Sample Complexity of Scientific Discovery: PAC Learnability of Compositional Function Trees
Pith reviewed 2026-06-30 07:49 UTC · model grok-4.3
The pith
Compositional function trees have generalization error controlled by depth and operator Lipschitz constants rather than by the total number of possible expressions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
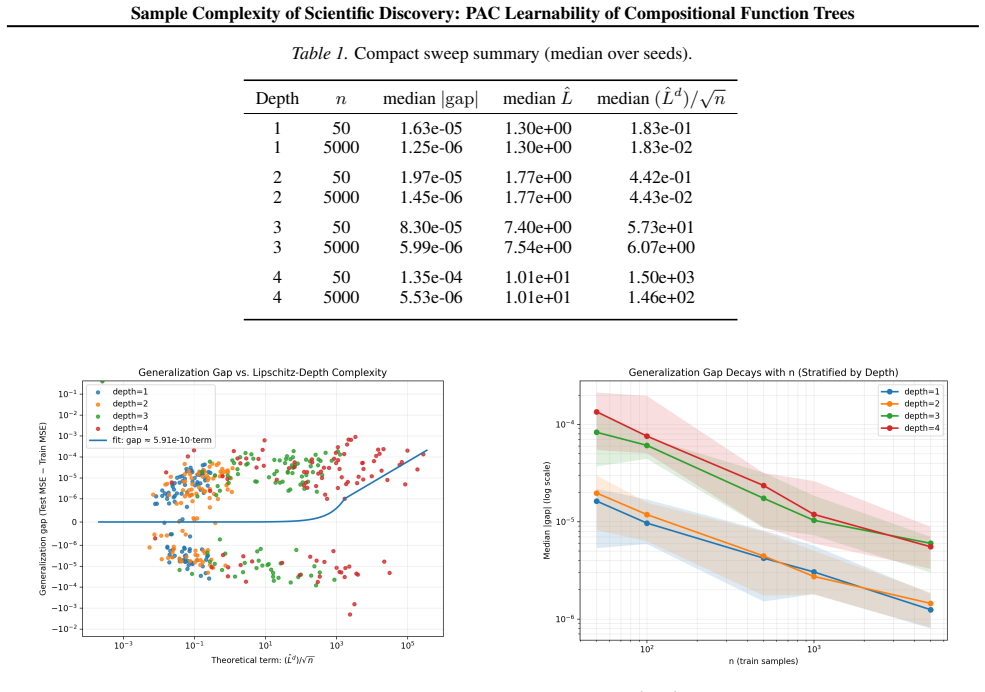
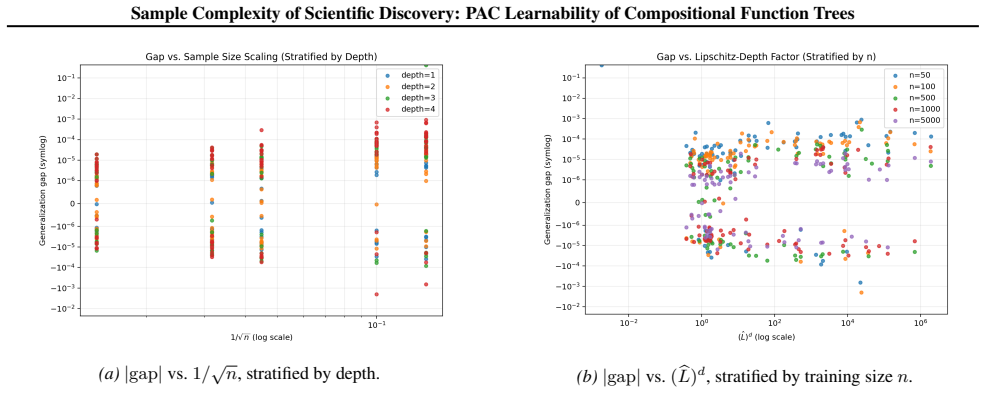
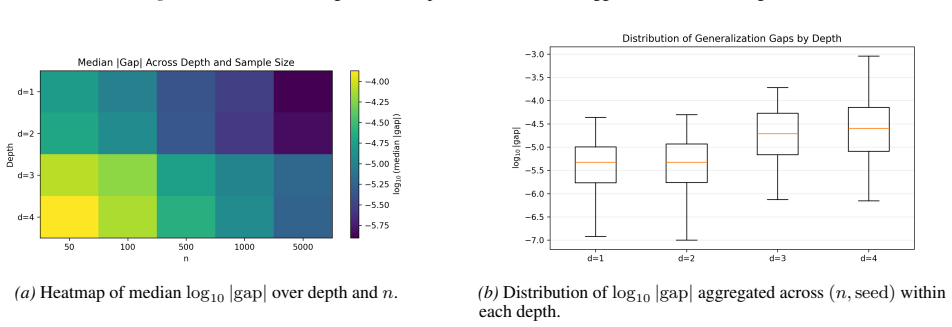
Under mild Lipschitz conditions on operators and bounded affine leaves, a finite-union bound over a vocabulary of size K together with Maurer-type vector contraction yields R_n(H_comp^d) ≤ (K b sqrt(2) L)^{d-1} R_n(H_comp^1), with corresponding high-probability risk bounds scaling as O(L^d / sqrt(n)) when K,b=O(1).
