MVDGC: Joint 3D and 2D Multi-view Pedestrian Detection via Dual Geometric Constraints
Pith reviewed 2026-07-02 19:04 UTC · model grok-4.3
The pith
3D cylindrical queries unify bird's-eye and image-view pedestrian localization into one refinement task by enforcing dual geometric constraints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
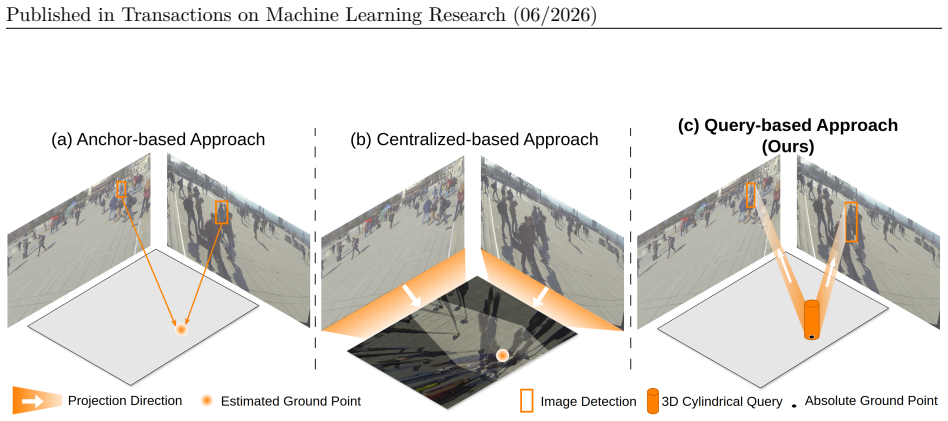
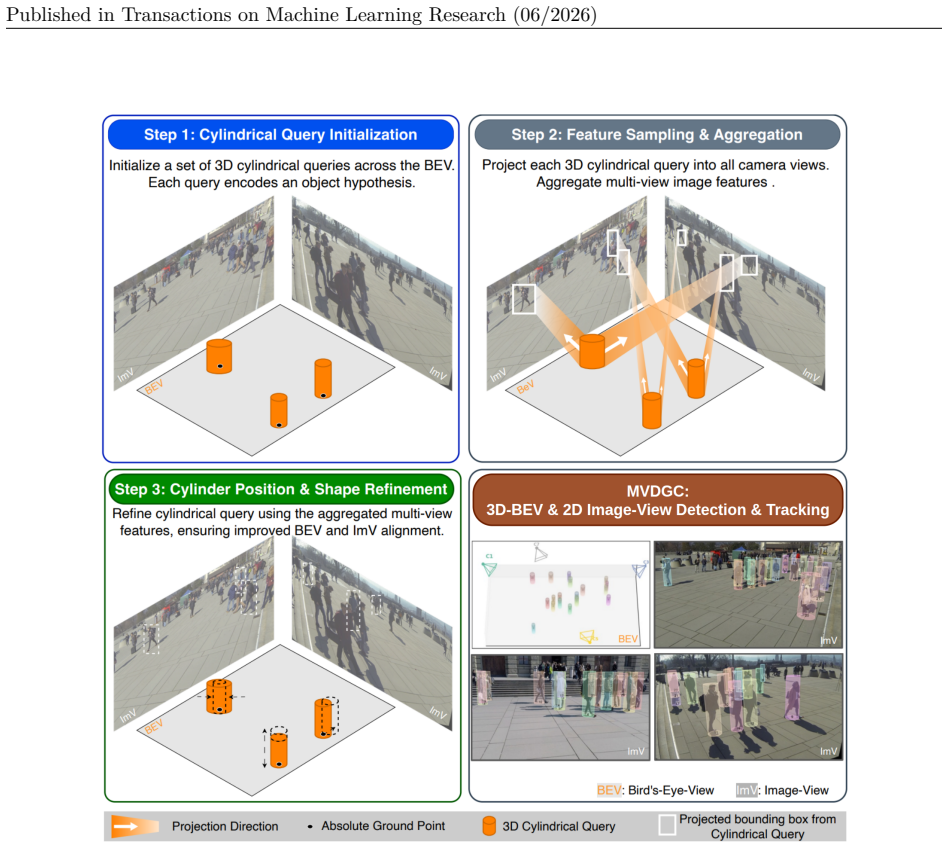
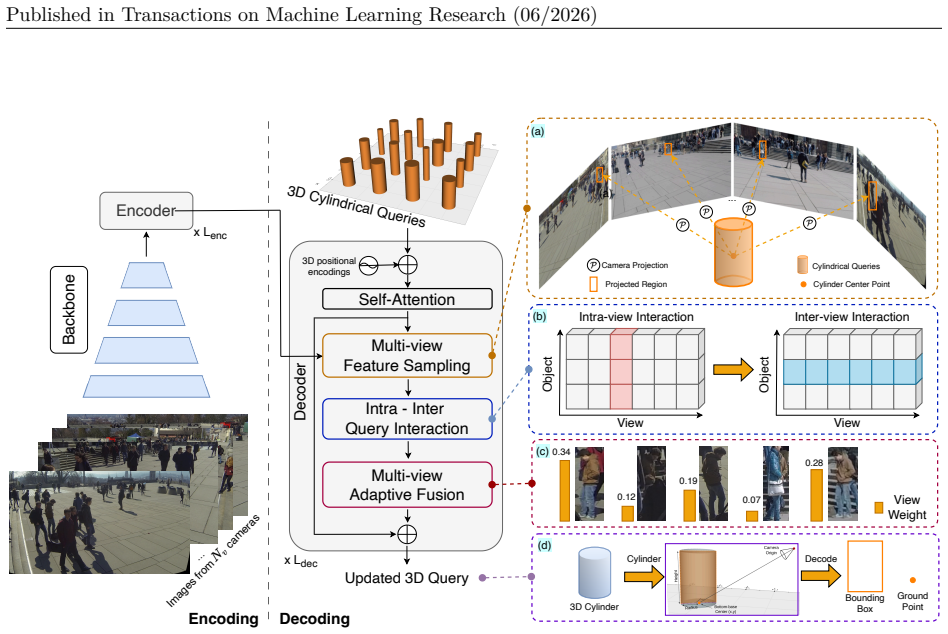
The 3D cylindrical query enables the unification of BEV and ImV localization into a single task: 3D cylinder position and shape refinement. By modeling each pedestrian as a vertical cylinder whose center lies on the BEV plane and whose projection casts a rectangular box in the image views, the queries extract 2D features from the intact image-view features using camera projection, eliminating projection-induced distortions.
What carries the argument
3D cylindrical queries that model each pedestrian as a vertical cylinder whose BEV-plane center and image-view rectangular projection supply dual geometric constraints.
If this is right
- Joint optimization of cylinder position and shape improves localization accuracy in densely populated scenes where projection blur is severe.
- Multi-view consistency between BEV points and image boxes functions as a direct geometric constraint inside the main task instead of an auxiliary signal.
- Feature extraction occurs on undistorted image features, removing the spatial-structure break caused by perspective transformation.
- The single-task formulation removes the need to maintain separate pipelines for 3D ground localization and 2D bounding-box detection.
Where Pith is reading between the lines
- The cylinder representation could be tested on other upright objects such as vehicles if their vertical extent can be approximated without large shape error.
- The same query mechanism might allow end-to-end training of multi-view systems that output both 3D tracks and 2D detections without post-processing fusion steps.
- If the dual-constraint refinement proves stable, it could reduce reliance on dense BEV feature maps and lower memory cost in real-time multi-camera setups.
