Read the Trace, Steer the Path: Trajectory-Aware Reinforcement Learning for Diffusion Language Models
Pith reviewed 2026-06-28 06:57 UTC · model grok-4.3
The pith
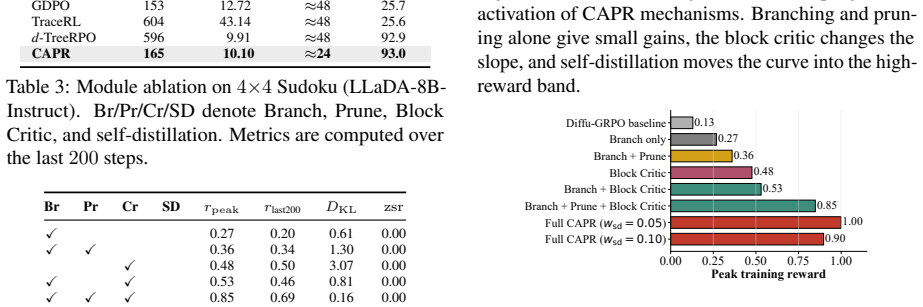
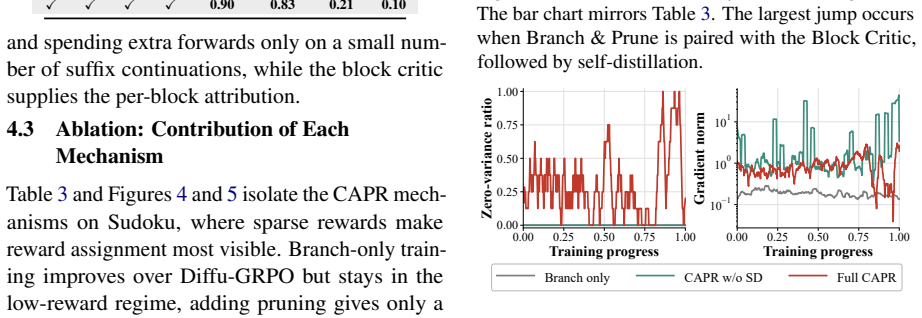
CAPR turns the denoising trace of diffusion LLMs into block-level rewards that recover tree-search granularity at lower cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
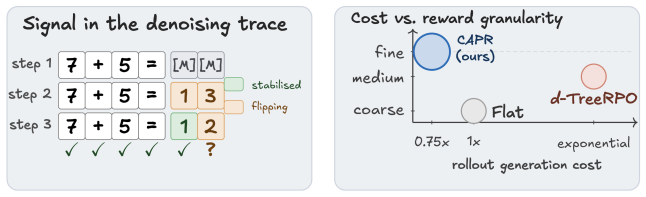
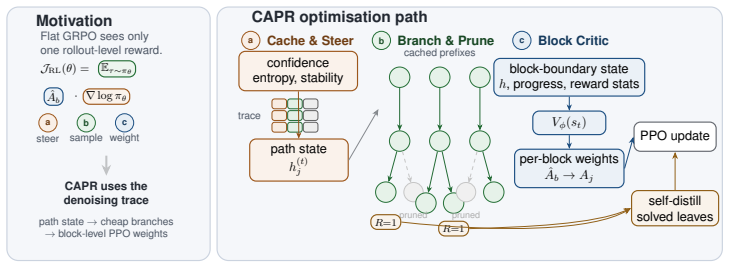
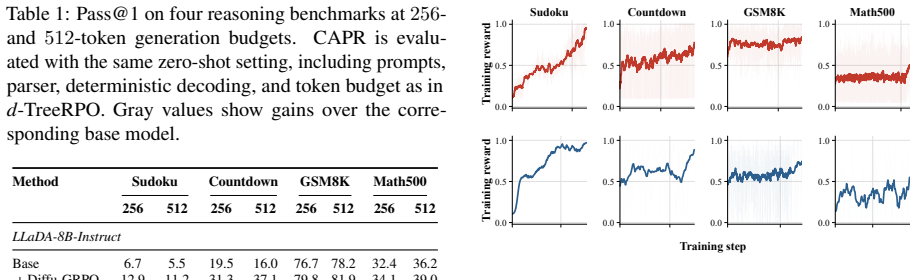
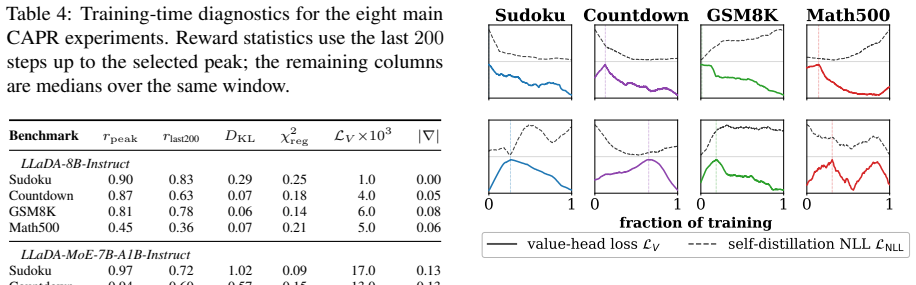
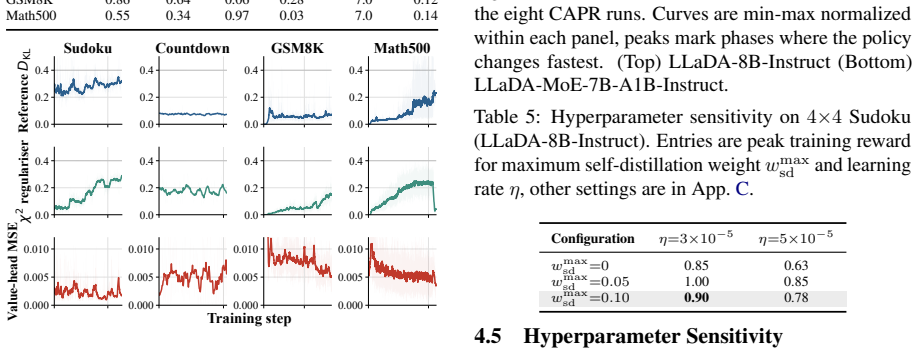
CAPR records path-state and block-progress features under a block-wise unmasking schedule, then redistributes the final outcome reward across blocks according to the tokens revealed in each block. This trains the value head to convert one sparse reward into block-level PPO weights, recovering much of the