What carries the argument
Finite union bound over the vocabulary of size K combined with recursive Maurer vector contraction, which produces the depth-dependent multiplier (K b sqrt(2) L)^{d-1} on the base Rademacher complexity.
If this is right
- High-probability excess risk bounds scale as O(L^d / sqrt(n)) for fixed K and b.
- The combinatorial number of distinct symbolic structures does not appear in the leading term of the bound.
- Empirical generalization gaps observed when training differentiable operator trees correlate positively with the term (L^d)/sqrt(n).
- The bound applies directly to symbolic regression on targets of controlled depth built from the given operator vocabulary.
Where Pith is reading between the lines
- Preferring operators whose Lipschitz constants are close to one could keep the sample requirement modest even at larger depths.
- The contraction technique might extend to other structured hypothesis classes that compose a finite set of smooth maps.
- The theory supplies a concrete criterion for choosing operator vocabularies in symbolic regression systems.
- Direct verification of the bound on real scientific data would test whether the Lipschitz and bounded-leaf assumptions hold in practice.
Load-bearing premise
The base operators satisfy uniform Lipschitz conditions with a fixed constant L and the affine leaves are bounded.
What would settle it
An experiment in which the measured excess risk for depth-d trees fails to decrease proportionally to L^d over sqrt(n) as sample size n grows, or in which the empirical Rademacher complexity exceeds the stated multiplicative bound by more than a small constant factor.
Figures
read the original abstract
Scientific discovery via symbolic regression is often viewed as statistically and computationally intractable because the hypothesis space of expressions grows combinatorially with depth. This paper revisits the statistical side through the lens of PAC learning, focusing on compositional function trees built from a finite vocabulary of smooth operators (e.g., $\{+,\times,\sin,\exp\}$ and affine maps). We prove that the relevant generalization quantity, Rademacher complexity, hence the excess risk, does not necessarily blow up exponentially with the number of distinct symbolic structures, but is controlled by (i) the depth $d$ and (ii) the Lipschitz constants of the base operators along the composed computation graph. Concretely, under mild Lipschitz conditions on operators and bounded affine leaves, a finite-union bound over a vocabulary of size $K=|\mathcal{H}_{\mathrm{base}}|$ together with Maurer-type vector contraction yields $\mathfrak{R}_n(\mathcal{H}_{\mathrm{comp}}^{d}) \leq (Kb\sqrt{2}L)^{d-1}\mathfrak{R}_n(\mathcal{H}_{\mathrm{comp}}^{1})$ with arity bound $b$; corresponding high-probability risk bounds scale as $\mathcal{O}(L^{d}/\sqrt{n})$ when $K,b=O(1)$ and $\mathfrak{R}_n(\mathcal{H}_{\mathrm{comp}}^{1})=O(n^{-1/2})$. We complement the theory with a modular codebase that trains differentiable operator trees (not MLPs) on synthetic "physics-like" targets of controlled depth and shows that the empirical generalization gap correlates positively with the predicted complexity term $(\widehat{L}^{d})/\sqrt{n}$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that under mild Lipschitz conditions on base operators and bounded affine leaves, the Rademacher complexity of compositional function trees of depth d satisfies R_n(H_comp^d) ≤ (K b sqrt(2) L)^{d-1} R_n(H_comp^1) via finite union bound and Maurer-type vector contraction, yielding high-probability excess risk bounds of order O(L^d / sqrt(n)) for constant K, b. The theory is supported by experiments on synthetic physics-like targets showing positive correlation between the empirical generalization gap and the predicted term (L^d)/sqrt(n).
