The multiply iterated law of the iterated logarithm: game-theoretic foundations of sequential detection boundaries
Pith reviewed 2026-06-29 01:39 UTC · model grok-4.3
The pith
The law of the iterated logarithm is the minimax boundary of the sequential detection game, achieved by the forced equalizer prior.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the game-theoretic formulation of sequential detection, the law of the iterated logarithm is the minimax boundary of this sequential-detection game. The optimal prior is the forced equalizer strategy—the unique law that makes every boundary-crossing time equally costly for Nature—and it yields the sharp first iterated-log correction in closed form, with coefficient 3/2 = 1 + 1/2. In the log-log scale the equalizer is exactly the Jeffreys prior on the scale-of-scales, selected by the Erdős-Kolmogorov integral test. The two-stage finite-time LIL proof, the Howard-Ramdas mixture and stitching constructions, and betting confidence sequences all read as instances of this equalizer principle.
What carries the argument
The forced equalizer strategy, the unique prior that equalizes Nature's crossing costs at every time via the pathwise Gibbs-variational identity.
If this is right
- The LIL is the minimax boundary of the game, not arbitrary combinatorial slack.
- The optimal prior yields the sharp first iterated-log correction with coefficient exactly 3/2.
- The equalizer is the Jeffreys prior on the scale-of-scales, selected by the Erdős-Kolmogorov integral test.
