SING: Synthetic Intention Graph for Scalable Active Tool Discovery in LLM Agents
Pith reviewed 2026-06-27 03:54 UTC · model grok-4.3
The pith
SING constructs an intention-tool graph to allow LLM agents to discover relevant tools dynamically from large corpora without full schema exposure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
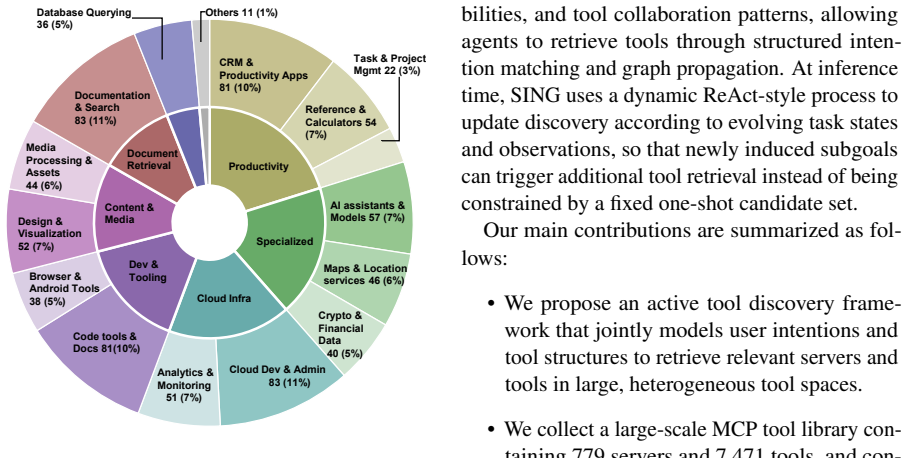
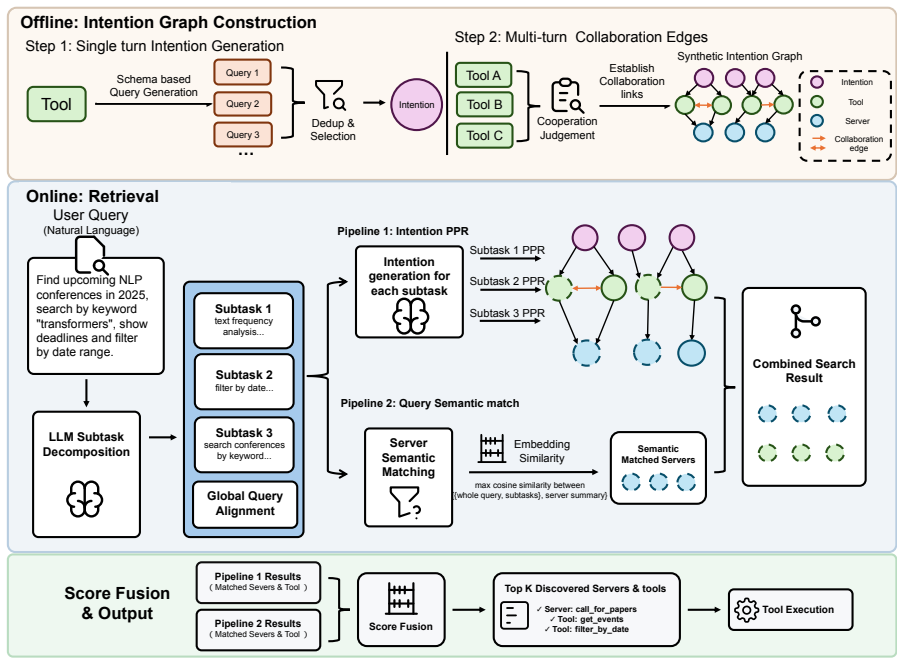
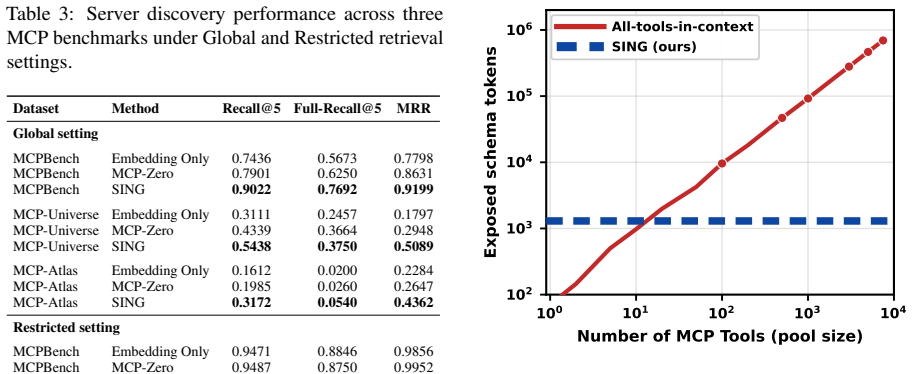
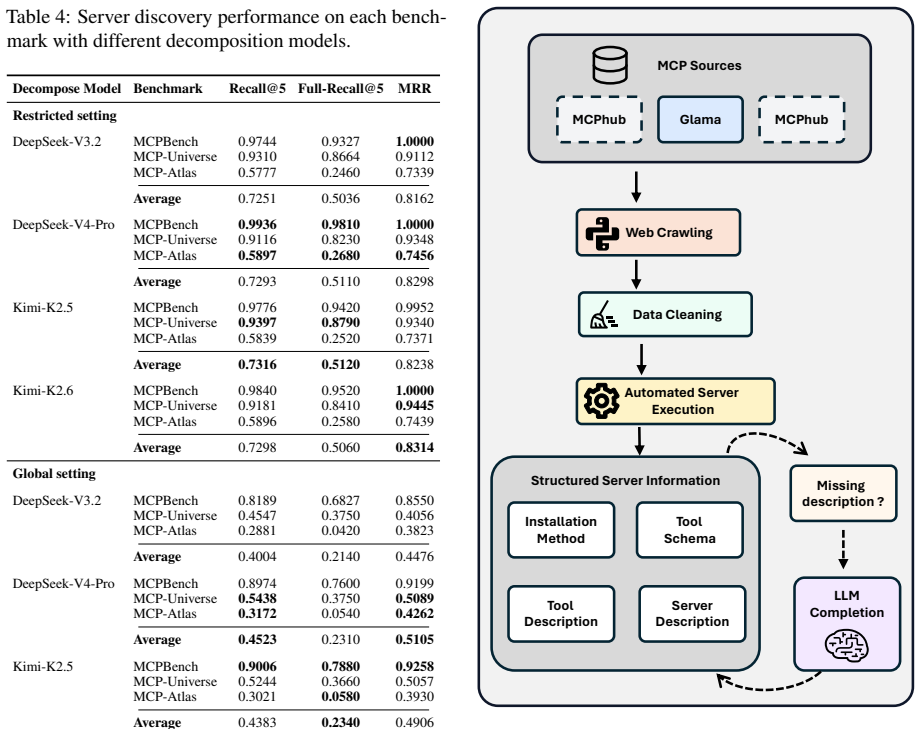
SING is an intention-aware active tool discovery framework that builds an intention-tool graph linking user intentions, tool capabilities, and tool collaboration patterns, and dynamically retrieves tools according to evolving task states. Using a unified corpus of 7,471 tools, we evaluate SING on three real-world tool-use benchmarks. SING improves Global Recall@5 by up to 59.8% and downstream success rate by up to 28.9% over baselines, while reducing full-corpus tool-schema exposure by 99.8%.
What carries the argument
The intention-tool graph that links user intentions, tool capabilities, and tool collaboration patterns for dynamic retrieval based on evolving task states.
If this is right
- LLM agents can operate in larger tool ecosystems without context overload from exhaustive schema injection.
- Tool selection aligns better with true task intentions, especially in long-horizon tasks involving decomposition and subgoals.
- Agent harnesses can manage context more efficiently by retrieving only relevant tools on demand.
- Scalability improves as the number of available tools grows to thousands.
Where Pith is reading between the lines
- Graph-based intention modeling could extend to other areas like API composition or multi-agent coordination.
- Updating the graph with new tools and observed collaborations might allow continuous adaptation without retraining.
