Task-Restricted Symmetries in Recurrent Weight Space
Pith reviewed 2026-06-27 00:45 UTC · model grok-4.3
The pith
Ordered real Schur coordinates identify task-restricted approximate invariances in the recurrent weights of one-layer tanh RNNs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
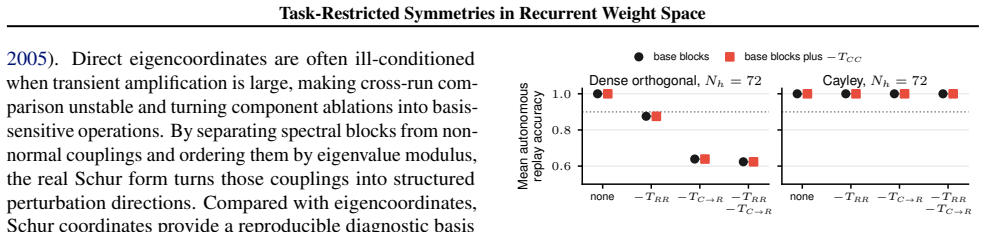
In one-layer tanh RNNs, ordered real Schur coordinates of the recurrent matrix separate eigenvalues from nonnormal couplings and supply a basis for ablations that keep input and readout fixed. On the copy task, selected nonnormal couplings can be removed with little loss in some trained solutions while others remain essential for autonomous replay. The loss-preserving ablation profile varies across flip-flop, sine generation, and context-dependent integration tasks and across different trained solutions, identifying candidate task-restricted approximate functional invariances rather than universal symmetries of recurrent weight space.
What carries the argument
Ordered real Schur coordinates of the recurrent weight matrix, separating spectral blocks from directed nonnormal couplings to enable structured ablation while fixing input and readout maps.
If this is right
- Selected nonnormal Schur couplings can be removed with little loss on the copy task in some trained solutions.
- Other Schur couplings are required to maintain accurate autonomous replay.
- The loss-preserving ablation profile differs across flip-flop, sine generation, and context-dependent integration.
- The profile also differs across different trained solutions on the same task.
- Schur-coordinate ablations diagnose which structured perturbations preserve versus disrupt a trained recurrent solution.
Where Pith is reading between the lines
- The same Schur ablation method could be applied to recurrent networks with multiple layers or different activation functions.
- Task-specific redundancy patterns might guide structured pruning or compression techniques for RNNs.
- The approach may connect to analyses of transient amplification in nonnormal dynamical systems.
- Similar coordinate changes could be tested on other matrix representations used in sequence models.
Load-bearing premise
Ordered real Schur coordinates supply a diagnostic basis that isolates the effect of nonnormal couplings through structured ablation while keeping input and readout maps unchanged.
What would settle it
A trained RNN on the copy task in which ablating a coupling previously identified as dispensable produces large performance degradation, or in which the set of dispensable couplings is identical across all tested tasks.
Figures

read the original abstract
Recurrent networks can contain substantial functional redundancy in weight space: changing a recurrent matrix may leave the input-output rollout nearly unchanged on a task distribution, while similar-scale changes can destroy the same behavior. We study this redundancy in one-layer tanh RNNs using ordered real Schur coordinates. The Schur form separates spectral blocks from directed nonnormal couplings, giving a diagnostic basis for structured ablations that keep the input and readout maps fixed. In a fixed-length copy task, selected nonnormal Schur couplings can be removed with little loss in some trained solutions, whereas other couplings are necessary for accurate autonomous replay. Across flip-flop, sine generation, and context-dependent integration, the loss-preserving ablation profile varies across tasks and trained solutions. These results identify candidate approximate functional invariances, not universal symmetries of recurrent weight space. Schur-coordinate ablations provide a practical diagnostic for which structured perturbations preserve a trained recurrent solution and which ones disrupt its computation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines functional redundancy in the recurrent weight matrices of one-layer tanh RNNs by transforming them into ordered real Schur form, which isolates spectral blocks from directed nonnormal couplings. Structured ablations are performed on selected off-diagonal blocks while holding the input and readout maps fixed; the modified matrix is transformed back to the original basis and evaluated on task rollouts. On a fixed-length copy task, certain nonnormal couplings can be removed with negligible performance loss in some trained solutions while others are required for accurate autonomous replay. Across flip-flop, sine generation, and context-dependent integration tasks, the loss-preserving ablation profile is shown to vary both across tasks and across individually trained networks. The work positions these findings as candidate task-restricted approximate functional invariances rather than universal symmetries of recurrent weight space.
Significance. If the empirical ablation profiles are reproducible, the paper supplies a practical, linear-algebra-based diagnostic for identifying which structured perturbations to a trained recurrent matrix preserve versus disrupt a given computation. The method leverages the standard real Schur decomposition, keeps input and readout weights unchanged, and yields falsifiable, task-dependent predictions about removable couplings. This contributes to the literature on redundancy and interpretability in RNNs by demonstrating that approximate invariances are both present and task-specific.
minor comments (3)
- [§3.2] §3.2 and Figure 2: the description of how the ordered real Schur form is computed (e.g., choice of ordering criterion for blocks) should be stated explicitly so that the ablation procedure can be reproduced from the text alone.
