Discard the Dross and Select the Essential: Pre-query Sample Selection for Black-box Membership Inference Attacks
Pith reviewed 2026-06-30 05:37 UTC · model grok-4.3
The pith
PSS-MIA ranks samples by loss gaps from reference models and queries only the top subset, cutting black-box MIA budgets by 60-83 percent while preserving attack strength.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
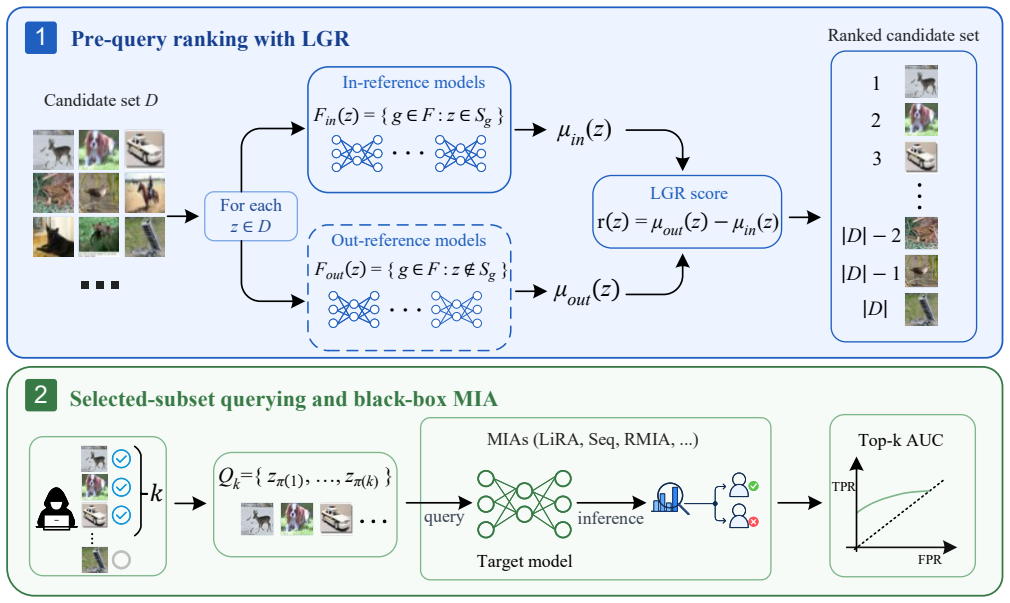
By ranking candidate samples according to the strength of their membership signal estimated from loss gaps on reference models and then querying only the selected subset, PSS-MIA with LGR allows existing black-box MIAs to achieve better performance with substantially fewer queries.
What carries the argument
Loss-Gap Ranking (LGR), which ranks candidate samples by estimating the strength of their membership signal using loss gaps computed from reference models.
If this is right
- PSS-MIA can be embedded with any existing black-box MIA method.
