Learning from Human Driving: A Human-in-the-Loop Online Behavior Cloning Framework for Autonomous Driving
Pith reviewed 2026-06-27 19:17 UTC · model grok-4.3
The pith
A human-in-the-loop online behavior cloning framework improves autonomous driving policies by incorporating real-time human interventions through three deployment phases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
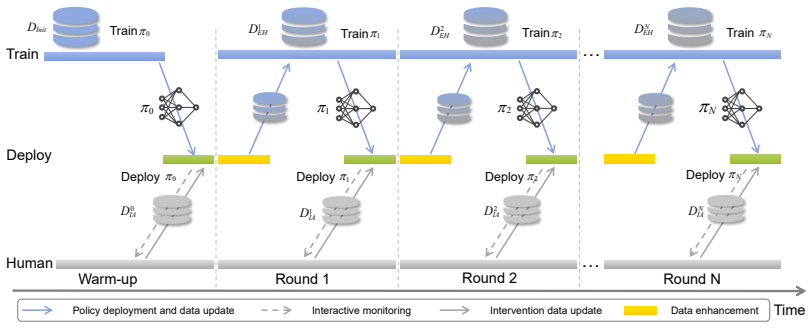
The HiL-OBC framework executes autonomous driving policy optimization in three phases—human-intervention initialization, Bayesian policy adaptation for latent behavioral modeling, and online deployment with updates—while the MOBC model applies a takeover trigger and multi-variant loss to a lightweight network, yielding measured driving score increases of 47.25 percent, 31.59 percent, and 32.12 percent for StructNav, LFG, and LMDrive on the LangAuto-Human CARLA benchmark.
What carries the argument
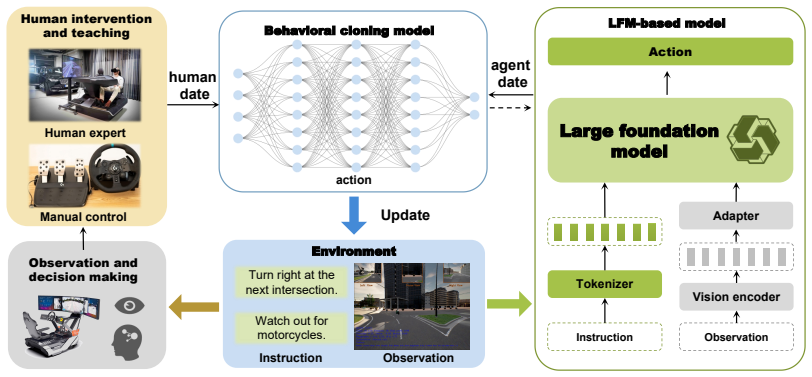
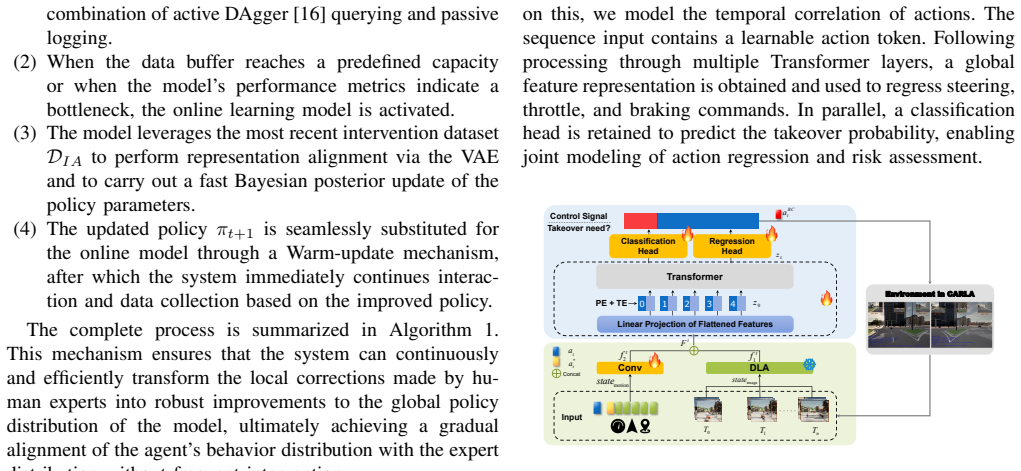
The Human-in-the-Loop Online Behavior Cloning (HiL-OBC) framework operating in three phases with the Multi-modal Online Behavior Cloning (MOBC) model that incorporates takeover triggers and multi-variant loss for online policy refinement.