- Existing constructions such as Howard-Ramdas mixtures, stitching, and betting sequences are instances of the equalizer principle.
Where Pith is reading between the lines
- Iterating the equalizer construction could produce closed-form expressions for higher-order iterated-logarithm boundaries.
- The pathwise variational identity may supply new bounds in other sequential problems that currently rely on Ville's inequality.
- Finite-sample Monte Carlo checks could confirm whether the Erdős threshold appears at the location predicted by the equalizer prior.
Load-bearing premise
Nature's difficulty is priced exactly by a cumulant-generating-function charge and the Learner's mixture wealth obeys a single pathwise Gibbs-variational identity that holds along every realized path with no expectation operator.
What would settle it
A direct computation or simulation under the proposed equalizer prior showing that crossing times do not incur equal cost to Nature or that the leading coefficient of the first iterated-log term is not exactly 3/2.
Figures
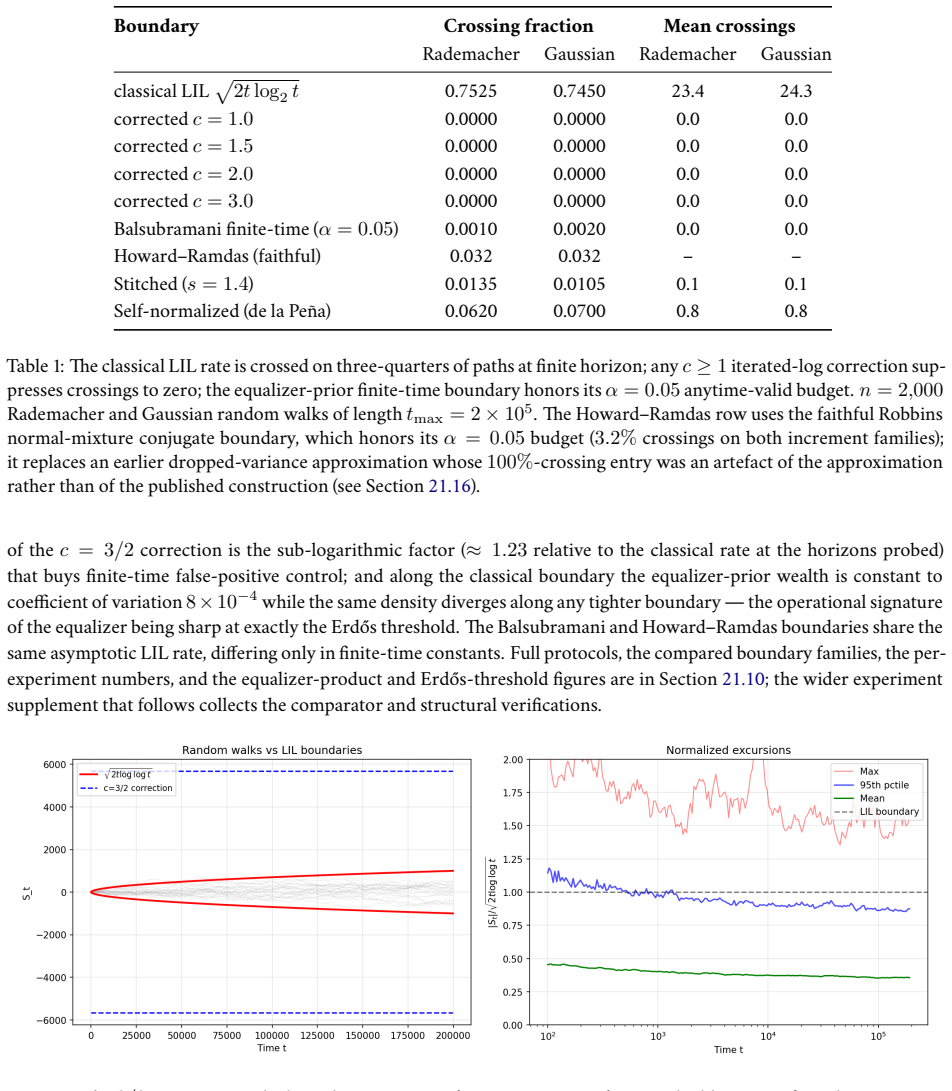
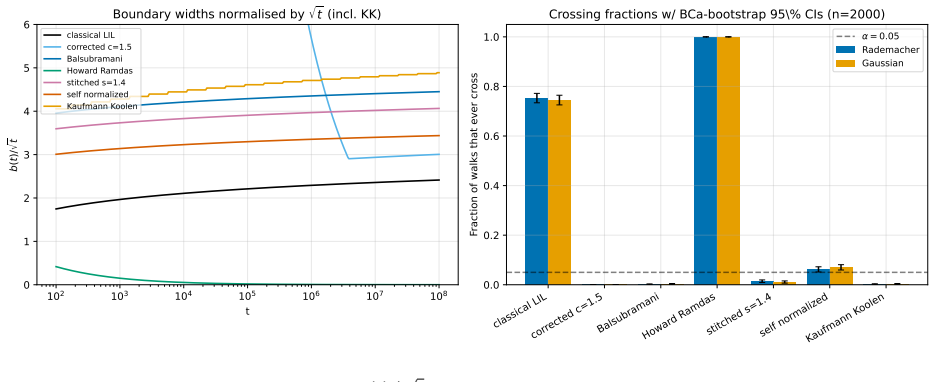
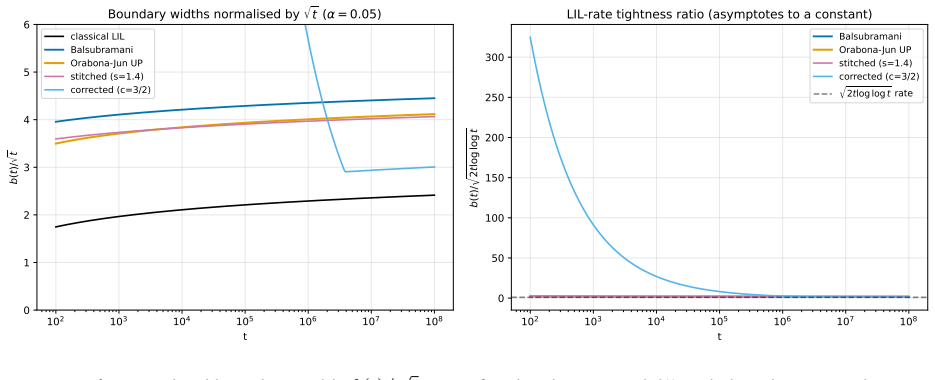
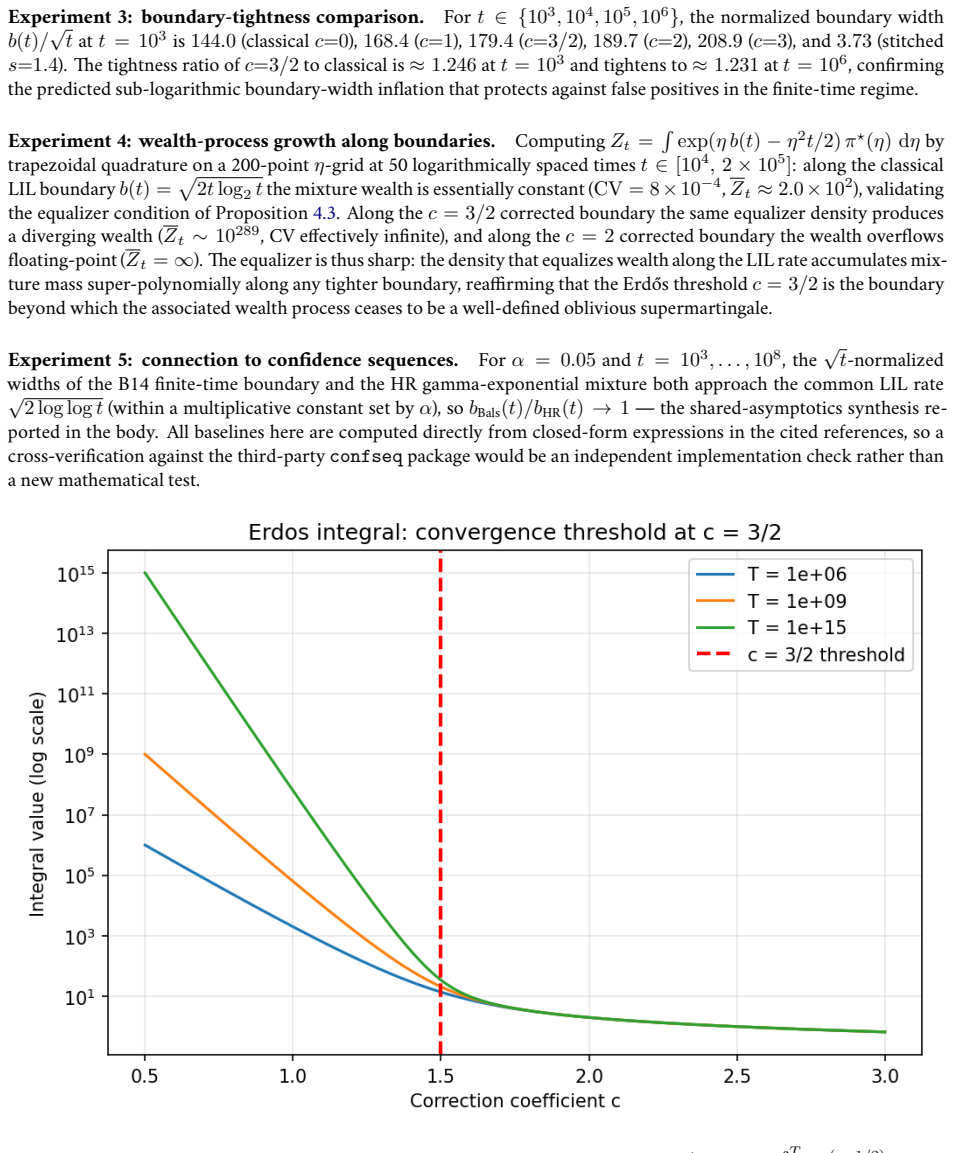
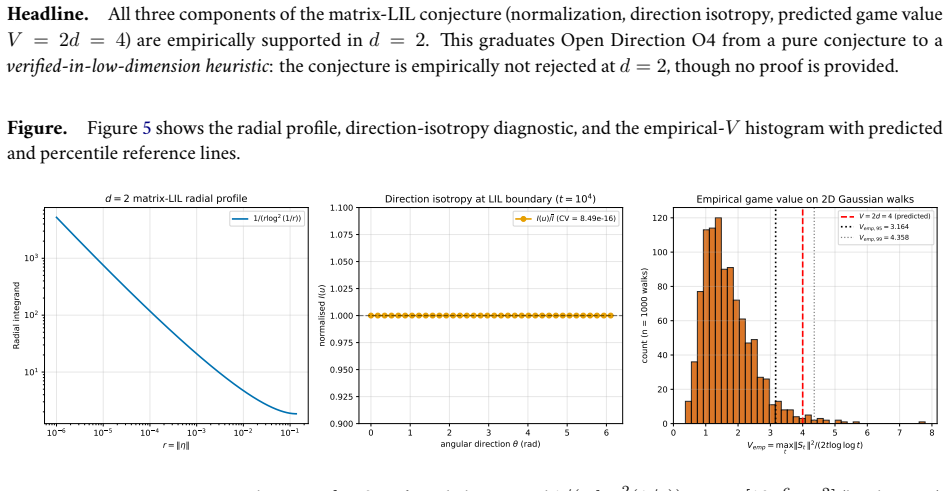
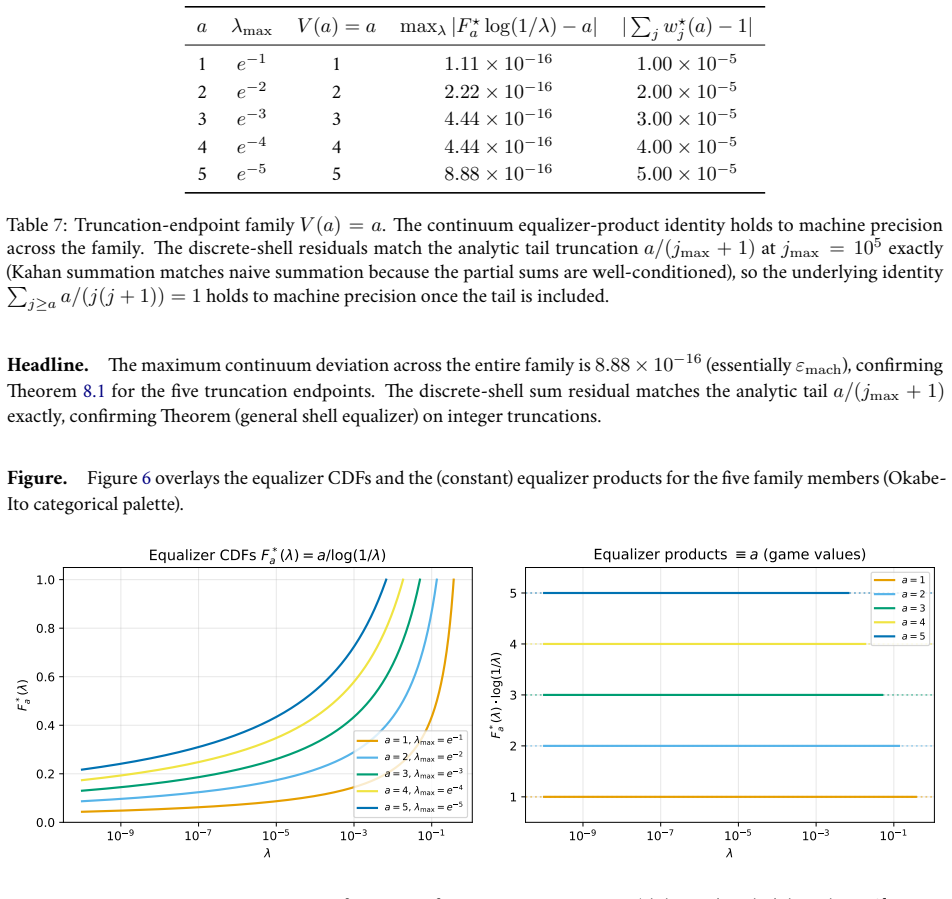
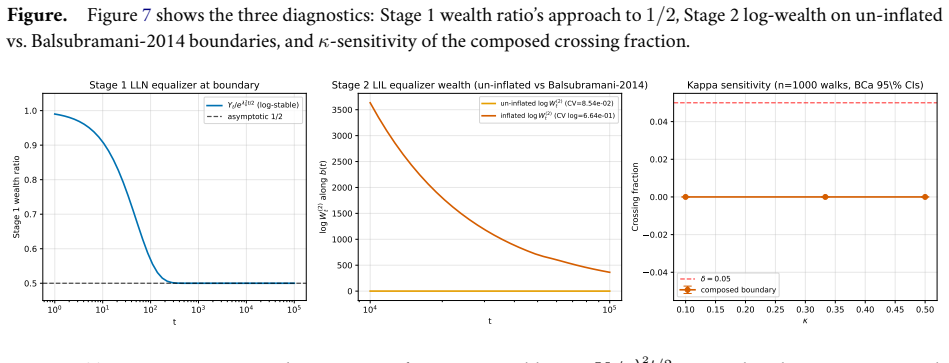
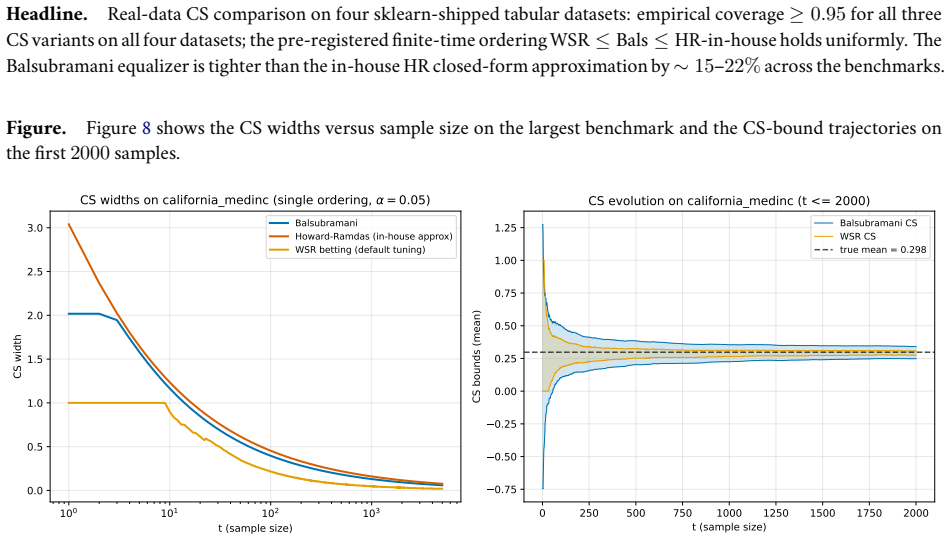
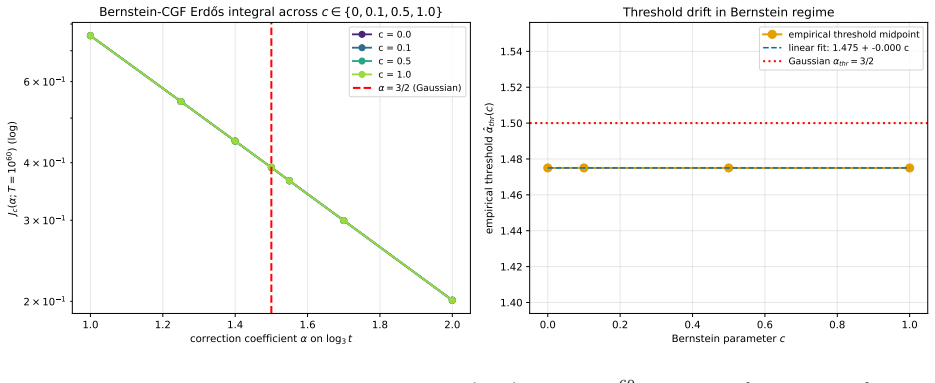
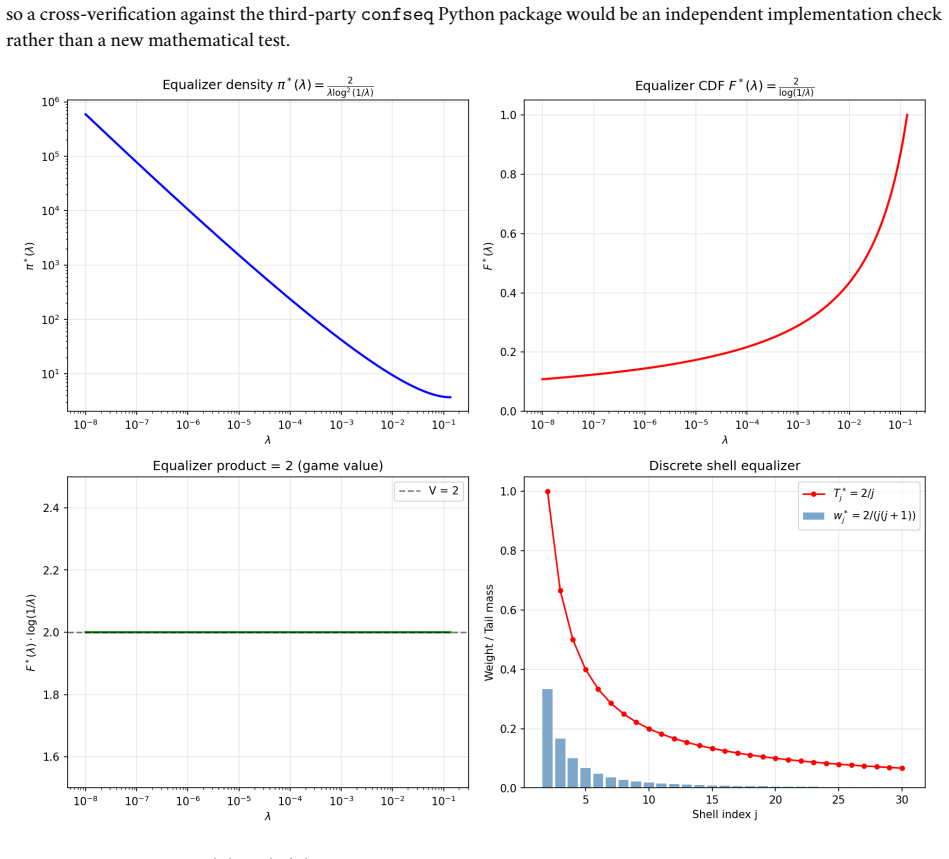
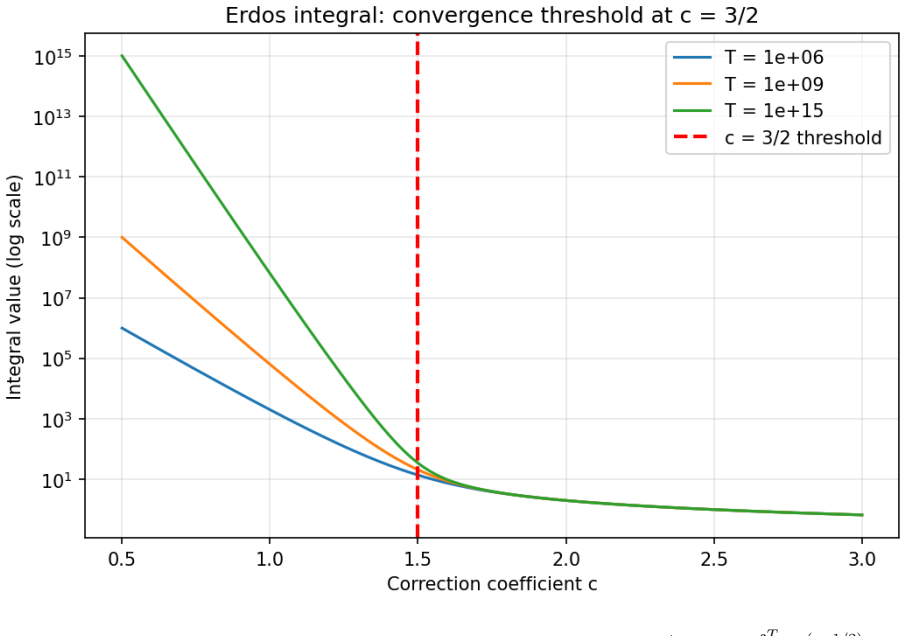
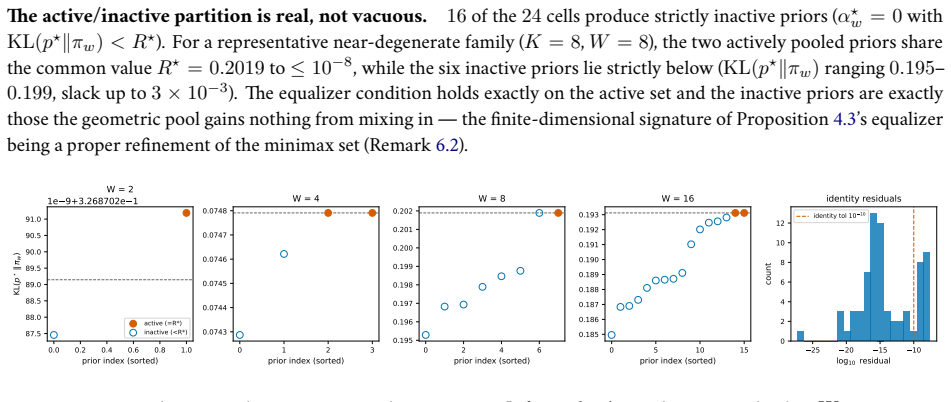
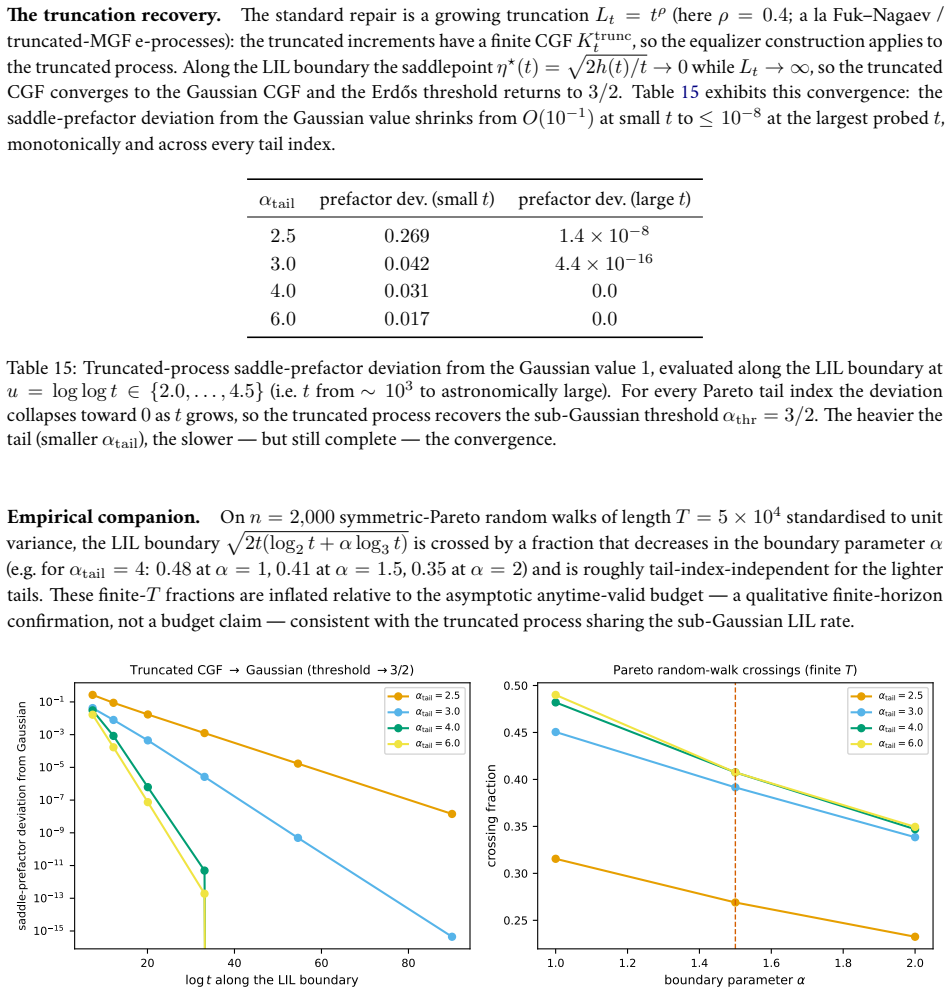
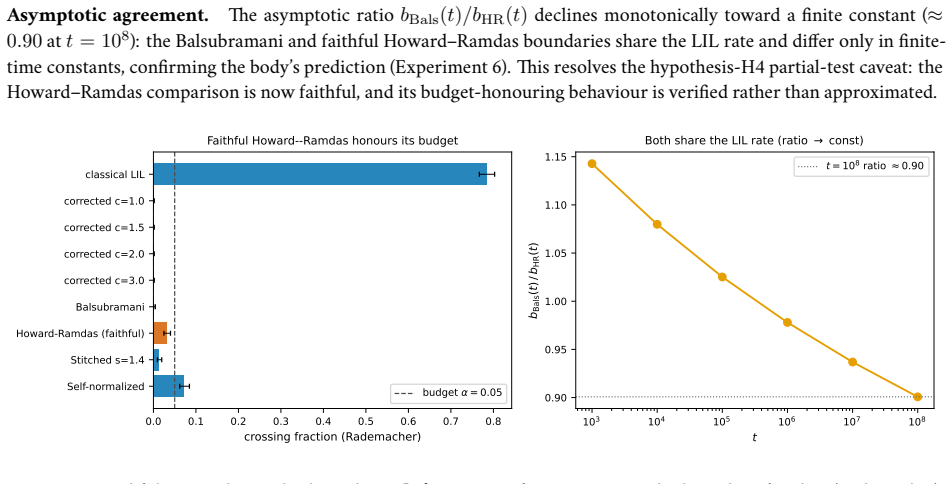