Significance. If the bound holds with the stated assumptions, the result would offer a useful PAC-learning analysis for symbolic regression, demonstrating that generalization is controlled by depth and operator Lipschitz constants rather than the combinatorial size of the expression space. The modular codebase for training differentiable operator trees (distinct from MLPs) is a strength, enabling direct verification of the empirical claims on controlled-depth targets.
major comments (1)
- [Abstract] Abstract: The derivation of R_n(H_comp^d) ≤ (K b sqrt(2) L)^{d-1} R_n(H_comp^1) applies Maurer vector contraction recursively under a uniform L-Lipschitz condition on all operators. However, the vocabulary includes exp (not globally Lipschitz) and × (Lipschitz constant depends on the magnitude of the other factor). Bounded affine leaves control only the depth-1 case; the abstract provides no mechanism to propagate explicit bounds on intermediate activations, so the contraction cannot be applied with depth-independent L for the full class H_comp^d.
minor comments (1)
- The description of the empirical correlation between generalization gap and (L^d)/sqrt(n) should report a quantitative statistic (e.g., Pearson r or regression slope with confidence interval) rather than a qualitative statement.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting an important point about the Lipschitz assumptions. We address the major comment below and will make the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The derivation of R_n(H_comp^d) ≤ (K b sqrt(2) L)^{d-1} R_n(H_comp^1) applies Maurer vector contraction recursively under a uniform L-Lipschitz condition on all operators. However, the vocabulary includes exp (not globally Lipschitz) and × (Lipschitz constant depends on the magnitude of the other factor). Bounded affine leaves control only the depth-1 case; the abstract provides no mechanism to propagate explicit bounds on intermediate activations, so the contraction cannot be applied with depth-independent L for the full class H_comp^d.
Authors: We agree that the abstract (and the current presentation) does not explicitly describe how bounded affine leaves induce bounds on intermediate activations, which is needed to justify uniform Lipschitz constants for operators such as exp and ×. The manuscript states the result under 'mild Lipschitz conditions on operators and bounded affine leaves,' intending these conditions to hold on the compact ranges determined by the leaves (where exp is Lipschitz and multiplication has a bounded local Lipschitz constant). However, an explicit inductive range-propagation argument is indeed absent. We will revise by adding a short preliminary lemma in Section 3 that inductively bounds the range of every node in a depth-d tree given bounded leaves; this justifies applying a single effective L (or folding any mild depth dependence into the existing O(L^d) term). The main complexity bound and all subsequent statements will be updated for clarity. This addresses the concern without altering the core proof strategy. revision: yes
Circularity Check
No circularity: bound obtained by direct application of standard Rademacher and contraction inequalities to tree structure.
full rationale
The derivation applies a finite-union bound over vocabulary size K together with Maurer-type vector contraction to obtain the recursive inequality R_n(H_comp^d) ≤ (K b sqrt(2) L)^{d-1} R_n(H_comp^1) under the stated Lipschitz and bounded-leaf assumptions. This is a standard chaining argument on the compositional hypothesis class and does not reduce any quantity to a fitted parameter, self-definition, or load-bearing self-citation; the result is independent of its own outputs and remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Base operators satisfy uniform Lipschitz conditions with constant L
- domain assumption Affine leaves are bounded
Reference graph
Works this paper leans on
-
[1]
A theory of the learnable , author=. Commun. ACM , year=