If this is right
- Existing driving policies gain substantial robustness in complex and long-tail environments through continuous human-guided updates.
- The three-phase deployment allows initialization from human data followed by online refinement without full retraining.
- Multi-variant loss optimization in MOBC simultaneously improves decision-making across varied experimental settings.
- Integration with large foundation models supplies cross-modal perception while human input supplies high-level flexibility.
Where Pith is reading between the lines
- The same online takeover mechanism could be tested on physical vehicles to check whether simulation gains transfer when sensor noise and real-world delays appear.
- If takeover frequency stays low after initial training, the method might reduce reliance on ever-larger offline datasets by focusing human effort only on edge cases.
- Neighboring imitation-learning systems without explicit takeover triggers might adopt the Bayesian adaptation step to handle distribution shift more gracefully.
Load-bearing premise
Human interventions can be collected and incorporated online without introducing new biases, delays, or inconsistencies that undermine the Bayesian policy adaptation and multi-variant loss optimization.
What would settle it
A trial in which human takeover signals arrive with added latency or inconsistent quality and the reported driving score gains for the three baseline methods disappear or reverse.
Figures


read the original abstract
With the evolution of large foundation models (LFMs), data-driven autonomous driving has made significant strides. However, existing paradigms still face severe challenges in complex interaction and long-tail scenarios due to distribution shift and causal confusion. These limitations often result in a lack of human-level decision-making flexibility and safety in extreme conditions. To overcome this limitation, this paper proposes a Human-in-the-Loop Online Behavior Cloning frame work (HiL-OBC) for autonomous driving, which aims to deeply integrate the cross-modal perceptual capabilities of LFMs with the high-level driving intelligence of human experts. Specifically, HiL-OBC deployment is executed through three critical phases: policy initialization with human intervention, latent behavioral modeling with Bayesian policy adaptation, and online deploy ment and updates. Furthermore, we design a Multi-modal Online Behavior Cloning (MOBC) model, which optimizes the base driving policy online through a lightweight network architecture, a takeover trigger mechanism, and a multi-variant loss function, thereby enhancing the system's decision-making robustness in complex environments. We evaluated the HiL-OBC on the LangAuto-Human CARLA benchmark. Experimental results demonstrate that the driving policies optimized via the human-in-the-loop mechanism achieve substantial performance gains: the DS of StructNav, LFG, and LMDrive increased by 47.25%, 31.59%, and 32.12%, respectively, with a simultaneous of various experimental settings and key components highlights the advantages of human-in-the-loop learning in improving decision-making robustness and overall driving performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a Human-in-the-Loop Online Behavior Cloning (HiL-OBC) framework for autonomous driving that integrates large foundation models with human expertise via three deployment phases (policy initialization with human intervention, latent behavioral modeling with Bayesian policy adaptation, and online deployment/updates) and a Multi-modal Online Behavior Cloning (MOBC) model using a lightweight network, takeover trigger, and multi-variant loss. Evaluated on the LangAuto-Human CARLA benchmark, it claims that the approach yields driving score (DS) gains of 47.25%, 31.59%, and 32.12% for StructNav, LFG, and LMDrive respectively.