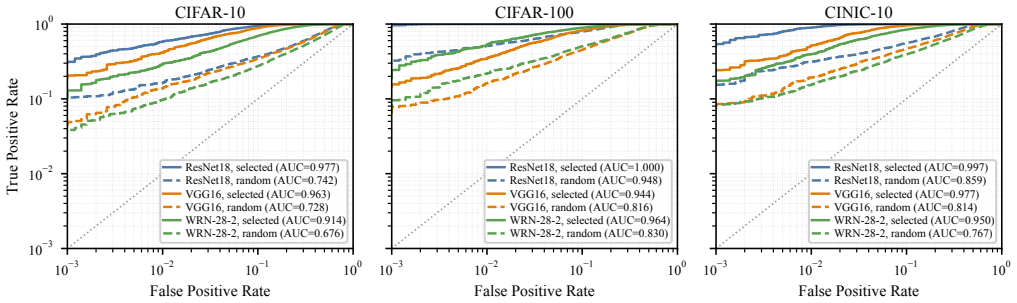
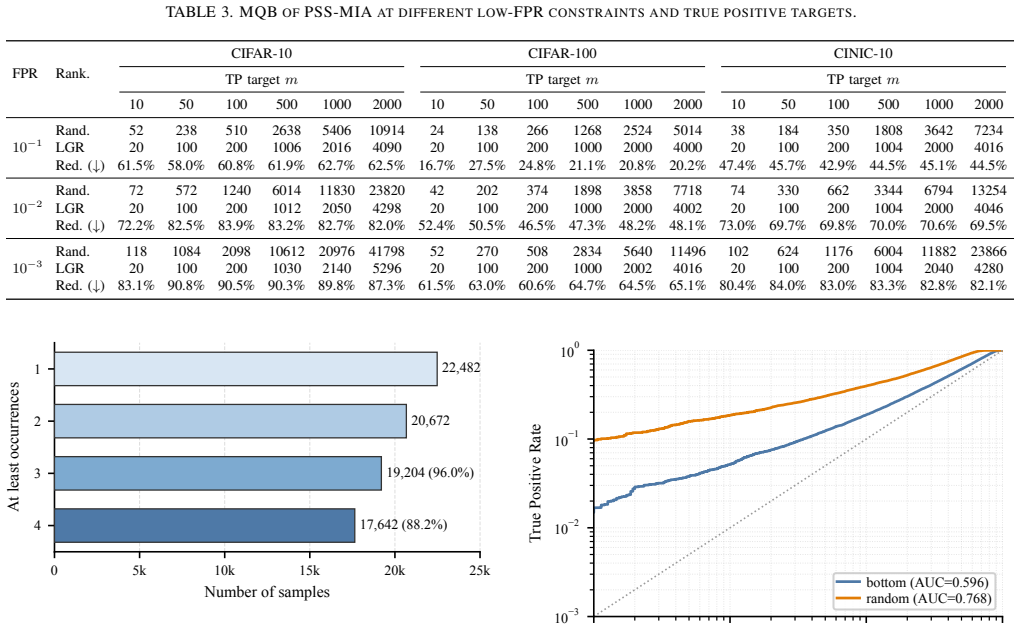
- Under a 0.1% FPR constraint, PSS-MIA saves at least 83.1%, 60.6%, and 80.4% of the query budget on CIFAR-10, CIFAR-100, and CINIC-10 respectively.
- PSS-MIA with LGR consistently outperforms all other compared sample-selection baselines.
Where Pith is reading between the lines
- If loss-gap ranking correlates with sample difficulty or outlier status, the selected subset may systematically differ in distribution from the full candidate pool.
- The same pre-query ranking idea could be tested on other query-based privacy attacks such as model extraction or property inference.
- Practical deployment would require reference models whose training distribution is close enough to the target to produce useful rankings.
Load-bearing premise
Loss gaps computed from reference models provide a reliable ranking of membership signal strength for the target model, and selecting the top subset does not introduce bias that invalidates the reported MIA gains.
What would settle it
An experiment on one of the three datasets in which the LGR-selected subset produces no higher attack accuracy or no larger query savings than a random subset of the same size.
