Principled Algorithms for Optimizing Generalized Metrics in Multi-Label Learning
Pith reviewed 2026-06-29 14:25 UTC · model grok-4.3
The pith
Surrogate losses for generalized multi-label metrics decompose exactly and admit H-consistency bounds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
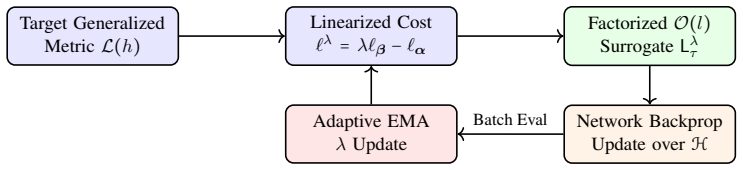
Within the empirical utility maximization framework, novel surrogate losses for a broad class of generalized metrics in multi-label learning admit provable H-consistency bounds and decompose exactly into O(l) time operations without approximations.
What carries the argument
The combinatorially formulated surrogate loss functions that decompose exactly for generalized linear-fractional metrics.
If this is right
- The surrogates enable non-asymptotic H-consistency guarantees for the hypothesis class and finite samples.
- Optimization of metrics like F-measure and Jaccard index becomes feasible in strictly linear time.
- The MMO algorithms achieve robust scalability in high-sparsity deep learning settings.
- Performance improves over continuous baselines on datasets such as MS-COCO and Reuters-21578.
Where Pith is reading between the lines
- The decomposition property may allow integration with existing multi-label frameworks without additional overhead.
- Extensions to other combinatorial metrics could follow if they satisfy the linear-fractional condition.
- Practical deployment in real-time systems becomes viable due to the linear scaling.
Load-bearing premise
The target metrics must be generalized linear-fractional functions for which the surrogate construction works.
What would settle it
Finding a generalized metric outside the linear-fractional class where the surrogate fails to decompose in O(l) time or loses the H-consistency property.
Figures
read the original abstract
Many real-world classification tasks require predicting multiple labels per instance, necessitating the optimization of complex evaluation metrics such as the $F$-measure and Jaccard index. While the Empirical Utility Maximization (EUM) framework is natural for these population-level metrics, existing theoretical results are largely limited to asymptotic Bayes-consistency. In this paper, we develop principled learning algorithms for optimizing a broad class of generalized metrics within the EUM framework, grounded in the stronger notion of $H$-consistency. Our key contribution is the design of novel surrogate loss functions for multi-label learning that admit provable $H$-consistency bounds, enabling optimization with non-asymptotic guarantees tailored to the hypothesis class and finite samples. Crucially, we prove these combinatorially formulated surrogates decompose exactly, operating in strictly $O(l)$ time without approximations. Building on this foundation, we introduce MMO (Multi-Label Metric Optimization), a new family of algorithms for optimizing generalized linear-fractional metrics. We validate our approach through extensive experiments, demonstrating robust scalability and superior performance over state-of-the-art continuous baselines on large-scale datasets (MS-COCO, Reuters-21578) in high-sparsity, deep learning regimes. Our results offer both theoretical rigor and practical effectiveness for general multi-label metric optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops surrogate loss functions for multi-label learning under the Empirical Utility Maximization (EUM) framework. It claims to establish H-consistency bounds and exact (non-approximate) O(l) decomposition for combinatorially formulated surrogates when the target metrics belong to the generalized linear-fractional class, introduces the MMO family of algorithms, and reports superior empirical performance versus continuous baselines on MS-COCO and Reuters-21578 in high-sparsity deep-learning regimes.
Significance. If the H-consistency and exact O(l) decomposition results hold for the stated class, the work would strengthen the theoretical toolkit for multi-label metric optimization by supplying non-asymptotic, hypothesis-class-specific guarantees that go beyond the asymptotic Bayes-consistency results currently available. The linear-time property would be practically valuable for large label cardinalities, and the reported experiments on large-scale datasets provide concrete evidence of scalability.
major comments (2)
- [Abstract] Abstract: The title and first sentence refer to optimization of a 'broad class of generalized metrics,' yet the technical claims (H-consistency, exact O(l) decomposition, MMO algorithms) are explicitly restricted to 'generalized linear-fractional metrics'; this scope mismatch is load-bearing for the generality asserted in the headline contribution.