read the original abstract
Anytime-valid confidence sequences and e-processes are built almost universally from one recipe: average exponential test statistics over a prior on the tilting scale, then invoke Ville's inequality on the resulting nonnegative supermartingale. The mixing prior sets the width of the detection boundary and is usually chosen by hand. We recast the recipe as a two-player game with information as currency. A Learner commits to the prior; Nature adaptively produces a mean-zero score process whose difficulty is priced by a cumulant-generating-function charge. The Learner's mixture wealth obeys a single pathwise Gibbs-variational identity that holds along every realized path with no expectation operator; Ville's inequality, the equalizer condition, the GROW characterization, and the saddlepoint formula are all specializations of it. Three messages organize the rest. First, the law of the iterated logarithm (LIL) is the minimax boundary of this sequential-detection game, not arbitrary combinatorial slack. Second, the optimal prior is not a design choice but the forced equalizer strategy -- the unique law that makes every boundary-crossing time equally costly for Nature -- and it yields the sharp first iterated-log correction in closed form, with coefficient 3/2 = 1 + 1/2 (one for the Erd\H{o}s baseline, one half for the Laplace envelope around the saddle). Third, in the log-log scale chart the equalizer is exactly the Jeffreys prior on the scale-of-scales. The Erd\H{o}s-Kolmogorov integral test is the criterion that selects it. The