Know Your Source: A Public Knowledge Store for Media Background Checks
Pith reviewed 2026-07-03 14:29 UTC · model grok-4.3
The pith
MEDIAREF supplies a public collection of web documents that lets LLMs produce better media background checks across 200 sources without paid search tools.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MEDIAREF is a publicly available knowledge store of web-sourced documents covering 200 media sources; when LLMs generate media background checks from it, the resulting assessments are higher quality by automatic and qualitative measures than those obtained under prior costly methods, and the collection itself supports fully reproducible, low-cost evaluation that can be updated by the same documented procedure.
What carries the argument
MEDIAREF, the publicly available knowledge store of web-sourced documents for 200 media sources that replaces proprietary search APIs for MBC generation.
If this is right
- Any researcher can now rerun or extend MBC generation experiments on the 200 sources without incurring API costs.
- LLM outputs for source credibility become directly comparable across studies because they rest on the same fixed public collection.
- The reproducible update procedure allows the store to stay current, preserving evaluation validity over time.
- Downstream automated fact-checking systems gain a concrete mechanism for incorporating source credibility signals at low marginal cost.
Where Pith is reading between the lines
- MEDIAREF could serve as a testbed for studying how collection methodology itself affects perceived source credibility.
- The same public-store pattern might be applied to other evidence domains where source reliability matters, such as scientific literature or government reports.
- Periodic community contributions to the store could further reduce maintenance burden while maintaining reproducibility.
Load-bearing premise
The documents collected from the web for the 200 media sources are sufficient and representative enough to produce accurate background checks without systematic bias introduced by the collection process.
What would settle it
An experiment that compares fact-verification accuracy when downstream systems use MBCs generated from MEDIAREF versus MBCs generated from live proprietary search results on the same 200 sources and finds the MEDIAREF versions produce measurably worse verification outcomes.
Figures

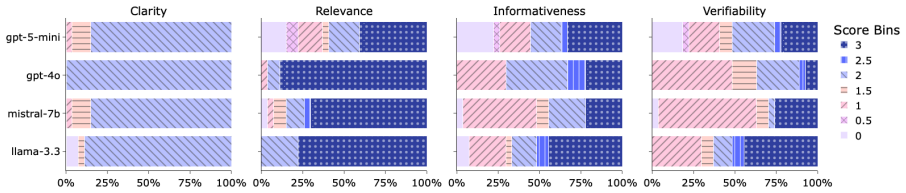
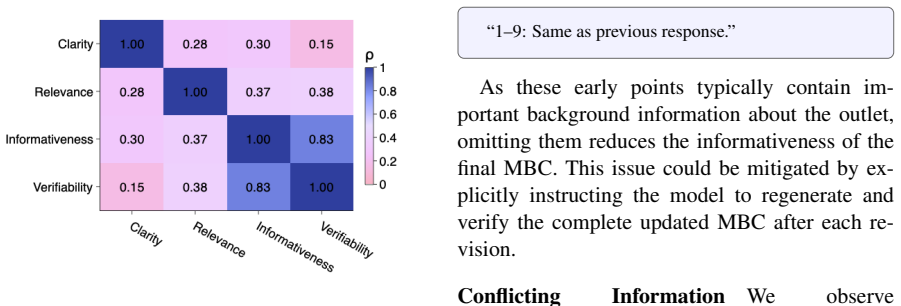

read the original abstract
LLM-based retrieval-augmented generation (RAG) is increasingly used for automated fact-checking (AFC) and related tasks. By grounding LLM outputs in retrieved evidence, RAG-based systems provide transparent justifications while allowing external information to be updated independently of the underlying model. However, existing approaches often assume retrieved evidence is reliable, although real-world information may be conflicting, outdated, and can originate from unreliable or biased sources. Recent work on *source-critical reasoning* addresses this challenge through media background checks (MBCs) (Schlichtkrull, 2024), which assess the credibility of evidence sources to support downstream fact verification. However, generating MBCs relies on costly proprietary search APIs, limiting reproducibility. To mitigate this issue, we introduce MEDIAREF, a publicly available knowledge store of web-sourced documents that enables reproducible, low-cost evaluation of MBC generation across 200 media sources. We describe a reproducible methodology for constructing and updating the collection, assess widely used LLMs on the MBC generation task, and demonstrate that MEDIAREF supports higher-quality MBC generation through both automatic and qualitative evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MEDIAREF, a publicly available knowledge store of web-sourced documents covering 200 media sources. It describes a reproducible methodology for constructing and updating the collection, evaluates widely used LLMs on the media background check (MBC) generation task, and claims that MEDIAREF enables higher-quality MBC generation (supported by automatic and qualitative evaluations) while facilitating reproducible, low-cost evaluation.
