KadiAssistant: A conversational AI Agent for information retrieval in Kadi4Mat
Pith reviewed 2026-05-20 21:33 UTC · model grok-4.3
The pith
KadiAssistant pairs a self-hosted LLM with privacy-preserving semantic search to let researchers query and synthesize access-controlled data in Kadi4Mat.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
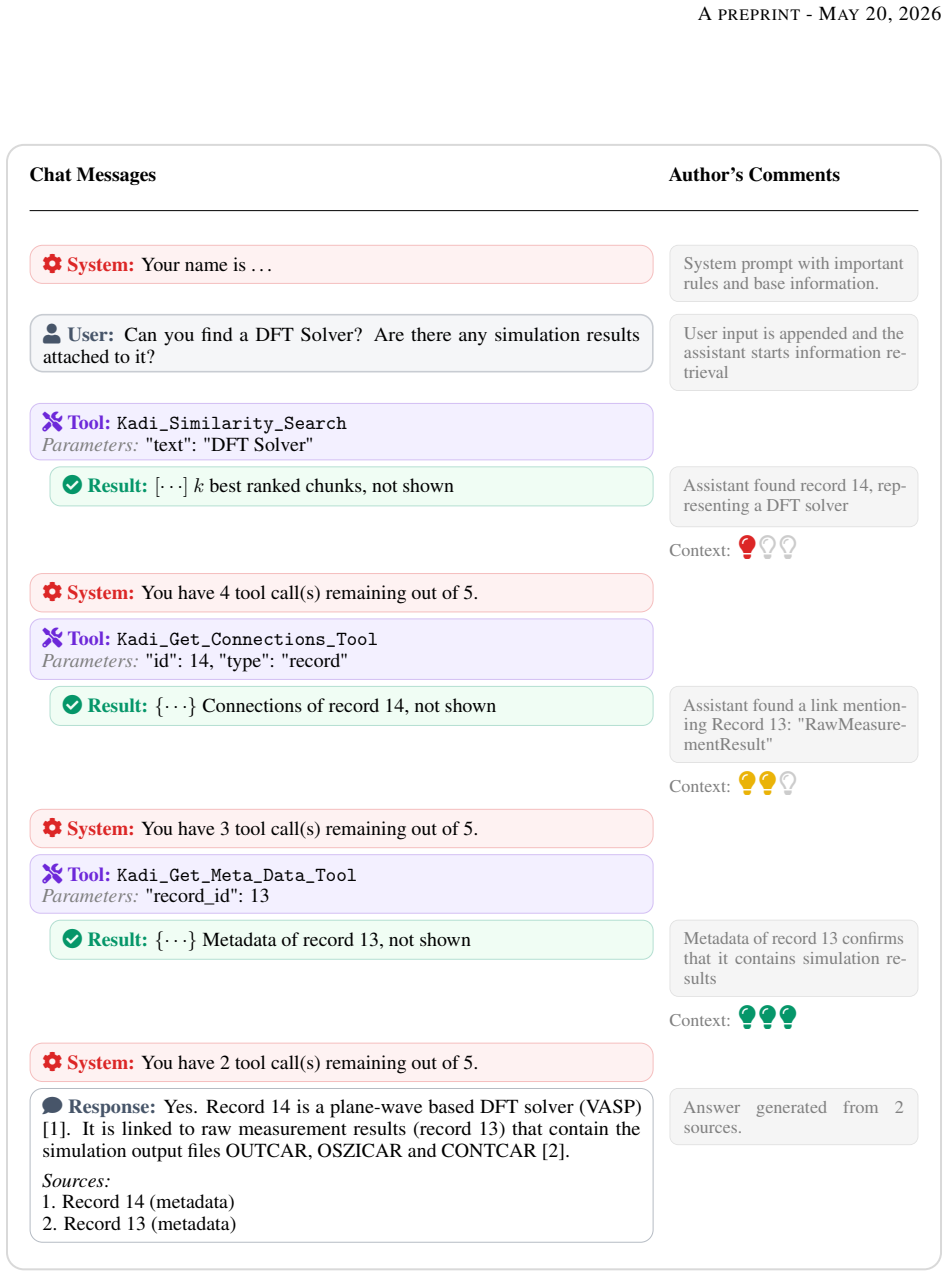
KadiAssistant combines a self-hosted large language model with a privacy-preserving semantic search, inspired by retrieval-augmented generation, that can access files and record metadata on Kadi. This allows the assistant to screen, aggregate, and structure information into a highly informative answer while respecting fine-grained access permissions and bridging terminology differences across disciplines.