Figures

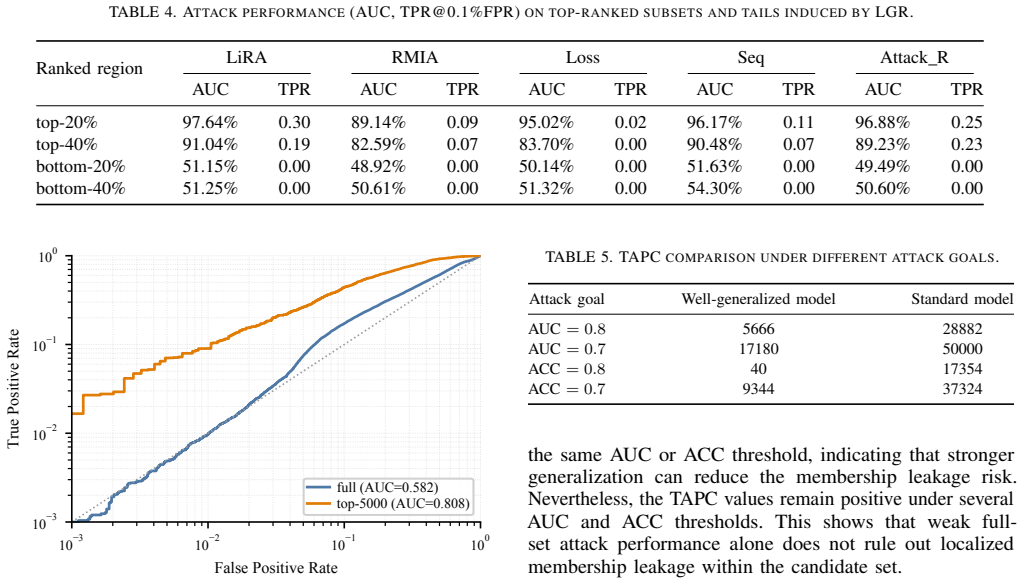
read the original abstract
Black-box membership inference attacks (MIAs) rely on target-model queries to infer whether candidate samples were used for training. However, membership signals are highly non-uniform across samples: some candidate samples support strong member/non-member separability, whereas many others provide little useful signal. Consequently, indiscriminate querying can incur substantial query cost and increase query-induced exposure, with limited marginal benefit for inference. This raises a key question: which candidate samples are worth querying for black-box MIAs? To address this question, we propose PSS-MIA, a pre-query sample selection framework which can be embedded with any existing MIA methods. PSS-MIA proceeds in two stages: it first ranks candidate samples and selects a subset expected to support stronger membership inference, then queries the selected samples and uses the returned outputs for an existing black-box MIA, thereby reducing query cost and query-induced exposure. In the first stage, we propose Loss-Gap Ranking (LGR), which ranks candidate samples by estimating the strength of their membership signal using loss gaps computed from reference models. Experiments on CIFAR-10, CIFAR-100, and CINIC-10 with five representative black-box MIA methods demonstrate that PSS-MIA with LGR consistently outperforms all other compared methods. Moreover, under a 0.1% FPR constraint, PSS-MIA can save at least 83.1%, 60.6%, and 80.4% of the query budget for the three datasets, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PSS-MIA, a two-stage pre-query sample selection framework for black-box membership inference attacks. In the first stage, Loss-Gap Ranking (LGR) uses loss gaps from reference models to rank and select a subset of candidate samples expected to exhibit stronger membership signals; the second stage queries only this subset and feeds the outputs to any existing black-box MIA. Experiments on CIFAR-10, CIFAR-100, and CINIC-10 with five representative MIAs report that PSS-MIA with LGR consistently outperforms baselines and, at 0.1% FPR, saves at least 83.1%, 60.6%, and 80.4% of the query budget on the three datasets.
Significance. If the central transfer assumption holds, the work addresses a practical efficiency bottleneck in black-box MIAs by reducing query cost and exposure while preserving or improving attack performance. The multi-dataset, multi-method experimental design is a positive feature; however, the headline savings claims rest on an unvalidated premise that reference-model LGR rankings identify samples with genuinely stronger target-model signals.
major comments (4)
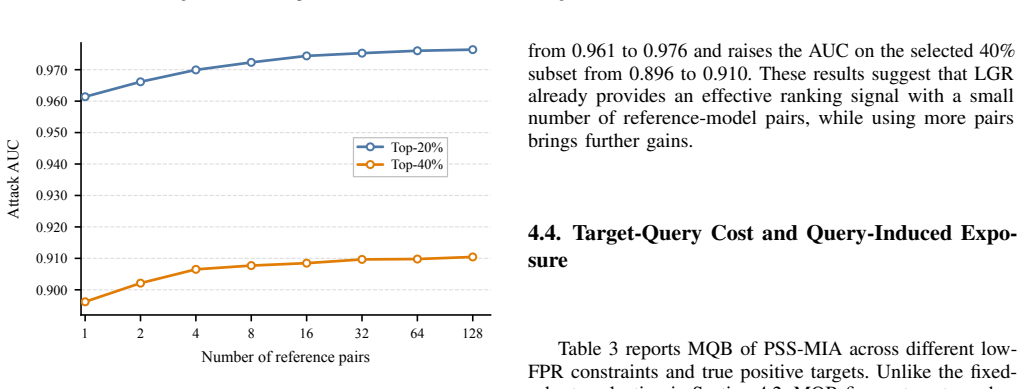
- [Method (LGR subsection)] Method section (LGR description): no correlation is reported between the loss-gap scores computed on the reference models and any membership signal (loss, confidence, or output statistics) measured on the target model itself. Without this measurement, it is impossible to confirm that the selected subset actually carries stronger signals rather than an arbitrary or biased sample.