Significance. If the central claims hold, the public release of MEDIAREF would lower barriers to reproducible research on source-critical reasoning for fact-checking and RAG systems by replacing proprietary search APIs. The emphasis on a documented, updatable collection methodology is a clear strength for community use.
major comments (2)
- [Evaluation section] Evaluation section: the claim that MEDIAREF 'supports higher-quality MBC generation through both automatic and qualitative evaluation' lacks any reported metrics, baselines, statistical significance tests, error bars, or data exclusion criteria. Without these details the improvement cannot be verified and the central empirical claim remains unsupported.
- [Methodology section] Methodology section: the reproducible web-search/crawl procedure for the 200 sources is presented without any external validation or gold-standard comparison to assess systematic selection bias (e.g., over-representation of easily indexed pages or omission of paywalled/offline credibility documents). This assumption is load-bearing for the claim that the store yields genuinely higher-quality MBCs rather than artifacts of the retrieval process itself.
minor comments (2)
- Add a summary table listing the 200 sources together with document counts, update dates, and source-type distribution to improve transparency and reproducibility.
- [Abstract] The abstract would benefit from a single sentence stating the approximate total number of documents in MEDIAREF.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us identify areas for improvement in the manuscript. We address each major comment below.
read point-by-point responses
-
Referee: [Evaluation section] the claim that MEDIAREF 'supports higher-quality MBC generation through both automatic and qualitative evaluation' lacks any reported metrics, baselines, statistical significance tests, error bars, or data exclusion criteria. Without these details the improvement cannot be verified and the central empirical claim remains unsupported.
Authors: We agree that the evaluation section would benefit from more detailed reporting. The manuscript currently presents some automatic and qualitative results, but we acknowledge the lack of specific metrics, baselines, and statistical tests. In the revised manuscript, we will include quantitative metrics (e.g., ROUGE, BERTScore), baseline comparisons (e.g., against direct LLM generation without MEDIAREF), statistical significance tests, error bars where applicable, and explicit data exclusion criteria. This will make the empirical claims verifiable. revision: yes
-
Referee: [Methodology section] the reproducible web-search/crawl procedure for the 200 sources is presented without any external validation or gold-standard comparison to assess systematic selection bias (e.g., over-representation of easily indexed pages or omission of paywalled/offline credibility documents). This assumption is load-bearing for the claim that the store yields genuinely higher-quality MBCs rather than artifacts of the retrieval process itself.
Authors: We recognize the importance of validating the collection methodology against potential biases. The paper emphasizes reproducibility of the procedure, but we did not include external validation. We will add a new subsection discussing potential selection biases and provide a small-scale validation study comparing a sample of sources against established media bias databases (e.g., AllSides, Media Bias Fact Check). We will also note limitations regarding paywalled content. However, a full gold-standard for all 200 sources is beyond the scope of this work due to resource constraints. revision: partial
Circularity Check
Minor self-citation to prior MBC work; central contribution is independent public store release with evaluations
full rationale
The paper introduces MEDIAREF as a reproducible web-sourced collection for MBC generation across 200 sources and evaluates LLMs on it via automatic and qualitative methods to claim higher-quality output. The sole self-citation is to Schlichtkrull (2024) for background on the MBC task itself; this does not justify or reduce the main claims about the new store's utility or the evaluation results, which rest on the described collection methodology and experiments rather than any fitted parameter, self-definition, or load-bearing self-citation chain. No equations, predictions, or ansatzes appear that collapse to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Web-sourced documents from the selected 200 media sources are representative for evaluating source credibility in fact-checking tasks.
