WattGPU: Predicting Inference Power and Latency on Unseen GPUs and LLMs
Pith reviewed 2026-07-03 05:40 UTC · model grok-4.3
The pith
WattGPU models predict power draw and latency for LLM inference on unseen GPUs using only public metadata and specs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
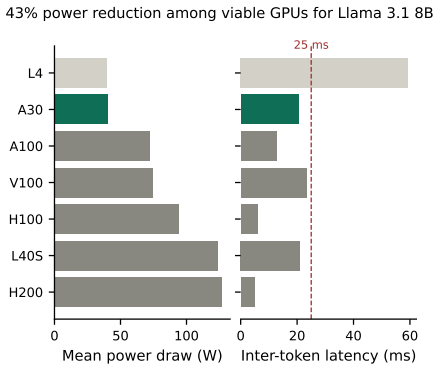
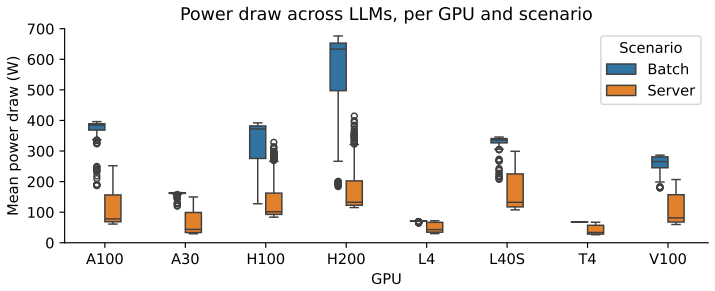
WattGPU introduces two predictive models for mean GPU power draw and inter-token latency that rely exclusively on publicly available LLM metadata and GPU specifications. Leave-one-GPU-out and leave-one-LLM-out cross-validation on 42 open-source models (0.1B to 27B parameters) and 8 GPUs demonstrates generalization to unseen NVIDIA server-grade hardware in both offline and server inference scenarios. The power model reaches median absolute percentage errors of at most 3.4 percent offline and 13.5 percent server-side on unseen GPUs; the latency model reaches 8.5 percent in server mode, with Kendall tau correlations of at least 0.76 for GPU rankings. These figures represent error reductions of
What carries the argument
Two machine learning models that map public LLM metadata and GPU specifications directly to mean power draw and inter-token latency.
If this is right
- Operators gain the ability to evaluate many LLM-GPU pairings for energy efficiency without running profiling workloads on each combination.
- GPU rankings for server scenarios remain reliable enough for selection decisions even when absolute errors are present.
- Energy estimates improve by factors of two to four over load-scaled TDP and roofline methods on unseen combinations.
- The same public-data approach applies across both offline batch and online server inference workloads.
Where Pith is reading between the lines
- Similar models could be trained for non-NVIDIA accelerators if equivalent public specification data become available.
- Embedding these predictors into cluster schedulers could automate energy-aware placement of inference jobs at scale.
- Testing the models on models larger than 27B parameters would reveal whether prediction accuracy holds as model size increases.
- The technique opens a path to system-level simulations that combine many such predictions to forecast data-center power demand.
Load-bearing premise
The cross-validation performance observed on the 42 LLMs and 8 GPUs will generalize to arbitrary new GPUs and LLMs in actual server and offline deployments.
What would settle it
Collecting real power and latency measurements on an NVIDIA GPU and LLM pair absent from the original dataset and observing median absolute percentage errors substantially above 13.5 percent for power or 8.5 percent for latency.