-
[2]
Rademacher and Gaussian Complexities: Risk Bounds and Structural Results , author=. J. Mach. Learn. Res. , year=
-
[3]
Annals of Statistics , year=
Empirical margin distributions and bounding the generalization error of combined classifiers , author=. Annals of Statistics , year=
-
[4]
Journal of Functional Analysis , year=
The Sizes of Compact Subsets of Hilbert Space and Continuity of Gaussian Processes , author=. Journal of Functional Analysis , year=
-
[5]
Annals of Probability , year=
A new look at independence , author=. Annals of Probability , year=
-
[6]
2014 , howpublished =
Probability in High Dimension , author =. 2014 , howpublished =
2014
-
[7]
2018 , edition=
Foundations of Machine Learning , author=. 2018 , edition=
2018
-
[8]
Journal of Machine Learning Research , year=
Stability and Generalization , author=. Journal of Machine Learning Research , year=
-
[9]
2010 , eprint =
Robustness and Generalization , author =. 2010 , eprint =
2010
-
[10]
Alquier, Pierre , year =. User-friendly Introduction to. doi:10.1561/2200000100 , note =. 2110.11216 , archivePrefix=
-
[12]
Langford, John and Seeger, Matthias , year =
-
[13]
PAC-Bayesian Generalization Error Bounds for Gaussian Process Classification , volume =
Seeger, Matthias , year =. PAC-Bayesian Generalization Error Bounds for Gaussian Process Classification , volume =. Journal of Machine Learning Research , doi =
-
[14]
Dziugaite, Gintare Karolina and Roy, Daniel M. , title =. Proceedings of the Thirty-Third Conference on Uncertainty in Artificial Intelligence,. 2017 , url =. 1703.11008 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[15]
Proceedings of the 26th International Conference on Machine Learning , pages =
Germain, Pascal and Lacasse, Alexandre and Laviolette, Fran. Proceedings of the 26th International Conference on Machine Learning , pages =. 2009 , doi =
2009
-
[17]
2014 , isbn =
Shalev-Shwartz, Shai and Ben-David, Shai , title =. 2014 , isbn =
2014
-
[18]
1991 , isbn =
Ledoux, Michel and Talagrand, Michel , title =. 1991 , isbn =
1991
-
[19]
and Wellner, Jon A
van der Vaart, Aad W. and Wellner, Jon A. , title =. 1996 , isbn =
1996
-
[20]
2014 , edition =
Talagrand, Michel , title =. 2014 , edition =
2014
-
[21]
Theoretical Computer Science , volume =
Maurer, Andreas , title =. Theoretical Computer Science , volume =. 2016 , doi =
2016
-
[23]
2011 , eprint =
Structured Sparsity and Generalization , author =. 2011 , eprint =
2011
-
[24]
2017 , eprint =
Spectrally-normalized margin bounds for neural networks , author =. 2017 , eprint =
2017
-
[25]
2017 , eprint=
Exploring Generalization in Deep Learning , author=. 2017 , eprint=
2017
-
[26]
Vapnik, Vladimir Naumovich , biburl =
-
[27]
Science , year =
Distilling Free-Form Natural Laws from Experimental Data , author =. Science , year =
-
[28]
, title =
Koza, John R. , title =. 1992 , isbn =
1992
-
[30]
2021 , eprint =
Deep Symbolic Regression: Recovering Mathematical Expressions from Data via Risk-Seeking Policy Gradients , author =. 2021 , eprint =
2021
-
[32]
Proceedings of the National Academy of Sciences , volume =
Bongard, Josh and Lipson, Hod , title =. Proceedings of the National Academy of Sciences , volume =. 2007 , doi =
2007
-
[33]
and Proctor, Joshua L
Brunton, Steven L. and Proctor, Joshua L. and Kutz, J. Nathan , title =. Proceedings of the National Academy of Sciences , year =
-
[34]
Journal of Computational Physics , volume =
Raissi, Maziar and Perdikaris, Paris and Karniadakis, George Em , title =. Journal of Computational Physics , volume =. 2019 , doi =
2019
-
[37]
2020 , eprint=
Discovering Symbolic Models from Deep Learning with Inductive Biases , author=. 2020 , eprint=
2020
-
[38]
2021 , eprint =
Contemporary Symbolic Regression Methods and their Relative Performance , author =. 2021 , eprint =
2021
-
[39]
Automatica , volume =
Rissanen, Jorma , title =. Automatica , volume =. 1978 , doi =
1978
-
[41]
Neurocomputing , volume =