- [Abstract] Abstract: The central claim that 'we prove these combinatorially formulated surrogates decompose exactly, operating in strictly O(l) time without approximations' is asserted without derivation steps, explicit assumptions on the metric class, or even a worked example (e.g., expansion for F1 or Jaccard), preventing verification of the O(l) property that underpins the algorithmic contribution.
minor comments (1)
- The abstract introduces the symbol l without defining it as the label cardinality; this should be stated on first use for readability.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We address each major comment below and will revise the manuscript to improve precision and verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract: The title and first sentence refer to optimization of a 'broad class of generalized metrics,' yet the technical claims (H-consistency, exact O(l) decomposition, MMO algorithms) are explicitly restricted to 'generalized linear-fractional metrics'; this scope mismatch is load-bearing for the generality asserted in the headline contribution.
Authors: We agree there is a scope mismatch. The technical results (H-consistency bounds, exact decomposition, and MMO algorithms) are developed for the class of generalized linear-fractional metrics. We will revise the abstract (and consider a title adjustment) to consistently and precisely refer to this class rather than the broader phrasing, while noting that the class includes standard metrics such as F1 and Jaccard. revision: yes
-
Referee: [Abstract] Abstract: The central claim that 'we prove these combinatorially formulated surrogates decompose exactly, operating in strictly O(l) time without approximations' is asserted without derivation steps, explicit assumptions on the metric class, or even a worked example (e.g., expansion for F1 or Jaccard), preventing verification of the O(l) property that underpins the algorithmic contribution.
Authors: The abstract is a high-level summary; the full proof, assumptions on the metric class, and O(l) decomposition appear in the main text. To address the request for easier verification, we will add a worked example of the exact decomposition for the F1 metric (and state the assumptions explicitly) in the revised manuscript. revision: yes
Circularity Check
No circularity; derivation self-contained within defined metric class
full rationale
Abstract and summary contain no equations, no fitted parameters renamed as predictions, and no self-citations. The claimed O(l) exact decomposition and H-consistency are stated to hold inside the explicitly delimited generalized linear-fractional class; the paper does not claim the result for metrics outside that class. This is a standard restriction of a theorem to its hypothesis class rather than a self-referential reduction. No load-bearing step reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Awasthi, A
P. Awasthi, A. Mao, M. Mohri, and Y. Zhong. H -consistency bounds for surrogate loss minimizers. In International Conference on Machine Learning, 2022 a
2022
-
[2]
Awasthi, A
P. Awasthi, A. Mao, M. Mohri, and Y. Zhong. Multi-class H -consistency bounds. In Advances in Neural Information Processing Systems, 2022 b
2022
-
[3]
Bao and M
H. Bao and M. Sugiyama. Calibrated surrogate maximization of linear-fractional utility in binary classification. In International Conference on Artificial Intelligence and Statistics, pages 2337--2347, 2020
2020
-
[4]
P. L. Bartlett, M. I. Jordan, and J. D. McAuliffe. Convexity, classification, and risk bounds. Journal of the American Statistical Association, 101 0 (473): 0 138--156, 2006
2006
-
[5]
B \'e n \'e dict, H
G. B \'e n \'e dict, H. Koops, D. Odijk, M. de Rijke, et al. sigmoidf1: A smooth f1 score surrogate loss for multilabel classification. Transactions on Machine Learning Research, 2022
2022
-
[6]
Berger and S
A. Berger and S. Guda. Threshold optimization for f measure of macro-averaged precision and recall. Pattern Recognition, 102: 0 107250, 2020
2020
-
[7]
J. Berkson. Application of the logistic function to bio-assay. Journal of the American Statistical Association, 39: 0 357--365, 1944
1944
-
[8]
J. Berkson. Why I prefer logits to probits. Biometrics, 7 0 (4): 0 327--339, 1951
1951
-
[9]
Berman, A