Load-bearing premise
Modeling each pedestrian as a vertical cylinder centered on the BEV plane with rectangular projections in the images supplies accurate constraints without introducing new errors during feature extraction.
What would settle it
Compare end-to-end localization error of the joint cylinder-refinement model against a standard BEV-projection baseline on the same multi-view sequences with high pedestrian density; a statistically significant drop in error for the cylinder model would support the claim.
Figures


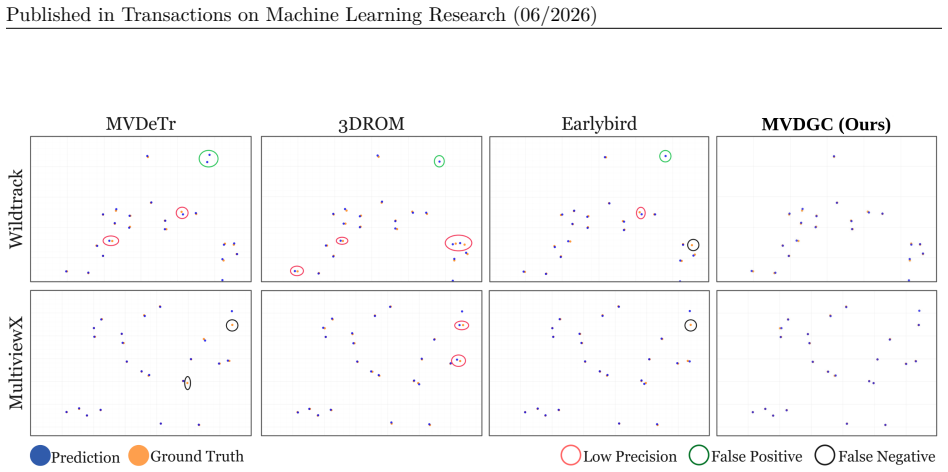
read the original abstract
The core challenge in multi-view pedestrian detection (MVPD) lies in effective aggregation of visual features from different viewpoints for robust occlusion reasoning. Recent approaches have addressed this by first projecting image-view features onto a Bird's Eye View (BEV) map, where ground localization is then performed. Despite impressive performance, the perspective transformation induces severe distortion, causing spatial structure break and degrading the quality of object feature extraction. The blurred and ambiguous features hinder accurate BEV point localization, especially in densely populated regions. Moreover, the strong mutual relationship between the BEV ground point and image bounding boxes is not capitalized on. Although multi-view consistency of 2D detections can serve as a powerful constraint in BEV space, these detections are commonly treated as auxiliary signals rather than being jointly optimized with the primary task.In this work, we propose \textbf{MVDGC}, a unified framework that \emph{jointly estimates pedestrian locations on the BEV plane and 2D bounding boxes in image views}. MVDGC employs a \emph{sparse set of 3D cylindrical queries} that embraces geometric context across both BEV and image views, enforcing dual spatial constraints for precise localization. Specifically, the geometric constraints is established by modeling each pedestrian as a vertical cylinder whose center lies on the BEV plane and whose projection casts a rectangular box in the image views. These queries function as shape anchors that directly extract 2D features from the intact image-view features using camera projection, eliminating projection-induced distortions. The 3D cylindrical query enables the unification of BEV and ImV localization into a single task: 3D cylinder position and shape refinement. Code is available at: https://github.com/UARK-AICV/MVDGC
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce MVDGC, a unified framework for multi-view pedestrian detection that jointly estimates pedestrian locations on the BEV plane and 2D bounding boxes in image views using a sparse set of 3D cylindrical queries. These queries model each pedestrian as a vertical cylinder with center on the BEV plane, whose projection is a rectangular box in image views, enforcing dual geometric constraints to extract intact image features without BEV distortion. The 3D cylindrical query unifies BEV and ImV localization into 3D cylinder position and shape refinement.