- [Experiments] Experiments section: the paper contains no control that applies an existing MIA to a random subset of identical cardinality; such a baseline is required to isolate whether the reported performance gains and query savings are attributable to LGR or to the mere reduction in sample count.
- [Results (tables reporting FPR-constrained savings)] Results (performance tables): the outperformance and budget-saving figures (83.1%/60.6%/80.4% at 0.1% FPR) are presented without statistical significance tests or correction for multiple comparisons across five methods and three datasets, leaving open the possibility that some reported advantages are within noise.
- [Method (reference model paragraph)] Reference-model training paragraph: insufficient detail is given on architecture, training data, and hyperparameters of the reference models used to compute LGR, preventing assessment of whether they are sufficiently similar to the target to support reliable ranking transfer.
minor comments (2)
- [Abstract] Abstract: the acronym LGR is used before its expansion; expand on first use.
- [Results tables] All result tables should report standard deviations or confidence intervals alongside mean metrics to allow readers to judge variability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment point-by-point below and will revise the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: Method section (LGR description): no correlation is reported between the loss-gap scores computed on the reference models and any membership signal (loss, confidence, or output statistics) measured on the target model itself. Without this measurement, it is impossible to confirm that the selected subset actually carries stronger signals rather than an arbitrary or biased sample.
Authors: We agree that an explicit correlation analysis would strengthen the justification for the transfer assumption. In the revised manuscript we will add a new subsection or appendix figure reporting Pearson/Spearman correlations between LGR scores (computed on reference models) and target-model membership signals such as loss gaps and confidence gaps, computed on the same candidate samples. This will directly demonstrate that higher LGR ranks correspond to stronger target-model signals. revision: yes
-
Referee: Experiments section: the paper contains no control that applies an existing MIA to a random subset of identical cardinality; such a baseline is required to isolate whether the reported performance gains and query savings are attributable to LGR or to the mere reduction in sample count.
Authors: This is a fair criticism. We will add a random-subset baseline of identical cardinality to all tables and figures in the revised experiments section. The new baseline will apply each of the five MIAs to randomly chosen subsets of the same size as the LGR-selected subsets, allowing readers to isolate the benefit of informed selection from the effect of simply querying fewer samples. revision: yes
-
Referee: Results (performance tables): the outperformance and budget-saving figures (83.1%/60.6%/80.4% at 0.1% FPR) are presented without statistical significance tests or correction for multiple comparisons across five methods and three datasets, leaving open the possibility that some reported advantages are within noise.
Authors: We accept that statistical testing is needed for robustness. In the revision we will rerun the experiments with multiple random seeds, apply paired statistical tests (e.g., Wilcoxon signed-rank) to the AUC and TPR@0.1%FPR metrics, and report p-values with Bonferroni correction for the 5 methods × 3 datasets comparisons. Tables will be updated to flag statistically significant improvements. revision: yes
-
Referee: Reference-model training paragraph: insufficient detail is given on architecture, training data, and hyperparameters of the reference models used to compute LGR, preventing assessment of whether they are sufficiently similar to the target to support reliable ranking transfer.
