Generalization Guarantees for Multi-Input Neural Operator Learning in Sobolev Spaces
Pith reviewed 2026-06-27 01:53 UTC · model grok-4.3
The pith
Multi-input neural operators obtain Sobolev-norm error bounds that separately quantify each input's contribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
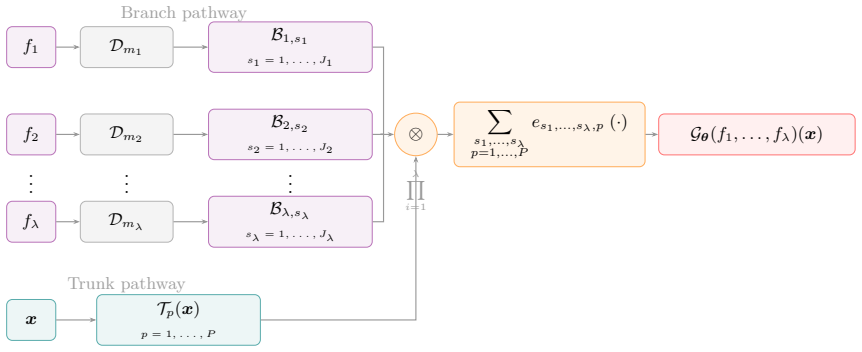
We develop approximation and generalization error estimates for multi-input neural operators, with the output error measured in Sobolev norms. In contrast to standard operator-learning settings with a single input function, our framework allows multiple input functions defined on possibly different domains, with different dimensions and Sobolev regularities. The derived rates explicitly quantify the contribution of each input space to the final error bound. In particular, in the balanced regime, the approximation and generalization rates are governed by the interaction between the input dimensions, regularities, and Sobolev orders, while the dependence on the model complexity retains a log l
What carries the argument
Multi-input neural operator whose Sobolev-norm error bounds are obtained by balancing the approximation and generalization contributions across inputs of heterogeneous dimensions and regularities.
If this is right
- The contribution of each input can be isolated in the final error bound.
- Balanced regimes produce rates determined by the combined effect of all inputs rather than any single one.
- The model-complexity penalty remains slow-growing even with multiple inputs.
- The same analysis covers Sobolev training of such operators.
- The framework applies directly to operator-learning tasks arising in PDEs and scientific computing.
Where Pith is reading between the lines
- Network architectures could be tuned by allocating more parameters to inputs with lower regularity or higher dimension.
- The explicit per-input rates may guide the collection of training data when some inputs are more expensive to sample than others.
- Similar analysis might apply to operators with inputs that are discrete parameters rather than functions.
Load-bearing premise
The multi-input setting with inputs on domains of differing dimensions and Sobolev regularities admits error bounds whose dominant terms arise from the interaction of those dimensions, regularities, and Sobolev orders in a balanced regime.
What would settle it
A numerical experiment on a PDE with two inputs of known but differing dimensions and regularities that shows the observed generalization error failing to match the predicted per-input contributions would falsify the explicit quantification.
Figures
read the original abstract
We develop approximation and generalization error estimates for multi-input neural operators, with the output error measured in Sobolev norms. In contrast to standard operator-learning settings with a single input function, our framework allows multiple input functions defined on possibly different domains, with different dimensions and Sobolev regularities. The derived rates explicitly quantify the contribution of each input space to the final error bound. In particular, in the balanced regime, the approximation and generalization rates are governed by the interaction between the input dimensions, regularities, and Sobolev orders, while the dependence on the model complexity retains a \(\log\log/\log\)-type structure. Our analysis provides a general theoretical framework for multi-input operator learning, including Sobolev training, and is applicable to operator learning problems arising from partial differential equations and scientific computing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops approximation and generalization error estimates for neural operators taking multiple input functions defined on domains of possibly different dimensions and Sobolev regularities, with the output error measured in Sobolev norms. It claims that the derived rates explicitly quantify each input's contribution and, in a balanced regime, are governed by the interaction of the per-input dimensions d_i, regularities s_i and the output Sobolev order, while model complexity enters only through a log-log/log factor. The framework is positioned as applicable to Sobolev training and operator-learning problems from PDEs and scientific computing.
