MVSegNet: A Lightweight Boundary-Aware Network for Fetal Lateral Ventricle Segmentation and Atrial Width Estimation in Prenatal Ultrasound
Pith reviewed 2026-06-27 22:16 UTC · model grok-4.3
The pith
MVSegNet segments fetal lateral ventricles in prenatal ultrasound with 80.79% Dice score using a lightweight boundary-aware network.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
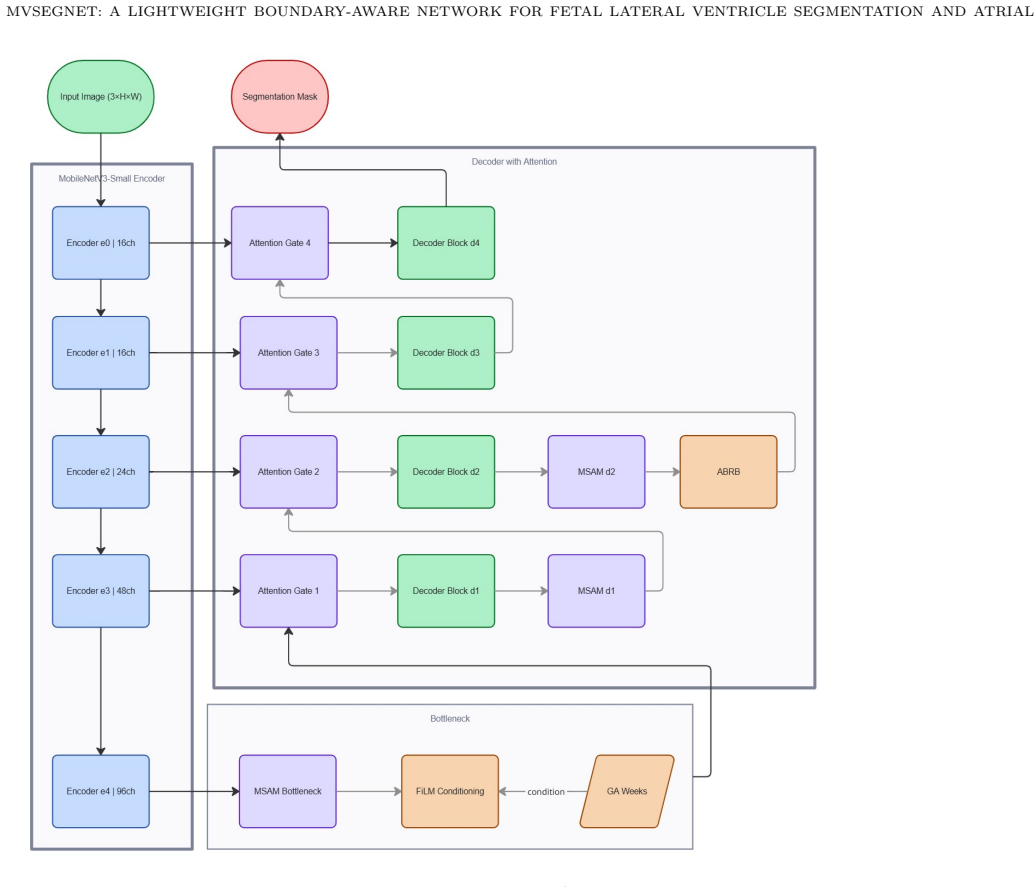
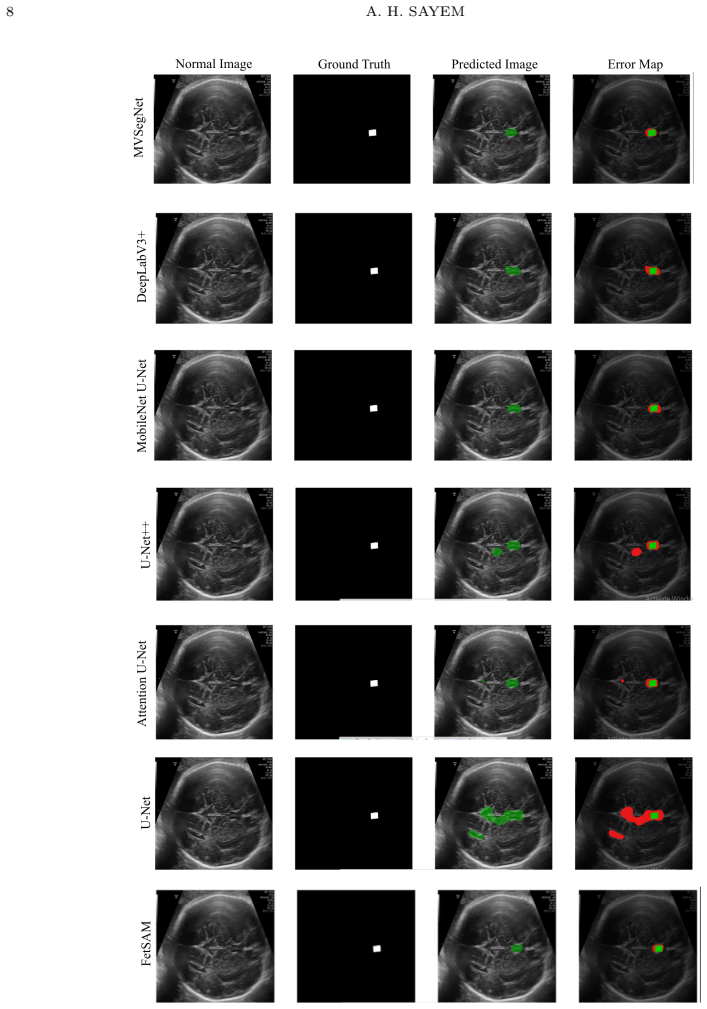
MVSegNet is a lightweight encoder-decoder network that integrates multi-scale feature extraction and boundary-aware refinement to segment the fetal lateral ventricle and estimate atrial width from prenatal ultrasound. Evaluated on 584 expert-annotated transventricular frames with a 70/15/15 split, the model records a Dice score of 80.79%, IoU of 68.47%, Hausdorff distance of 4.07 mm, and atrial width mean absolute error of 3.40 mm. It contains 2.31 million parameters and processes images at 165.6 frames per second on an NVIDIA T4 GPU, outperforming all six evaluated baselines on boundary and measurement metrics while keeping computational demands low.
What carries the argument
MVSegNet, a lightweight encoder-decoder architecture that performs multi-scale feature extraction followed by boundary-aware refinement to mitigate ultrasound artifacts during ventricle segmentation.
If this is right
- Automated atrial width measurements become more accurate than those from the six compared segmentation baselines.
- The low parameter count and 165.6 fps speed make the model feasible for real-time clinical ultrasound workflows.
- Boundary precision improves, as shown by the 4.07 mm Hausdorff distance on the held-out test frames.
- The approach supports deployment of automated fetal ultrasound analysis tools that require modest hardware.
- Measurement error of 3.40 mm provides a concrete reduction relative to prior methods on the same 584-frame collection.
Where Pith is reading between the lines
- The same multi-scale and boundary-refinement design may transfer to segmentation of other fetal brain structures that face similar ultrasound artifacts.
- Performance gains on boundary metrics could reduce the need for manual correction in clinical measurement pipelines.
- Validation on datasets collected across different scanner vendors would test whether the reported advantages generalize beyond the original acquisition setup.
- Combining MVSegNet outputs with other prenatal biometry tools might yield more consistent overall screening results.
Load-bearing premise
The 584 expert-annotated transventricular frames and the 15% test split are representative of the full range of clinical variability, acoustic conditions, and patient populations encountered in routine prenatal screening.
What would settle it
Re-evaluation of MVSegNet on an independent multi-center dataset that includes images from different ultrasound machines, broader gestational age ranges, and varied acoustic conditions would show whether the reported Dice, Hausdorff, and atrial-width error values remain stable.
