DreamReasoner-8B: Block-Size Curriculum Learning for Diffusion Reasoning Models
Pith reviewed 2026-06-26 21:00 UTC · model grok-4.3
The pith
Block-size curriculum learning closes the granularity gap so diffusion models can reason competitively with autoregressive ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
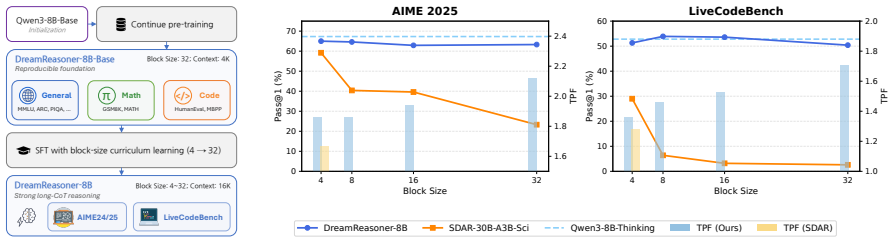
Block diffusion language models exhibit a stark performance disparity in long-CoT reasoning: large block sizes during training produce remarkably poor results while small block sizes preserve effective reasoning. Block-size curriculum learning, which gradually transitions training from fine-grained to coarse-grained block sizes, overcomes the granularity gap and enables strong reasoning performance that generalizes across diverse inference block sizes. On mathematical and code reasoning benchmarks this yields results competitive with leading open autoregressive models.
What carries the argument
Block-size curriculum learning, a training schedule that starts with small blocks and progressively increases block size to close the granularity gap between training and inference.
If this is right
- Large-block training alone yields poor long-CoT reasoning performance.
- Small-block training preserves reasoning ability but limits the speed gains from larger blocks.
- The curriculum produces representations that transfer to a range of inference block sizes.
- DreamReasoner-8B reaches competitive results with Qwen3-8B on mathematical and code reasoning benchmarks.
Where Pith is reading between the lines
- The same gradual block-size schedule might improve diffusion models on other sequence tasks that require long dependencies.
- If the granularity gap is the main obstacle, similar curricula could be tested on non-language diffusion models.
- The result suggests training strategy, not model architecture, is the current bottleneck for scaling block diffusion to reasoning.
Load-bearing premise
The performance difference between large-block and small-block training arises from a fixable granularity mismatch rather than an inherent limit of block diffusion for long reasoning sequences.
What would settle it
A block diffusion model trained exclusively on large blocks that achieves reasoning performance equal to or better than the curriculum-trained version on the same math and code benchmarks.
Figures

read the original abstract
Block diffusion language models accelerate decoding through parallel block-wise denoising, yet whether they can be reliably scaled for long chain-of-thought (CoT) reasoning remains unresolved. To this end, we develop DreamReasoner-8B, an open-source block diffusion reasoning model, and conduct a systematic study of how training and inference block sizes affect long-CoT reasoning. Our analysis reveals a stark performance disparity: training with large block sizes yields remarkably poor reasoning, whereas small block sizes preserve effective reasoning. To bridge this granularity gap, we propose block-size curriculum learning, which gradually transitions training from fine-grained to coarse-grained block sizes, thereby overcoming this limitation and enabling strong reasoning performance that generalizes across diverse inference block sizes. On mathematical and code reasoning benchmarks, DreamReasoner-8B achieves results competitive with leading open autoregressive models such as Qwen3-8B. This work establishes a practical foundation for efficient, reasoning-capable diffusion language models. We release our model at https://github.com/DreamLM/DreamReasoner.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DreamReasoner-8B, an 8B-parameter block diffusion language model, and studies the impact of training and inference block sizes on long chain-of-thought reasoning. It identifies a performance disparity where large-block training yields poor reasoning while small-block training preserves it, proposes block-size curriculum learning to gradually increase block size during training, and claims this overcomes the granularity gap to enable strong reasoning that generalizes across inference block sizes, achieving results competitive with Qwen3-8B on mathematical and code reasoning benchmarks.
Significance. If the central empirical claims hold with proper controls, the work would be significant for demonstrating that block diffusion models can be scaled to long-CoT reasoning via curriculum training, offering a path to parallel decoding advantages over autoregressive models while maintaining competitive accuracy. The open release of the model and code would further strengthen its impact.
major comments (3)
- [Abstract] Abstract and experimental sections: the abstract states that systematic experiments were performed and reports competitive benchmark numbers, but provides no details on baselines, number of runs, error bars, data splits, or exact curriculum schedule; without these the central empirical claim cannot be evaluated.