Significance. If the performance gains can be robustly attributed to the human-in-the-loop mechanism rather than unablated factors, the work would offer a practical route to improving robustness in long-tail driving scenarios by online incorporation of human interventions; however, the absence of controls, ablations, and statistical details in the presented results limits assessment of its potential impact on the field.
major comments (2)
- [Abstract] Abstract: the central claim attributes DS gains of 47.25%, 31.59%, and 32.12% to the HiL-OBC pipeline and MOBC model, yet supplies no information on baselines, statistical tests, error bars, data exclusion rules, or implementation details; this directly undermines verification that the gains arise from the human-in-the-loop component rather than other factors in the CARLA benchmark.
- [Method / Experimental Results] The three-phase deployment and MOBC loss description assume human interventions collected via the takeover trigger can be folded into Bayesian adaptation and multi-variant optimization without introducing new distribution shifts or causal confusion, but the evaluation provides no quantitative controls (e.g., intervention quality metrics, delay statistics, or comparison to offline human data) to support this assumption.
minor comments (2)
- [Abstract] Abstract contains an incomplete sentence: "with a simultaneous of various experimental settings and key components highlights the advantages" appears to be missing words (likely intended as an ablation study description).
- [Abstract] Minor typographical issues: "frame work" should be "framework"; inconsistent capitalization and phrasing in the method description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate where revisions will be made to improve clarity and support for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim attributes DS gains of 47.25%, 31.59%, and 32.12% to the HiL-OBC pipeline and MOBC model, yet supplies no information on baselines, statistical tests, error bars, data exclusion rules, or implementation details; this directly undermines verification that the gains arise from the human-in-the-loop component rather than other factors in the CARLA benchmark.
Authors: The abstract is necessarily concise, but we agree it would benefit from explicit context on the experimental setup. The full manuscript uses the original StructNav, LFG, and LMDrive models as baselines and reports gains relative to these without the HiL-OBC components; ablation studies on key components and experimental settings are also presented to isolate the human-in-the-loop contribution. In revision we will expand the abstract to name the baselines and reference the Experiments section for statistical details, error bars, and implementation information. revision: yes
-
Referee: [Method / Experimental Results] The three-phase deployment and MOBC loss description assume human interventions collected via the takeover trigger can be folded into Bayesian adaptation and multi-variant optimization without introducing new distribution shifts or causal confusion, but the evaluation provides no quantitative controls (e.g., intervention quality metrics, delay statistics, or comparison to offline human data) to support this assumption.
Authors: The takeover trigger, multi-variant loss, and Bayesian adaptation are designed to incorporate interventions while mitigating shifts, and the LangAuto-Human benchmark uses online human data. We acknowledge that the current evaluation does not report explicit intervention quality metrics, delay statistics, or offline comparisons. In the revised manuscript we will add a dedicated analysis subsection with these quantitative controls drawn from our existing logs to directly address the assumption. revision: yes
Circularity Check
No circularity: empirical framework validated by benchmark experiments
full rationale