Figures
read the original abstract
Fetal ventriculomegaly is assessed by measuring the atrial width of the lateral ventricle in prenatal ultrasound. Accurate segmentation is essential for this measurement, but acoustic shadowing, speckle noise, and poor contrast make it difficult. We developed MVSegNet, a lightweight encoder-decoder network combining multi-scale feature extraction and boundary-aware refinement. The model was trained and evaluated on 584 expert-annotated transventricular ultrasound frames using a 70/15/15 split. Performance was compared against six segmentation baselines using overlap, boundary, and measurement metrics. MVSegNet achieved a Dice score of 80.79%, IoU of 68.47%, Hausdorff distance of 4.07 mm, and atrial width mean absolute error of 3.40 mm. The model contains 2.31 million parameters and runs at 165.6 frames per second on an NVIDIA T4 GPU. MVSegNet outperformed all evaluated baselines on boundary and measurement metrics while maintaining low computational cost, supporting its use in automated fetal ultrasound analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents MVSegNet, a lightweight encoder-decoder network combining multi-scale feature extraction and boundary-aware refinement for fetal lateral ventricle segmentation and atrial width estimation in prenatal ultrasound. Trained and evaluated on 584 expert-annotated transventricular frames using a 70/15/15 split, it reports Dice 80.79%, IoU 68.47%, Hausdorff distance 4.07 mm, and atrial width MAE 3.40 mm. The model has 2.31 million parameters and runs at 165.6 FPS on an NVIDIA T4 GPU, outperforming six baselines on boundary and measurement metrics while maintaining low computational cost.
Significance. If the results hold, this could contribute an efficient tool for automated prenatal ultrasound analysis, addressing challenges like acoustic shadowing and speckle noise in assessing fetal ventriculomegaly. The emphasis on low parameter count and high speed is a clear strength for potential real-time clinical use. Concrete metrics and baseline comparisons are provided, which is positive for empirical work in the field.
major comments (3)
- [Abstract] Abstract: The central claim of outperformance on boundary and measurement metrics rests on comparison to six baselines, but no descriptions of the baselines, their training, or the loss function for MVSegNet are supplied, leaving the superiority claim only moderately supported.
- [Abstract] Abstract: The evaluation uses a single 70/15/15 split of 584 frames with no mention of multi-center sourcing, gestational-age stratification, pathology distribution, scanner variability, or external validation. This is load-bearing for the claim that the results support use in automated analysis under routine clinical conditions with varied acoustic shadowing and speckle.
- [Abstract] Abstract: No statistical tests, standard deviations, or confidence intervals accompany the reported metrics (Dice 80.79%, HD 4.07 mm, MAE 3.40 mm), which is necessary to substantiate that improvements over baselines are reliable rather than due to split variability.
minor comments (1)
- [Abstract] Abstract: Adding a reference to an architecture diagram or table summarizing the six baselines would improve clarity of the experimental setup.
Simulated Author's Rebuttal
We appreciate the referee's thorough review and constructive feedback on our manuscript. We have carefully considered each major comment and made revisions to the abstract and main text to address the concerns about baseline descriptions, evaluation details, and statistical reporting. Below we provide point-by-point responses.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of outperformance on boundary and measurement metrics rests on comparison to six baselines, but no descriptions of the baselines, their training, or the loss function for MVSegNet are supplied, leaving the superiority claim only moderately supported.
Authors: We agree that the abstract would benefit from additional context. The full descriptions of the six baselines, their training protocols, and the loss function for MVSegNet are detailed in the Methods section of the manuscript. We have revised the abstract to briefly note the comparison to standard segmentation models trained under the same conditions. revision: yes
-
Referee: [Abstract] Abstract: The evaluation uses a single 70/15/15 split of 584 frames with no mention of multi-center sourcing, gestational-age stratification, pathology distribution, scanner variability, or external validation. This is load-bearing for the claim that the results support use in automated analysis under routine clinical conditions with varied acoustic shadowing and speckle.
Authors: The dataset sourcing and split details are provided in the paper. We have updated the abstract to include mention of the single-center collection and gestational age range. We have also expanded the Discussion section to discuss limitations related to scanner variability and the absence of external validation, emphasizing that the results are promising but require further validation for broader clinical deployment. revision: partial
-
Referee: [Abstract] Abstract: No statistical tests, standard deviations, or confidence intervals accompany the reported metrics (Dice 80.79%, HD 4.07 mm, MAE 3.40 mm), which is necessary to substantiate that improvements over baselines are reliable rather than due to split variability.