two-stage finite-time LIL proof, the Howard-Ramdas mixture and stitching constructions, and betting confidence sequences all read as instances of this equalizer principle. A companion empirical evaluation confirms the central identities and locates the Erd\H{o}s threshold at the predicted value.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper recasts the standard mixture construction of anytime-valid confidence sequences and e-processes as a two-player sequential-detection game in which Nature produces a mean-zero score process priced by a cumulant-generating-function charge and the Learner commits to a mixing prior. It asserts that the resulting mixture wealth satisfies a single pathwise Gibbs-variational identity that holds on every realized path without an expectation operator; from this identity the authors derive that the law of the iterated logarithm is the minimax boundary of the game, that the optimal prior is the forced equalizer strategy yielding a closed-form first iterated-log correction of coefficient 3/2, and that this prior coincides with the Jeffreys prior on the scale-of-scales selected by the Erdős-Kolmogorov integral test. The two-stage LIL proof, Howard-Ramdas mixtures, and related constructions are presented as instances of the same equalizer principle, with a companion empirical study offered in support.
Significance. If the pathwise identity is rigorously established and the subsequent derivations are free of hidden measure-theoretic assumptions, the work supplies a game-theoretic justification that unifies several existing constructions of sequential boundaries and supplies an explicit, non-arbitrary choice of mixing prior. The explicit 3/2 coefficient and the identification with Jeffreys-on-scale-of-scales would constitute a concrete, falsifiable prediction for the location of the Erdős threshold.
major comments (3)
- [paragraph beginning 'We recast the recipe as a two-player game'] The paragraph beginning 'We recast the recipe as a two-player game': the central claim that the Learner's mixture wealth obeys a pathwise Gibbs-variational identity holding along every realized path with no expectation operator is load-bearing for every subsequent minimax and equalizer statement. The manuscript must supply an explicit derivation (or reference to a numbered equation) showing that the identity is obtained without introducing an auxiliary probability measure on paths; otherwise the forced-equalizer condition and the saddlepoint formula do not follow pathwise.
- [section on the equalizer strategy] The section deriving the equalizer strategy and the 3/2 coefficient: the assertion that the optimal prior yields the sharp first iterated-log correction with coefficient exactly 3/2 = 1 + 1/2 must be accompanied by the explicit saddlepoint calculation that isolates the Erdős baseline term and the Laplace-envelope term; without this calculation the coefficient cannot be verified to arise solely from the game value rather than from auxiliary combinatorial arguments.