Figures
read the original abstract
Large Language Model (LLM) inference workloads are a rapidly growing contributor to data center energy consumption. Optimizing these deployments requires matching specific LLMs to the most efficient GPUs, but operators currently lack the tools to do so without exhaustively profiling each combination. While some predictive models exist, they still require profiling data and struggle to generalize to hardware unseen during training. To address this, we introduce \textit{WattGPU}, featuring two predictive models for mean GPU power draw and Inter-Token Latency (ITL). Our approach leverages only publicly available LLM metadata and GPU specifications, eliminating the need for hardware access or profiling while enabling generalization to unseen NVIDIA server-grade GPUs and LLMs. We evaluate our models using rigorous leave-one-GPU-out and leave-one-LLM-out cross-validation on a dataset of 42 open-source LLMs (0.1B--27B parameters) and 8 GPUs under both offline and server scenarios. The mean power draw model achieves a median absolute percentage error of $\leq3.4\%$ for offline and $\leq13.5\%$ for server scenarios on unseen GPUs, while the latency model achieves $\leq8.5\%$ in server mode, both maintaining strong GPU ranking correlations for server scenarios (Kendall $\tau\geq0.76$). Compared to standard physically grounded baselines -- Load-Scaled Thermal Design Power (TDP) for power draw and roofline for latency -- our models reduce median absolute percentage error by approximately 4$\times$ on unseen LLM-GPU combinations for server scenarios or approximately 2$\times$ for completely unseen GPUs. WattGPU's data and code are publicly available at https://github.com/maufadel/wattgpu.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WattGPU, consisting of two ML models that predict mean GPU power draw and inter-token latency (ITL) for LLM inference workloads. The models use only publicly available LLM metadata and GPU specifications (no profiling required) and are evaluated via leave-one-GPU-out and leave-one-LLM-out cross-validation on 42 LLMs (0.1B–27B parameters) and 8 GPUs under offline and server scenarios. Reported results include median absolute percentage error ≤3.4% (offline power), ≤13.5% (server power), and ≤8.5% (server latency) on held-out items, with Kendall τ ≥0.76 for rankings and 2–4× error reduction versus TDP and roofline baselines.
Significance. If the generalization claims hold, the work offers a practical, profiling-free method for matching LLMs to efficient GPUs, which could meaningfully reduce data-center energy consumption for inference. Public release of data and code at the cited GitHub repository is a clear strength for reproducibility and further testing.
major comments (2)
- [Abstract / evaluation] Abstract and evaluation description: leave-one-GPU-out CV is conducted on only 8 GPUs total (training on 7 per fold). This sample size is load-bearing for the central claim of generalization to arbitrary unseen NVIDIA server-grade GPUs, because any shared traits (e.g., similar SM counts, memory hierarchies, or TDP scaling among the chosen cards) could be implicitly captured by the feature-based regressor rather than learned from public specs alone; the reported 2–4× error reductions versus baselines may therefore be specific to this narrow distribution.
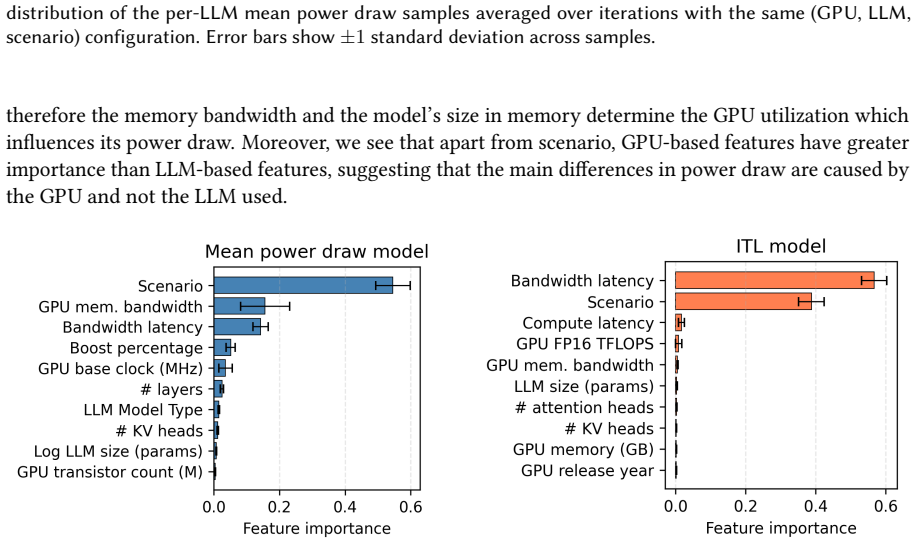
- [Abstract] Abstract: the claim that the models 'enable generalization to unseen NVIDIA server-grade GPUs and LLMs' rests on the public-spec features being sufficient; however, with N=8 GPUs the paper must demonstrate (via feature ablation or diversity analysis) that the regressor is not simply memorizing the sampled hardware cluster.