granularity of tree search while avoiding full tree expansion and reducing rollout-generation cost to roughly 0.75x that of flat rollouts and 0.6x that of tree rollouts.
What carries the argument
Cached-Amortized Path Refinement (CAPR), which summarizes the denoising trace into a compact path state, caches trajectory states for cheap sibling continuations, and trains a block-level value head from redistributed outcome rewards.
If this is right
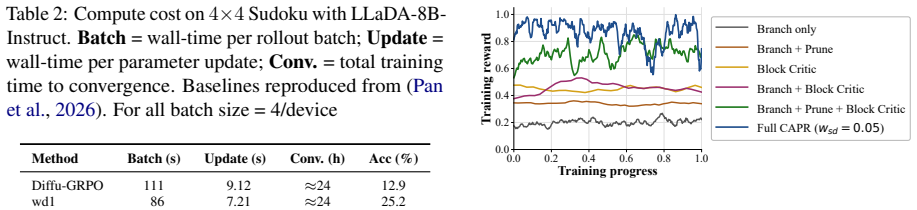
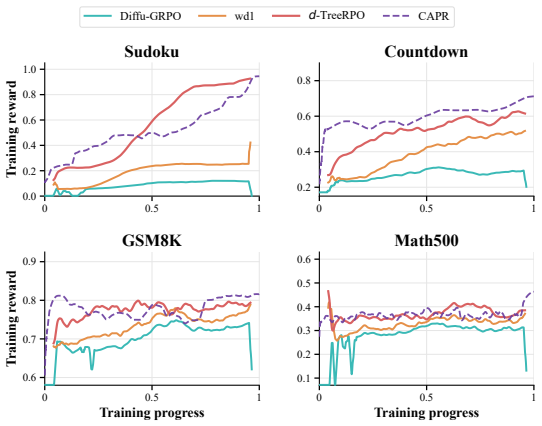
- CAPR sets a new state of the art for RL-tuned dLLMs on 4x4 Sudoku, Countdown, GSM8K, and Math500 at 256- and 512-token budgets on both dense and mixture-of-experts LLaDA backbones.
- Rollout-generation cost falls to roughly 0.75x flat rollouts and 0.6x tree rollouts under standard settings.
- On Sudoku the method matches the strongest tree-structured baseline at less than one third of the per-step compute.
