mu, L. Shi, S. Wang, Z. Yu, B. Zhang, C. Wang, S. Liu, and Q. Wang, “Clarifygpt: A framework for enhancing llm-based code generation via requirements clarification,”Proceedings of the ACM on Software Engineering, vol. 1, no. FSE, pp. 2332–2354, 2024
2024
-
[25]
Python code generation by asking clarification questions,
H.-S. X. Li, M. Mesgar, A. F. Martins, and I. Gurevych, “Python code generation by asking clarification questions,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023, pp. 14 287–14 306
2023
-
[26]
Curiosity by design: An llm-based coding assistant asking clarification questions,
H. Darji and T. Lutellier, “Curiosity by design: An llm-based coding assistant asking clarification questions,”arXiv preprint arXiv:2507.21285, 2025
-
[27]
Clarigen: Bridging instruction gaps via interactive clarification in code generation,
C. Miao, Y . Wang, L. He, L. Fang, and P. S. Yu, “Clarigen: Bridging instruction gaps via interactive clarification in code generation,” in AAAI 2025 Workshop on Preventing and Detecting LLM Misinformation (PDLM), 2025
2025
-
[28]
Large language models should ask clarifying questions to increase confidence in generated code,
J. J. Wu, “Large language models should ask clarifying questions to increase confidence in generated code,”arXiv preprint arXiv:2308.13507, 2023
-
[29]
Automated repair of ambiguous problem descriptions for llm-based code generation,
H. Jia, R. Morris, H. Ye, F. Sarro, and S. Mechtaev, “Automated repair of ambiguous problem descriptions for llm-based code generation,”arXiv preprint arXiv:2505.07270, 2025
-
[30]
Contested: Consistency-aided tested code generation with llm,
J. Dong, J. Sun, W. Zhang, J. S. Dong, and D. Hao, “Contested: Consistency-aided tested code generation with llm,”Proceedings of the ACM on Software Engineering, vol. 2, no. ISSTA, pp. 596–617, 2025
2025
-
[31]
E. Firouzi and M. Ghafari, “Persistent human feedback, llms, and static analyzers for secure code generation and vulnerability detection,”arXiv preprint arXiv:2602.05868, 2026
-
[32]
Llm- based test-driven interactive code generation: User study and empirical evaluation,
S. Fakhoury, A. Naik, G. Sakkas, S. Chakraborty, and S. K. Lahiri, “Llm- based test-driven interactive code generation: User study and empirical evaluation,”IEEE Transactions on Software Engineering, vol. 50, no. 9, pp. 2254–2268, 2024
2024
-
[33]
Machine learning testing: Survey, landscapes and horizons,
J. M. Zhang, M. Harman, L. Ma, and Y . Liu, “Machine learning testing: Survey, landscapes and horizons,”IEEE Transactions on Software Engineering, vol. 48, no. 1, pp. 1–36, 2020
2020
-
[34]
Quantcode-eval: Bench- marking quantitative strategy code reproduction from finance papers,
W. Lu, Z. Yuan, H. Wu, D. Jin, and C. Wu, “Quantcode-eval: Bench- marking quantitative strategy code reproduction from finance papers,” Available at SSRN 6801618, 2026
2026
-
[35]
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
T. Y . Zhuo, M. C. Vu, J. Chim, H. Hu, W. Yu, R. Widyasari, I. N. B. Yusuf, H. Zhan, J. He, I. Paulet al., “Bigcodebench: Benchmarking code generation with diverse function calls and complex instructions,”arXiv preprint arXiv:2406.15877, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Deepseek v4 flash,
DeepSeek-AI, “Deepseek v4 flash,” https://www.deepseek.com, 2026
2026
-
[37]
Claude opus 4.7,
Anthropic, “Claude opus 4.7,” https://www.anthropic.com/claude/opus, 2026
2026
-
[38]
Literate programming,
D. E. Knuth, “Literate programming,”The computer journal, vol. 27, no. 2, pp. 97–111, 1984
1984
-
[39]
Natural language outlines for code: Literate programming in the llm era,