Lei, Yunwen and Ding, Lixin and Bi, Yingzhou , title =. Neurocomputing , volume =. 2016 , doi =
2016
-
[42]
Journal of Machine Learning Research , year =
Kanade, Varun and Rebeschini, Patrick and Vaskevicius, Tomas , title =. Journal of Machine Learning Research , year =
-
[43]
and Kutz, J
Fasel, U. and Kutz, J. N. and Brunton, B. W. and Brunton, S. L. , title =. Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences , volume =. 2022 , doi =
2022
-
[44]
User-friendly introduction to pac-bayes bounds.arXiv preprint arXiv:2110.11216,
Alquier, P. User-friendly introduction to PAC - B ayes bounds, 2024. URL https://arxiv.org/abs/2110.11216. Foundations and Trends in Machine Learning
-
[45]
Bartlett, P. L. and Mendelson, S. Rademacher and gaussian complexities: Risk bounds and structural results. J. Mach. Learn. Res., 3: 0 463--482, 2003. URL https://api.semanticscholar.org/CorpusID:463216
2003
-
[46]
Spectrally-normalized margin bounds for neural networks
Bartlett, P. L., Foster, D. J., and Telgarsky, M. J. Spectrally-normalized margin bounds for neural networks, 2017. URL https://arxiv.org/abs/1706.08498
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[47]
Discovering governing equations from data by sparse identification of nonlinear dynamical systems
Brunton, S. L., Proctor, J. L., and Kutz, J. N. Discovering governing equations from data by sparse identification of nonlinear dynamical systems. Proceedings of the National Academy of Sciences, 113 0 (15): 0 3932--3937, 2016. doi:10.1073/pnas.1517384113
-
[48]
Catoni, O. PAC - B ayesian Supervised Classification: The Thermodynamics of Statistical Learning , volume 56 of Lecture Notes---Monograph Series. Institute of Mathematical Statistics, Beachwood, Ohio, 2007. ISBN 978-0-940600-68-7. doi:10.1214/074921707000000391. URL https://doi.org/10.1214/074921707000000391
-
[49]
Interpretable Machine Learning for Science with PySR and SymbolicRegression.jl
Cranmer, M. Interpretable machine learning for science with PySR and S ymbolic R egression.jl, 2023. URL https://arxiv.org/abs/2305.01582
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
URL https://arxiv.org/abs/2006.11287.2006.11287
Cranmer, M., Sanchez-Gonzalez, A., Battaglia, P., Xu, R., Cranmer, K., Spergel, D., and Ho, S. Discovering symbolic models from deep learning with inductive biases, 2020. URL https://arxiv.org/abs/2006.11287
-
[51]
Dudley, R. M. The sizes of compact subsets of hilbert space and continuity of gaussian processes. Journal of Functional Analysis, 1: 0 125--165, 1967. URL https://api.semanticscholar.org/CorpusID:122249056
1967
-
[52]
Exponential tail local R ademacher complexity risk bounds without the B ernstein condition
Kanade, V., Rebeschini, P., and Vaskevicius, T. Exponential tail local R ademacher complexity risk bounds without the B ernstein condition. Journal of Machine Learning Research, 25 0 (388): 0 1--43, 2024. URL http://jmlr.org/papers/v25/23-0063.html
2024
-
[53]
and Panchenko, D
Koltchinskii, V. and Panchenko, D. Empirical margin distributions and bounding the generalization error of combined classifiers. Annals of Statistics, 30: 0 1--50, 2002. URL https://api.semanticscholar.org/CorpusID:2307733
2002
-
[54]
Koza, J. R. Genetic Programming: On the Programming of Computers by Means of Natural Selection. MIT Press, Cambridge, MA, 1992. ISBN 978-0-262-11170-6
1992
-
[55]
La Cava, W., Orzechowski, P., Burlacu, B., Olivetti de Fran c a, F., Virgolin, M., Jin, Y., Kommenda, M., and Moore, J. H. Contemporary symbolic regression methods and their relative performance, 2021. URL https://arxiv.org/abs/2107.14351. NeurIPS 2021 Datasets and Benchmarks Track; introduces the SRBench suite
-
[56]
and Seeger, M
Langford, J. and Seeger, M. Bounds for averaging classifiers. 02 2001
2001
-
[57]
Ledoux, M. and Talagrand, M. Probability in B anach Spaces: Isoperimetry and Processes . Springer-Verlag, Berlin, 1991. ISBN 978-3-540-52013-9. doi:10.1007/978-3-642-20212-4
-
[58]
Local R ademacher complexity bounds based on covering numbers