Authors: We will expand the reference-model description in Section 3.2 (and add a dedicated appendix table) to specify: (i) exact architectures (identical to the target models, e.g., ResNet-18/34), (ii) training datasets (same distribution, disjoint from target training set), and (iii) all hyperparameters (optimizer, learning-rate schedule, epochs, batch size, data augmentation). This will allow readers to evaluate the similarity assumption. revision: yes
Circularity Check
No circularity: LGR ranking and performance claims are independent of target MIA outputs
full rationale
The paper defines PSS-MIA as a two-stage process where LGR ranks samples using loss gaps from separate reference models before any target queries occur; the reported query savings and accuracy gains are measured on held-out evaluation after selection. No equations or steps reduce the final MIA metrics to the selection procedure by construction, and no self-citations are invoked to justify uniqueness or load-bearing assumptions. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Membership inference attacks against machine learning models,
R. Shokri, M. Stronati, C. Song, and V . Shmatikov, “Membership inference attacks against machine learning models,” in2017 IEEE Symposium on Security and Privacy (SP). IEEE, 2017, pp. 3–18
2017
-
[2]
Privacy risk in machine learning: Analyzing the connection to overfitting,
S. Yeom, I. Giacomelli, M. Fredrikson, and S. Jha, “Privacy risk in machine learning: Analyzing the connection to overfitting,” in2018 IEEE 31st Computer Security Foundations Symposium (CSF). IEEE, 2018, pp. 268–282
2018
-
[3]
Label- only membership inference attacks,
C. A. Choquette-Choo, F. Tramer, N. Carlini, and N. Papernot, “Label- only membership inference attacks,” inProceedings of the 38th International Conference on Machine Learning (ICML). PMLR, 2021, pp. 1964–1974
2021
-
[4]
Membership inference attacks from first principles,
N. Carlini, S. Chien, M. Nasr, S. Song, A. Terzis, and F. Tramer, “Membership inference attacks from first principles,” in2022 IEEE Symposium on Security and Privacy (SP). IEEE, 2022, pp. 1897– 1914
2022
-
[5]
ML-Leaks: Model and data independent membership inference attacks and defenses on machine learning models,
A. Salem, Y . Zhang, M. Humbert, P. Berrang, M. Fritz, and M. Backes, “ML-Leaks: Model and data independent membership inference attacks and defenses on machine learning models,” inNetwork and Distributed System Security Symposium (NDSS). The Internet Society, 2019
2019
-
[6]
Low-cost high-power mem- bership inference attacks,
S. Zarifzadeh, P. Liu, and R. Shokri, “Low-cost high-power mem- bership inference attacks,” inProceedings of the 41st International Conference on Machine Learning (ICML). PMLR, 2024, pp. 58 244– 58 282
2024
-
[7]
Systematic evaluation of privacy risks of machine learning models,
L. Song and P. Mittal, “Systematic evaluation of privacy risks of machine learning models,” in30th USENIX Security Symposium. USENIX Association, 2021, pp. 2615–2632
2021
-
[8]
Demystifying membership inference attacks in machine learning as a service,
S. Truex, L. Liu, M. E. Gursoy, L. Yu, and W. Wei, “Demystifying membership inference attacks in machine learning as a service,”IEEE Transactions on Services Computing, vol. 14, no. 6, pp. 2073–2089, 2021
2073
-
[9]
White-box vs black-box: Bayes optimal strategies for membership inference,
A. Sablayrolles, M. Douze, C. Schmid, Y . Ollivier, and H. J ´egou, “White-box vs black-box: Bayes optimal strategies for membership inference,” inProceedings of the 36th International Conference on Machine Learning (ICML). PMLR, 2019, pp. 5558–5567
2019
-
[10]
Privacy risks of securing machine learning models against adversarial examples,
L. Song, R. Shokri, and P. Mittal, “Privacy risks of securing machine learning models against adversarial examples,” inProceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security (CCS). ACM, 2019, pp. 241–257