Significance. If the rates are correctly derived under the stated assumptions, the work supplies the first general error bounds that decompose the effect of heterogeneous input spaces, which is directly relevant to multi-physics and coupled PDE applications. The explicit per-input decomposition and the retention of the mild log-log/log complexity dependence are potentially useful for guiding architecture design and sample-complexity estimates in scientific machine learning.
major comments (1)
- [Abstract and balanced-regime definition] Abstract, paragraph 2 and the definition of the balanced regime (presumably §3 or §4): the central claim that rates are governed by an interaction among all inputs rather than collapsing to the weakest input requires explicit inequalities on {d_i, s_i} that prevent any single input from dominating the product-space covering numbers or Sobolev embedding constants. The manuscript does not state or verify these parameter restrictions, so the 'explicit quantification of each input's contribution' holds only conditionally; this is load-bearing for the multi-input novelty.
minor comments (1)
- [§2] Notation for the multi-input operator and the precise Sobolev spaces (e.g., the product domain and the norm on the output) should be introduced with a single displayed equation early in §2 to avoid repeated re-definition.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. The single major comment raises a valid point about the need for explicit parameter restrictions in the balanced regime. We address it below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and balanced-regime definition] Abstract, paragraph 2 and the definition of the balanced regime (presumably §3 or §4): the central claim that rates are governed by an interaction among all inputs rather than collapsing to the weakest input requires explicit inequalities on {d_i, s_i} that prevent any single input from dominating the product-space covering numbers or Sobolev embedding constants. The manuscript does not state or verify these parameter restrictions, so the 'explicit quantification of each input's contribution' holds only conditionally; this is load-bearing for the multi-input novelty.
Authors: We agree that the balanced regime, as currently presented, requires an explicit set of inequalities on the tuples {d_i, s_i} to guarantee that no single input dominates the product-space entropy numbers or the Sobolev embedding constants. The manuscript implicitly assumes such a regime when stating that rates are governed by the interaction of all inputs, but does not spell out the necessary restrictions or verify that they suffice to keep the covering-number product from being controlled by the worst-case factor. We will add a precise definition of the balanced regime (new subsection in §3) that states the required inequalities (e.g., s_i / d_i bounded away from the minimal value by a fixed fraction, and similar control on the output Sobolev index relative to each input), together with a short verification that these conditions ensure the multi-input entropy integral remains comparable to the sum of the individual contributions rather than collapsing to the weakest one. This revision will make the claim unconditional under the stated regime. revision: yes
Circularity Check
No significant circularity; derivation of Sobolev error bounds is self-contained
full rationale
The paper presents approximation and generalization error estimates derived for multi-input neural operators with output measured in Sobolev norms. The abstract describes explicit quantification of per-input contributions in a balanced regime, but provides no equations or steps that reduce by construction to fitted parameters, self-definitions, or load-bearing self-citations. Standard functional-analytic techniques for covering numbers and embeddings appear to be applied independently to the multi-input setting without the central claims collapsing to tautological renamings or ansatzes imported from the authors' prior work. This is the expected non-finding for a theoretical error-bound paper whose claims remain falsifiable via external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Abu-Mostafa
Y. Abu-Mostafa. The Vapnik-Chervonenkis dimension: Information versus complexity in learning. Neural Computation, 1(3):312–317, 1989
1989
-
[2]
Anthony, P
M. Anthony, P. Bartlett, et al. Neural network learning: Theoretical foundations, volume 9. cambridge university press Cambridge, 1999
1999
-
[3]
A. D. Back and T. Chen. Universal approximation of multiple nonlinear operators by neural networks. Neural Computation, 14(11):2561–2566, 2002
2002
-
[4]
Bagby, L
T. Bagby, L. Bos, and N. Levenberg. Multivariate simultaneous approximation. Constructive approximation, 18(4):569–577, 2002
2002
-
[5]
Bartlett, V