Reference graph
Works this paper leans on
-
[1]
2018 , publisher=
Misinformation and Mass Audiences , author=. 2018 , publisher=
2018
-
[3]
2019 , book_title =
Fact-checking as idea and practice in journalism , author =. 2019 , book_title =
2019
-
[5]
Nature human behaviour , volume=
Measuring the impact of COVID-19 vaccine misinformation on vaccination intent in the UK and USA , author=. Nature human behaviour , volume=. 2021 , publisher=
2021
-
[6]
Human Vaccines & Immunotherapeutics , volume =
Katherine Kricorian and Rachel Civen and Ozlem Equils , title =. Human Vaccines & Immunotherapeutics , volume =. 2022 , publisher =. doi:10.1080/21645515.2021.1950504 , note =
-
[7]
The Quest to Automate Fact-Checking , journal =
Hassan, Naeemul and Adair, Bill and Hamilton, James and Li, Chengkai and Tremayne, Mark and Yang, Jun and Yu, Cong , year =. The Quest to Automate Fact-Checking , journal =
-
[8]
Fact Checking: Task definition and dataset construction
Vlachos, Andreas and Riedel, Sebastian. Fact Checking: Task definition and dataset construction. Proceedings of the ACL 2014 Workshop on Language Technologies and Computational Social Science. 2014. doi:10.3115/v1/W14-2508
-
[10]
Resolving Conflicting Evidence in Automated Fact-Checking: A Study on Retrieval-Augmented LLMs , doi =
Ge, Ziyu and Wu, Yuhao and Chin, Daniel and Lee, Roy Ka-Wei and Cao, Rui , year =. Resolving Conflicting Evidence in Automated Fact-Checking: A Study on Retrieval-Augmented LLMs , doi =
-
[13]
The Fact Extraction and VER ification ( FEVER ) Shared Task
Thorne, James and Vlachos, Andreas and Cocarascu, Oana and Christodoulopoulos, Christos and Mittal, Arpit. The Fact Extraction and VER ification ( FEVER ) Shared Task. Proceedings of the First Workshop on Fact Extraction and VER ification ( FEVER ). 2018. doi:10.18653/v1/W18-5501
-
[14]
Salton, Gerard and Fox, Edward A. and Wu, Harry , title =. 1983 , issue_date =. doi:10.1145/182.358466 , journal =
-
[15]
Towards Debiasing Fact Verification Models
Schuster, Tal and Shah, Darsh and Yeo, Yun Jie Serene and Roberto Filizzola Ortiz, Daniel and Santus, Enrico and Barzilay, Regina. Towards Debiasing Fact Verification Models. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019....
-
[16]
2023 , eprint=
AVeriTeC: A Dataset for Real-world Claim Verification with Evidence from the Web , author=. 2023 , eprint=
2023
-
[18]
Missing Counter-Evidence Renders NLP Fact-Checking Unrealistic for Misinformation
Glockner, Max and Hou, Yufang and Gurevych, Iryna. Missing Counter-Evidence Renders NLP Fact-Checking Unrealistic for Misinformation. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.397
-
[20]
AIC CTU system at AV eri T e C : Re-framing automated fact-checking as a simple RAG task
Ullrich, Herbert and Mlyn \'a r , Tom \'a s and Drchal, Jan. AIC CTU system at AV eri T e C : Re-framing automated fact-checking as a simple RAG task. Proceedings of the Seventh Fact Extraction and VERification Workshop (FEVER). 2024. doi:10.18653/v1/2024.fever-1.16
-
[21]
H er O at AV eri T e C : The Herd of Open Large Language Models for Verifying Real-World Claims
Yoon, Yejun and Jung, Jaeyoon and Yoon, Seunghyun and Park, Kunwoo. H er O at AV eri T e C : The Herd of Open Large Language Models for Verifying Real-World Claims. Proceedings of the Seventh Fact Extraction and VERification Workshop (FEVER). 2024. doi:10.18653/v1/2024.fever-1.15
-
[22]
Dunamu-ml ' s Submissions on AVERITEC Shared Task
Park, Heesoo and Lee, Dongjun and Kim, Jaehyuk and Park, ChoongWon and Park, Changhwa. Dunamu-ml ' s Submissions on AVERITEC Shared Task. Proceedings of the Seventh Fact Extraction and VERification Workshop (FEVER). 2024. doi:10.18653/v1/2024.fever-1.7
-
[23]
Multi-hop Evidence Pursuit Meets the Web: Team Papelo at FEVER 2024
Malon, Christopher. Multi-hop Evidence Pursuit Meets the Web: Team Papelo at FEVER 2024. Proceedings of the Seventh Fact Extraction and VERification Workshop (FEVER). 2024. doi:10.18653/v1/2024.fever-1.2
-
[24]
METEOR : An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments
Banerjee, Satanjeev and Lavie, Alon. METEOR : An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. 2005
2005
-
[25]
B leu: a Method for Automatic Evaluation of Machine Translation
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing. B leu: a Method for Automatic Evaluation of Machine Translation. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. 2002. doi:10.3115/1073083.1073135
-
[26]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
2004
-
[27]
Taking MT Evaluation Metrics to Extremes: Beyond Correlation with Human Judgments
Fomicheva, Marina and Specia, Lucia. Taking MT Evaluation Metrics to Extremes: Beyond Correlation with Human Judgments. Computational Linguistics. 2019. doi:10.1162/coli_a_00356
-
[30]
Arabzadeh, Negar and Yan, Xinyi and Clarke, Charles L. A. , title =. Proceedings of the 30th ACM International Conference on Information & Knowledge Management , pages =. 2021 , isbn =. doi:10.1145/3459637.3482159 , abstract =
-
[31]
Transactions of the Association for Computational Linguistics , volume =
Luan, Yi and Eisenstein, Jacob and Toutanova, Kristina and Collins, Michael , title =. Transactions of the Association for Computational Linguistics , volume =. 2021 , month =. doi:10.1162/tacl_a_00369 , url =
-
[32]
Daniel Jurafsky and James H. Martin. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition with Language Models. 2025
2025
-
[33]
2021 , eprint=
DeBERTa: Decoding-enhanced BERT with Disentangled Attention , author=. 2021 , eprint=
2021
-
[34]
THE DECODER , author=
GPT-4 architecture, datasets, costs and more leaked , url=. THE DECODER , author=. 2023 , month=
2023
-
[36]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[37]
2019 , url=
Language Models are Unsupervised Multitask Learners , author=. 2019 , url=
2019
-
[38]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[39]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v...
-
[41]
e and Osman, Magda and Bechlivanidis, Christos and Meder, Bj \
Adams, Zo \"e and Osman, Magda and Bechlivanidis, Christos and Meder, Bj \"o rn. (Why) Is Misinformation a Problem?. Perspect Psychol Sci
-
[42]
Communication Research , volume=
Credibility perceptions and detection accuracy of fake news headlines on social media: Effects of truth-bias and endorsement cues , author=. Communication Research , volume=. 2022 , publisher=
2022
-
[43]
Axios , author=
News engagement plummets as Americans tune out , url=. Axios , author=. 2022 , month=
2022
-
[44]
Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , articleno =
Warren, Greta and Shklovski, Irina and Augenstein, Isabelle , title =. Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , articleno =. 2025 , isbn =
2025
-
[45]
Generating Fact Checking Briefs
Fan, Angela and Piktus, Aleksandra and Petroni, Fabio and Wenzek, Guillaume and Saeidi, Marzieh and Vlachos, Andreas and Bordes, Antoine and Riedel, Sebastian. Generating Fact Checking Briefs. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.580
-
[46]
State of the Fact-Checkers Report - 2024
Nyariki, Enock. State of the Fact-Checkers Report - 2024
2024
-
[47]
State of the Fact-Checkers Report - 2025
Nyariki, Enock. State of the Fact-Checkers Report - 2025
2025
-
[48]
ACM Computing Surveys , volume=
Natural language reasoning, a survey , author=. ACM Computing Surveys , volume=. 2024 , publisher=
2024
-
[49]
Psychological science in the public interest , volume=
Misinformation and its correction: Continued influence and successful debiasing , author=. Psychological science in the public interest , volume=. 2012 , publisher=
2012
-
[51]
Factuality challenges in the era of large language models and opportunities for fact-checking
Augenstein, Isabelle and Baldwin, Timothy and Cha, Meeyoung and Chakraborty, Tanmoy and Ciampaglia, Giovanni Luca and Corney, David and DiResta, Renee and Ferrara, Emilio and Hale, Scott and Halevy, Alon and Hovy, Eduard and Ji, Heng and Menczer, Filippo and Miguez, Ruben and Nakov, Preslav and Scheufele, Dietram and Sharma, Shivam and Zagni, Giovanni. Fa...
