GHGbench: A Unified Multi-Entity, Multi-Task Benchmark for Carbon Emission Prediction
Pith reviewed 2026-05-14 19:45 UTC · model grok-4.3
The pith
GHGbench shows building carbon emissions are structurally harder to predict than company emissions, with out-of-distribution gaps dominating model differences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GHGbench establishes that building-level greenhouse gas emission prediction is structurally more difficult than company-level prediction, that the in-distribution to out-of-distribution performance gap substantially exceeds within-model differences across both tracks, that a tabular foundation model is the first baseline to open a paired-bootstrap-significant improvement over tuned gradient-boosted trees on multi-city building tasks, and that multimodal remote-sensing embeddings deliver gains precisely where tabular generalization collapses, while exposing catastrophic city transfer and sector-factor lookup ceilings as systematic limitations.
What carries the argument
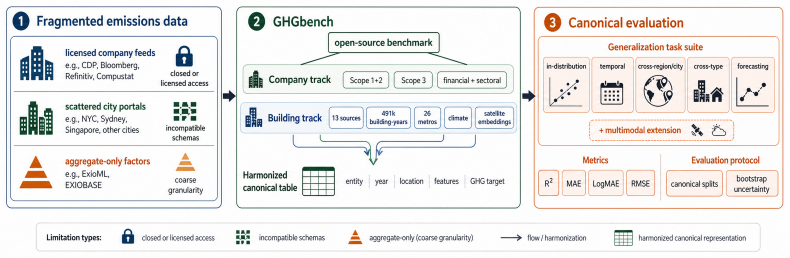
The GHGbench benchmark, consisting of a company track with 32,000+ records and a building track with 491,591 harmonized records across 26 metropolitan areas, evaluated on canonical in-distribution and cross-region/city transfer splits using multi-seed paired-bootstrap statistical tests.
Load-bearing premise
Harmonizing 13 heterogeneous building data sources into a single schema produces accurate labels and features without introducing systematic errors that affect the reported generalization gaps.
What would settle it
Re-evaluating the building track on the same splits but with independently sourced and harmonized emission labels from additional cities that removes the paired-bootstrap significance between the tabular foundation model and tuned trees would falsify the central performance claims.
Figures









read the original abstract
Open datasets and benchmarks for entity-level carbon-emission prediction remain fragmented across access, scale, granularity, and evaluation. We introduce GHGbench, an open dataset and benchmark for company- and building-level greenhouse-gas prediction. The company track contains 32,000+ company-year records from 12,000+ firms with Scope 1+2 and Scope 3 disclosures and financial/sectoral signals; the building track harmonises 491,591 building-year records from 13 open sources into a single schema across 26 metropolitan areas (10 U.S., 15 Australian, 1 Singaporean), with climate covariates and multimodal remote-sensing embeddings. GHGbench defines canonical splits with in-distribution and cross-region/city transfer as primary tasks and temporal hold-out plus short-horizon forecasting as supplementary appendix evidence; headline baselines span gradient-boosted trees, a tabular foundation model, MLP, FT-Transformer, and multimodal fusion, with an LLM panel as auxiliary, all evaluated under multi-seed paired-bootstrap tests. Three benchmark-level findings emerge: (i) building emissions are structurally harder than company emissions; (ii) the in-distribution to out-of-distribution gap dwarfs any within-model gap across both the company track and the building track, and a tabular foundation model is, to our knowledge, the first baseline to open a paired-bootstrap-significant gap over tuned trees on a multi-city building-emissions task; (iii) multimodal remote-sensing embeddings help precisely where tabular generalisation breaks. GHGbench also exposes catastrophic city transfer and the sector-factor lookup ceiling as systematic failure modes. Code and reconstruction recipes are available at GHGbench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GHGbench, a unified benchmark for company- and building-level greenhouse gas emission prediction. The company track aggregates over 32,000 company-year records from 12,000+ firms with Scope 1+2 and Scope 3 disclosures plus financial/sectoral signals. The building track harmonizes 491,591 building-year records from 13 open sources into a single schema across 26 metropolitan areas (10 U.S., 15 Australian, 1 Singaporean), incorporating climate covariates and multimodal remote-sensing embeddings. Canonical splits emphasize in-distribution versus cross-region/city transfer tasks, with temporal hold-out and short-horizon forecasting as supplementary evidence. Baselines include gradient-boosted trees, a tabular foundation model, MLP, FT-Transformer, multimodal fusion, and an auxiliary LLM panel, all evaluated with multi-seed paired-bootstrap tests. Three headline findings are reported: (i) building emissions are structurally harder than company emissions; (ii) ID-to-OOD gaps dwarf within-model differences, with the tabular foundation model achieving the first paired-bootstrap-significant improvement over tuned trees on the multi-city building task; (iii) multimodal remote-sensing embeddings help precisely where tabular generalization breaks. The work also identifies catastrophic city transfer and sector-factor lookup ceilings as systematic failure modes, with code and reconstruction recipes released.