P. Bartlett, V. Maiorov, and R. Meir. Almost linear VC dimension bounds for piecewise polynomial networks. Advances in neural information processing systems, 11, 1998
1998
-
[6]
Brenner, L
S. Brenner, L. Scott, and L. Scott. The mathematical theory of finite element methods, volume 3. Springer, 2008
2008
-
[7]
Caponnetto and E
A. Caponnetto and E. De Vito. Optimal rates for the regularized least-squares algorithm. Foundations of Computational mathematics, 7(3):331–368, 2007
2007
-
[8]
M. Chen, H. Jiang, W. Liao, and T. Zhao. Nonparametric regression on low-dimensional manifolds using deep ReLU networks: Function approximation and statistical recovery. Information and Inference: A Journal of the IMA, 11(4):1203–1253, 2022
2022
-
[9]
Chen and H
T. Chen and H. Chen. Approximations of continuous functionals by neural networks with application to dynamic systems. IEEE Transactions on Neural networks, 4(6):910–918, 1993
1993
-
[10]
Chen and H
T. Chen and H. Chen. Universal approximation to nonlinear operators by neural net- works with arbitrary activation functions and its application to dynamical systems. IEEE transactions on neural networks, 6(4):911–917, 1995
1995
-
[11]
Czarnecki, S
W. Czarnecki, S. Osindero, M. Jaderberg, G. Swirszcz, and R. Pascanu. Sobolev training for neural networks. Advances in neural information processing systems, 30, 2017
2017
-
[12]
R. A. DeVore and G. G. Lorentz. Constructive approximation, volume 303. Springer Science & Business Media, 1993
1993
-
[13]
Dong and Z
H. Dong and Z. Li. On theW 2,p estimate for oblique derivative problem in lipschitz domains. International Mathematics Research Notices, 2022(5):3602–3635, 2022. 32
2022
-
[14]
Gilbarg, N
D. Gilbarg, N. S. Trudinger, D. Gilbarg, and N. Trudinger. Elliptic partial differential equations of second order, volume 2. Springer, 1998
1998
-
[15]
Goswami, M
S. Goswami, M. Yin, Y. Yu, and G. Karniadakis. A physics-informed variational Deep- ONet for predicting crack path in quasi-brittle materials. Computer Methods in Applied Mechanics and Engineering, 391:114587, 2022
2022
-
[16]
G¨ uhring, G
I. G¨ uhring, G. Kutyniok, and P. Petersen. Error bounds for approximations with deep ReLU neural networks inW s,p norms. Analysis and Applications, 18(05):803–859, 2020
2020
-
[17]
G¨ uhring and M
I. G¨ uhring and M. Raslan. Approximation rates for neural networks with encodable weights in smoothness spaces. Neural Networks, 134:107–130, 2021
2021
-
[18]
W. Hao, R. P. Li, Y. Xi, T. Xu, and Y. Yang. Multiscale neural networks for approximating green’s functions. SIAM Journal on Scientific Computing, 48(2):C240–C270, 2026
2026
-
[19]
J. He, X. Liu, and J. Xu. Mgno: Efficient parameterization of linear operators via multigrid. In International Conference on Learning Representations, volume 2024, pages 53409–53428, 2024
2024
-
[20]
S. Hill and F. X.-F. Ye. Geometric regularization of autoencoders via observed stochastic dynamics. arXiv preprint arXiv:2604.16282, 2026
Pith/arXiv arXiv 2026
-
[21]
Hu and P
J. Hu and P. Jin. A hybrid iterative method based on mionet for pdes: Theory and numerical examples. Mathematics of Computation, 2025
2025
-
[22]
P. Jin, S. Meng, and L. Lu. Mionet: Learning multiple-input operators via tensor product. SIAM Journal on Scientific Computing, 44(6):A3490–A3514, 2022
2022
-
[23]
Kovachki, S
N. Kovachki, S. Lanthaler, and S. Mishra. On universal approximation and error bounds for fourier neural operators. Journal of Machine Learning Research, 22(290):1–76, 2021
2021
-
[24]
Lanthaler
S. Lanthaler. Operator learning with pca-net: upper and lower complexity bounds. Journal of Machine Learning Research, 24(318):1–67, 2023
2023
-
[25]
Lanthaler, S
S. Lanthaler, S. Mishra, and G. Karniadakis. Error estimates for DeepONets: A deep learn- ing framework in infinite dimensions. Transactions of Mathematics and Its Applications, 6(1):tnac001, 2022
2022
-
[26]
J. Li, S. Huang, H. Feng, D.-X. Zhou, and G. Kutyniok. Sparse-aware neural networks for nonlinear functionals: Mitigating the exponential dependence on dimension. arXiv preprint arXiv:2604.06774, 2026
Pith/arXiv arXiv 2026
-
[27]
Z. Li, D. Z. Huang, B. Liu, and A. Anandkumar. Fourier neural operator with learned defor- mations for pdes on general geometries. Journal of Machine Learning Research, 24(388):1– 26, 2023
2023
-
[28]
Z. Li, N. Kovachki, K. Azizzadenesheli, B. Liu, K. Bhattacharya, A. Stuart, and A. Anand- kumar. Fourier neural operator for parametric partial differential equations. arXiv preprint arXiv:2010.08895, 2020. 33
Pith/arXiv arXiv 2010
-
[29]
H. Liu, B. Dahal, R. Lai, and W. Liao. Generalization error guaranteed auto-encoder-based nonlinear model reduction for operator learning. Applied and Computational Harmonic Analysis, 74:101717, 2025
2025
-
[30]
H. Liu, H. Yang, M. Chen, T. Zhao, and W. Liao. Deep nonparametric estimation of operators between infinite dimensional spaces. Journal of Machine Learning Research, 25(24):1–67, 2024