2019
-
[11]
Prac- tical blind membership inference attack via differential comparisons,
B. Hui, Y . Yang, H. Yuan, P. Burlina, N. Z. Gong, and Y . Cao, “Prac- tical blind membership inference attack via differential comparisons,” inNetwork and Distributed System Security Symposium (NDSS). The Internet Society, 2021
2021
-
[12]
Membership leakage in label-only exposures,
Z. Li and Y . Zhang, “Membership leakage in label-only exposures,” inProceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security (CCS). ACM, 2021, pp. 880–895
2021
-
[13]
Enhanced Label-Only membership inference attacks with fewer queries,
H. Li, Z. Li, S. Wu, Y . Ye, M. Zhang, D. Feng, and Y . Zhang, “Enhanced Label-Only membership inference attacks with fewer queries,” in34th USENIX Security Symposium. USENIX Association, 2025, pp. 5465–5483
2025
-
[14]
Please tell me more: Privacy impact of explainability through the lens of membership inference attack,
H. Liu, Y . Wu, Z. Yu, and N. Zhang, “Please tell me more: Privacy impact of explainability through the lens of membership inference attack,” in2024 IEEE Symposium on Security and Privacy (SP). IEEE, 2024, pp. 4791–4809
2024
-
[15]
Canary in a coalmine: Better membership inference with ensembled adversarial queries,
Y . Wen, A. Bansal, H. Kazemi, E. Borgnia, M. Goldblum, J. Geiping, and T. Goldstein, “Canary in a coalmine: Better membership inference with ensembled adversarial queries,” inInternational Conference on Learning Representations (ICLR), 2023
2023
-
[16]
Enhanced membership inference attacks against machine learning models,
J. Ye, A. Maddi, S. K. Murakonda, V . Bindschaedler, and R. Shokri, “Enhanced membership inference attacks against machine learning models,” inProceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security (CCS). ACM, 2022, pp. 3093–3106
2022
-
[17]
On the importance of difficulty calibration in membership inference attacks,
L. Watson, C. Guo, G. Cormode, and A. Sablayrolles, “On the importance of difficulty calibration in membership inference attacks,” inInternational Conference on Learning Representations (ICLR), 2022
2022
-
[18]
On the difficulty of membership inference attacks,
S. Rezaei and X. Liu, “On the difficulty of membership inference attacks,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2021, pp. 7892–7900
2021
-
[19]
Scalable membership inference attacks via quantile regression,
M. Bertran, S. Tang, A. Roth, M. Kearns, J. H. Morgenstern, and S. Wu, “Scalable membership inference attacks via quantile regression,” Advances in Neural Information Processing Systems, vol. 36, pp. 314– 330, 2023
2023
-
[20]
Is difficulty calibration all we need? Towards more practical membership inference attacks,
Y . He, B. Li, Y . Wang, M. Yang, J. Wang, H. Hu, and X. Zhao, “Is difficulty calibration all we need? Towards more practical membership inference attacks,” inProceedings of the 2024 ACM SIGSAC Con- ference on Computer and Communications Security (CCS). ACM, 2024, pp. 1226–1240
2024
-
[21]
Membership inference attacks by exploiting loss trajectory,
Y . Liu, Z. Zhao, M. Backes, and Y . Zhang, “Membership inference attacks by exploiting loss trajectory,” inProceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security (CCS). ACM, 2022, pp. 2085–2098
2022
-
[22]
SeqMIA: Sequential-metric based membership inference attack,
H. Li, Z. Li, S. Wu, C. Hu, Y . Ye, M. Zhang, D. Feng, and Y . Zhang, “SeqMIA: Sequential-metric based membership inference attack,” in Proceedings of the 2024 ACM SIGSAC Conference on Computer and Communications Security (CCS). ACM, 2024, pp. 3496–3510
2024
-
[23]
Fundamental limits of membership inference attacks on machine learning models,
E. Aubinais, E. Gassiat, and P. Piantanida, “Fundamental limits of membership inference attacks on machine learning models,”Journal of Machine Learning Research, vol. 26, no. 263, pp. 1–54, 2025
2025
-
[24]
When does data augmentation help with membership inference attacks?