- The approach works by training a block-level value head that supplies PPO weights from a single sparse outcome reward.
Where Pith is reading between the lines
- The same trace-to-block-reward mapping could be tested on other iterative generative models that produce internal confidence sequences during sampling.
- If the redistribution rule introduces schedule-dependent bias, performance would degrade when the block size or unmasking order changes.
- The cached path-state representation may allow combining CAPR with other search methods that operate on partial trajectories.
Load-bearing premise
Redistributing the final outcome reward across blocks according to the tokens revealed in each block under a block-wise unmasking schedule yields accurate local value estimates that approximate full tree supervision without systematic bias.
What would settle it
A direct comparison on a small task where the learned block-level value head predictions show low correlation with the actual rewards obtained by expanding the same blocks into complete trajectories would falsify the accuracy of the redistributed supervision.
Figures

read the original abstract
Diffusion large language models (dLLMs) generate responses by iteratively unmasking and revising many positions in parallel. This process leaves a rich denoising trace depicting which tokens become confident, which remain unstable, and when commitments form. Existing dLLM reinforcement learning methods use this signal only weakly. Flat rollouts are cheap, but assign a single outcome reward to the whole trajectory. Tree rollouts provide finer, verifiable training signals by branching partial trajectories and propagating leaf rewards upward, but are compute intensive. We ask whether the denoising trace itself can provide tree-like supervision without tree-level compute. We introduce CAPR (Cached-Amortized Path Refinement), a dLLM-RL algorithm that summarizes the denoising trace into a compact path state, uses cached trajectory states to generate cheap sibling continuations, and trains a block-level value head for local block-wise supervision. Under a block-wise unmasking schedule, CAPR records path-state and block-progress features, then redistributes the final outcome reward across blocks according to the tokens revealed in each block. This trains the value head to convert one sparse reward into block-level PPO weights. CAPR therefore recovers much of the granularity of tree search while avoiding full tree expansion, reducing rollout-generation cost to roughly 0.75x that of flat rollouts and 0.6x that of tree rollouts (under standard settings). Across 4x4 Sudoku, Countdown, GSM8K, and Math500, on dense and mixture-of-experts LLaDA backbones, CAPR sets a new state of the art for RL-tuned dLLMs at 256- and 512-token budgets. On Sudoku, it matches the strongest tree-structured baseline at less than one third of the per-step compute.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CAPR (Cached-Amortized Path Refinement), an RL algorithm for diffusion LLMs that summarizes the denoising trace into a path state, uses cached states for sibling continuations, and redistributes the terminal outcome reward across blocks proportional to tokens revealed under a block-wise unmasking schedule to train a block-level value head for PPO. It claims this recovers much of tree-search granularity at reduced cost (roughly 0.75x flat rollouts and 0.6x tree rollouts) while setting SOTA for RL-tuned dLLMs on 4x4 Sudoku, Countdown, GSM8K, and Math500 across dense and MoE LLaDA backbones at 256- and 512-token budgets.
Significance. If the reward-redistribution mechanism produces value estimates sufficiently close to explicit tree supervision without systematic bias, the work would offer a practical efficiency gain for fine-grained RL in dLLMs, lowering the barrier to tree-like training signals. The caching and trace-summarization ideas are a concrete algorithmic contribution that could generalize beyond the reported tasks.
major comments (2)
- [Abstract / method description] The central mechanism—redistributing the final outcome reward across blocks according to tokens revealed in each block under the chosen unmasking schedule—is presented as yielding local value estimates that approximate tree-rollout supervision. No comparison to explicit tree-search value estimates, no ablation on schedule parameters, and no analysis of potential bias from early-block credit assignment or caching of sibling states is provided to support this equivalence, which is required for the claimed 0.6–0.75× cost reduction with preserved granularity.
- [Results (implied from abstract claims)] The SOTA and cost-reduction claims (0.75x flat, 0.6x tree; matching strongest tree baseline on Sudoku at <1/3 per-step compute) are stated without error bars, statistical significance tests, or ablation tables isolating the contribution of the block-wise value head versus the caching mechanism.
minor comments (2)
- The phrase 'under standard settings' for the cost ratios is undefined; explicit hyperparameter values or a reference table for the unmasking schedule and cache size would improve reproducibility.