- [Method / Experiments] The claim that block-size curriculum learning produces representations that transfer to inference block sizes different from the final training regime (and overcomes an inherent architectural limit of parallel block denoising for sequential long-CoT dependencies) is load-bearing but rests on the observed disparity without ablations showing that gradual transition is necessary versus other factors such as total training compute or data ordering.
- [Experiments] No evidence is provided that the performance gap is caused by a fixable granularity gap rather than an architectural limitation; direct comparisons to Qwen3-8B are reported but without matched training data, token budget, or inference settings, undermining the generalization claim.
minor comments (2)
- [Method] Notation for block sizes during training versus inference should be clarified with explicit symbols and a table summarizing the curriculum schedule.
- [Appendix] The GitHub link is provided but the manuscript should include a reproducibility checklist or pointer to exact training hyperparameters and data splits.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments, which highlight important areas for improving the clarity and robustness of our empirical results. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental sections: the abstract states that systematic experiments were performed and reports competitive benchmark numbers, but provides no details on baselines, number of runs, error bars, data splits, or exact curriculum schedule; without these the central empirical claim cannot be evaluated.
Authors: We acknowledge that additional details are required for proper evaluation. In the revised version, we will update the abstract to mention the baselines used, include the number of experimental runs with error bars, specify the data splits, and detail the exact block-size curriculum schedule in the methods section. revision: yes
-
Referee: [Method / Experiments] The claim that block-size curriculum learning produces representations that transfer to inference block sizes different from the final training regime (and overcomes an inherent architectural limit of parallel block denoising for sequential long-CoT dependencies) is load-bearing but rests on the observed disparity without ablations showing that gradual transition is necessary versus other factors such as total training compute or data ordering.
Authors: Our experiments demonstrate a clear performance disparity between small and large block sizes, with the curriculum approach enabling effective transfer. To more rigorously isolate the effect of the gradual transition, we will include additional ablation studies comparing curriculum learning against constant block size with equivalent compute and reordered data in the revision. revision: yes
-
Referee: [Experiments] No evidence is provided that the performance gap is caused by a fixable granularity gap rather than an architectural limitation; direct comparisons to Qwen3-8B are reported but without matched training data, token budget, or inference settings, undermining the generalization claim.
Authors: The ability of the model to achieve strong reasoning with small block sizes during training shows that the limitation is not architectural but related to training granularity. We will revise the discussion to explicitly address this point. Regarding comparisons to Qwen3-8B, we will add caveats noting the differences in training data and compute, while maintaining that the results demonstrate competitive performance under our training regime. revision: partial
Circularity Check
No circularity; empirical curriculum results benchmarked against external autoregressive model
full rationale
The paper reports an observed performance disparity between large- and small-block training, introduces block-size curriculum learning as a training schedule, and validates the resulting model via direct comparison to Qwen3-8B on standard benchmarks. No equations, fitted parameters presented as predictions, self-citation load-bearing premises, or uniqueness theorems appear in the provided text. The central claim rests on external empirical comparison rather than any self-referential derivation or renaming of inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- block-size curriculum schedule
axioms (1)
- domain assumption Block diffusion models are capable of long CoT reasoning when trained with appropriate granularity progression
Reference graph
Works this paper leans on
-
[1]
Andrew Campbell, Joe Benton, Valentin De Bortoli, Thomas Rainforth, George Deligiannidis, and Ar- naud Doucet
AAAI Press. Andrew Campbell, Joe Benton, Valentin De Bortoli, Thomas Rainforth, George Deligiannidis, and Ar- naud Doucet. 2022. A continuous time framework for discrete denoising models.Advances in Neural Information Processing Systems, 35:28266–28279. Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri...
2022
-
[2]
Evaluating large language models trained on code.Preprint, arXiv:2107.03374. Yang Chen, Zhuolin Yang, Zihan Liu, Chankyu Lee, Peng Xu, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. 2025. Acereason-nemotron: Advanc- ing math and code reasoning through reinforcement learning.Preprint, arXiv:2505.16400. Shuang Cheng, Yihan Bian, Dawei Liu, Linfeng Zhang, ...