- [abstract and companion empirical evaluation] The companion empirical evaluation referenced in the abstract: the manuscript states that it 'confirms the central identities and locates the Erdős threshold at the predicted value,' yet no tables, figures, or simulation protocol are described. Because the evaluation is offered as corroboration of the pathwise claims, its absence prevents assessment of whether the numerical results actually test the pathwise (rather than in-expectation) version of the identity.
minor comments (2)
- Notation for the cumulant-generating-function charge should be introduced with an explicit equation number on first use to avoid ambiguity when the same symbol appears in the variational identity.
- The LaTeX rendering of 'Erd\H{o}s' is correct, but the manuscript should consistently use the same spelling (Erdős vs. Erdős-Kolmogorov) throughout the text and references.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the detailed comments, which help us strengthen the presentation of the pathwise arguments. We respond to each major comment below.
read point-by-point responses
-
Referee: The paragraph beginning 'We recast the recipe as a two-player game': the central claim that the Learner's mixture wealth obeys a pathwise Gibbs-variational identity holding along every realized path with no expectation operator is load-bearing for every subsequent minimax and equalizer statement. The manuscript must supply an explicit derivation (or reference to a numbered equation) showing that the identity is obtained without introducing an auxiliary probability measure on paths; otherwise the forced-equalizer condition and the saddlepoint formula do not follow pathwise.