- Notation for 'path-state and block-progress features' is introduced without an accompanying equation or pseudocode snippet, making the exact input to the value head unclear.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below, outlining clarifications from the manuscript and planned revisions to strengthen the supporting evidence for the method's claims.
read point-by-point responses
-
Referee: [Abstract / method description] The central mechanism—redistributing the final outcome reward across blocks according to tokens revealed in each block under the chosen unmasking schedule—is presented as yielding local value estimates that approximate tree-rollout supervision. No comparison to explicit tree-search value estimates, no ablation on schedule parameters, and no analysis of potential bias from early-block credit assignment or caching of sibling states is provided to support this equivalence, which is required for the claimed 0.6–0.75× cost reduction with preserved granularity.
Authors: The manuscript motivates the redistribution mechanism via the denoising trace properties and demonstrates its utility through SOTA results on four benchmarks with the stated compute savings. We agree, however, that direct validation of the approximation quality would strengthen the equivalence claim. In revision we will add a dedicated analysis subsection that (i) compares CAPR block-level value estimates against explicit tree-search values on Sudoku and GSM8K subsets, (ii) ablates block size and unmasking schedule parameters, and (iii) quantifies bias from early-block credit assignment and sibling-state caching. These additions will directly support the reported cost reductions. revision: yes
-
Referee: [Results (implied from abstract claims)] The SOTA and cost-reduction claims (0.75x flat, 0.6x tree; matching strongest tree baseline on Sudoku at <1/3 per-step compute) are stated without error bars, statistical significance tests, or ablation tables isolating the contribution of the block-wise value head versus the caching mechanism.
Authors: The current manuscript reports point estimates for the performance and compute metrics. We acknowledge that statistical rigor and component isolation are needed. The revised version will include error bars from multiple random seeds, paired statistical significance tests against baselines, and ablation tables that separately measure the block-wise value head and the caching mechanism. These will appear in the main results and appendix. revision: yes
Circularity Check
No significant circularity; CAPR is an independent algorithmic proposal
full rationale
The paper presents CAPR as a new RL algorithm for dLLMs that processes the external denoising trace under a block-wise unmasking schedule to redistribute a terminal reward into block-level value estimates for PPO. No equations, fitted parameters, or self-citations are shown that reduce the claimed supervision or compute savings to the inputs by construction. The method is framed as using the generation trace as an independent signal rather than re-deriving quantities from the same data or prior author results. This is the most common honest finding for algorithmic papers that do not invoke uniqueness theorems or ansatzes from self-citations.
Axiom & Free-Parameter Ledger
free parameters (1)
- block-wise unmasking schedule parameters
axioms (1)
- domain assumption The denoising trace contains sufficient information to support block-level value estimates approximating tree search
Reference graph
Works this paper leans on
-
[1]
Sdar: A synergistic diffusion-autoregression paradigm for scalable sequence generation.Preprint, arXiv:2510.06303. Kyunghyun Cho, Bart van Merriënboer, Caglar Gul- cehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. 2014. Learning phrase representations using RNN encoder–decoder for statistical machine translation. InProceedings of...
arXiv 2014
-
[2]
Training verifiers to solve math word prob- lems.Preprint, arXiv:2110.14168. Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, Zhiyuan Liu, Hao Peng, Lei Bai, Wanli Ouyang, Yu Cheng, Bowen Zhou, and Ning Ding. 2025. The entropy mechanism of rein- forcement learning for reasoning langua...
Pith/arXiv arXiv 2025
-
[3]
Audrey Huang, Wenhao Zhan, Tengyang Xie, Jason D
Mdpo: Overcoming the training-inference di- vide of masked diffusion language models.Preprint, arXiv:2508.13148. Audrey Huang, Wenhao Zhan, Tengyang Xie, Jason D. Lee, Wen Sun, Akshay Krishnamurthy, and Dy- lan J. Foster. 2025a. Correcting the mythos of kl- regularization: Direct alignment without overopti- mization via chi-squared preference optimization...
arXiv 2002
-
[4]
InThe Twelfth In- ternational Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024
Let’s verify step by step. InThe Twelfth In- ternational Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. Open- Review.net. Timothy P. Lillicrap, Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. 2016. Continuous con- trol with deep reinforcement learning. In4th I...