Authors: We concur that variability measures are essential. We have re-evaluated the model using multiple random seeds and reported standard deviations for the key metrics in the revised results section. Additionally, we have included statistical significance tests comparing MVSegNet to the baselines. revision: yes
Circularity Check
No circularity: empirical metrics on explicit held-out test split
full rationale
The paper reports an empirical ML segmentation study. It trains MVSegNet on 584 annotated frames using a 70/15/15 split and evaluates Dice, IoU, Hausdorff, and MAE on the held-out test portion, comparing against baselines. No derivation chain, first-principles prediction, fitted parameter renamed as prediction, or self-citation load-bearing step is present. Results are direct measurements on independent test data; the central claim does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- model architecture and training hyperparameters
axioms (1)
- domain assumption Expert annotations are accurate and consistent ground truth for segmentation
Reference graph
Works this paper leans on
-
[1]
Toward a com- prehensive benchmark framework for automated fetal lateral ventricle segmentation in prenatal ultrasound
Alzubaidi, M., Agus, M., Alyafei, K., Wijaya, I.P., Anbar, M., Househ, M., Alam, T., 2023. Toward a com- prehensive benchmark framework for automated fetal lateral ventricle segmentation in prenatal ultrasound. Data Brief47, 108995
2023
-
[2]
Encoder-decoder with atrous separable convolution for semantic image segmentation
Chen, L.-C., Zhu, Y., Papandreou, G., Schroff, F., Adam, H., 2018. Encoder-decoder with atrous separable convolution for semantic image segmentation. In:Proc. Eur. Conf. Comput. Vis. (ECCV), Springer, Cham, pp. 801–818
2018
-
[3]
Searching for MobileNetV3
Howard, A., Sandler, M., Chu, G., Chen, L.-C., Chen, B., Tan, M., Wang, W., Zhu, Y., Pang, R., Vasudevan, V., Le, Q.V., Adam, H., 2019. Searching for MobileNetV3. In:Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), pp. 1314–1324
2019
-
[4]
Segment Anything
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.-Y., Dollar, P., Girshick, R., 2023. Segment Anything. In:Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), pp. 4015–4026
2023
-
[5]
Segment Anything in Medical Images.Nat
Ma, J., He, Y., Li, F., Han, L., You, C., Wang, B., 2024. Segment Anything in Medical Images.Nat. Commun.15, 654
2024
-
[6]
Attention U-Net: Learning where to look for the pancreas
Oktay, O., Schlemper, J., Folgoc, L.L., Lee, M., Heinrich, M., Misawa, K., Mori, K., McDonagh, S., Hammerla, N.Y., Kainz, B., Glocker, B., Rueckert, D., 2018. Attention U-Net: Learning where to look for the pancreas. In:Proc. Med. Imaging Deep Learn. (MIDL), Amsterdam, the Netherlands
2018
-
[7]
FiLM: Visual reasoning with a general conditioning layer
Perez, E., Strub, F., de Vries, H., Dumoulin, V., Courville, A., 2018. FiLM: Visual reasoning with a general conditioning layer. In:Proc. AAAI Conf. Artif. Intell., pp. 3942–3951
2018
-
[8]
U-Net: Convolutional networks for biomedical image segmen- tation
Ronneberger, O., Fischer, P., Brox, T., 2015. U-Net: Convolutional networks for biomedical image segmen- tation. In:Proc. Int. Conf. Med. Image Comput. Comput.-Assist. Interv. (MICCAI), Springer, Cham, pp. 234–241
2015
-
[9]
UNet++: A nested U-Net architecture for medical image segmentation
Zhou, Z., Rahman Siddiquee, M.M., Tajbakhsh, N., Liang, J., 2018. UNet++: A nested U-Net architecture for medical image segmentation. In:Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, Springer, Cham, pp. 3–11. Department of Computer Science & Engineering, Stamford University Bangladesh, Dhaka 1217, Banglades...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.