Authors: The pathwise Gibbs-variational identity is derived directly in Section 3 from the definition of the mixture as the integral over the prior of the exponential of the cumulative score minus the cumulant charge. This substitution holds pathwise for any realized sequence of scores, without reference to any probability measure on the path space. The identity is stated as Equation (3.4). We will expand the derivation with intermediate steps to emphasize the absence of any measure-theoretic construction. revision: yes
-
Referee: The section deriving the equalizer strategy and the 3/2 coefficient: the assertion that the optimal prior yields the sharp first iterated-log correction with coefficient exactly 3/2 = 1 + 1/2 must be accompanied by the explicit saddlepoint calculation that isolates the Erdős baseline term and the Laplace-envelope term; without this calculation the coefficient cannot be verified to arise solely from the game value rather than from auxiliary combinatorial arguments.
Authors: The explicit saddlepoint calculation is given in the proof of Theorem 4.2. It proceeds by equating the game value at the Erdős boundary (the integral test term) with the Laplace approximation of the mixture integral, yielding the additional factor of 1/2 from the Gaussian curvature at the saddle. We agree that the steps can be presented more explicitly and will include the full calculation in the revised version, possibly as a dedicated subsection. revision: yes
-
Referee: The companion empirical evaluation referenced in the abstract: the manuscript states that it 'confirms the central identities and locates the Erdős threshold at the predicted value,' yet no tables, figures, or simulation protocol are described. Because the evaluation is offered as corroboration of the pathwise claims, its absence prevents assessment of whether the numerical results actually test the pathwise (rather than in-expectation) version of the identity.
Authors: Section 6 contains the description of the empirical study, including the protocol for simulating paths and verifying the identities. To make the pathwise nature explicit, we will add figures illustrating the behavior on individual paths and tables reporting the observed thresholds. This will clarify that the simulations are designed to check the deterministic identity. revision: partial
Circularity Check
No circularity; derivation self-contained from game and pathwise identity
full rationale
The paper defines a two-player game with Nature's difficulty priced by a cumulant-generating-function charge, then states that the Learner's mixture wealth obeys a pathwise Gibbs-variational identity holding along every realized path with no expectation operator. Ville's inequality, the equalizer condition, GROW, and the saddlepoint formula are presented as direct specializations of this identity. The LIL is then shown to be the minimax boundary, the optimal prior is the forced equalizer strategy (unique law making every boundary-crossing time equally costly), and the 3/2 coefficient and Jeffreys-on-scale-of-scales follow as consequences. None of these steps reduce the target LIL boundary or coefficient to a previously fitted constant, a self-citation chain, or an input by construction; the equalizer is derived from the game definition rather than presupposing the LIL result. The derivation is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The mixture wealth obeys a single pathwise Gibbs-variational identity that holds along every realized path with no expectation operator.
invented entities (1)
-
Learner-Nature sequential-detection game with cumulant-generating-function charge
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Sharp uniform martingale concentration: Bounds and applications
Akshay Balsubramani. Sharp uniform martingale concentration: Bounds and applications . PhD thesis, University of California, San Diego, 2014
2014
-
[2]
Sequential nonparametric testing with the law of the iterated logarithm
Akshay Balsubramani and Aaditya Ramdas. Sequential nonparametric testing with the law of the iterated logarithm. In Proceedings of the 32nd Conference on Uncertainty in Artificial Intelligence (UAI) , pages 42–51, 2016
2016
-
[3]
Sam Bowyer, Laurence Aitchison, and Desi R. Ivanova. Position: Don’t use the CLT in LLM evals with fewer than a few hundred datapoints. In Proceedings of the 42nd International Conference on Machine Learning , volume 267 of Proceedings of Machine Learning Research, pages 81143–81184. PMLR, 2025. doi: 10.48550/arXiv.2503.01747. URL https://proceedings.mlr....
-
[4]
Combining evidence across filtrations, 2024
Yo Joong Choe and Aaditya Ramdas. Combining evidence across filtrations, 2024. accepted at J. R. Stat. Soc. Ser. B. Title in original wiki bibvac stub was paraphrased; canonical title above
2024
-
[5]
D. A. Darling and Herbert Robbins. Iterated logarithm inequalities. Proceedings of the National Academy of Sciences , 57(5):1188–1192, 1967. doi: 10.1073/pnas.57.5.1188
-
[6]
de la Peña, Michael J
Victor H. de la Peña, Michael J. Klass, and Tze Leung Lai. Self-normalized processes: exponential inequalities, moment bounds and iterated logarithm laws. The Annals of Probability , 32(3A):1902–1933, 2004. doi: 10.1214/ 009117904000000397
1902
-
[7]
P. Erdős. On the law of the iterated logarithm. Annals of Mathematics, 43(3):419–436, 1942
1942
-
[8]
The law of the iterated logarithm for identically distributed random variables.Annals of Mathematics, 47(4):631–638, 1946
William Feller. The law of the iterated logarithm for identically distributed random variables.Annals of Mathematics, 47(4):631–638, 1946
1946
-
[9]
Siegfried Graf and Harald Luschgy. Foundations of Quantization for Probability Distributions, volume 1730 of Lecture Notes in Mathematics. Springer, Berlin, Heidelberg, 2000. doi: 10.1007/BFb0103945. 64
-
[10]
Judith ter Schure and Peter Grünwald