Lei, Y., Ding, L., and Bi, Y. Local R ademacher complexity bounds based on covering numbers. Neurocomputing, 218: 0 320--330, 2016. doi:10.1016/j.neucom.2016.08.074
-
[59]
Makke, N. and Chawla, S. Interpretable scientific discovery with symbolic regression: a review. Artificial Intelligence Review, 57 0 (1), 2024. doi:10.1007/s10462-023-10622-0. URL https://doi.org/10.1007/s10462-023-10622-0. Article number 2
-
[60]
A chain rule for the expected suprema of G aussian processes
Maurer, A. A chain rule for the expected suprema of G aussian processes. Theoretical Computer Science, 650: 0 109--122, 2016 a . doi:10.1016/j.tcs.2016.07.034
-
[61]
A vector-contraction inequality for Rademacher complexities
Maurer, A. A vector-contraction inequality for R ademacher complexities, 2016 b . URL https://arxiv.org/abs/1605.00251
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[62]
Structured Sparsity and Generalization
Maurer, A. and Pontil, M. Structured sparsity and generalization, 2011. URL https://arxiv.org/abs/1108.3476
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[63]
McAllester, D. A. Some PAC - B ayesian theorems. Machine Learning, 37 0 (3): 0 355--363, 1999. doi:10.1023/A:1007618624809. URL https://doi.org/10.1023/A:1007618624809
-
[64]
Foundations of Machine Learning
Mohri, M., Rostamizadeh, A., and Talwalkar, A. Foundations of Machine Learning. MIT Press, Cambridge, MA, 2nd edition, 2018. ISBN 9780262039406
2018
-
[65]
Exploring Generalization in Deep Learning
Neyshabur, B., Bhojanapalli, S., McAllester, D., and Srebro, N. Exploring generalization in deep learning, 2017. URL https://arxiv.org/abs/1706.08947
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[66]
K., Landajuela, M., Mundhenk, T
Petersen, B. K., Landajuela, M., Mundhenk, T. N., Santiago, C. P., Kim, S. K., and Kim, J. T. Deep symbolic regression: Recovering mathematical expressions from data via risk-seeking policy gradients, 2021. URL https://arxiv.org/abs/1912.04871. Published at ICLR 2021
-
[67]
Modeling by shortest data description
Rissanen, J. Modeling by shortest data description. Automatica, 14 0 (5): 0 465--471, 1978. doi:10.1016/0005-1098(78)90005-5
-
[68]
Schmidt, M. D. and Lipson, H. Distilling free-form natural laws from experimental data. Science, 324 0 (5923): 0 81--85, 2009 a . doi:10.1126/science.1165893
-
[69]
Schmidt, M. D. and Lipson, H. Symbolic regression of implicit equations. In Genetic Programming Theory and Practice VII, Genetic and Evolutionary Computation, pp.\ 73--85. Springer, New York, 2009 b . doi:10.1007/978-1-4419-1626-6\_5. URL https://doi.org/10.1007/978-1-4419-1626-6\_5
-
[70]
Pac-bayesian generalization error bounds for gaussian process classification
Seeger, M. Pac-bayesian generalization error bounds for gaussian process classification. Journal of Machine Learning Research, 3, 08 2002. doi:10.1162/153244303765208386
-
[71]
Shalev-Shwartz, S. and Ben-David, S. Understanding Machine Learning: From Theory to Algorithms. Cambridge University Press, 2014. ISBN 978-1-107-05713-5. doi:10.1017/CBO9781107298019
-
[72]
Upper and Lower Bounds for Stochastic Processes: Modern Methods and Classical Problems
Talagrand, M. Upper and Lower Bounds for Stochastic Processes: Modern Methods and Classical Problems. Springer, Heidelberg, 2 edition, 2014. ISBN 978-3-642-54074-5. doi:10.1007/978-3-642-54075-2
- [73]
-
[74]
Udrescu, S.-M. and Tegmark, M. AI F eynman: A physics-inspired method for symbolic regression, 2020. URL https://arxiv.org/abs/1905.11481
-
[75]
Valiant, L. G. A theory of the learnable. Commun. ACM, 27: 0 1134--1142, 1984. URL https://api.semanticscholar.org/CorpusID:59712
1984
-
[76]
van der Vaart, A. W. and Wellner, J. A. Weak Convergence and Empirical Processes: With Applications to Statistics. Springer Series in Statistics. Springer, 1996. ISBN 978-0-387-94640-5. doi:10.1007/978-1-4757-2545-2
-
[77]
Vapnik, V. N. Statistical Learning Theory. Wiley, New York, NY, USA, September 1998
1998
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.