What carries the argument
Self-hosted LLM integrated with privacy-preserving semantic search that reads Kadi files and metadata under enforced access rules.
If this is right
- Researchers gain the ability to retrieve information from distributed records without prior mastery of metadata schemas or domain-specific interfaces.
- Fine-grained permissions on sensitive warm data remain intact during search and synthesis operations.
- Terminology and format differences across disciplines are bridged so that answers can draw from electrochemical, simulation, and manufacturing records alike.
- The findable pillar of FAIR principles is strengthened for both private and published data in the Kadi ecosystem.
Where Pith is reading between the lines
- The same privacy-first retrieval pattern could be applied to other research data platforms that store mixed-sensitivity records.
- Widespread adoption might encourage metadata standardization because accurate aggregation depends on consistent terminology.
- Self-hosting the language model keeps raw data inside institutional boundaries, offering a template for privacy-sensitive scientific assistants elsewhere.
Load-bearing premise
The semantic search can reliably enforce fine-grained access permissions across heterogeneous data formats and terminologies while still producing accurate aggregated answers.
What would settle it
A user query that returns content from a record the user is not permitted to see, or that misses relevant records because of mismatched terminology in the permission layer.
Figures










read the original abstract
We introduce KadiAssistant, a privacy-by-design AI assistant integrated into the Kadi research data ecosystem, enabling researchers to efficiently access, aggregate, and synthesize information from heterogeneous, privacy-sensitive research data. Interdisciplinary fields such as materials science bring together disciplines with their own terminology and standards. While this convergence fuels innovation, it also makes it increasingly difficult to connect and access knowledge, as data are distributed across disciplines, organizations, and individuals. For example, battery research combines electrochemical measurements, materials characterization data, physics-based simulations, and manufacturing parameters, each using different formats, vocabularies, and standards. Efficiently storing and sharing such heterogeneous data via research data platforms, such as Kadi4Mat, demands domain knowledge, technical expertise, and familiarity with metadata schemas and interfaces. Research data also vary in sensitivity: newly generated 'warm' data are often private, whereas published 'cold' data are usually openly accessible. The Kadi ecosystem offers fine-grained access control needed for sensitive data. A solution for efficient information retrieval in Kadi must therefore respect the fine-grained access permissions. To address these intertwined challenges of information retrieval, strong data privacy, and complex access control, KadiAssistant combines a self-hosted large language model (LLM) with a privacy-preserving semantic search, inspired by retrieval-augmented generation, that can access files and record metadata on Kadi. This allows the assistant to screen, aggregate, and structure information into a highly informative answer. KadiAssistant therefore bridges terminology and standards, lowers access barriers for researchers, and strengthens the Findable pillar of FAIR data principles.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces KadiAssistant, a privacy-by-design conversational AI agent for information retrieval in the Kadi4Mat research data management platform. It describes an architecture combining a self-hosted LLM with a privacy-preserving semantic search (RAG-inspired) that accesses files and record metadata to screen, aggregate, and structure heterogeneous research data (e.g., in battery research) while respecting fine-grained access permissions and supporting the Findable aspect of FAIR principles.
Significance. If the described components function as claimed, the system could meaningfully reduce barriers to synthesizing interdisciplinary research data under strict privacy constraints, advancing practical use of research data platforms. The self-hosted LLM choice and emphasis on permission-respecting retrieval are positive design choices for sensitive domains. However, significance remains prospective given the absence of any implementation, metrics, or validation.
major comments (2)
- [Architecture description] The description of the privacy-preserving semantic search (in the paragraph beginning 'To address these intertwined challenges...'): the mechanism for integrating fine-grained access permissions into retrieval is unspecified (e.g., no mention of query-time filtering, per-user embeddings, or post-retrieval gating). This is load-bearing for the central claim that the assistant retrieves only permitted data while still producing accurate aggregated answers across heterogeneous formats and terminologies.
- [Overall manuscript] No evaluation or implementation section: the manuscript provides no metrics, error analysis, or tests on mixed-permission heterogeneous datasets, leaving the claims about reliable screening/aggregation and privacy enforcement unverified.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the manuscript. We address each major comment below, indicating the revisions we will incorporate to clarify the architecture and strengthen the presentation of the work.
read point-by-point responses
-
Referee: [Architecture description] The description of the privacy-preserving semantic search (in the paragraph beginning 'To address these intertwined challenges...'): the mechanism for integrating fine-grained access permissions into retrieval is unspecified (e.g., no mention of query-time filtering, per-user embeddings, or post-retrieval gating). This is load-bearing for the central claim that the assistant retrieves only permitted data while still producing accurate aggregated answers across heterogeneous formats and terminologies.