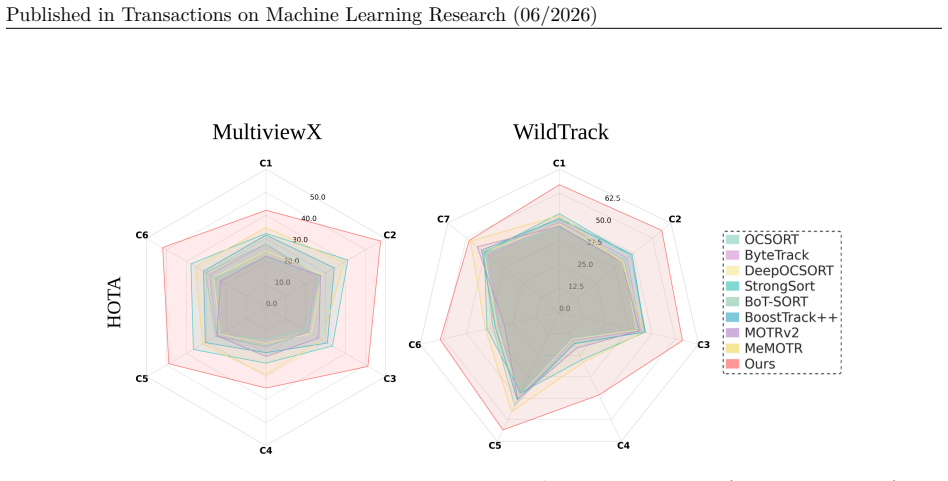
Significance. If the geometric modeling and dual constraints hold without introducing significant approximation errors, this could represent a meaningful advance in multi-view detection by preserving spatial structure and jointly optimizing 2D and 3D tasks. The release of code supports reproducibility. However, the absence of quantitative results, ablations, or error analysis in the abstract makes the practical significance difficult to assess at this stage.
major comments (1)
- [Abstract] Abstract: The central unification claim—that the 3D cylindrical query enables joint BEV/ImV localization via dual constraints—rests on the assertion that modeling each pedestrian as a vertical cylinder 'whose projection casts a rectangular box in the image views' supplies accurate geometric constraints without new errors. No validation, error analysis, or ablation addressing non-vertical poses or heavy occlusion is supplied, leaving the load-bearing assumption untested.
minor comments (1)
- [Abstract] Abstract: 'The geometric constraints is established' contains a subject-verb agreement error.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for identifying the need to substantiate the core modeling assumption. We address the comment below and commit to strengthening the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central unification claim—that the 3D cylindrical query enables joint BEV/ImV localization via dual constraints—rests on the assertion that modeling each pedestrian as a vertical cylinder 'whose projection casts a rectangular box in the image views' supplies accurate geometric constraints without new errors. No validation, error analysis, or ablation addressing non-vertical poses or heavy occlusion is supplied, leaving the load-bearing assumption untested.