Pith/arXiv arXiv 2025
-
[3]
Sdar: A synergistic diffusion-autoregression paradigm for scalable sequence generation.arXiv preprint arXiv:2510.06303. Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question an- swering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457. Karl C...
arXiv 2018
-
[4]
Training verifiers to solve math word prob- lems.Preprint, arXiv:2110.14168. DeepSeek-AI. 2025. Deepseek-r1: Incentivizing rea- soning capability in llms via reinforcement learning. Preprint, arXiv:2501.12948. DeepSeek-AI. 2026. Deepseek-v4: Towards highly efficient million-token context intelligence. Juechu Dong, Boyuan Feng, Driss Guessous, Yanbo Liang,...
Pith/arXiv arXiv 2025
-
[5]
Efficient-dlm: From autoregressive to diffu- sion language models, and beyond in speed.Preprint, arXiv:2512.14067. Shansan Gong, Shivam Agarwal, Yizhe Zhang, Jiacheng Ye, Lin Zheng, Mukai Li, Chenxin An, Peilin Zhao, Wei Bi, Jiawei Han, Hao Peng, and Lingpeng Kong. 2025a. Scaling diffusion language models via adapta- tion from autoregressive models.Intern...
Pith/arXiv arXiv 2023
-
[6]
InProceedings of the 61st Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers)
SSD-LM: Semi-autoregressive simplex-based diffusion language model for text generation and modular control. InProceedings of the 61st Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers). Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt
-
[7]
Measuring massive multitask language under- standing.arXiv preprint arXiv:2009.03300. Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. Measuring mathematical problem solving with the MATH dataset. InThirty- fifth Conference on Neural Information Processing Systems Datasets and Bench...
Pith/arXiv arXiv 2009
-
[8]
Diffusion language models are super data learners.arXiv preprint arXiv:2511.03276. Zanlin Ni, Shenzhi Wang, Yang Yue, Tianyu Yu, Weilin Zhao, Yeguo Hua, Tianyi Chen, Jun Song, Cheng Yu, Bo Zheng, and Gao Huang. 2026. The flex- ibility trap: Why arbitrary order limits reasoning potential in diffusion language models.Preprint, arXiv:2601.15165. Shen Nie, Fe...
arXiv 2026
-
[9]
Mimo: Unlocking the reasoning potential of language model – from pretraining to posttraining. Preprint, arXiv:2505.07608. Zhihui Xie, Jiacheng Ye, Lin Zheng, Jiahui Gao, Jing- wei Dong, Zirui Wu, Xueliang Zhao, Shansan Gong, Xin Jiang, Zhenguo Li, and Lingpeng Kong. 2025. Dream-coder 7b: An open diffusion language model for code.Preprint, arXiv:2509.01142...
arXiv 2025
-
[10]
arXiv preprint arXiv:2508.15487
Dream 7b: Diffusion large language models. arXiv preprint arXiv:2508.15487. Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. Hellaswag: Can a machine really finish your sentence?arXiv preprint arXiv:1905.07830. Lingxiao Zhao, Xueying Ding, Lijun Yu, and Le- man Akoglu. 2024. Improving and unifying discrete&continuous-time disc...
Pith/arXiv arXiv 2019
-
[11]
InConferenec on Language Mod- eling, COLM, October 7-9, 2024, Philadelphia, PA
A reparameterized discrete diffusion model for text generation. InConferenec on Language Mod- eling, COLM, October 7-9, 2024, Philadelphia, PA. Fengqi Zhu, Rongzhen Wang, Shen Nie, Xiaolu Zhang, Chunwei Wu, Jun Hu, Jun Zhou, Jianfei Chen, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. 2025. Llada 1.5: Variance-reduced preference optimiza- tion for large langu...
Pith/arXiv arXiv 2024
-
[12]
A noise injection module stochas- tically masks tokens while enforcing at least one masked token per block to prevent degenerate cases
that uses input sequences directly as super- vision targets. A noise injection module stochas- tically masks tokens while enforcing at least one masked token per block to prevent degenerate cases. The resulting interleaved sequences are processed via FlexAttention (Dong et al., 2024), which com- piles the structured sparse attention pattern into optimized...
2024
-
[13]
for sentence completion, PIQA (Bisk et al.,
-
[14]
We follow the evaluation framework in Dream-7B (Ye et al., 2025) to evaluate our model
for physical reasoning, WinoGrande (Sak- aguchi et al., 2021) for pronoun disambiguation, and RACE (Lai et al., 2017) for reading compre- hension.Mathematical and scientific reasoningis assessed through GSM8K (Cobbe et al., 2021) and MATH (Hendrycks et al., 2020) for mathematical problem-solving, and GPQA (Rein et al., 2023) for graduate-level science que...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.