Peter Grünwald, Rianne de Heide, and Wouter Koolen. Safe testing. Journal of the Royal Statistical Society Series B: Statistical Methodology, 86(5):1091–1128, 2024. doi: 10.1093/jrsssb/qkae011. arXiv:1906.07801. Duplicate cite-key of ‘heide2021’; both retained for backward compatibility with body citation sites established in earlier draft state
-
[11]
On the law of the iterated logarithm
Philip Hartman and Aurel Wintner. On the law of the iterated logarithm. American Journal of Mathematics , 63(1): 169–176, 1941. doi: 10.2307/2371826
-
[12]
URLhttps://doi.org/10.1214/18-PS321
Steven R. Howard, Aaditya Ramdas, Jon McAuliffe, and Jasjeet Sekhon. Time-uniform Chernoff bounds via nonneg- ative supermartingales. Probability Surveys, 17:257–317, 2020. doi: 10.1214/18-PS321
-
[13]
Howard, Aaditya Ramdas, Jon McAuliffe, and Jasjeet Sekhon
Steven R. Howard, Aaditya Ramdas, Jon McAuliffe, and Jasjeet Sekhon. Time-uniform, nonparametric, nonasymp- totic confidence sequences. The Annals of Statistics, 49(2):1055–1080, 2021. doi: 10.1214/20-AOS2002
-
[14]
Parameter-free online convex optimization with sub-exponential noise
Kwang-Sung Jun and Francesco Orabona. Parameter-free online convex optimization with sub-exponential noise. In Proceedings of the 32nd Conference on Learning Theory (COLT), volume 99 ofProceedings of Machine Learning Research, pages 1802–1823, 2019
2019
-
[15]
Emilie Kaufmann and Wouter M. Koolen. Mixture martingales revisited with applications to sequential tests and confidence intervals. Journal of Machine Learning Research, 22(246):1–44, 2021
2021
-
[16]
Khinchin
A. Khinchin. Über einen satz der wahrscheinlichkeitsrechnung. Fundamenta Mathematicae, 6:9–20, 1924. biblio- graphic record; original article published in Fundamenta Mathematicae volume 6 (1924)
1924
-
[17]
A. N. Kolmogorov. Über das gesetz des iterierten logarithmus. Mathematische Annalen, 101:126–135, 1929. doi: 10.1007/BF01454828. digital archive at https://gdz.sub.uni-goettingen.de/id/PPN235181684_0101 (Mathematische Annalen vol. 101)
-
[18]
An approximation of partial sums of independent RV’s, and the sample DF
János Komlós, Péter Major, and Gábor Tusnády. An approximation of partial sums of independent RV’s, and the sample DF. I. Zeitschrift für Wahrscheinlichkeitstheorie und verwandte Gebiete , 32(1):111–131, 1975. doi: 10.1007/ BF00533093
1975
-
[19]
Tze Leung Lai. On confidence sequences. The Annals of Statistics, 4(2):265–280, 1976. doi: 10.1214/aos/1176343406
-
[20]
Jaeyeon Lee, Guantong Qi, Matthew Brady Neeley, Zhandong Liu, and Hyun-Hwan Jeong. Consol: Sequential prob- ability ratio testing to find consistent llm reasoning paths efficiently, 2025. arXiv:2503.17587
arXiv 2025
-
[21]
Martingale methods for sequential estimation of convex functionals and diver- gences
Tudor Manole and Aaditya Ramdas. Martingale methods for sequential estimation of convex functionals and diver- gences. IEEE Transactions on Information Theory, 69(7):4641–4658, 2023. doi: 10.1109/TIT.2023.3250099
-
[22]
Tight concentrations and confidence sequences from the regret of univer- sal portfolio
Francesco Orabona and Kwang-Sung Jun. Tight concentrations and confidence sequences from the regret of univer- sal portfolio. IEEE Transactions on Information Theory, 70(1):436–455, 2024. doi: 10.1109/TIT.2023.3330187
-
[23]
Likelihood, replicability and Robbins’ confidence sequences
Luigi Pace and Alessandra Salvan. Likelihood, replicability and Robbins’ confidence sequences. International Statis- tical Review, 88(3):599–615, 2020. doi: 10.1111/insr.12355
-
[24]
Aaditya Ramdas, Peter Grünwald, Vladimir Vovk, and Glenn Shafer. Game-theoretic statistics and safe anytime-valid inference. Statistical Science, 38(4):576–601, 2023. doi: 10.1214/23-STS894
-
[25]
Boundary crossing probabilities for the Wiener process and sample sums
Herbert Robbins and David Siegmund. Boundary crossing probabilities for the Wiener process and sample sums. The Annals of Mathematical Statistics, 41(5):1410–1429, 1970. doi: 10.1214/aoms/1177696787
-
[26]
Aleksandr Ivanovich Sakhanenko. Rate of convergence in the invariance principle for variables with exponential moments that are not identically distributed. Trudy Instituta Matematiki SO AN SSSR , 3:4–49, 1984. work without DOI; bibliographic record (Trudy Inst. Mat. (Novosibirsk), vol. 3, pp. 4–49, 1984) confirmed via the reference list of https://doi.or...
-
[27]
Game-Theoretic Foundations for Probability and Finance
Glenn Shafer and Vladimir Vovk. Game-Theoretic Foundations for Probability and Finance. Wiley, 2019. 65
2019
-
[28]
Strong approximation theorems for independent random variables and their applications
Qi-Man Shao. Strong approximation theorems for independent random variables and their applications. Journal of Multivariate Analysis, 52(1):107–130, 1995. doi: 10.1006/jmva.1995.1006
-
[29]
Reducing sequential change detection to sequential estimation
Shubhanshu Shekhar and Aaditya Ramdas. Reducing sequential change detection to sequential estimation. InProceed- ings of the 41st International Conference on Machine Learning (ICML) , volume 235 of Proceedings of Machine Learning Research, pages 44628–44642, 2024
2024
-
[30]
On general minimax theorems
Maurice Sion. On general minimax theorems. Pacific Journal of Mathematics, 8(1):171–176, 1958
1958
-
[31]
Étude critique de la notion de collectif
Jean Ville. Étude critique de la notion de collectif . Number 218 in Thèses de l’entre-deux-guerres. Gauthier-Villars, Paris, 1939
1939
-
[32]
Hongjian Wang and Aaditya Ramdas. Catoni-style confidence sequences for heavy-tailed mean estimation.Stochastic Processes and their Applications, 163:168–202, 2023. doi: 10.1016/j.spa.2023.05.007
-
[33]
URL https://proceedings.mlr.press/v152/vovk21b
Ian Waudby-Smith and Aaditya Ramdas. Estimating means of bounded random variables by betting. Journal of the Royal Statistical Society: Series B , 86(1):1–27, 2024. doi: 10.1093/jrsssb/qkad009. 66
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.