LatentWave: JEPA Pretraining for Wireless Foundation Models
Pith reviewed 2026-06-28 00:03 UTC · model grok-4.3
The pith
Predicting masked regions in latent space produces more transferable representations for wireless tasks than reconstructing masked inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
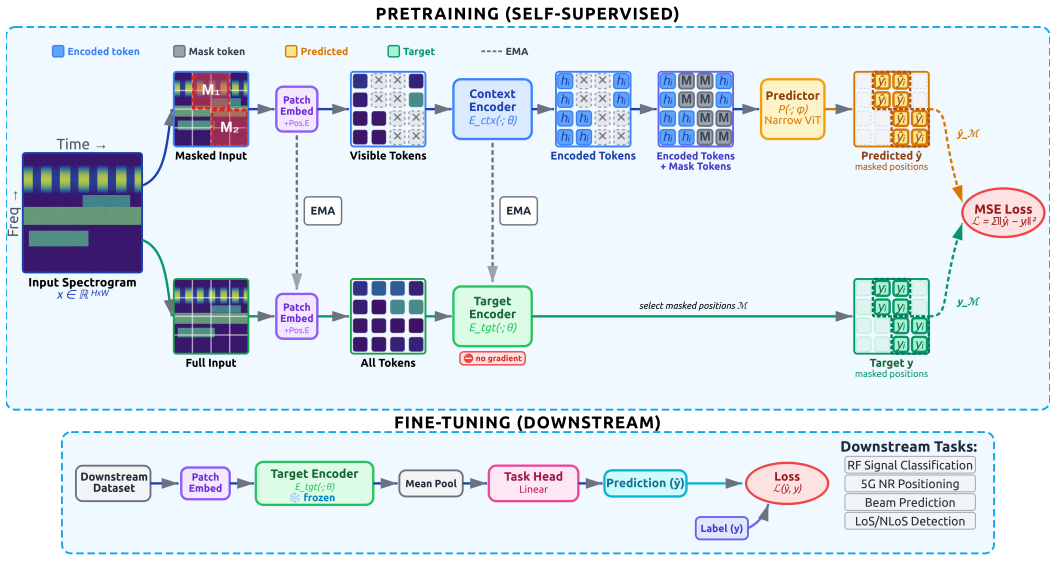
By predicting masked regions in latent space via a Joint-Embedding Predictive Architecture on diverse wireless spectrograms and CSI, LatentWave learns representations that transfer more effectively out of the box to downstream tasks than those from masked input reconstruction, while per-channel patch embeddings with stochastic channel sampling enable processing of variable antenna counts.
What carries the argument
Joint-Embedding Predictive Architecture (JEPA) that predicts masked regions in latent space, using per-channel patch embeddings and stochastic channel sampling.
If this is right
- Frequency masking strongly favors channel-related tasks such as positioning and beam prediction.
- Region masking better preserves discriminability for signal classification.
- The model can process variable antenna counts through stochastic channel sampling during pretraining.
- Representations transfer more effectively across diverse downstream tasks compared to masked input reconstruction.
Where Pith is reading between the lines
- Task-specific choice of masking geometry could be used to optimize performance on a given wireless application.
- The latent-space approach may lower the amount of task-specific labeled data needed in practical wireless deployments.
- Similar latent prediction pretraining could apply to other spectrogram-based domains such as radar or audio.
Load-bearing premise
The idea that masked input reconstruction biases representations toward low-level signal details that reduce transferability, while latent-space prediction avoids this bias.
What would settle it
If LatentWave shows no improvement or worse performance than the WavesFM masked-reconstruction baseline on the four downstream tasks when both are pretrained on the same data, the claim of superior transferability would be falsified.
Figures

read the original abstract
Wireless foundation models have emerged as a promising alternative to building separate models for each wireless task. However, existing approaches rely on masked input reconstruction, which can bias representations toward low-level signal details. In this paper, we propose LatentWave, a wireless foundation model pretrained using a Joint-Embedding Predictive Architecture (JEPA) on diverse wireless spectrograms and channel state information (CSI). By predicting masked regions in latent space, LatentWave learns representations that are more transferable out of the box across diverse downstream tasks. The proposed architecture employs per-channel patch embeddings with stochastic channel sampling during pretraining, allowing it to process variable antenna counts and improving usability across heterogeneous wireless configurations. We evaluate LatentWave on four downstream tasks: RF signal classification, 5G NR positioning, beam prediction, and LoS/NLoS classification, comparing against a masked-modeling baseline (WavesFM) pretrained on the same data. Additionally, we show that the masking geometry introduces a task-dependent inductive bias: frequency masking strongly favors channel-related tasks such as positioning and beam prediction, while region masking better preserves discriminability for signal classification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LatentWave, a wireless foundation model pretrained via Joint-Embedding Predictive Architecture (JEPA) on spectrograms and CSI data. It claims that latent-space prediction yields more transferable representations than masked input reconstruction (as in the WavesFM baseline pretrained on identical data), evaluates this on four downstream tasks (RF signal classification, 5G NR positioning, beam prediction, LoS/NLoS classification), introduces per-channel patch embeddings with stochastic channel sampling to handle variable antenna counts, and reports that masking geometry (frequency vs. region) introduces task-dependent inductive biases.