Authors: We agree that the current description leaves the permission integration mechanism underspecified. In the revised manuscript we will expand the relevant paragraph to state that Kadi4Mat's native fine-grained access control is applied at query time: the semantic search component issues retrieval requests under the authenticated user's session, so that only records and files the user is permitted to access are returned before any embedding or LLM processing occurs. This query-time filtering respects existing permissions without requiring per-user embeddings or post-retrieval gating, thereby supporting both privacy and the production of accurate aggregated answers from heterogeneous data. revision: yes
-
Referee: [Overall manuscript] No evaluation or implementation section: the manuscript provides no metrics, error analysis, or tests on mixed-permission heterogeneous datasets, leaving the claims about reliable screening/aggregation and privacy enforcement unverified.
Authors: The manuscript presents the conceptual design and privacy-preserving architecture of KadiAssistant. We acknowledge that empirical validation would strengthen the claims. We will add a dedicated section describing the current prototype implementation status and planned evaluation, including qualitative tests on heterogeneous battery-research datasets that respect mixed permissions and metrics such as retrieval relevance and permission adherence. Comprehensive quantitative error analysis and large-scale validation remain part of planned follow-up work. revision: partial
Circularity Check
No circularity: system description with no derivations or fitted results
full rationale
The manuscript is a high-level system description of KadiAssistant that introduces an architecture combining a self-hosted LLM with privacy-preserving semantic search inspired by RAG. No equations, derivations, parameter fittings, or mathematical claims are present in the abstract or described full text. The central design choice is presented as an engineering solution to access-control and terminology challenges rather than a result derived from prior steps within the paper. No self-citations, uniqueness theorems, or ansatzes are invoked to justify any load-bearing claim. This is a standard non-circular descriptive paper whose content is self-contained as an architectural proposal.
Axiom & Free-Parameter Ledger
invented entities (1)
-
KadiAssistant
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
KadiAssistant combines a self-hosted large language model (LLM) with a privacy-preserving semantic search, inspired by retrieval-augmented generation, that can access files and record metadata on Kadi.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
To add a user access rights filter to the k-NN search, we use the 'record_id' and an existing Kadi4Mat function that retrieves all accessible record IDs.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[2]
Harrison Chase and LangChain Contributors.LangChain.URL: https://www.langchain.com/ (visited on 03/25/2026)
work page 2026
-
[3]
Harrison Chase and LangChain Contributors.LangGraph.URL: https://github.com/langchain- ai/ langgraph(visited on 03/25/2026)
work page 2026
-
[4]
A survey on privacy risks and protection in large language models
Kang Chen et al. “A survey on privacy risks and protection in large language models”. In:Journal of King Saud University Computer and Information Sciences37.7 (Sept. 2025), p. 163.ISSN: 1319-1578, 2213-1248.DOI: 10.1007/s44443-025-00177-1.URL:https://link.springer.com/10.1007/s44443-025-00177-1
work page doi:10.1007/s44443-025-00177-1.url:https://link.springer.com/10.1007/s44443-025-00177-1 2025
-
[5]
Open-source embedding database for AI and LLM applications
Chroma.ChromaDB. Open-source embedding database for AI and LLM applications. Chroma.URL: https: //www.trychroma.com/(visited on 05/06/2026)
work page 2026
-
[6]
May 2026.DOI: 10.5281/zenodo.20072958 .URL: https: //doi.org/10.5281/zenodo.20072958
Adrian Cierpka et al.KadiAssistant Dataset. May 2026.DOI: 10.5281/zenodo.20072958 .URL: https: //doi.org/10.5281/zenodo.20072958
-
[7]
Semantic Resources for Managing Knowledge in Battery Research
