When Does Generating More Help? Disentangling Fixed-Source Synthesis from Source Expansion in Synthetic Data Scaling
Pith reviewed 2026-07-03 15:18 UTC · model grok-4.3
The pith
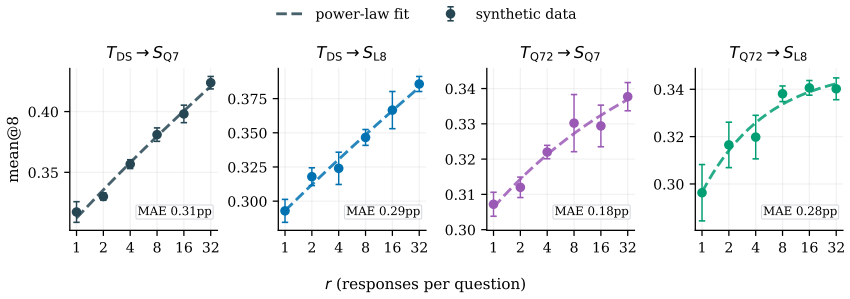
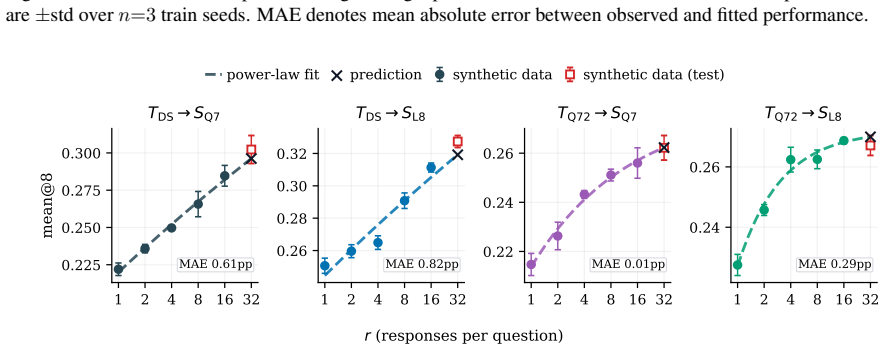
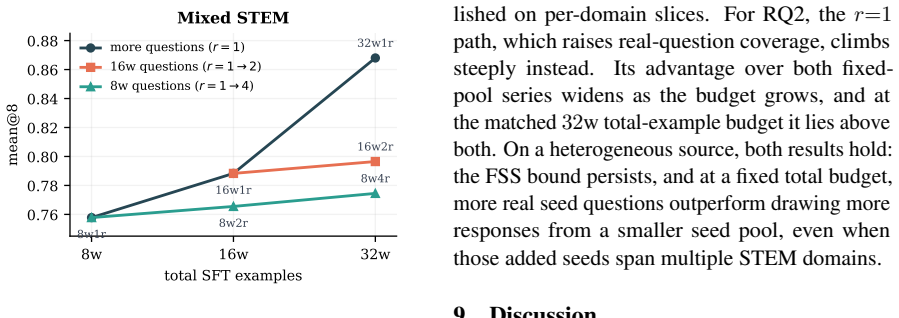
Scaling synthetic data by generating more responses from fixed seeds follows a derived law that predicts high-budget results, yet adding new seeds outperforms at large matched budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
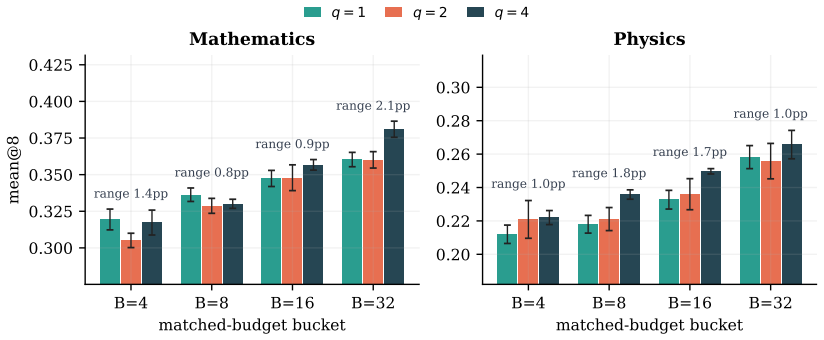
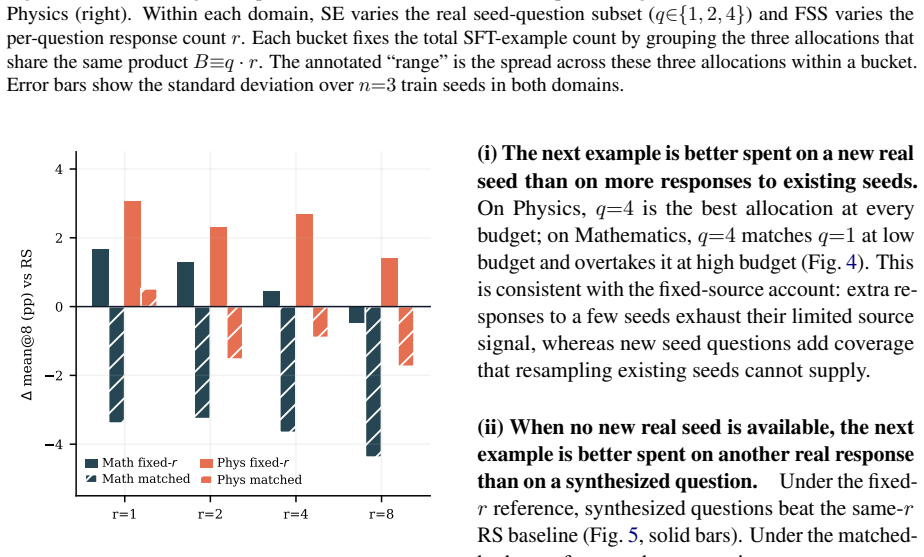
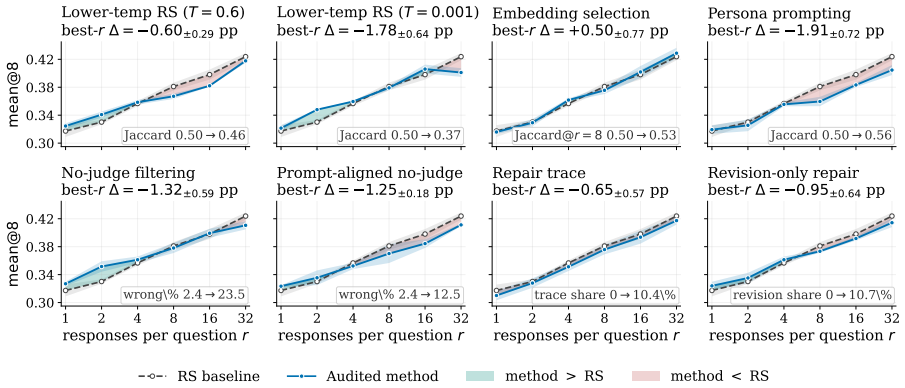
By holding the seed-question pool and teacher model fixed while varying only the per-question response budget under rejection sampling, the authors derive a rectified scaling law for fixed-source synthesis from the coverage achieved by repeated sampling. The resulting form, fitted on low budgets, predicts performance at the held-out highest budget for every evaluated teacher-student pair. At matched total-sample budgets, source expansion and fixed-source synthesis are comparable at small budgets, but adding seed questions outperforms at large budgets. Within fixed-source synthesis, synthesizing additional questions from existing seeds or varying the protocol does not outperform plain rejecti
What carries the argument
The adapted rectified scaling law for fixed-source synthesis, derived from repeated sampling coverage of a fixed source under rejection sampling.
If this is right
- High-budget performance under fixed-source synthesis can be forecasted from low-budget experiments without running the full scale.
- At large total data budgets, allocating resources to seed expansion is more effective than increasing the response count per seed.
- Fixed-source synthesis reaches a performance bound and cannot be improved beyond plain rejection sampling by the tested alternatives.
- Fixed-source synthesis supplies a controlled benchmark setting for comparing different synthesis protocols at matched budgets.
Where Pith is reading between the lines
- As budgets increase, synthetic data pipelines may need to prioritize methods that enlarge seed diversity rather than multiply samples from existing seeds.
- The separation between the two scaling axes could be examined in tasks or data types beyond language model fine-tuning to test generality.
- The bound observed in fixed-source synthesis likely depends on the initial diversity of the seed pool, suggesting experiments that vary seed quality.
Load-bearing premise
Fixing the seed-question pool and teacher model while varying only the per-question response budget under rejection sampling cleanly isolates fixed-source synthesis effects without confounding factors that would change the scaling behavior.
What would settle it
The scaling law fitted on low budgets fails to predict performance at the held-out highest budget for any teacher-student pair, or source expansion fails to outperform fixed-source synthesis at large matched total-sample budgets.