Authors: The vertical-cylinder representation is a standard modeling choice in pedestrian detection because the large majority of pedestrians in typical surveillance scenes maintain an upright posture; the projection of such a cylinder under the pinhole model yields an axis-aligned rectangle, thereby supplying the geometric correspondence between BEV center and image bounding box. The 3D query is not a rigid template: its center, radius and height are refined end-to-end, allowing the network to adjust shape parameters while the dual-view feature extraction remains distortion-free. Nevertheless, we agree that the manuscript currently lacks dedicated ablations or error breakdowns for non-upright poses and for heavy-occlusion regimes. We will add (i) a quantitative comparison of cylinder versus tilted-cylinder or 3D-box alternatives on a subset of annotated non-vertical cases, (ii) an occlusion-stratified error analysis, and (iii) an ablation that isolates the contribution of the dual geometric constraints under increasing occlusion levels. These additions will be placed in the experimental section and will directly test whether the approximation introduces measurable new errors. revision: yes
Circularity Check
No significant circularity; derivation is self-contained via explicit modeling assumptions
full rationale
The paper defines its core mechanism upfront by modeling pedestrians as vertical cylinders (center on BEV plane, rectangular projection in image views) and uses this to enable joint BEV/ImV refinement via 3D queries. This is presented as an input modeling choice, not derived from or equivalent to the output predictions. No equations, fitted parameters, or self-citations are shown that would reduce the unification claim to a re-expression of inputs by construction. The framework is externally falsifiable via its geometric constraints and code release.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pedestrians can be modeled as vertical cylinders with centers on the BEV plane whose projections form rectangular boxes in image views
invented entities (1)
-
sparse set of 3D cylindrical queries
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education
Clancey, William J. Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education. Proceedings of the Eighth International Joint Conference on Artificial Intelligence (IJCAI-83)
-
[2]
Classification Problem Solving
Clancey, William J. Classification Problem Solving. Proceedings of the Fourth National Conference on Artificial Intelligence
-
[3]
, title =
Robinson, Arthur L. , title =. 1980 , doi =. https://science.sciencemag.org/content/208/4447/1019.full.pdf , journal =
1980
-
[4]
New Ways to Make Microcircuits Smaller---Duplicate Entry
Robinson, Arthur L. New Ways to Make Microcircuits Smaller---Duplicate Entry. Science
-
[5]
Clancey and Glenn Rennels , abstract =
Diane Warner Hasling and William J. Clancey and Glenn Rennels , abstract =. Strategic explanations for a diagnostic consultation system , journal =. 1984 , issn =. doi:https://doi.org/10.1016/S0020-7373(84)80003-6 , url =
-
[6]
and Rennels, Glenn R
Hasling, Diane Warner and Clancey, William J. and Rennels, Glenn R. and Test, Thomas. Strategic Explanations in Consultation---Duplicate. The International Journal of Man-Machine Studies
-
[7]
Poligon: A System for Parallel Problem Solving
Rice, James. Poligon: A System for Parallel Problem Solving
-
[8]
Transfer of Rule-Based Expertise through a Tutorial Dialogue
Clancey, William J. Transfer of Rule-Based Expertise through a Tutorial Dialogue
-
[9]
The Engineering of Qualitative Models
Clancey, William J. The Engineering of Qualitative Models
-
[10]
2017 , eprint=
Attention Is All You Need , author=. 2017 , eprint=
2017
-
[11]
Pluto: The 'Other' Red Planet
NASA. Pluto: The 'Other' Red Planet
-
[12]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Cross-view cross-scene multi-view crowd counting , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[13]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Sparsebev: High-performance sparse 3d object detection from multi-camera videos , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[14]
IEEE Transactions on Circuits and Systems for Video Technology , volume=
Graph neural networks for cross-camera data association , author=. IEEE Transactions on Circuits and Systems for Video Technology , volume=. 2022 , publisher=
2022
-
[15]
Proceedings of the 29th ACM International Conference on Multimedia , pages=
Multiview detection with shadow transformer (and view-coherent data augmentation) , author=. Proceedings of the 29th ACM International Conference on Multimedia , pages=
-
[16]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
EarlyBird: early-fusion for multi-view tracking in the bird's eye View , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[17]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Enhancing multi-view pedestrian detection through generalized 3d feature pulling , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[18]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Multi-view target transformation for pedestrian detection , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[19]
Advances in neural information processing systems , volume=
Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training , author=. Advances in neural information processing systems , volume=
-
[20]
Communications Engineering , volume=