K. Shi, D. Altınbüken, S. Anand, M. Christodorescu, K. Grünwedel, A. Koenings, S. Naidu, A. Pathak, M. Rasi, F. Ribeiroet al., “Natural language outlines for code: Literate programming in the llm era,” inProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering, 2025, pp. 150–161
2025
-
[40]
Enhancing code generation via bidirectional comment-level mutual grounding,
Y . Di and T. Zhang, “Enhancing code generation via bidirectional comment-level mutual grounding,”arXiv preprint arXiv:2505.07768, 2025
-
[41]
Bounded model checking
A. Biere, A. Cimatti, E. M. Clarke, O. Strichman, and Y . Zhu, “Bounded model checking.”Handbook of satisfiability, vol. 185, no. 99, pp. 457– 481, 2009
2009
-
[42]
Jupyter notebook: The classic notebook interface,
Jupyter, “Jupyter notebook: The classic notebook interface,” https:// jupyter.org/, 2026
2026
-
[43]
Model checking,
E. M. Clarke, “Model checking,” inInternational conference on founda- tions of software technology and theoretical computer science. Springer, 1997, pp. 54–56
1997
-
[44]
Semantical considerations on floyd-hoare logic,
V . R. Pratt, “Semantical considerations on floyd-hoare logic,” in17th Annual Symposium on Foundations of Computer Science (sfcs 1976). IEEE, 1976, pp. 109–121
1976
-
[45]
Toward natural language computa- tion i,
A. W. Biermann and B. W. Ballard, “Toward natural language computa- tion i,”American Journal of Computational Linguistics, vol. 6, no. 2, pp. 71–86, 1980
1980
-
[46]
Natural language programming: Styles, strategies, and contrasts,
L. A. Miller, “Natural language programming: Styles, strategies, and contrasts,”IBM Systems Journal, vol. 20, no. 2, pp. 184–215, 1981
1981
-
[47]
C. Peng, M. Jiang, Y . Zhou, and L. Wu, “Thought is all you need: Smart contract vulnerability detection with thought-augmented large language model,”Proc. ACM Softw. Eng., vol. 3, no. FSE, 2026. [Online]. Available: https://doi.org/10.1145/3808141
-
[48]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
D. Zhou, N. Schärli, L. Hou, J. Wei, N. Scales, X. Wang, D. Schu- urmans, C. Cui, O. Bousquet, Q. Leet al., “Least-to-most prompting enables complex reasoning in large language models,”arXiv preprint arXiv:2205.10625, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[49]
Recovering traceability links between code and documentation,
G. Antoniol, G. Canfora, G. Casazza, A. De Lucia, and E. Merlo, “Recovering traceability links between code and documentation,”IEEE transactions on software engineering, vol. 28, no. 10, pp. 970–983, 2002
2002
-
[50]
Lissa: Toward generic traceability link recovery through retrieval-augmented generation,
D. Fuch β, T. Hey, J. Keim, H. Liu, N. Ewald, T. Thirolf, and A. Koziolek, “Lissa: Toward generic traceability link recovery through retrieval-augmented generation,” in2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE, 2025, pp. 1396– 1408
2025
-
[51]
Python symbolic execution with llm-powered code generation,
W. Wang, K. Liu, A. R. Chen, G. Li, Z. Jin, G. Huang, and L. Ma, “Python symbolic execution with llm-powered code generation,”arXiv preprint arXiv:2409.09271, 2024
-
[52]
Langchain,
H. Chase, “Langchain,” https://github.com/langchain-ai/langchain, 2022
2022
-
[53]
O’Reilly Media, Inc
S. Bird, E. Klein, and E. Loper,Natural language processing with Python: analyzing text with the natural language toolkit. " O’Reilly Media, Inc.", 2009
2009
-
[54]
A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, A. El-Kishky, A. McLaughlin, A. Low, A. Ostrow, A. Ananthramet al., “Openai gpt-5 system card,”arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. D. O. Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockmanet al., “Evaluating large language models trained on code,”arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[56]