- [Table 1] Table 1: error bars or standard deviations across the N=10 trained networks per task are not reported; adding them would strengthen the claim that ablation profiles differ across solutions.
- The manuscript uses the term 'approximate functional invariances' without a quantitative threshold for 'little loss'; a short definition (e.g., <5% relative increase in task error) would remove ambiguity.
Simulated Author's Rebuttal
We thank the referee for their positive summary and significance assessment of the manuscript. The recommendation of minor revision is noted, and we appreciate the recognition of the work's contribution to understanding task-dependent redundancies in RNNs via Schur ablations. Since no specific major comments were raised, we have no points to address in detail but remain open to any minor suggestions for the revision.
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper applies the standard real Schur decomposition (an external linear-algebra fact) to trained RNN recurrent matrices, performs direct empirical ablations of selected blocks while holding input/readout weights fixed, and reports task-specific performance changes. No step defines a quantity from the target result, renames a fitted parameter as a prediction, or relies on a self-citation chain for a uniqueness claim. The central observations are observational diagnostics, not derivations that reduce to their own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Every real matrix admits a real Schur decomposition that separates spectral blocks from nonnormal couplings
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year =
Git Re-Basin: Merging Models modulo Permutation Symmetries , author =. International Conference on Learning Representations , year =
-
[2]
Proceedings of the 40th International Conference on Machine Learning , series =
Equivariant Architectures for Learning in Deep Weight Spaces , author =. Proceedings of the 40th International Conference on Machine Learning , series =. 2023 , url =
2023
-
[3]
International Conference on Learning Representations , year =
The Role of Permutation Invariance in Linear Mode Connectivity of Neural Networks , author =. International Conference on Learning Representations , year =
-
[4]
Proceedings of the 41st International Conference on Machine Learning , series =
Equivariant Deep Weight Space Alignment , author =. Proceedings of the 41st International Conference on Machine Learning , series =. 2024 , url =
2024
-
[5]
Neural Computation , volume =
Opening the Black Box: Low-Dimensional Dynamics in High-Dimensional Recurrent Neural Networks , author =. Neural Computation , volume =. 2013 , doi =
2013
-
[6]
Nature , volume =
Context-Dependent Computation by Recurrent Dynamics in Prefrontal Cortex , author =. Nature , volume =. 2013 , doi =
2013
-
[7]
Advances in Neural Information Processing Systems , volume =
Universality and Individuality in Neural Dynamics across Large Populations of Recurrent Networks , author =. Advances in Neural Information Processing Systems , volume =
-
[8]
2005 , isbn =
Spectra and Pseudospectra: The Behavior of Nonnormal Matrices and Operators , author =. 2005 , isbn =
2005
-
[9]
Numerische Mathematik , volume =
Bounds for Iterates, Inverses, Spectral Variation and Fields of Values of Non-Normal Matrices , author =. Numerische Mathematik , volume =. 1962/63 , url =
1962
-
[10]
Neuron , volume =
Balanced Amplification: A New Mechanism of Selective Amplification of Neural Activity Patterns , author =. Neuron , volume =. 2009 , doi =
2009
-
[11]
Physical Review E , volume =
Non-normal Amplification in Random Balanced Neuronal Networks , author =. Physical Review E , volume =. 2012 , doi =
2012
-
[12]
PLOS Computational Biology , volume =
Coding with Transient Trajectories in Recurrent Neural Networks , author =. PLOS Computational Biology , volume =. 2020 , doi =
2020
-
[13]
eLife , volume =
Aligned and Oblique Dynamics in Recurrent Neural Networks , author =. eLife , volume =. 2024 , doi =
2024
-
[14]
Neuron , volume =
Primate Neocortex Performs Balanced Sensory Amplification , author =. Neuron , volume =. 2024 , doi =
2024
-
[15]
Advances in Neural Information Processing Systems , volume =
Permutation Equivariant Neural Functionals , author =. Advances in Neural Information Processing Systems , volume =. 2023 , url =
2023
-
[16]
International Conference on Learning Representations , year =
Graph Neural Networks for Learning Equivariant Representations of Neural Networks , author =. International Conference on Learning Representations , year =
-
[17]
Neural Computation , volume =
Long Short-Term Memory , author =. Neural Computation , volume =. 1997 , doi =
1997
-
[18]
Proceedings of the 33rd International Conference on Machine Learning , series =
Unitary Evolution Recurrent Neural Networks , author =. Proceedings of the 33rd International Conference on Machine Learning , series =. 2016 , publisher =
2016
-
[19]
International Conference on Learning Representations , year =
Traveling Waves Encode the Recent Past and Enhance Sequence Learning , author =. International Conference on Learning Representations , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.