The paper describes a three-phase HiL-OBC deployment and MOBC model (policy initialization, Bayesian adaptation, online updates with takeover trigger and multi-variant loss) but presents no equations, derivations, or fitted-parameter predictions. Performance gains (DS increases of 47.25%, 31.59%, 32.12%) are reported as direct experimental outcomes on the LangAuto-Human CARLA benchmark. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or framework description. The central claim rests on external benchmark measurements rather than reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
LMDrive: Closed-loop end-to-end driving with large language models,
H. Shao, Y . Hu, L. Wang, G. Song, S. L. Waslander, Y . Liu, and H. Li, “LMDrive: Closed-loop end-to-end driving with large language models,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 15 120–15 130
2024
-
[2]
A connectivity- based real-time traffic prediction considering lane-changing maneuvers with application to eco-driving control of electric vehicles,
S. He, S. Wang, Y . Shao, Z. Sun, and M. W. Levin, “A connectivity- based real-time traffic prediction considering lane-changing maneuvers with application to eco-driving control of electric vehicles,”IEEE Trans. V eh. Technol., vol. 75, no. 1, pp. 168–181, 2026
2026
-
[3]
A survey on recent advancements in autonomous driving using deep reinforcement learning: Applications, challenges, and solutions,
R. Zhao, Y . Li, Y . Fan, F. Gao, M. Tsukada, and Z. Gao, “A survey on recent advancements in autonomous driving using deep reinforcement learning: Applications, challenges, and solutions,”IEEE Trans. Intell. Transp. Syst., vol. 25, no. 12, pp. 19 365–19 398, 2024
2024
-
[4]
Alleviating shifted distribution in human preference alignment through meta-learning,
S. Dou, Y . Liu, E. Zhou, S. Gao, T. Li, L. Xiong, X. Zhao, H. Jia, J. Ye, R. Zheng, T. Gui, Q. Zhang, and X. Huang, “Alleviating shifted distribution in human preference alignment through meta-learning,” in Proc. AAAI Conf. Artif. Intell. (AAAI), 2025, pp. 23 805–23 813
2025
-
[5]
DriveGPT4: Interpretable end-to-end autonomous driving via large language model,
Z. Xu, Y . Zhang, E. Xie, Z. Zhao, Y . Guo, K.-Y . K. Wong, Z. Li, and H. Zhao, “DriveGPT4: Interpretable end-to-end autonomous driving via large language model,”IEEE Robot. Autom. Lett., vol. 9, no. 10, pp. 8186–8193, 2024
2024
-
[6]
ReasonDrive: Efficient visual question answer- ing for autonomous vehicles with reasoning-enhanced small vision- language models,
A. Chahe and L. Zhou, “ReasonDrive: Efficient visual question answer- ing for autonomous vehicles with reasoning-enhanced small vision- language models,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2025, pp. 3870–3879
2025
-
[7]
P. Zheng, Y . Zhao, Z. Gong, H. Zhu, and S. Wu, “SimpleLLM4AD: An end-to-end vision-language model with graph visual question answering for autonomous driving,”arXiv preprint arXiv:2407.21293, 2024
-
[8]
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
X. Tian, J. Gu, B. Li, Y . Liu, Z. Zhao, Y . Wang, K. Zhan, P. Jia, X. Lang, and H. Zhao, “DriveVLM: The convergence of autonomous driving and large vision-language models,”arXiv preprint arXiv:2402.12289, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Human- guided deep reinforcement learning for optimal decision making of autonomous vehicles,
J. Wu, H. Yang, L. Yang, Y . Huang, X. He, and C. Lv, “Human- guided deep reinforcement learning for optimal decision making of autonomous vehicles,”IEEE Trans. Syst., Man, Cybern., Syst., vol. 54, no. 11, pp. 6595–6609, 2024
2024
-
[10]
Safety-aware human-in- the-loop reinforcement learning with shared control for autonomous driving,
W. Huang, H. Liu, Z. Huang, and C. Lv, “Safety-aware human-in- the-loop reinforcement learning with shared control for autonomous driving,”IEEE Trans. Intell. Transp. Syst., vol. 25, no. 11, pp. 16 181– 16 192, 2024
2024
-
[11]
Human-in-the-loop gaussian splatting for robotic teleoperation,