2024
-
[31]
H. Liu, Z. Zhang, W. Liao, and H. Schaeffer. Neural scaling laws of deep ReLU and deep operator network: A theoretical study. arXiv preprint arXiv:2410.00357, 2024
Pith/arXiv arXiv 2024
-
[32]
L. Lu, P. Jin, and G. E. Karniadakis. Deeponet: Learning nonlinear operators for identifying differential equations based on the universal approximation theorem of operators. arXiv preprint arXiv:1910.03193, 2019
Pith/arXiv arXiv 1910
-
[33]
Marcati and C
C. Marcati and C. Schwab. Exponential convergence of deep operator networks for elliptic partial differential equations. SIAM Journal on Numerical Analysis, 61(3):1513–1545, 2023
2023
-
[34]
H. N. Mhaskar and N. Hahm. Neural networks for functional approximation and system identification. Neural Computation, 9(1):143–159, 1997
1997
-
[35]
J. A. A. Opschoor, P. C. Petersen, and C. Schwab. Deep ReLU networks and high-order finite element methods. Analysis and Applications, 18(05):715–770, 2020
2020
-
[36]
I. Pinelis. Optimum bounds for the distributions of martingales in banach spaces. The Annals of Probability, pages 1679–1706, 1994
1994
-
[37]
Schumaker
L. Schumaker. Spline functions: basic theory. Cambridge university press, 2007
2007
-
[38]
Schwab, A
C. Schwab, A. Stein, and J. Zech. Deep operator network approximation rates for lipschitz operators. Analysis and Applications, 24(01):199–239, 2026
2026
-
[39]
Z. Shi, J. Fan, L. Song, D.-X. Zhou, and J. A. Suykens. Nonlinear functional regression by functional deep neural network with kernel embedding. Journal of Machine Learning Research, 26(284):1–49, 2025
2025
-
[40]
J. W. Siegel. Optimal approximation rates for deep ReLU neural networks on sobolev and besov spaces. Journal of Machine Learning Research, 24(357):1–52, 2023
2023
-
[41]
L. Song, Y. Liu, J. Fan, and D. Zhou. Approximation of smooth functionals using deep ReLU networks. Neural Networks, 166:424–436, 2023
2023
-
[42]
Srinivas and F
S. Srinivas and F. Fleuret. Knowledge transfer with jacobian matching. In International conference on machine learning, pages 4723–4731. PMLR, 2018
2018
-
[43]
Vlassis and W
N. Vlassis and W. Sun. Sobolev training of thermodynamic-informed neural networks for interpretable elasto-plasticity models with level set hardening. Computer Methods in Applied Mechanics and Engineering, 377:113695, 2021. 34
2021
-
[44]
N. N. Vlassis, R. Ma, and W. Sun. Geometric deep learning for computational mechan- ics part i: Anisotropic hyperelasticity. Computer Methods in Applied Mechanics and Engineering, 371:113299, 2020
2020
-
[45]
S. Wang, H. Wang, and P. Perdikaris. Learning the solution operator of parametric partial differential equations with physics-informed DeepONets. Science advances, 7(40):eabi8605, 2021
2021
-
[46]
A. Weihs and H. Schaeffer. Generalization bounds and statistical guarantees for multi-task and multiple operator learning with mno networks. arXiv preprint arXiv:2604.01961, 2026
arXiv 2026
-
[47]
A. Weihs and H. Schaeffer. Multiple neural operators achieve near-optimal rates for multi- task learning. arXiv preprint arXiv:2605.22724, 2026
Pith/arXiv arXiv 2026
- [48]
-
[49]
J.-Q. Yang and L. Shi. Efficient approximation for encoder–decoder neural operators via variation spaces. arXiv preprint arXiv:2606.01244, 2026
Pith/arXiv arXiv 2026
-
[50]
Y. Yang. DeepONet for solving nonlinear partial differential equations with physics- informed training. Neural Networks, page 108490, 2025
2025
-
[51]
Y. Yang and J. He. Deep neural networks with general activations: Super-convergence in sobolev norms. arXiv preprint arXiv:2508.05141, 2025
arXiv 2025
-
[52]
Y. Yang, Y. Wu, H. Yang, and Y. Xiang. Nearly optimal approximation rates for deep super ReLU networks on Sobolev spaces. arXiv preprint arXiv:2310.10766, 2023
arXiv 2023
-
[53]
Yang and Y
Y. Yang and Y. Xiang. Approximation of functionals by neural network without curse of dimensionality. Journal of Machine Learning, 1(4):342–372, 2022
2022
-
[54]
Y. Yang, H. Yang, and Y. Xiang. Nearly optimal VC-dimension and pseudo-dimension bounds for deep neural network derivatives. In Thirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[55]
Z. Yang, S. Huang, H. Feng, and D.-X. Zhou. Spherical analysis of learning nonlinear functionals. Constructive Approximation, pages 1–29, 2026
2026
-
[56]
Yarotsky
D. Yarotsky. Error bounds for approximations with deep ReLU networks. Neural Networks, 94:103–114, 2017
2017
-
[57]
Yarotsky and A
D. Yarotsky and A. Zhevnerchuk. The phase diagram of approximation rates for deep neural networks. Advances in neural information processing systems, 33:13005–13015, 2020. 35 A Proofs for Approximation Error This section contains the detailed proof of the approximation error estimate. The construc- tion consists of four steps. Step 1, which concerns the d...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.