M. Berman, A. R. Triki, and M. B. Blaschko. The lov \'a sz-softmax loss: A tractable surrogate for the optimization of the intersection-over-union measure in neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4413--4421, 2018
2018
-
[10]
Bogatinovski, L
J. Bogatinovski, L. Todorovski, S. D z eroski, and D. Kocev. Comprehensive comparative study of multi-label classification methods. Expert Systems with Applications, 203: 0 117215, 2022
2022
-
[11]
o r \'e nyi, K. Dembczynski, and E. H \
R. Busa-Fekete, B. Sz \"o r \'e nyi, K. Dembczynski, and E. H \"u llermeier. Online f-measure optimization. In Advances in Neural Information Processing Systems, 2015
2015
-
[12]
Busa-Fekete, H
R. Busa-Fekete, H. Choi, K. Dembczynski, C. Gentile, H. Reeve, and B. Szorenyi. Regret bounds for multilabel classification in sparse label regimes. In Advances in Neural Information Processing Systems, pages 5404--5416, 2022
2022
-
[13]
Cheng, Y
F. Cheng, Y. Zhou, J. Gao, and S. Zheng. Efficient optimization of-measure with cost-sensitive svm. Mathematical Problems in Engineering, 2016 0 (1): 0 1--11, 2016
2016
-
[14]
Cheng, E
W. Cheng, E. H \"u llermeier, and K. J. Dembczynski. Bayes optimal multilabel classification via probabilistic classifier chains. In International Conference on Machine Learning, pages 279--286, 2010
2010
-
[15]
Cortes, A
C. Cortes, A. Mao, C. Mohri, M. Mohri, and Y. Zhong. Cardinality-aware set prediction and top- k classification. In Advances in Neural Information Processing Systems, 2024
2024
-
[16]
Cortes, A
C. Cortes, A. Mao, M. Mohri, and Y. Zhong. Balancing the scales: A theoretical and algorithmic framework for learning from imbalanced data. In International Conference on Machine Learning, 2025 a
2025
-
[17]
Cortes, M
C. Cortes, M. Mohri, and Y. Zhong. Improved balanced classification with theoretically grounded loss functions. In Advances in Neural Information Processing Systems, 2025 b
2025
-
[18]
Cortes, A
C. Cortes, A. Mao, M. Mohri, and Y. Zhong. Optimized deferral for imbalanced settings. In International Conference on Machine Learning, 2026 a
2026
-
[19]
Cortes, M
C. Cortes, M. Mohri, and Y. Zhong. A theoretical framework for modular learning of robust generative models. In International Conference on Machine Learning, 2026 b
2026
-
[20]
Dembczynski, W
K. Dembczynski, W. Waegeman, W. Cheng, and E. H \"u llermeier. An exact algorithm for f-measure maximization. In Advances in Neural Information Processing Systems, 2011
2011
-
[21]
Dembczynski, W
K. Dembczynski, W. Kot owski, and E. H \"u llermeier. Consistent multilabel ranking through univariate loss minimization. In International Conference on Machine Learning, pages 1347--1354, 2012
2012
-
[22]
Dembczynski, A
K. Dembczynski, A. Jachnik, W. Kotlowski, W. Waegeman, and E. H \"u llermeier. Optimizing the f-measure in multi-label classification: Plug-in rule approach versus structured loss minimization. In International Conference on Machine Learning, pages 1130--1138, 2013
2013
-
[23]
Dembczy \'n ski, W
K. Dembczy \'n ski, W. Kot owski, O. Koyejo, and N. Natarajan. Consistency analysis for binary classification revisited. In International Conference on Machine Learning, pages 961--969, 2017
2017
-
[24]
J. Deng, S. Satheesh, A. Berg, and F. Li. Fast and balanced: Efficient label tree learning for large scale object recognition. In Advances in Neural Information Processing Systems, 2011
2011
-
[25]
G. DeSalvo, C. Mohri, M. Mohri, and Y. Zhong. Budgeted multiple-expert deferral. arXiv preprint arXiv:2510.26706, 2025
-
[26]
E. Eban, M. Schain, A. Mackey, A. Gordon, R. Rifkin, and G. Elidan. Scalable learning of non-decomposable objectives. In Artificial Intelligence and Statistics, pages 832--840, 2017
2017
-
[27]
Elisseeff and J
A. Elisseeff and J. Weston. A kernel method for multi-labelled classification. In Advances in Neural Information Processing Systems, 2001
2001
-
[28]
Fathony and Z
R. Fathony and Z. Kolter. Ap-perf: Incorporating generic performance metrics in differentiable learning. In International Conference on Artificial Intelligence and Statistics, pages 4130--4140, 2020
2020
-
[29]
Gao and Z.-H
W. Gao and Z.-H. Zhou. On the consistency of multi-label learning. In Conference on Learning Theory, pages 341--358, 2011
2011
-
[30]
Ghosh, H
A. Ghosh, H. Kumar, and P. S. Sastry. Robust loss functions under label noise for deep neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, 2017
2017
-