Localization and recognition of human action in 3D using transformers , author=. Communications Engineering , volume=. 2024 , publisher=
2024
-
[21]
European conference on computer vision , pages=
End-to-end object detection with transformers , author=. European conference on computer vision , pages=. 2020 , organization=
2020
-
[22]
IEEE transactions on pattern analysis and machine intelligence , volume=
Multicamera people tracking with a probabilistic occupancy map , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2008 , publisher=
2008
-
[23]
2023 IEEE International conference on image processing (ICIP) , pages=
Deep oc-sort: Multi-pedestrian tracking by adaptive re-identification , author=. 2023 IEEE International conference on image processing (ICIP) , pages=. 2023 , organization=
2023
-
[24]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
MeMOTR: Long-term memory-augmented transformer for multi-object tracking , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[25]
European Conference on Computer Vision , pages=
Multiview detection with feature perspective transformation , author=. European Conference on Computer Vision , pages=. 2020 , organization=
2020
-
[26]
European Conference on Computer Vision , pages=
3d random occlusion and multi-layer projection for deep multi-camera pedestrian localization , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[27]
The WILDTRACK Multi-Camera Person Dataset
The wildtrack multi-camera person dataset , author=. arXiv preprint arXiv:1707.09299 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
European conference on computer vision , pages=
Towards real-time multi-object tracking , author=. European conference on computer vision , pages=. 2020 , organization=
2020
-
[29]
EURASIP Journal on Image and Video Processing , volume=
Evaluating multiple object tracking performance: the clear mot metrics , author=. EURASIP Journal on Image and Video Processing , volume=. 2008 , publisher=
2008
-
[30]
European conference on computer vision , pages=
Performance measures and a data set for multi-target, multi-camera tracking , author=. European conference on computer vision , pages=. 2016 , organization=
2016
-
[31]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Wildtrack: A multi-camera hd dataset for dense unscripted pedestrian detection , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[32]
International journal of computer vision , volume=
Hota: A higher order metric for evaluating multi-object tracking , author=. International journal of computer vision , volume=. 2021 , publisher=
2021
-
[33]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Detrs with collaborative hybrid assignments training , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[34]
arXiv preprint arXiv:2408.06604 (2024) 5
MV-DETR: Multi-modality indoor object detection by Multi-View DEtecton TRansformers , author=. arXiv preprint arXiv:2408.06604 , year=
-
[35]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Stacked homography transformations for multi-view pedestrian detection , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[36]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Lifting multi-view detection and tracking to the bird's eye view , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[37]
European conference on computer vision , pages=
Bytetrack: Multi-object tracking by associating every detection box , author=. European conference on computer vision , pages=. 2022 , organization=
2022
-
[38]
BoT-SORT: Robust as- sociations multi-pedestrian tracking,
BoT-SORT: Robust associations multi-pedestrian tracking , author=. arXiv preprint arXiv:2206.14651 , year=
-
[39]
IEEE Transactions on Multimedia , volume=
Strongsort: Make deepsort great again , author=. IEEE Transactions on Multimedia , volume=. 2023 , publisher=
2023
-
[40]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Motrv2: Bootstrapping end-to-end multi-object tracking by pretrained object detectors , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[41]
arXiv preprint arXiv:2408.13003 , year=
Boosttrack++: using tracklet information to detect more objects in multiple object tracking , author=. arXiv preprint arXiv:2408.13003 , year=
-
[42]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Observation-centric sort: Rethinking sort for robust multi-object tracking , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[43]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Two-level data augmentation for calibrated multi-view detection , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[44]
Proceedings of the IEEE International Conference on Computer Vision , pages=
Deep occlusion reasoning for multi-camera multi-target detection , author=. Proceedings of the IEEE International Conference on Computer Vision , pages=
-
[45]
2017 16th IEEE international conference on machine learning and applications (ICMLA) , pages=
Deep multi-camera people detection , author=. 2017 16th IEEE international conference on machine learning and applications (ICMLA) , pages=. 2017 , organization=
2017
-
[46]
2016 IEEE winter conference on applications of computer vision (WACV) , pages=
Crowd density estimation based on rich features and random projection forest , author=. 2016 IEEE winter conference on applications of computer vision (WACV) , pages=. 2016 , organization=
2016
-
[47]
Pattern Recognition , volume=
Multicamera pedestrian detection using logic minimization , author=. Pattern Recognition , volume=. 2021 , publisher=
2021
-
[48]
2011 International Conference on Computer Vision , pages=