Significance. If the performance gains hold after isolating the JEPA objective from architectural changes and are supported by rigorous controls, the work would offer a concrete alternative pretraining strategy for wireless foundation models, with potential practical value for heterogeneous antenna configurations and task transfer.
major comments (3)
- [Abstract, §4] Abstract and §4 (experimental comparison): the central claim attributes superior transferability to latent-space JEPA prediction versus masked reconstruction, yet the proposed architecture adds per-channel patch embeddings and stochastic channel sampling; it is not stated whether the WavesFM baseline was reimplemented with these components or retained its original architecture. Without this clarification, gains on the four tasks cannot be isolated to the JEPA objective.
- [Abstract] Abstract: comparisons on four downstream tasks are reported without quantitative results, error bars, data-split details, or statistical significance tests; this prevents assessment of whether the claimed out-of-box transferability is robust or sensitive to post-hoc choices.
- [§5] §5 (masking geometry analysis): the claim that frequency masking favors channel tasks while region masking preserves discriminability for classification requires explicit ablation tables showing performance deltas when swapping masking strategies on the same pretrained model; the current description leaves the strength of this inductive-bias effect unclear.
minor comments (2)
- [§3] Notation for per-channel embeddings and stochastic sampling should be defined with explicit equations or pseudocode in §3 to allow reproduction.
- [Figures in §4] Figure captions for downstream-task results should include the exact number of runs and confidence intervals.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which help improve the clarity and rigor of our work. We provide point-by-point responses below.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (experimental comparison): the central claim attributes superior transferability to latent-space JEPA prediction versus masked reconstruction, yet the proposed architecture adds per-channel patch embeddings and stochastic channel sampling; it is not stated whether the WavesFM baseline was reimplemented with these components or retained its original architecture. Without this clarification, gains on the four tasks cannot be isolated to the JEPA objective.
Authors: We agree that this clarification is important. The WavesFM baseline was retained with its original architecture, as the primary goal was to compare the pretraining objectives (JEPA versus masked reconstruction) using identical pretraining data. The per-channel patch embeddings and stochastic channel sampling are contributions of LatentWave to handle variable antenna counts. We will revise the manuscript to explicitly state this and note that full isolation of the objective would require additional experiments with a matched architecture, which we will discuss as a limitation. revision: partial
-
Referee: [Abstract] Abstract: comparisons on four downstream tasks are reported without quantitative results, error bars, data-split details, or statistical significance tests; this prevents assessment of whether the claimed out-of-box transferability is robust or sensitive to post-hoc choices.
Authors: We will revise the abstract to include key quantitative performance metrics with error bars. Additionally, we will ensure that §4 includes detailed data-split information and statistical significance tests for the reported comparisons to demonstrate the robustness of the results. revision: yes
-
Referee: [§5] §5 (masking geometry analysis): the claim that frequency masking favors channel tasks while region masking preserves discriminability for classification requires explicit ablation tables showing performance deltas when swapping masking strategies on the same pretrained model; the current description leaves the strength of this inductive-bias effect unclear.