Figures

read the original abstract
Synthetic data can be scaled along two routes: Source Expansion (SE), which enlarges the source by adding seed materials or generators, and Fixed-Source Synthesis (FSS), which holds the source fixed and scales the generation budget. Existing scaling studies typically expand the source as the data grows, conflating SE with FSS and leaving FSS underexplored. We isolate FSS by holding the seed-question pool and teacher model fixed, varying only the per-question response budget under Rejection Sampling (RS). We adapt the rectified scaling law to FSS, deriving it from how repeated sampling covers a fixed source. Empirically, the derived form, fit on low budgets, predicts performance at the held-out highest budget for every evaluated teacher--student pair. At matched total-sample budgets, SE and FSS are comparable at small budgets; at large budgets, adding seed questions outperforms spending the same budget on more responses. Within FSS, however, neither synthesizing additional questions from the existing seeds nor varying the synthesis protocol outperforms plain RS at matched budgets. FSS is thus a bounded scaling axis and a controlled setting for comparing synthesis protocols. We will release our code and data to facilitate further research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to disentangle Fixed-Source Synthesis (FSS) from Source Expansion (SE) in synthetic data scaling by holding the seed-question pool and teacher model fixed while scaling only the per-question response budget under Rejection Sampling (RS). It adapts the rectified scaling law to FSS by deriving its form from repeated sampling coverage of a fixed source, shows that this form (fitted on low budgets) predicts performance at the held-out highest budget across evaluated teacher-student pairs, and reports that at matched total-sample budgets SE outperforms FSS at large scales while within FSS neither additional question synthesis nor alternative protocols beat plain RS. The conclusion is that FSS is a bounded scaling axis providing a controlled setting for protocol comparisons.
Significance. If the experimental isolation holds, the work supplies a controlled testbed for synthesis protocols and establishes that FSS saturates, informing compute allocation in synthetic data pipelines. The planned release of code and data is a concrete strength that supports reproducibility and follow-on work.
major comments (2)
- [§4] §4 (FSS isolation setup): The claim that fixing the seed-question pool and teacher while varying only per-question RS budget cleanly isolates FSS (without implicit source expansion or distribution shift from sampling dynamics or rejection criteria) is load-bearing for both the SE-vs-FSS comparison at matched budgets and the boundedness conclusion; the manuscript provides no auxiliary analysis (e.g., coverage metrics or distribution-shift tests) to confirm the assumption.
- [§3] §3 (adapted rectified scaling law): The derivation of the functional form from repeated sampling on a fixed source underpins the low-to-high budget prediction result; the paper does not verify whether the adapted law remains independent of the specific rejection threshold or temperature used in RS, which could affect the extrapolation claim.
minor comments (2)
- [Tables/Figures] Table 1 and Figure 3: axis labels and legend entries use inconsistent abbreviations for SE/FSS that are not defined on first use.
- [Related Work] Related-work section: the discussion of prior scaling-law adaptations omits explicit comparison to the original rectified law parameters, making the novelty of the FSS adaptation harder to assess.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major comment point by point below, providing our responses and indicating where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: [§4] §4 (FSS isolation setup): The claim that fixing the seed-question pool and teacher while varying only per-question RS budget cleanly isolates FSS (without implicit source expansion or distribution shift from sampling dynamics or rejection criteria) is load-bearing for both the SE-vs-FSS comparison at matched budgets and the boundedness conclusion; the manuscript provides no auxiliary analysis (e.g., coverage metrics or distribution-shift tests) to confirm the assumption.
Authors: The isolation of FSS is achieved by construction in our experimental setup: the seed-question pool is fixed, the teacher model is fixed, and we only vary the number of responses generated per question using Rejection Sampling with fixed rejection criteria and temperature. This ensures that the underlying source distribution remains unchanged, and performance improvements stem from increased coverage of that fixed source rather than source expansion. We acknowledge that the original manuscript does not include auxiliary analyses such as coverage metrics or explicit distribution-shift tests. To address this, we will add such analyses in the revised manuscript, for example by measuring the diversity of generated responses or checking for shifts in response characteristics across budgets. revision: yes
-
Referee: [§3] §3 (adapted rectified scaling law): The derivation of the functional form from repeated sampling on a fixed source underpins the low-to-high budget prediction result; the paper does not verify whether the adapted law remains independent of the specific rejection threshold or temperature used in RS, which could affect the extrapolation claim.
Authors: Our derivation of the adapted rectified scaling law models the effect of repeated sampling from a fixed source, resulting in a functional form that describes saturation due to coverage limits. The form is derived generally from the coverage process and is not tied to specific values of the rejection threshold or sampling temperature in the theoretical derivation. That said, we agree that verifying the law's robustness to variations in these hyperparameters would strengthen the extrapolation results. In the revision, we will include additional experiments testing the law's predictive accuracy under different rejection thresholds and temperatures. revision: yes
Circularity Check
No significant circularity; derivation and prediction are independent of inputs
full rationale
The paper adapts an external rectified scaling law and derives an FSS-specific form from the mechanics of repeated sampling on a fixed seed pool. It then fits parameters on low-budget data and evaluates predictive accuracy on a held-out high-budget point. This constitutes standard out-of-sample extrapolation rather than a reduction by construction. No self-citation chain, uniqueness theorem, or ansatz smuggling is load-bearing for the central claim in the provided text. The experimental isolation of FSS is an explicit design choice whose validity is separately debatable but does not create a definitional loop in the reported derivation.