[31]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770--778, 2016
2016
-
[32]
Joachims
T. Joachims. A support vector method for multivariate performance measures. In International Conference on Machine Learning, pages 377--384, 2005
2005
-
[33]
Kapoor, R
A. Kapoor, R. Viswanathan, and P. Jain. Multilabel classification using bayesian compressed sensing. In Advances in Neural Information Processing Systems, 2012
2012
-
[34]
P. Kar, H. Narasimhan, and P. Jain. Online and stochastic gradient methods for non-decomposable loss functions. In Advances in Neural Information Processing Systems, 2014
2014
-
[35]
D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[36]
Kotlowski and K
W. Kotlowski and K. Dembczy \'n ski. Surrogate regret bounds for generalized classification performance metrics. In Asian Conference on Machine Learning, pages 301--316, 2016
2016
-
[37]
W. Kot owski, M. Wydmuch, E. Schultheis, R. Babbar, and K. Dembczy \'n ski. A general online algorithm for optimizing complex performance metrics. arXiv preprint arXiv:2406.14743, 2024
-
[38]
Koyejo, N
O. Koyejo, N. Natarajan, P. Ravikumar, and I. S. Dhillon. Consistent binary classification with generalized performance metrics. In Advances in Neural Information Processing Systems, pages 2744--2752, 2014
2014
-
[39]
O. O. Koyejo, N. Natarajan, P. K. Ravikumar, and I. S. Dhillon. Consistent multilabel classification. In Advances in Neural Information Processing Systems, 2015
2015
-
[40]
D. D. Lewis. Evaluating and optimizing autonomous text classification systems. In Proceedings of the 18th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 246--254, 1995
1995
-
[41]
T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll \'a r, and C. L. Zitnick. Microsoft coco: Common objects in context. In European Conference on Computer Vision, pages 740--755, 2014
2014
-
[42]
Y. Lin. A note on margin-based loss functions in classification. Statistics & Probability Letters, 68 0 (1): 0 73--82, 2004
2004
-
[43]
Z. C. Lipton, C. Elkan, and B. Narayanaswamy. Thresholding classifiers to maximize f1 score. Stat, 1050: 0 14, 2014
2014
-
[44]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[45]
J. Luo, H. Qiao, and B. Zhang. A minimax probability machine for nondecomposable performance measures. IEEE Transactions on Neural Networks and Learning Systems, 34 0 (5): 0 2353--2365, 2021
2021
-
[46]
A. Mao. Theory and Algorithms for Learning with Multi-Class Abstention and Multi-Expert Deferral. PhD thesis, New York University, 2025
2025
-
[47]
A. Mao, C. Mohri, M. Mohri, and Y. Zhong. Two-stage learning to defer with multiple experts. In Advances in Neural Information Processing Systems, 2023 a
2023
-
[48]
A. Mao, M. Mohri, and Y. Zhong. H -consistency bounds: Characterization and extensions. In Advances in Neural Information Processing Systems, 2023 b
2023
-
[49]
A. Mao, M. Mohri, and Y. Zhong. H -consistency bounds for pairwise misranking loss surrogates. In International conference on Machine learning, 2023 c
2023
-
[50]
A. Mao, M. Mohri, and Y. Zhong. Ranking with abstention. In ICML 2023 Workshop The Many Facets of Preference-Based Learning, 2023 d
2023
-
[51]
A. Mao, M. Mohri, and Y. Zhong. Structured prediction with stronger consistency guarantees. In Advances in Neural Information Processing Systems, 2023 e
2023
-
[52]
A. Mao, M. Mohri, and Y. Zhong. Cross-entropy loss functions: Theoretical analysis and applications. In International Conference on Machine Learning, 2023 f
2023
-
[53]
A. Mao, M. Mohri, and Y. Zhong. Principled approaches for learning to defer with multiple experts. In International Symposium on Artificial Intelligence and Mathematics, 2024 a
2024
-
[54]
A. Mao, M. Mohri, and Y. Zhong. Predictor-rejector multi-class abstention: Theoretical analysis and algorithms. In International Conference on Algorithmic Learning Theory, pages 822--867, 2024 b
2024
-
[55]
A. Mao, M. Mohri, and Y. Zhong. Theoretically grounded loss functions and algorithms for score-based multi-class abstention. In International Conference on Artificial Intelligence and Statistics, pages 4753--4761, 2024 c
2024
-
[56]
A. Mao, M. Mohri, and Y. Zhong. H -consistency guarantees for regression. In International Conference on Machine Learning, pages 34712--34737, 2024 d
2024
-
[57]
A. Mao, M. Mohri, and Y. Zhong. Multi-label learning with stronger consistency guarantees. In Advances in Neural Information Processing Systems, 2024 e