Y . Lee, H. Kim, H. Ji, J. Heo, Y . Lee, J. Kang, J. Lee, and D. Lee, “Human-in-the-loop gaussian splatting for robotic teleoperation,”IEEE Robot. Autom. Lett., vol. 11, no. 1, pp. 105–112, 2026
2026
-
[12]
Research on the steering torque control for intelligent vehicles co-driving with the penalty factor of human–machine intervention,
J. Wu, Q. Kong, K. Yang, Y . Liu, D. Cao, and Z. Li, “Research on the steering torque control for intelligent vehicles co-driving with the penalty factor of human–machine intervention,”IEEE Trans. Syst., Man, Cybern., Syst., vol. 53, no. 1, pp. 59–70, 2023
2023
-
[13]
Evolutionary decision-making and planning for autonomous driving: A hybrid augmented intelligence framework,
K. Yuan, Y . Huang, S. Yang, M. Wu, D. Cao, Q. Chen, and H. Chen, “Evolutionary decision-making and planning for autonomous driving: A hybrid augmented intelligence framework,”IEEE Trans. Intell. Transp. Syst., vol. 25, no. 7, pp. 7339–7351, 2024
2024
-
[14]
Brain-inspired modeling and decision- making for human-like autonomous driving in mixed traffic environ- ment,
P. Hang, Y . Zhang, and C. Lv, “Brain-inspired modeling and decision- making for human-like autonomous driving in mixed traffic environ- ment,”IEEE Trans. Intell. Transp. Syst., vol. 24, no. 10, pp. 10 420– 10 432, 2023
2023
-
[15]
CARLA: An open urban driving simulator,
A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V . Koltun, “CARLA: An open urban driving simulator,” inProc. Conf. Robot Learn. (CoRL), 2017, pp. 1–16
2017
-
[16]
A reduction of imitation learning and structured prediction to no-regret online learning,
S. Ross, G. Gordon, and D. Bagnell, “A reduction of imitation learning and structured prediction to no-regret online learning,” inProc. 14th Int. Conf. Artif. Intell. Statist. (AISTATS), 2011, pp. 627–635
2011
-
[17]
Deep layer aggrega- tion,
F. Yu, D. Wang, E. Shelhamer, and T. Darrell, “Deep layer aggrega- tion,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2018, pp. 2403–2412
2018
-
[18]
Focal loss for dense object detection,
T.-Y . Lin, P. Goyal, R. Girshick, K. He, and P. Doll ´ar, “Focal loss for dense object detection,” inProc. IEEE Int. Conf. Comput. Vis. (ICCV), 2017, pp. 2980–2988
2017
-
[19]
Learning to navigate unseen en- vironments: Back translation with environmental dropout,
H. Tan, L. Yu, and M. Bansal, “Learning to navigate unseen en- vironments: Back translation with environmental dropout,” inProc. IEEE/CVF North Am. Chapter Assoc. Comput. Linguist. (NAACL- HLT), 2019, pp. 2610–2621
2019
-
[20]
VLN- BERT: A recurrent vision-and-language BERT for navigation,
Y . Hong, Q. Wu, Y . Qi, C. Rodriguez-Opazo, and S. Gould, “VLN- BERT: A recurrent vision-and-language BERT for navigation,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2021, pp. 1643–1653
2021
-
[21]
History aware multimodal Transformer for vision-and-language navigation,
S. Chen, P.-L. Guhur, C. Schmid, and I. Laptev, “History aware multimodal Transformer for vision-and-language navigation,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2021, pp. 5676–5688
2021
-
[22]
How to not train your dragon: Training-free embodied object goal navigation with semantic frontiers,
J. Chen, G. Li, S. Kumar, B. Ghanem, and F. Yu, “How to not train your dragon: Training-free embodied object goal navigation with semantic frontiers,” inProc. Robot. Sci. Syst. (RSS), 2024
2024
-
[23]
Navigation with large language models: Semantic guesswork as a heuristic for planning,
D. Shah, M. R. Equi, B. Osi ´nski, F. Xia, B. Ichter, and S. Levine, “Navigation with large language models: Semantic guesswork as a heuristic for planning,” inProc. Conf. Robot Learn. (CoRL), ser. PMLR, vol. 229, 2023, pp. 2683–2699
2023
-
[24]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2016, pp. 770–778
2016
-
[25]
Stacked hourglass networks for human pose estimation,
A. Newell, K. Yang, and J. Deng, “Stacked hourglass networks for human pose estimation,” inProc. Eur . Conf. Comput. Vis. (ECCV), 2016, pp. 483–499
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.