-
[52]
Conformity in Large Language Models
Zhu, Xiaochen and Zhang, Caiqi and Stafford, Tom and Collier, Nigel and Vlachos, Andreas. Conformity in Large Language Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.195
-
[53]
SIGIR Forum , month = jul, articleno =
Metzler, Donald and Tay, Yi and Bahri, Dara and Najork, Marc , title =. SIGIR Forum , month = jul, articleno =. 2021 , issue_date =. doi:10.1145/3476415.3476428 , abstract =
-
[54]
Text Retrieval Conference , year=
Okapi at TREC-3 , author=. Text Retrieval Conference , year=
-
[55]
2025 , eprint=
OpenAI GPT-5 System Card , author=. 2025 , eprint=
2025
-
[57]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[58]
2024 , url =
Llama 3 Model Card , author=. 2024 , url =
2024
-
[59]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[64]
Free-Marginal Multirater Kappa (multirater κfree): An Alternative to Fleiss Fixed-Marginal Multirater Kappa , volume =
Randolph, Justus , year =. Free-Marginal Multirater Kappa (multirater κfree): An Alternative to Fleiss Fixed-Marginal Multirater Kappa , volume =
-
[65]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[68]
2025 , institution=
Adversarial Machine Learning: A Taxonomy and Terminology of Attacks and Mitigations , author=. 2025 , institution=
2025
-
[70]
AI@Meta. 2024. https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md Llama 3 model card
2024
-
[71]
Mubashara Akhtar, Rami Aly, Yulong Chen, Zhenyun Deng, Michael Schlichtkrull, Chenxi Whitehouse, and Andreas Vlachos. 2025. https://doi.org/10.18653/v1/2025.fever-1.15 The 2nd automated verification of textual claims ( AV eri T e C ) shared task: Open-weights, reproducible and efficient systems . In Proceedings of the Eighth Fact Extraction and VERificati...
-
[72]
Hunt Allcott and Matthew Gentzkow. 2017. https://doi.org/10.1257/jep.31.2.211 Social media and fake news in the 2016 election . Journal of Economic Perspectives, 31(2):211–36
-
[73]
Anthropic. 2024. https://assets.anthropic.com/m/1cd9d098ac3e6467/original/Claude-3-Model-Card-October-Addendum.pdf Model card addendum: Claude 3.5 haiku and upgraded claude 3.5 sonnet
2024
-
[74]
Ramy Baly, Georgi Karadzhov, Dimitar Alexandrov, James Glass, and Preslav Nakov. 2018. https://doi.org/10.18653/v1/D18-1389 Predicting factuality of reporting and bias of news media sources . In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 3528--3539, Brussels, Belgium. Association for Computational Linguistics
-
[75]
Ramy Baly, Georgi Karadzhov, Abdelrhman Saleh, James Glass, and Preslav Nakov. 2019. https://doi.org/10.18653/v1/N19-1216 Multi-task ordinal regression for jointly predicting the trustworthiness and the leading political ideology of news media . In Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Lingu...
-
[76]
Satanjeev Banerjee and Alon Lavie. 2005. https://aclanthology.org/W05-0909/ METEOR : An automatic metric for MT evaluation with improved correlation with human judgments . In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization , pages 65--72, Ann Arbor, Michigan. Association for Compu...
2005
-
[77]
Adrien Barbaresi. 2021. https://doi.org/10.18653/v1/2021.acl-demo.15 Trafilatura: A web scraping library and command-line tool for text discovery and extraction . In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations, page...
-
[78]
Rui Cao, Yulong Chen, Zhenyun Deng, Michael Schlichtkrull, and Andreas Vlachos. 2026. https://doi.org/10.18653/v1/2026.fever-1.6 The automatic verification of image-text claims ( AV er I ma T e C ) shared task . In Proceedings of the Ninth Fact Extraction and VER ification Workshop ( FEVER ) , pages 74--90, Rabat, Morocco. Association for Computational Li...
-
[79]
Ziyu Ge, Yuhao Wu, Daniel Chin, Roy Ka-Wei Lee, and Rui Cao. 2025. https://doi.org/10.48550/arXiv.2505.17762 Resolving conflicting evidence in automated fact-checking: A study on retrieval-augmented llms
-
[80]
L Graves and M Amazeen. 2019. Fact-checking as idea and practice in journalism. Oxford Research Encyclopedias. Oxford University Press
2019
-
[81]
Zhijiang Guo, Michael Schlichtkrull, and Andreas Vlachos. 2022. https://doi.org/10.1162/tacl_a_00454 A survey on automated fact-checking . Transactions of the Association for Computational Linguistics, 10:178--206
-
[82]
Naeemul Hassan, Bill Adair, James Hamilton, Chengkai Li, Mark Tremayne, Jun Yang, and Cong Yu. 2015. The quest to automate fact-checking. Proceedings of the 2015 Computation + Journalism Symposium
2015
-
[83]
Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. 2021. https://arxiv.org/abs/2006.03654 Deberta: Decoding-enhanced bert with disentangled attention . Preprint, arXiv:2006.03654
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[84]
Giwon Hong, Jeonghwan Kim, Junmo Kang, Sung-Hyon Myaeng, and Joyce Jiyoung Whang. 2024. https://doi.org/10.18653/v1/2024.findings-naacl.159 Why so gullible? enhancing the robustness of retrieval-augmented models against counterfactual noise . In Findings of the Association for Computational Linguistics: NAACL 2024, pages 2474--2495, Mexico City, Mexico. A...