2024
-
[5]
Shen Nie, Fengqi Zhu, Chao Du, Tianyu Pang, Qian Liu, Guangtao Zeng, Min Lin, and Chongxuan Li
Boundary-guided policy optimization for memory-efficient rl of diffusion large language mod- els.Preprint, arXiv:2510.11683. Shen Nie, Fengqi Zhu, Chao Du, Tianyu Pang, Qian Liu, Guangtao Zeng, Min Lin, and Chongxuan Li. 2025a. Scaling up masked diffusion models on text. Preprint, arXiv:2410.18514. Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang O...
Pith/arXiv arXiv 2025
-
[6]
Kevin Rojas, Jiahe Lin, Kashif Rasul, Anderson Schnei- der, Yuriy Nevmyvaka, Molei Tao, and Wei Deng
d-treerpo: Towards more reliable policy op- timization for diffusion language models.Preprint, arXiv:2512.09675. Kevin Rojas, Jiahe Lin, Kashif Rasul, Anderson Schnei- der, Yuriy Nevmyvaka, Molei Tao, and Wei Deng
-
[7]
Improving reasoning for diffusion language models via group diffusion policy optimization. Preprint, arXiv:2510.08554. Subham S. Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T. Chiu, Alexan- der Rush, and V olodymyr Kuleshov. 2024. Simple and effective masked diffusion language models. In Advances in Neural Information Pro...
arXiv 2024
-
[8]
Seed diffusion: A large-scale diffusion lan- guage model with high-speed inference.Preprint, arXiv:2508.02193. Richard S. Sutton. 1988. Learning to predict by the methods of temporal differences.Mach. Learn., 3:9– 44. Hongze Tan, Zihan Wang, Jianfei Pan, Jinghao Lin, Hao Wang, Yifan Wu, Tao Chen, Zhihang Zheng, Zhihao Tang, and Haihua Yang. 2026. Gtpo and...
Pith/arXiv arXiv 1988
-
[9]
Jingyi Yang, Guanxu Chen, Xuhao Hu, and Jing Shao
Advancing reasoning in diffusion language models with denoising process rewards.Preprint, arXiv:2510.01544. Jingyi Yang, Guanxu Chen, Xuhao Hu, and Jing Shao. 2025a. Taming masked diffusion language models via consistency trajectory reinforcement learning with fewer decoding step.Preprint, arXiv:2509.23924. Kai Yang, Xin Xu, Yangkun Chen, Weijie Liu, Jiaf...
-
[10]
Ling Yang, Ye Tian, Bowen Li, Xinchen Zhang, Ke Shen, Yunhai Tong, and Mengdi Wang
Entropic: Towards stable long-term training of llms via entropy stabilization with proportional- integral control.Preprint, arXiv:2511.15248. Ling Yang, Ye Tian, Bowen Li, Xinchen Zhang, Ke Shen, Yunhai Tong, and Mengdi Wang. 2025b. Mmada: Multimodal large diffusion language mod- els.Preprint, arXiv:2505.15809. Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui G...
arXiv 2025
-
[11]
CAPR moves from the low- reward region into the same high-reward band as the tree method while using the cheaper cached/branched rollout structure
baselines. CAPR moves from the low- reward region into the same high-reward band as the tree method while using the cheaper cached/branched rollout structure. On GSM8K and Math500, the base model already has stronger task competence and the reward axis is much narrower, so CAPR stays close to thed-TreeRPO curve and may move slightly above or below it at d...
2026
-
[12]
Identify John’s age when Digimon came out
-
[13]
Determine Jim’s age when Digimon came out
-
[14]
First, we know that Digimon had its 20th anniversary, so it came out 20 years ago
Calculate Jim’s current age. First, we know that Digimon had its 20th anniversary, so it came out 20 years ago. If John is currently 28 years old, then his age when Digimon came out was28−20 = 8years old. Next, we know that when Digimon came out, John was twice as old as Jim. Therefore, let’s set up the equation:8 = 2·Jim’s age. To find Jim’s age, we divi...
-
[15]
Understand that Digimon had its 20th anniversary, 20 years ago
-
[16]
At that time, John was twice as old as Jim
-
[17]
Jim’s age then
We are currently given that John is 28 years old. Let’s denote Jim’s current age asJ. Since Digimon had its 20th anniversary 20 years ago, John was28−20 = 8years old at that time. At that time, John was twice as old as Jim. Therefore, we can set up the equation: 8 = 2J. To find Jim’s current age, we solve forJ:J= 8 2 = 4. Thus, Jim is currently 4 years ol...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.