Judging llm-as-a-judge with mt-bench and chatbot arena,
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. Xinget al., “Judging llm-as-a-judge with mt-bench and chatbot arena,”Advances in neural information processing systems, vol. 36, pp. 46 595–46 623, 2023
2023
-
[57]
Prometheus: Inducing fine-grained evaluation capability in language models,
S. Kim, J. Shin, J. Jang, S. Longpre, H. Lee, S. Yun, R. Shin, S. Kim, J. Thorne, M. Seoet al., “Prometheus: Inducing fine-grained evaluation capability in language models,” inInternational Conference on Learning Representations, vol. 2024, 2024, pp. 29 927–29 962
2024
-
[58]
Fewer hallucinations, more verification: A three-stage llm-based framework for asr error correction,
Y . Fang, B. Chen, J. Peng, X. Li, Y . Xi, C. Zhang, and G. Zhong, “Fewer hallucinations, more verification: A three-stage llm-based framework for asr error correction,”arXiv preprint arXiv:2505.24347, 2025
-
[59]
Llm-check: Investigating detection of hallucinations in large language models,
G. Sriramanan, S. Bharti, V . S. Sadasivan, S. Saha, P. Kattakinda, and S. Feizi, “Llm-check: Investigating detection of hallucinations in large language models,”Advances in Neural Information Processing Systems, vol. 37, pp. 34 188–34 216, 2024
2024
-
[60]
Calibration and correctness of language models for code,
C. Spiess, D. Gros, K. S. Pai, M. Pradel, M. R. I. Rabin, A. Alipour, S. Jha, P. Devanbu, and T. Ahmed, “Calibration and correctness of language models for code,” in2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE, 2025, pp. 540–552
2025
-
[61]
Validating llm-generated programs with meta- morphic prompt testing,
X. Wang and D. Zhu, “Validating llm-generated programs with meta- morphic prompt testing,”arXiv preprint arXiv:2406.06864, 2024
-
[62]
Effective LLM Code Refinement via Property-Oriented and Structurally Minimal Feedback
L. He, Z. Chen, Z. Zhang, J. Shao, X. Gao, and L. Sheng, “Use property- based testing to bridge llm code generation and validation,”arXiv preprint arXiv:2506.18315, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
E. Meijer, “Guardians of the agents,”Commun. ACM, vol. 69, no. 1, p. 46–52, Dec. 2025. [Online]. Available: https://doi.org/10.1145/3777544
-
[64]
Sharpen the spec, cut the code: A case for generative file system with sysspec,
Q. Liu, M. Zou, H. Zhang, D. Du, Y . Xia, and H. Chen, “Sharpen the spec, cut the code: A case for generative file system with sysspec,”arXiv preprint arXiv:2512.13047, 2025
-
[65]
FM-Agent: Scaling Formal Methods to Large Systems via LLM-Based Hoare-Style Reasoning
H. Ding, Z. Wang, and H. Chen, “Fm-agent: Scaling formal methods to large systems via llm-based hoare-style reasoning,”arXiv preprint arXiv:2604.11556, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[66]
Self-spec: Model-authored specifications for reliable llm code generation,
Z. Xu, X. Cheng, J. Xue, and Y . Li, “Self-spec: Model-authored specifications for reliable llm code generation,” inOpen Conference of AI Agents for Science 2025
2025
-
[67]
Spec Kit,
D. Delimarsky and M. Riem, “Spec Kit,” Apr. 2026. [Online]. Available: https://github.com/github/spec-kit
2026
-
[68]
Y . Liu, Y . Xue, D. Wu, Y . Sun, Y . Li, M. Shi, and Y . Liu, “Propertygpt: Llm-driven formal verification of smart contracts through retrieval- augmented property generation,”arXiv preprint arXiv:2405.02580, 2024
-
[69]
RvLLM: LLM runtime verification with domain knowledge,
