Neural Variance-aware Dueling Bandits with Deep Representation and Shallow Exploration
Pith reviewed 2026-05-19 11:26 UTC · model grok-4.3
The pith
Variance-aware neural algorithms for contextual dueling bandits achieve sublinear regret of order O(d sqrt(sum sigma_t^2) + sqrt(dT)).
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under standard assumptions, the proposed algorithms achieve sublinear cumulative average regret of order O(d sqrt(sum_{t=1}^T sigma_t^2) + sqrt(dT)) for sufficiently wide neural networks, where d is the contextual dimension, sigma_t^2 is the variance of comparisons at round t, and T is the total number of rounds. The design balances exploration and exploitation while relying solely on last-layer gradients for the variance-aware component.
What carries the argument
Variance-aware exploration strategy that adaptively accounts for uncertainty in pairwise comparisons while relying only on gradients with respect to the learnable parameters of the last layer.
If this is right
- The algorithms provide theoretical guarantees under both Upper Confidence Bound and Thompson Sampling frameworks.
- They apply to nonlinear utility functions via wide neural networks.
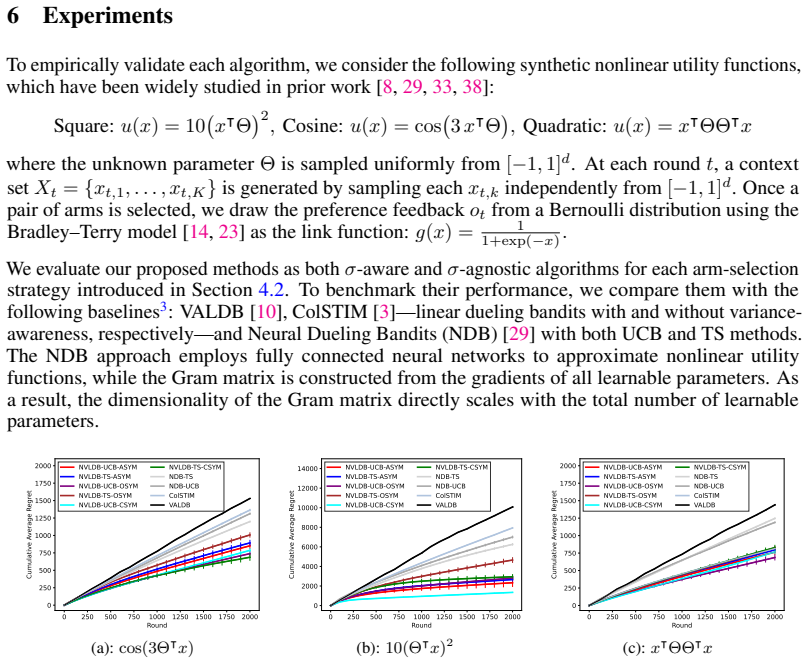
- Empirical validation shows sublinear regret on synthetic nonlinear tasks and real-world tasks while maintaining reasonable computational efficiency.
- The methods outperform existing approaches in the reported experiments.
Where Pith is reading between the lines
- This approach may extend naturally to recommendation systems where user preferences exhibit complex nonlinear structure.
- It suggests that deep representations paired with shallow last-layer exploration can reduce computation in high-dimensional preference learning.
- The variance-dependent term in the regret bound could guide practical tuning when comparison noise varies across rounds.
Load-bearing premise
The neural networks must be sufficiently wide to approximate the unknown nonlinear utility functions and the variance-aware exploration must be effective when computed solely from last-layer gradients.
What would settle it
An experiment showing linear regret growth when using sufficiently wide neural networks on nonlinear utilities or when last-layer gradient variance estimates fail to adapt exploration properly.