2024
-
[58]
A. Mao, M. Mohri, and Y. Zhong. Realizable H -consistent and B ayes-consistent loss functions for learning to defer. In Advances in Neural Information Processing Systems, 2024 f
2024
-
[59]
A. Mao, M. Mohri, and Y. Zhong. Regression with multi-expert deferral. In International Conference on Machine Learning, pages 34738--34759, 2024 g
2024
-
[60]
A. Mao, M. Mohri, and Y. Zhong. A universal growth rate for learning with smooth surrogate losses. In Advances in Neural Information Processing Systems, 2024 h
2024
-
[61]
A. Mao, M. Mohri, and Y. Zhong. Mastering multiple-expert routing: Realizable H -consistency and strong guarantees for learning to defer. In International Conference on Machine Learning, 2025 a
2025
-
[62]
A. Mao, M. Mohri, and Y. Zhong. Enhanced -consistency bounds. In International Conference on Algorithmic Learning Theory, 2025 b
2025
-
[63]
A. Mao, M. Mohri, and Y. Zhong. Principled algorithms for optimizing generalized metrics in binary classification. In International Conference on Machine Learning, 2025 c
2025
-
[64]
A. K. McCallum. Multi-label text classification with a mixture model trained by em. In AAAI Workshop on Text Learning, 1999
1999
-
[65]
A. K. Menon, A. S. Rawat, S. Reddi, and S. Kumar. Multilabel reductions: what is my loss optimising? In Advances in Neural Information Processing Systems, 2019
2019
-
[66]
Mohri, D
C. Mohri, D. Andor, E. Choi, M. Collins, A. Mao, and Y. Zhong. Learning to reject with a fixed predictor: Application to decontextualization. In International Conference on Learning Representations, 2024
2024
-
[67]
Mohri and Y
M. Mohri and Y. Zhong. Mind the gap: Structure-aware consistency in preference learning. In International Conference on Machine Learning, 2026 a
2026
-
[68]
Mohri and Y
M. Mohri and Y. Zhong. Linear-core surrogates: Smooth loss functions with linear rates for classification and structured prediction. In International Conference on Machine Learning, 2026 b
2026
-
[69]
Mohri and Y
M. Mohri and Y. Zhong. Beyond tsybakov: Model margin noise and H -consistency bounds. In International Symposium on Artificial Intelligence and Mathematics, 2026 c
2026
-
[70]
Mohri, A
M. Mohri, A. Rostamizadeh, and A. Talwalkar. Foundations of Machine Learning. MIT Press, second edition, 2018
2018
-
[71]
Narasimhan, R
H. Narasimhan, R. Vaish, and S. Agarwal. On the statistical consistency of plug-in classifiers for non-decomposable performance measures. In Advances in Neural Information Processing Systems, 2014
2014
-
[72]
Narasimhan, P
H. Narasimhan, P. Kar, and P. Jain. Optimizing non-decomposable performance measures: A tale of two classes. In International Conference on Machine Learning, pages 199--208, 2015 a
2015
-
[73]
Narasimhan, H
H. Narasimhan, H. Ramaswamy, A. Saha, and S. Agarwal. Consistent multiclass algorithms for complex performance measures. In International Conference on Machine Learning, pages 2398--2407, 2015 b
2015
-
[74]
Narasimhan, W
H. Narasimhan, W. Pan, P. Kar, P. Protopapas, and H. G. Ramaswamy. Optimizing the multiclass f-measure via biconcave programming. In International Conference on Data Mining, pages 1101--1106, 2016
2016
-
[75]
Narasimhan, A
H. Narasimhan, A. Cotter, and M. Gupta. Optimizing generalized rate metrics with three players. In Advances in Neural Information Processing Systems, 2019
2019
-
[76]
Narasimhan, H
H. Narasimhan, H. G. Ramaswamy, S. K. Tavker, D. Khurana, P. Netrapalli, and S. Agarwal. Consistent multiclass algorithms for complex metrics and constraints. Journal of Machine Learning Research, 25 0 (367): 0 1--81, 2024
2024
-
[77]
Natarajan, O
N. Natarajan, O. Koyejo, P. Ravikumar, and I. Dhillon. Optimal classification with multivariate losses. In International Conference on Machine Learning, pages 1530--1538, 2016
2016
-
[78]
S. P. Parambath, N. Usunier, and Y. Grandvalet. Optimizing F -measures by cost-sensitive classification. In Advances in Neural Information Processing Systems, pages 2123--2131, 2014
2014
-
[79]
Petterson and T
J. Petterson and T. Caetano. Submodular multi-label learning. In Advances in Neural Information Processing Systems, 2011
2011
-
[80]
Pillai, G
I. Pillai, G. Fumera, and F. Roli. Designing multi-label classifiers that maximize f measures: State of the art. Pattern Recognition, 61: 0 394--404, 2017
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.