Significance. If the harmonization steps are validated to preserve unbiased labels and features, GHGbench would constitute a valuable contribution by establishing the first large-scale, multi-entity benchmark that systematically tests generalization across cities, regions, and modalities in carbon-emission prediction. The explicit release of code/recipes, use of paired-bootstrap significance testing, and identification of concrete failure modes (city transfer, lookup ceilings) are strengths that support reproducibility and future work. The reported dominance of distribution shift over model choice, together with the utility of remote-sensing embeddings, could usefully inform model design in this application area.
major comments (1)
- [Building track harmonization] Building track (abstract and § on data construction): the central claims (i)–(iii) all rest on the harmonized 491k-record building dataset. The manuscript states that 13 heterogeneous sources were unified but reports no quantitative validation of this step—no inter-source label agreement metrics, no ablation on single-source subsets, and no audit of imputation or aggregation-rule effects. Without such checks, systematic differences in reporting standards, emission-factor assumptions, or city-level aggregation could artifactually inflate the reported ID/OOD gaps and multimodal gains, exactly as flagged by the weakest-assumption analysis.
minor comments (2)
- The abstract and methods would benefit from a concise table summarizing the 13 building sources, their original schemas, and the exact harmonization rules applied (even if full recipes are in the released code).
- Clarify whether the paired-bootstrap tests correct for multiple comparisons across the many model–split combinations reported.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential value of GHGbench for the community. We address the single major comment below and will incorporate the suggested validation steps in the revised manuscript.
read point-by-point responses
-
Referee: [Building track harmonization] Building track (abstract and § on data construction): the central claims (i)–(iii) all rest on the harmonized 491k-record building dataset. The manuscript states that 13 heterogeneous sources were unified but reports no quantitative validation of this step—no inter-source label agreement metrics, no ablation on single-source subsets, and no audit of imputation or aggregation-rule effects. Without such checks, systematic differences in reporting standards, emission-factor assumptions, or city-level aggregation could artifactually inflate the reported ID/OOD gaps and multimodal gains, exactly as flagged by the weakest-assumption analysis.
Authors: We agree that quantitative validation of the harmonization is necessary to support the central claims. The original manuscript emphasized release of the full reconstruction recipes to enable external audits, but did not include explicit agreement metrics or sensitivity checks. In the revision we will add: (i) pairwise label agreement statistics on the subset of buildings that appear in multiple sources, (ii) performance ablations restricted to single-source city subsets for the largest metropolitan areas, and (iii) sensitivity tables showing how ID/OOD gaps and multimodal gains change under alternative imputation and aggregation rules. These additions will confirm that the reported findings are robust to harmonization choices. revision: yes
Circularity Check
No circularity: benchmark relies on external data harmonization and standard evaluation protocols
full rationale
The paper constructs GHGbench by aggregating and harmonizing 13 external public building datasets plus company disclosures, defines canonical ID/OOD splits, and evaluates off-the-shelf baselines (trees, tabular foundation models, multimodal fusion) under paired-bootstrap tests. No equations, fitted parameters, or self-citations are used to derive the three headline empirical findings; those findings are direct statistical comparisons on the released data. The harmonization step is presented as a preprocessing recipe whose validity is left to external audit rather than being defined in terms of the reported gaps. This is a standard benchmark paper whose derivation chain is self-contained against external sources and does not reduce any claim to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard multi-seed paired-bootstrap statistical tests are appropriate for comparing model performance on this data.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The building track harmonises 491,591 building-year records from 13 open sources into a single schema... headline baselines span gradient-boosted trees, a tabular foundation model, MLP, FT-Transformer, and multimodal fusion
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Three benchmark-level findings emerge: (i) building emissions are structurally harder... (ii) the in-distribution to out-of-distribution gap dwarfs any within-model gap... (iii) multimodal remote-sensing embeddings help precisely where tabular generalisation breaks
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.