Authors: We will add explicit ablation tables in §5 that show the performance deltas for each downstream task when using frequency masking versus region masking on the same pretrained model. This will provide a clearer quantification of the task-dependent inductive biases introduced by the masking geometry. revision: yes
Circularity Check
No circularity: empirical claims rest on external task benchmarks
full rationale
The manuscript advances no derivation chain, equations, or first-principles predictions. Its central claim—that JEPA latent-space prediction yields more transferable representations than masked input reconstruction—is supported solely by empirical comparisons of downstream performance (RF classification, 5G positioning, beam prediction, LoS/NLoS) against a same-data baseline. Architectural additions (per-channel patches, stochastic sampling) are described as implementation choices, not derived quantities. No self-citations, fitted parameters renamed as predictions, or self-definitional reductions appear. The evaluation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Artificial intelligence in 6G wireless networks: Opportunities, Applications, and Challenges,
A. Alhammadi, I. Shayea, A. A. El-Saleh, M. H. Azmi, Z. H. Ismail, L. Kouhalvandi, S. A. Saad, and S. El Kafhali, “Artificial intelligence in 6G wireless networks: Opportunities, Applications, and Challenges,”Int. J. Intell. Syst., 2024
2024
-
[2]
Z. Yang, H. Du, D. Niyato, X. Wang, Y . Zhou, L. Feng, F. Zhou, W. Li, and X. Qiu, “Revolutionizing wireless networks with self-supervised learning: A Pathway to Intelligent Communications,”arXiv preprint arXiv:2406.06872, 2024
arXiv 2024
-
[3]
6G WavesFM: A foundation model for sensing, communication, and localization,
A. Aboulfotouh, E. Mohammed, and H. Abou-Zeid, “6G WavesFM: A foundation model for sensing, communication, and localization,”IEEE Open J. Commun. Soc., vol. 6, 2025
2025
-
[4]
WirelessGPT: A generative pre-trained multi-task learning framework for wireless communication,
T. Yang, P. Zhang, M. Zheng, Y . Shi, L. Jing, J. Huang, and N. Li, “WirelessGPT: A generative pre-trained multi-task learning framework for wireless communication,”IEEE Network, vol. 39, no. 5, pp. 58–65, 2025
2025
-
[5]
IQFM—A wireless foundation model for I/Q streams in AI-Native 6G,
O. Mashaal and H. Abou-Zeid, “IQFM—A wireless foundation model for I/Q streams in AI-Native 6G,”IEEE Open J. Commun. Soc., vol. 7, pp. 1426–1441, 2026
2026
-
[6]
Multimodal wireless foundation models,
A. Aboulfotouh and H. Abou-Zeid, “Multimodal wireless foundation models,”arXiv preprint arXiv:2511.15162, 2025
arXiv 2025
-
[7]
CSI2Vec: Towards a universal CSI feature representation for positioning and channel charting,
V . Palhares, S. Taner, and C. Studer, “CSI2Vec: Towards a universal CSI feature representation for positioning and channel charting,”arXiv preprint arXiv:2506.05237, 2025
arXiv 2025
-
[8]
Self-supervised learning from images with a joint-embedding predictive architecture,
M. Assran, Q. Duval, I. Misra, P. Bojanowski, P. Vincent, M. Rabbat, Y . LeCun, and N. Ballas, “Self-supervised learning from images with a joint-embedding predictive architecture,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), pp. 15619–15629, June 2023
2023
-
[9]
WirelessJEPA: A multi-antenna foundation model using spatio-temporal wireless latent predictions,
V . Chu, O. Mashaal, and H. Abou-Zeid, “WirelessJEPA: A multi-antenna foundation model using spatio-temporal wireless latent predictions,” arXiv preprint arXiv:2601.20190, 2026
arXiv 2026
-
[10]
Structured latent dynam- ics in wireless CSI via homomorphic world models,
S. Naoumi, M. Bennis, and M. Chafii, “Structured latent dynam- ics in wireless CSI via homomorphic world models,”arXiv preprint arXiv:2603.20048, 2026
arXiv 2026
-
[11]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Un- terthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” inProc. Int. Conf. Learn. Represent. (ICLR), 2021
2021
-
[12]
Trust in 5G open RANs through machine learning: RF fingerprinting on the POWDER PAWR platform,
G. Reus-Muns, D. Jaisinghani, K. Sankhe, and K. Chowdhury, “Trust in 5G open RANs through machine learning: RF fingerprinting on the POWDER PAWR platform,” inProc. IEEE Glob. Commun. Conf. (GLOBECOM), 2020
2020
-
[13]
EfficientFi: Toward large-scale lightweight WiFi sensing via CSI compression,
J. Yang, X. Chen, H. Zou, D. Wang, Q. Xu, and L. Xie, “EfficientFi: Toward large-scale lightweight WiFi sensing via CSI compression,”IEEE Internet Things J., vol. 9, no. 13, pp. 13086–13095, 2022
2022
-
[14]
Multimodal CSI- based human activity recognition using GANs,
D. Wang, J. Yang, W. Cui, L. Xie, and S. Sun, “Multimodal CSI- based human activity recognition using GANs,”IEEE Internet of Things Journal, vol. 8, no. 24, pp. 17345–17355, 2021
2021
-
[15]
CommRad RF: A dataset of communication radio signals for detection, identification and classification,
M. Zahid, “CommRad RF: A dataset of communication radio signals for detection, identification and classification,”Zenodo, 2024
2024
-
[16]
DeepMIMO: A generic deep learning dataset for millime- ter wave and massive MIMO applications,
A. Alkhateeb, “DeepMIMO: A generic deep learning dataset for millime- ter wave and massive MIMO applications,” inProc. Inf. Theory Appl. Workshop (ITA), (San Diego, CA), pp. 1–8, Feb 2019
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.