minor comments (1)
- [Abstract] The abstract states Kendall τ ≥0.76 for server scenarios but does not clarify whether this holds for both power and latency models or only one; a table or explicit breakdown would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments on the evaluation setup and generalization claims. We address each major comment below, acknowledging the inherent limitations of our dataset while outlining concrete revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / evaluation] Abstract and evaluation description: leave-one-GPU-out CV is conducted on only 8 GPUs total (training on 7 per fold). This sample size is load-bearing for the central claim of generalization to arbitrary unseen NVIDIA server-grade GPUs, because any shared traits (e.g., similar SM counts, memory hierarchies, or TDP scaling among the chosen cards) could be implicitly captured by the feature-based regressor rather than learned from public specs alone; the reported 2–4× error reductions versus baselines may therefore be specific to this narrow distribution.
Authors: We agree that N=8 GPUs represents a genuine limitation for claiming generalization to arbitrary unseen NVIDIA server-grade GPUs, as shared architectural traits within this set could influence results. The GPUs span multiple generations (Ampere, Ada, Hopper) with substantial variation in SM counts, memory capacity/bandwidth, and TDP, as listed in the manuscript's GPU table. The feature set is restricted to public specifications precisely to capture these differences. Nevertheless, the small sample size weakens the strength of the central claim, and we will add an explicit discussion of this limitation plus a diversity analysis of the GPU feature space (e.g., pairwise distances and clustering on public specs) in the revised manuscript to show the set is not narrowly clustered. revision: partial
-
Referee: [Abstract] Abstract: the claim that the models 'enable generalization to unseen NVIDIA server-grade GPUs and LLMs' rests on the public-spec features being sufficient; however, with N=8 GPUs the paper must demonstrate (via feature ablation or diversity analysis) that the regressor is not simply memorizing the sampled hardware cluster.
Authors: We will add both requested analyses in the revision. First, a feature ablation study will quantify the contribution of GPU-specific public features (e.g., SM count, memory bandwidth, TDP) by retraining with subsets removed and reporting the resulting error increases. Second, we will include a diversity analysis section that examines the distribution and variance of the 8 GPUs across public specifications to demonstrate they do not form a tight cluster. These additions will provide direct evidence that performance derives from the public features rather than memorization of the sampled set. revision: yes
Circularity Check
No circularity; standard ML training + CV on public features
full rationale
The paper trains supervised regressors on profiling data collected from 42 LLMs and 8 GPUs, using only public metadata and spec features as inputs, then reports leave-one-GPU-out and leave-one-LLM-out CV errors. This is ordinary empirical modeling with held-out evaluation; no equation reduces to its own fitted parameters by construction, no self-citation chain carries the central claim, and no ansatz or uniqueness result is smuggled in. The derivation is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- ML model parameters
Reference graph
Works this paper leans on
-
[1]
URL: https://www.iea.org/reports/energy-and-ai, license: CC BY 4.0
International Energy Agency, Energy and AI, Technical Report, International Energy Agency, Paris, 2025. URL: https://www.iea.org/reports/energy-and-ai, license: CC BY 4.0
2025
-
[2]
Y. Lei, J. Fernandez, V. Kypriotis, D. Skarlatos, E. Strubell, J. Sherry, D. Vosler, The energy cost of execution-idle in gpu clusters, arXiv preprint arXiv:2604.04745 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Theodorou, S