Simon Clark et al. “Semantic Resources for Managing Knowledge in Battery Research”. In:ChemSusChem 18.16 (Aug. 2025), e202500458.ISSN: 1864-5631, 1864-564X.DOI: 10 . 1002 / cssc . 202500458.URL: https://chemistry-europe.onlinelibrary.wiley.com/doi/10.1002/cssc.202500458
-
[8]
com/pgvector/pgvector(visited on 05/06/2026)
pgvector contributors.pgvector: Open-source vector similarity search for PostgreSQL.URL: https://github. com/pgvector/pgvector(visited on 05/06/2026)
work page 2026
-
[9]
Matthijs Douze et al.The Faiss library. 2025. arXiv: 2401.08281 [cs.LG].URL: https://arxiv.org/abs/ 2401.08281
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
European Organization For Nuclear Research and OpenAIRE.Zenodo. en. 2013.DOI: 10.25495/7GXK-RD71. URL:https://www.zenodo.org/
-
[11]
Aaron Grattafiori et al.The Llama 3 Herd of Models. Nov. 2024.DOI: 10.48550/arXiv.2407.21783. arXiv: 2407.21783 [cs].URL:http://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[12]
Julian Grolig et al.FAIR Development of Data-integrated AI to Detect Breathing Motion in Dynamic Lung MRI. Sept. 2023.DOI:10.5281/zenodo.8366576.URL:https://doi.org/10.5281/zenodo.8366576
work page doi:10.5281/zenodo.8366576.url:https://doi.org/10.5281/zenodo.8366576 2023
-
[13]
Accelerated data-driven materials science with the Materials Project
Matthew K. Horton et al. “Accelerated data-driven materials science with the Materials Project”. In:Nature Materials24.10 (Oct. 2025), pp. 1522–1532.ISSN: 1476-1122, 1476-4660.DOI: 10.1038/s41563- 025- 02272-0.URL:https://www.nature.com/articles/s41563-025-02272-0
-
[14]
P., Hautier, G., Chen, W., Richards, W
Anubhav Jain et al. “Commentary: The Materials Project: A materials genome approach to accelerating materials innovation”. In:APL Materials1.1 (July 2013), p. 011002.ISSN: 2166-532X.DOI: 10.1063/1.4812323. eprint: https://pubs.aip.org/aip/apm/article- pdf/doi/10.1063/1.4812323/13163869/011002_1_ online.pdf.URL:https://doi.org/10.1063/1.4812323. 16 APREPRI...
-
[15]
User Privacy and Large Language Models: An Analysis of Frontier Developers’ Privacy Policies
Jennifer King et al. “User Privacy and Large Language Models: An Analysis of Frontier Developers’ Privacy Policies”. In:Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society8.2 (Oct. 2025), pp. 1465– 1477.ISSN: 3065-8365.DOI: 10.1609/aies.v8i2.36646 .URL: https://ojs.aaai.org/index.php/ AIES/article/view/36646
-
[16]
Arnd Koeppe and CIDS Contributors.CIDS.URL: https://gitlab.com/intelligent-analysis/cids (visited on 03/26/2026)
work page 2026
-
[17]
Woosuk Kwon et al.Efficient Memory Management for Large Language Model Serving with PagedAttention. Sept. 2023.DOI: 10.48550/arXiv.2309.06180. arXiv: 2309.06180 [cs].URL: http://arxiv.org/abs/ 2309.06180
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.06180 2023
-
[18]
Patrick Lewis et al.Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Apr. 12, 2021.DOI: 10.48550/arXiv.2005.11401 . arXiv: 2005.11401 [cs] .URL: http://arxiv.org/abs/2005.11401 . Pre-published
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2005.11401 2021
-
[19]
Yu A. Malkov and D. A. Yashunin.Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs. Aug. 2018.DOI: 10.48550/arXiv.1603.09320. arXiv: 1603.09320 [cs]. URL:http://arxiv.org/abs/1603.09320
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1603.09320 2018
-
[20]
https://huggingface.co/meta- llama/Meta- Llama- 3- 70B- Instruct
Meta AI.Meta-Llama-3-70B-Instruct. https://huggingface.co/meta- llama/Meta- Llama- 3- 70B- Instruct. 2024. (Visited on 03/24/2026)
work page 2024
-
[21]
Hafiz Muhammad Noman and Michael Selzer. “Enhancing Multiscale Simulation Data Management with Domain Ontologies and an ELN: Addressing Challenges and Implementing Strategies”. In:Data Science Journal 24 (Sept. 2025), p. 28.ISSN: 1683-1470.DOI: 10.5334/dsj- 2025- 028 .URL: https://datascience. codata.org/articles/10.5334/dsj-2025-028/
-
[22]
Large language model chatbot developed by OpenAI
OpenAI.ChatGPT. Large language model chatbot developed by OpenAI. First released November 2022. OpenAI, 2022.URL:https://chat.openai.com/(visited on 05/06/2026)
work page 2022
-
[23]