Y . Zhang, S. Y . Emma, A. L. J. En, and J. S. Dong, “RvLLM: LLM runtime verification with domain knowledge,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. [Online]. Available: https://openreview.net/forum?id=XdwPWKbxd9
2025
-
[70]
Evaluating the ability of gpt-4o to generate verifiable specifications in verifast,
M. Rego, W. Fan, X. Hu, S. Dod, Z. Ni, D. Xie, J. DiVincenzo, and L. Tan, “Evaluating the ability of gpt-4o to generate verifiable specifications in verifast,” in2025 IEEE/ACM Second International Conference on AI Foundation Models and Software Engineering (Forge). IEEE, 2025, pp. 246–251
2025
-
[71]
Llm-guided formal verification coupled with mutation testing,
M. Hassan, S. Ahmadi-Pour, K. Qayyum, C. K. Jha, and R. Drechsler, “Llm-guided formal verification coupled with mutation testing,” in2024 Design, Automation & Test in Europe Conference & Exhibition (DATE). IEEE, 2024, pp. 1–2
2024
-
[72]
Grounded copilot: How programmers interact with code-generating models,
S. Barke, M. B. James, and N. Polikarpova, “Grounded copilot: How programmers interact with code-generating models,”Proceedings of the ACM on Programming Languages, vol. 7, no. OOPSLA1, pp. 85–111, 2023
2023
-
[73]
Reading between the lines: Modeling user behavior and costs in ai-assisted programming,
H. Mozannar, G. Bansal, A. Fourney, and E. Horvitz, “Reading between the lines: Modeling user behavior and costs in ai-assisted programming,” inProceedings of the 2024 CHI conference on human factors in computing systems, 2024, pp. 1–16
2024
-
[74]
Towards more effective ai-assisted programming: A systematic design exploration to improve visual studio intellicode’s user experience,
P. Vaithilingam, E. L. Glassman, P. Groenwegen, S. Gulwani, A. Z. Henley, R. Malpani, D. Pugh, A. Radhakrishna, G. Soares, J. Wanget al., “Towards more effective ai-assisted programming: A systematic design exploration to improve visual studio intellicode’s user experience,” in 2023 IEEE/ACM 45th International Conference on Software Engineering: Software ...
2023
-
[75]
C. Zhu-Tian, Z. Xiong, X. Yao, and E. Glassman, “Sketch then generate: Providing incremental user feedback and guiding llm code generation through language-oriented code sketches,”arXiv preprint arXiv:2405.03998, 2024
-
[76]
Validating ai-generated code with live programming,
K. Ferdowsi, R. Huang, M. B. James, N. Polikarpova, and S. Lerner, “Validating ai-generated code with live programming,” inProceedings of the 2024 CHI conference on human factors in computing systems, 2024, pp. 1–8
2024
-
[77]
Hilde: Intentional code generation via human-in-the-loop decoding,
E. A. González, R. Rothkopf, S. Lerner, and N. Polikarpova, “Hilde: Intentional code generation via human-in-the-loop decoding,” in2025 IEEE Symposium on Visual Languages and Human-Centric Computing (VL/HCC). IEEE, 2025, pp. 222–233
2025
-
[78]
Human-in-the- loop software development agents,
W. Takerngsaksiri, J. Pasuksmit, P. Thongtanunam, C. Tantithamthavorn, R. Zhang, F. Jiang, J. Li, E. Cook, K. Chen, and M. Wu, “Human-in-the- loop software development agents,” in2025 IEEE/ACM 47th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). IEEE, 2025, pp. 342–352
2025
-
[79]
M. Larbi, A. Akli, M. Papadakis, R. Bouyousfi, M. Cordy, F. Sarro, and Y . L. Traon, “When prompts go wrong: Evaluating code model robustness to ambiguous, contradictory, and incomplete task descriptions,”arXiv preprint arXiv:2507.20439, 2025
-
[80]
What Prompts Don't Say: Understanding and Managing Underspecification in LLM Prompts
C. Yang, Y . Shi, Q. Ma, M. X. Liu, C. Kästner, and T. Wu, “What prompts don’t say: Understanding and managing underspecification in llm prompts,”arXiv preprint arXiv:2505.13360, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.