G. Theodorou, S. Karagiorgou, C. Kotronis, On energy-aware and verifiable benchmarking of big data processing targeting ai pipelines, in: 2024 IEEE International Conference on Big Data (BigData), IEEE, 2024, pp. 3788–3798
2024
-
[4]
Burian, A
V. Burian, A. Stalla -Bourdillon, The increasing energy demand of artificial intelligence and its impact on commodity prices, Economic Bulletin,FocusBox 2/2025, European Cen- tral Bank, 2025. URL: https://www.ecb.europa.eu/press/economic-bulletin/focus/2025/html/ecb. ebbox202502_03~8eba688e29.en.html, accessed: 2025-07-31
2025
-
[5]
Strubell, A
E. Strubell, A. Ganesh, A. McCallum, Energy and policy considerations for modern deep learning research, in: Proceedings of the AAAI conference on artificial intelligence, 09, 2020, pp. 13693– 13696
2020
-
[6]
Samsi, D
S. Samsi, D. Zhao, J. McDonald, B. Li, A. Michaleas, M. Jones, W. Bergeron, J. Kepner, D. Tiwari, V. Gadepally, From words to watts: Benchmarking the energy costs of large language model inference, in: 2023 IEEE High Performance Extreme Computing Conference (HPEC), IEEE, 2023, pp. 1–9
2023
-
[7]
M. F. Argerich, M. Patiño-Martínez, Measuring and improving the energy efficiency of large language models inference, IEEE Access (2024)
2024
-
[8]
Tschand, A
A. Tschand, A. T. R. Rajan, S. Idgunji, A. Ghosh, J. Holleman, C. Kiraly, P. Ambalkar, R. Borkar, R. Chukka, T. Cockrell, et al., Mlperf power: Benchmarking the energy efficiency of machine learning systems from 𝜇watts to mwatts for sustainable ai, in: 2025 IEEE International Symposium on High Performance Computer Architecture (HPCA), IEEE, 2025, pp. 1201–1216
2025
-
[9]
Luccioni, B
S. Luccioni, B. Gamazaychikov, E. Strubell, S. Hooker, Y. Jernite, M. Mitchell, S. Chamberlin, Ai energy score leaderboard - december 2025, https://huggingface.co/spaces/AIEnergyScore/ Leaderboard, 2025
2025
-
[10]
Chung, J
J.-W. Chung, J. J. Ma, R. Wu, J. Liu, O. J. Kweon, Y. Xia, Z. Wu, M. Chowdhury, The ML.ENERGY benchmark: Toward automated inference energy measurement and optimization, in: NeurIPS Datasets and Benchmarks, 2025
2025
-
[11]
C. Niu, W. Zhang, J. Li, Y. Zhao, T. Wang, X. Wang, Y. Chen, Tokenpowerbench: Benchmarking the power consumption of llm inference, in: Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, 2026, pp. 32582–32590
2026
- [12]
-
[13]
Z. Fu, F. Chen, S. Zhou, H. Li, L. Jiang, Llmco2: Advancing accurate carbon footprint prediction for llm inferences, ACM SIGENERGY Energy Informatics Review 5 (2025) 63–68
2025
-
[14]
Wilkins, S
G. Wilkins, S. Keshav, R. Mortier, Offline energy-optimal llm serving: Workload-based energy models for llm inference on heterogeneous systems, ACM SIGENERGY Energy Informatics Review 4 (2024) 113–119
2024
-
[15]
A. K. Kakolyris, D. Masouros, P. Vavaroutsos, S. Xydis, D. Soudris, throttll’em: Predictive gpu throttling for energy efficient llm inference serving, in: 2025 IEEE International Symposium on High Performance Computer Architecture (HPCA), IEEE, 2025, pp. 1363–1378
2025
-
[16]
R. Patwari, A. Sirasao, D. Das, Forecasting llm inference performance via hardware-agnostic analytical modeling, arXiv preprint arXiv:2508.00904 (2025)
-
[17]
Agrawal, N
A. Agrawal, N. Kedia, J. Mohan, A. Panwar, N. Kwatra, B. S. Gulavani, R. Ramjee, A. Tumanov, Vidur: A large-scale simulation framework for llm inference, Proceedings of Machine Learning and Systems 6 (2024) 351–366
2024
- [18]
-
[19]
S. Imai, R. Nakazawa, M. Amaral, S. Choochotkaew, T. Chiba, Predicting llm inference latency: A roofline-driven ml method, in: Annual Conference on Neural Information Processing Systems, 2024
2024
-
[20]
Rincé, A
S. Rincé, A. Banse, Ecologits: Evaluating the environmental impacts of generative ai, Journal of Open Source Software 10 (2025) 7471
2025
-
[21]
F. Caravaca, Á. Cuevas, R. Cuevas, From prompts to power: Measuring the energy footprint of llm inference, arXiv preprint arXiv:2511.05597 (2025)
-
[22]
M. F. Argerich, J. Fürst, M. Patiño-Martínez, Watt counts: Energy-aware benchmark for sustainable llm inference on heterogeneous gpu architectures, arXiv preprint arXiv:2604.09048 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.