OpenAI et al.gpt-oss-120b & gpt-oss-20b Model Card. 2025. arXiv: 2508.10925 [cs.CL] .URL: https: //arxiv.org/abs/2508.10925
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
AI-powered search and chat platform developed by Perplexity AI
Perplexity AI.Perplexity.ai. AI-powered search and chat platform developed by Perplexity AI. Perplexity AI. URL:https://www.perplexity.ai/(visited on 05/06/2026)
work page 2026
-
[25]
Open-source vector similarity search engine
Qdrant.Qdrant Vector Database. Open-source vector similarity search engine. Qdrant.URL: https://qdrant. tech/(visited on 05/06/2026)
work page 2026
-
[26]
Data-Driven Virtual Material Analysis and Synthesis for Solid Electrolyte Inter- phases
Deepalaxmi Rajagopal et al. “Data-Driven Virtual Material Analysis and Synthesis for Solid Electrolyte Inter- phases”. In:Advanced Energy Materials13.40 (Oct. 2023), p. 2301985.ISSN: 1614-6832, 1614-6840.DOI: 10.1002/aenm.202301985.URL: https://advanced.onlinelibrary.wiley.com/doi/10.1002/aenm. 202301985
-
[27]
Luigi Sbailò et al. “The NOMAD Artificial-Intelligence Toolkit: turning materials-science data into knowledge and understanding”. In:npj Computational Materials8.1 (Dec. 5, 2022), p. 250.ISSN: 2057-3960.DOI: 10. 1038/s41524-022-00935-z.URL:https://www.nature.com/articles/s41524-022-00935-z
work page 2022
-
[28]
NOMAD: A distributed web-based platform for managingmaterials science research data
Markus Scheidgen et al. “NOMAD: A distributed web-based platform for managingmaterials science research data”. In:Journal of Open Source Software8.90 (Oct. 15, 2023), p. 5388.ISSN: 2475-9066.DOI: 10.21105/ joss.05388.URL:https://joss.theoj.org/papers/10.21105/joss.05388
-
[29]
2024.DOI:10.25446/OXFORD.25231847.V2.URL: https://portal.sds
Damon Strange and Megan Gooch.Taking the temperature - exploring the lifecycle of research data using the ‘hot’, ‘warm’ or ‘cold’ metaphor. 2024.DOI:10.25446/OXFORD.25231847.V2.URL: https://portal.sds. ox.ac.uk/articles/conference_contribution/Taking_the_temperature_- _exploring_the_ lifecycle_of_research_data_using_the_hot_warm_or_cold_metaphor/25231847/2
-
[30]
Kadi4Mat Team and Contributors.kadi-apy. Version 0.47.0. May 2025.DOI: 10.5281/zenodo.15422101 . URL:https://doi.org/10.5281/zenodo.15422101
-
[31]
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models
Nandan Thakur et al.BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models. 2021.DOI:10.48550/ARXIV.2104.08663.URL:https://arxiv.org/abs/2104.08663
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2104.08663.url:https://arxiv.org/abs/2104.08663 2021
-
[32]
The Navigation Fund.AIRDEC - Al-assisted Repository DEposit and Curation. 2025.DOI: 10.71707/WDQR- 2J50.URL:https://commons.datacite.org/doi.org/10.71707/wdqr-2j50(visited on 02/05/2026)
-
[33]
com / Unstructured - IO / unstructured(visited on 03/25/2026)
Unstructured.io.Unstructured open source library.URL: https : / / github . com / Unstructured - IO / unstructured(visited on 03/25/2026)
work page 2026
-
[34]
Ashish Vaswani et al.Attention Is All You Need. Aug. 2023.DOI: 10.48550/arXiv.1706.03762 . arXiv: 1706.03762 [cs].URL:http://arxiv.org/abs/1706.03762
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1706.03762 2023
-
[35]
Mark D. Wilkinson et al. “The FAIR Guiding Principles for scientific data management and stewardship”. In:Scientific Data3.1 (Mar. 15, 2016), p. 160018.ISSN: 2052-4463.DOI: 10.1038/sdata.2016.18 .URL: https://www.nature.com/articles/sdata201618. 17 APREPRINT- MAY20, 2026
-
[36]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang et al.Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models. June 2025.DOI: 10.48550/arXiv.2506.05176 . arXiv: 2506.05176 [cs] .URL: http://arxiv. org/abs/2506.05176
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.05176 2025
-
[37]
Yinghan Zhao et al. “LISA: A Lithium-Ion Solid-State Assistant using large language models for knowledge defragmentation in battery science and beyond”. In:Materials Today Communications45 (Apr. 2025), p. 112380. ISSN: 2352-4928.DOI: 10.1016/j.mtcomm.2025.112380 .URL: https://linkinghub.elsevier.com/ retrieve/pii/S235249282500892X. Acknowledgments This wo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.