Figures
read the original abstract
We introduce the first variance-aware algorithms for contextual dueling bandits that leverage shallow exploration strategies with neural networks for nonlinear utility approximation. A key theoretical challenge is the absence of a closed-form estimator, which led prior work to require an extremely large network width $m$ (i.e., $m = \widetilde{\Omega}(T^{14})$). We address this constraint with a novel analytical approach that combines iterative self-improvement with spectral analysis. Our analysis significantly reduces the network width requirement to $m = \widetilde{\Omega}(T^{6})$, and shows that our algorithms achieve a sublinear regret of $\widetilde{\mathcal{O}}(d\sqrt{\sum_{t=1}^{T} \sigma_t^2} + \sqrt{dT})$ under both UCB and TS frameworks. Empirical results show that the proposed algorithms are not only computationally efficient and exhibit sublinear regret in practical settings, but also achieve state-of-the-art performance on both synthetic and real-world tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes variance-aware UCB and Thompson Sampling algorithms for contextual dueling bandits. These use neural networks to model nonlinear utility functions but compute the exploration bonus exclusively from last-layer gradients. Under standard assumptions, the algorithms are claimed to achieve sublinear cumulative average regret of order O(d sqrt(sum_{t=1}^T sigma_t^2) + sqrt(d T)) when the networks are sufficiently wide. Empirical results on synthetic nonlinear tasks and real-world datasets are reported to show sublinear regret and outperformance relative to prior methods.
Significance. If the central regret bound holds, the work would be significant for demonstrating that deep representations can be paired with computationally cheap last-layer-only variance estimation to obtain adaptive, variance-aware regret bounds in dueling settings. This design choice could improve scalability over methods that propagate uncertainty through all layers. The explicit dependence on the per-round comparison variance sigma_t^2 is a positive feature of the stated bound.
major comments (1)
- [Abstract] Abstract and the regret statement: the bound O(d sqrt(sum sigma_t^2) + sqrt(d T)) is derived under the assumption that last-layer gradients alone suffice to set the variance-aware widths. No explicit width-dependent or depth-dependent error term is supplied to absorb residual uncertainty from earlier layers, which would be required for the concentration inequalities underlying the UCB/TS analysis to remain valid. This is load-bearing for the central theoretical claim.
minor comments (3)
- [Theoretical Analysis] Clarify the precise definition of 'sufficiently wide' networks and state the minimal width scaling required for the approximation and concentration arguments to go through.
- [Experiments] In the experimental section, report the network depths and widths used, together with the precise form of the last-layer gradient computation for the bonus.
- [Abstract] The notation in the regret expression uses non-standard delimiters; replace with standard big-O notation for readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for identifying this important point regarding the theoretical justification. We address the major comment below and will incorporate clarifications in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract and the regret statement: the bound O(d sqrt(sum sigma_t^2) + sqrt(d T)) is derived under the assumption that last-layer gradients alone suffice to set the variance-aware widths. No explicit width-dependent or depth-dependent error term is supplied to absorb residual uncertainty from earlier layers, which would be required for the concentration inequalities underlying the UCB/TS analysis to remain valid. This is load-bearing for the central theoretical claim.
Authors: We agree that an explicit discussion of the approximation error from earlier layers would strengthen the rigor of the presentation. Our analysis is conducted in the wide-network regime where, under standard NTK assumptions, the hidden-layer representations become effectively fixed after random initialization, and the uncertainty in the utility estimates is captured by the last-layer parameters. The width-dependent terms that control the quality of this approximation appear in the concentration arguments but were not highlighted in the abstract or main regret statement. We will revise the abstract, the statement of the main theorem, and the proof sketch to include an explicit remark on the width-dependent error term that absorbs residual uncertainty from earlier layers, ensuring the concentration inequalities remain valid. This does not change the leading-order regret bound but makes the assumptions more transparent. revision: yes
Circularity Check
No circularity: regret bound derived from standard assumptions without reduction to inputs
full rationale
The paper claims a sublinear regret bound O(d sqrt(sum sigma_t^2) + sqrt(d T)) under standard assumptions for sufficiently wide neural networks, using variance-aware exploration based on last-layer gradients. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations are present in the abstract or described derivation. The last-layer focus is an explicit design choice justified by computational efficiency and wide-network approximation, not a circular redefinition of the bound itself. The result is presented as following from independent theoretical analysis rather than by construction from the algorithm's own outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Standard assumptions for contextual dueling bandits hold
- domain assumption Neural networks are sufficiently wide to approximate nonlinear utilities
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.