Conditional random fields for multi-camera object detection , author=. 2011 International Conference on Computer Vision , pages=. 2011 , organization=
2011
-
[49]
Deformable DETR: Deformable Transformers for End-to-End Object Detection
Deformable detr: Deformable transformers for end-to-end object detection , author=. arXiv preprint arXiv:2010.04159 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[50]
Proceedings of the ieee/cvf conference on computer vision and pattern recognition , pages=
Bounding box regression with uncertainty for accurate object detection , author=. Proceedings of the ieee/cvf conference on computer vision and pattern recognition , pages=
-
[51]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Enhanced Multi-View Pedestrian Detection Using Probabilistic Occupancy Volume , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[52]
Advances in neural information processing systems , volume=
Pytorch: An imperative style, high-performance deep learning library , author=. Advances in neural information processing systems , volume=
-
[53]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Detrs with hybrid matching , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[54]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[55]
Proceedings of the International Conference on Machine Learning (ICML) , month =
Gedas Bertasius and Heng Wang and Lorenzo Torresani , title =. Proceedings of the International Conference on Machine Learning (ICML) , month =
-
[56]
IEEE transactions on pattern analysis and machine intelligence , volume=
Framework for performance evaluation of face, text, and vehicle detection and tracking in video: Data, metrics, and protocol , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2008 , publisher=
2008
-
[57]
2003 , publisher=
Multiple view geometry in computer vision , author=. 2003 , publisher=
2003
-
[58]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
A Bayesian filter for multi-view 3D multi-object tracking with occlusion handling , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2020 , publisher=
2020
-
[59]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Rest: A reconfigurable spatial-temporal graph model for multi-camera multi-object tracking , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[60]
arXiv preprint arXiv:2003.11753 , year=
Real-time 3d deep multi-camera tracking , author=. arXiv preprint arXiv:2003.11753 , year=
-
[61]
arXiv preprint arXiv:2201.12329 , year=
Dab-detr: Dynamic anchor boxes are better queries for detr , author=. arXiv preprint arXiv:2201.12329 , year=
-
[62]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Multi-view people detection in large scenes via supervised view-wise contribution weighting , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[63]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Learning to select views for efficient multi-view understanding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[64]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Bringing generalization to deep multi-view pedestrian detection , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[65]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Bevformer: learning bird's-eye-view representation from lidar-camera via spatiotemporal transformers , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[66]
Conference on robot learning , pages=
Detr3d: 3d object detection from multi-view images via 3d-to-2d queries , author=. Conference on robot learning , pages=. 2022 , organization=
2022
-
[67]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Exploring object-centric temporal modeling for efficient multi-view 3d object detection , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[68]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Booster-shot: Boosting stacked homography transformations for multiview pedestrian detection with attention , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[69]
European Conference on Computer Vision , pages=
Mahalanobis distance-based multi-view optimal transport for multi-view crowd localization , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[70]
arXiv preprint arXiv:2212.06137 , year=
Nms strikes back , author=. arXiv preprint arXiv:2212.06137 , year=
-
[71]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
nuscenes: A multimodal dataset for autonomous driving , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[72]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Argoverse: 3d tracking and forecasting with rich maps , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[73]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Scalability in perception for autonomous driving: Waymo open dataset , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[74]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Wide-area crowd counting via ground-plane density maps and multi-view fusion cnns , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[75]
Advances in Neural Information Processing Systems , volume=
Direct multi-view multi-person 3d pose estimation , author=. Advances in Neural Information Processing Systems , volume=
-
[76]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Tempo: Efficient multi-view pose estimation, tracking, and forecasting , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[77]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Scene-aware egocentric 3d human pose estimation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.