Y . Kaya and T. Dumitras, “When does data augmentation help with membership inference attacks?” inProceedings of the 38th International Conference on Machine Learning (ICML). PMLR, 2021, pp. 5345–5355
2021
-
[25]
A blessing of dimensionality in membership inference through regu- larization,
J. Tan, D. LeJeune, B. Mason, H. Javadi, and R. G. Baraniuk, “A blessing of dimensionality in membership inference through regu- larization,” inProceedings of the 26th International Conference on Artificial Intelligence and Statistics (AISTATS). PMLR, 2023, pp. 10 968–10 993
2023
-
[26]
An empirical study of example forgetting during deep neural network learning,
M. Toneva, A. Sordoni, R. Tachet des Combes, A. Trischler, Y . Ben- gio, and G. J. Gordon, “An empirical study of example forgetting during deep neural network learning,” inInternational Conference on Learning Representations (ICLR), 2019
2019
-
[27]
Does learning require memorization? A short tale about a long tail,
V . Feldman, “Does learning require memorization? A short tale about a long tail,” inProceedings of the 52nd Annual ACM SIGACT Symposium on Theory of Computing (STOC). ACM, 2020, pp. 954–959
2020
-
[28]
What neural networks memorize and why: Discovering the long tail via influence estimation,
V . Feldman and C. Zhang, “What neural networks memorize and why: Discovering the long tail via influence estimation,”Advances in Neural Information Processing Systems, vol. 33, pp. 2881–2891, 2020
2020
-
[29]
Can neural network memorization be localized?
P. Maini, M. C. Mozer, H. Sedghi, Z. C. Lipton, J. Z. Kolter, and C. Zhang, “Can neural network memorization be localized?” in Proceedings of the 40th International Conference on Machine Learning (ICML). PMLR, 2023, pp. 23 536–23 557
2023
-
[30]
Stolen memories: Leveraging model memorization for calibrated White-Box membership inference,
K. Leino and M. Fredrikson, “Stolen memories: Leveraging model memorization for calibrated White-Box membership inference,” in 29th USENIX Security Symposium. USENIX Association, 2020, pp. 1605–1622
2020
-
[31]
Disparate vulnerability to membership inference attacks,
B. Kulynych, M. Yaghini, G. Cherubin, M. Veale, and C. Troncoso, “Disparate vulnerability to membership inference attacks,”Proceedings on Privacy Enhancing Technologies, vol. 2022, no. 1, pp. 460–480, 2022
2022
-
[32]
The privacy onion effect: Memorization is relative,
N. Carlini, M. Jagielski, C. Zhang, N. Papernot, A. Terzis, and F. Tramer, “The privacy onion effect: Memorization is relative,” Advances in Neural Information Processing Systems, vol. 35, pp. 13 263–13 276, 2022
2022
-
[33]
Free Record- Level privacy risk evaluation through Artifact-Based methods,
J. Pollock, I. Shilov, E. Dodd, and Y .-A. de Montjoye, “Free Record- Level privacy risk evaluation through Artifact-Based methods,” in 34th USENIX Security Symposium. USENIX Association, 2025, pp. 5525–5544
2025
-
[34]
Learning multiple layers of features from tiny images,
A. Krizhevsky, “Learning multiple layers of features from tiny images,” Master’s thesis, University of Toronto, 2009
2009
-
[35]
CINIC-10 is not ImageNet or CIFAR-10
L. N. Darlow, E. J. Crowley, A. Antoniou, and A. J. Storkey, “CINIC- 10 is not ImageNet or CIFAR-10,”arXiv preprint arXiv:1810.03505, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[36]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2016, pp. 770–778
2016
-
[37]
Very deep convolutional networks for large-scale image recognition,
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” inInternational Conference on Learning Representations (ICLR), 2015
2015
-
[38]
Wide residual networks,
S. Zagoruyko and N. Komodakis, “Wide residual networks,” in Proceedings of the British Machine Vision Conference (BMVC). BMV A Press, 2016, pp. 87.1–87.12
2016
-
[39]
SoK: Membership inference is harder than previously thought,
A. Dionysiou and E. Athanasopoulos, “SoK: Membership inference is harder than previously thought,”Proceedings on Privacy Enhancing Technologies, vol. 2023, no. 3, pp. 286–306, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.