Axiom & Free-Parameter Ledger
free parameters (1)
- parameters of the adapted rectified scaling law
axioms (1)
- domain assumption Repeated sampling under rejection sampling covers a fixed source in a manner that yields the adapted rectified scaling law form.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2502.08606 , year =
Distillation scaling laws , author =. arXiv preprint arXiv:2502.08606 , year =
-
[2]
International Conference on Learning Representations , volume =
Smaller, weaker, yet better: Training llm reasoners via compute-optimal sampling , author =. International Conference on Learning Representations , volume =
-
[3]
Scaling Synthetic Data Creation with 1,000,000,000 Personas
Scaling synthetic data creation with 1,000,000,000 personas , author =. arXiv preprint arXiv:2406.20094 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
International Conference on Learning Representations , volume =
Openmathinstruct-2: Accelerating ai for math with massive open-source instruction data , author =. International Conference on Learning Representations , volume =
-
[5]
Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages =
Self-instruct: Aligning language models with self-generated instructions , author =. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages =
-
[6]
Orca: Progressive Learning from Complex Explanation Traces of GPT-4
Orca: Progressive learning from complex explanation traces of gpt-4 , author =. arXiv preprint arXiv:2306.02707 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
2025 , eprint =
WizardLM: Empowering large pre-trained language models to follow complex instructions , author =. 2025 , eprint =
2025
-
[8]
Advances in Neural Information Processing Systems , volume =
Mammoth2: Scaling instructions from the web , author =. Advances in Neural Information Processing Systems , volume =
-
[9]
2025 , eprint =
Scaling Laws of Synthetic Data for Language Models , author =. 2025 , eprint =
2025
-
[10]
Advances in Neural Information Processing Systems , volume =
Supergpqa: Scaling llm evaluation across 285 graduate disciplines , author =. Advances in Neural Information Processing Systems , volume =
-
[11]
Critique-Guided Distillation for Robust Reasoning via Refinement
Critique-Guided Distillation for Efficient and Robust Language Model Reasoning , author =. arXiv preprint arXiv:2505.11628 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages =
Tagcos: Task-agnostic gradient clustered coreset selection for instruction tuning data , author =. Findings of the Association for Computational Linguistics: NAACL 2025 , pages =
2025
-
[13]
International Conference on Learning Representations , volume =
What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning , author =. International Conference on Learning Representations , volume =
-
[14]
Less: Selecting influential data for targeted instruction tuning.arXiv preprint arXiv:2402.04333,
Less: Selecting influential data for targeted instruction tuning , author =. arXiv preprint arXiv:2402.04333 , year =
-
[15]
Advances in neural information processing systems , volume =
Self-refine: Iterative refinement with self-feedback , author =. Advances in neural information processing systems , volume =
-
[16]
International Conference on Learning Representations , volume =
Supercorrect: Advancing small llm reasoning with thought template distillation and self-correction , author =. International Conference on Learning Representations , volume =
-
[17]
arXiv preprint arXiv:2505.24850 , year =
Harnessing Negative Signals: Reinforcement Distillation from Teacher Data for LLM Reasoning , author =. arXiv preprint arXiv:2505.24850 , year =
-
[18]
Deep Learning Scaling is Predictable, Empirically
Deep learning scaling is predictable, empirically. arXiv , author =. arXiv preprint arXiv:1712.00409 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Scaling Laws for Neural Language Models
Scaling laws for neural language models , author =. arXiv preprint arXiv:2001.08361 , year =
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[20]
Training Compute-Optimal Large Language Models
Training compute-optimal large language models , author =. arXiv preprint arXiv:2203.15556 , volume =
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Advances in Neural Information Processing Systems , volume =
Scaling data-constrained language models , author =. Advances in Neural Information Processing Systems , volume =
-
[22]
Scaling laws for transfer , author =. arXiv preprint arXiv:2102.01293 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
arXiv preprint arXiv:2402.02314 , year =
Selecting large language model to fine-tune via rectified scaling law , author =. arXiv preprint arXiv:2402.02314 , year =
-
[24]
Advances in Neural Information Processing Systems , volume =
The quantization model of neural scaling , author =. Advances in Neural Information Processing Systems , volume =
-
[25]
Prescriptive Scaling Laws for Data Constrained Training
Prescriptive Scaling Laws for Data Constrained Training , author =. arXiv preprint arXiv:2605.01640 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Nvidia nemotron nano 2: An accurate and efficient hybrid mamba-transformer reasoning model , author =. arXiv preprint arXiv:2508.14444 , year =
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.