-
[85]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. https://arxiv.org/abs/2310.0...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[86]
Yichen Jiang, Shikha Bordia, Zheng Zhong, Charles Dognin, Maneesh Singh, and Mohit Bansal. 2020. https://doi.org/10.18653/v1/2020.findings-emnlp.309 H o V er: A dataset for many-hop fact extraction and claim verification . In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 3441--3460, Online. Association for Computational Linguistics
-
[87]
Heather Lent, Erick Galinkin, Yiyi Chen, Jens Myrup Pedersen, Leon Derczynski, and Johannes Bjerva. 2025. https://doi.org/10.1162/tacl_a_00762 NLP security and ethics, in the wild . Transactions of the Association for Computational Linguistics, 13:709--743
-
[88]
u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K \"u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \"a schel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems, 33:9459--9474
2020
-
[89]
Chin-Yew Lin. 2004. https://aclanthology.org/W04-1013/ ROUGE : A package for automatic evaluation of summaries . In Text Summarization Branches Out, pages 74--81, Barcelona, Spain. Association for Computational Linguistics
2004
-
[90]
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.741 FA ct S core: Fine-grained atomic evaluation of factual precision in long form text generation . In Proceedings of the 2023 Conference on Empirical Methods in Natural Langua...
-
[91]
Preslav Nakov, Jisun An, Haewoon Kwak, Muhammad Arslan Manzoor, Zain Muhammad Mujahid, and Husrev Taha Sencar. 2024. https://doi.org/10.18653/v1/2024.findings-acl.944 A survey on predicting the factuality and the bias of news media . In Findings of the Association for Computational Linguistics: ACL 2024, pages 15947--15962, Bangkok, Thailand. Association ...
-
[92]
Enock Nyariki. 2025. State of the fact-checkers report - 2025. https://www.poynter.org/wp-content/uploads/2026/03/2026-State-of-Fact-Checkers-4.pdf. Accessed: 2026-5-22
2025
-
[93]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, et al. 2024. https://arxiv.org/abs/2303.08774 Gpt-4 technical report . Preprint, arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[94]
Nedjma Ousidhoum, Zhangdie Yuan, and Andreas Vlachos. 2022. https://doi.org/10.18653/v1/2022.emnlp-main.163 Varifocal question generation for fact-checking . In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 2532--2544, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics
-
[95]
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. https://api.semanticscholar.org/CorpusID:160025533 Language models are unsupervised multitask learners
2019
-
[96]
Justus Randolph. 2010. Free-marginal multirater kappa (multirater κfree): An alternative to fleiss fixed-marginal multirater kappa. volume 4
2010
-
[97]
Robertson, Steve Walker, Susan Jones, Micheline Hancock-Beaulieu, and Mike Gatford
Stephen E. Robertson, Steve Walker, Susan Jones, Micheline Hancock-Beaulieu, and Mike Gatford. 1994. https://api.semanticscholar.org/CorpusID:41563977 Okapi at trec-3 . In Text Retrieval Conference
1994
-
[98]
Mark Rothermel, Tobias Braun, Marcus Rohrbach, and Anna Rohrbach. 2024. https://doi.org/10.18653/v1/2024.fever-1.12 I n F act: A strong baseline for automated fact-checking . In Proceedings of the Seventh Fact Extraction and VERification Workshop (FEVER), pages 108--112, Miami, Florida, USA. Association for Computational Linguistics
-
[99]
Michael Schlichtkrull. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.283 Generating media background checks for automated source critical reasoning . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 4927--4947, Miami, Florida, USA. Association for Computational Linguistics
-
[100]
Michael Schlichtkrull, Yulong Chen, Chenxi Whitehouse, Zhenyun Deng, Mubashara Akhtar, Rami Aly, Zhijiang Guo, Christos Christodoulopoulos, Oana Cocarascu, Arpit Mittal, James Thorne, and Andreas Vlachos. 2024. https://doi.org/10.18653/v1/2024.fever-1.1 The automated verification of textual claims ( AV eri T e C ) shared task . In Proceedings of the Seven...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.