- Testing the approach in open-ended environments with user-provided tools would reveal its robustness beyond curated corpora.
Load-bearing premise
The unified corpus and constructed graph accurately capture real-world user intentions, tool capabilities, and collaboration patterns that generalize to unseen tasks and tool sets.
What would settle it
Running the system on a new benchmark containing tools and tasks not represented in the original 7,471 tool corpus and measuring whether the reported gains in recall and success rate hold.
Figures
read the original abstract
Large language model (LLM) agents increasingly rely on agent harnesses that manage context, tools, and multi-turn execution, making tools a central interface for acting in realistic digital environments. As harness-connected tool ecosystems expand to hundreds or thousands of APIs, services, and task-specific skills, exhaustive tool schema injection becomes costly and imposes a closed-world assumption that limits agents to a predefined static inventory. Retrieval-augmented tool selection offers a natural alternative, but existing one-shot retrieval methods often fail to align isolated tool descriptions with the agent's true task intention, especially in long-horizon tasks where required capabilities emerge through decomposition, observations, and newly induced subgoals. We propose SING, an intention-aware active tool discovery framework that builds an intention-tool graph linking user intentions, tool capabilities, and tool collaboration patterns, and dynamically retrieves tools according to evolving task states. Using a unified corpus of 7,471 tools, we evaluate SING on three real-world tool-use benchmarks. SING improves Global Recall@5 by up to 59.8% and downstream success rate by up to 28.9% over baselines, while reducing full-corpus tool-schema exposure by 99.8%, demonstrating that intention-aware graph structure enables more accurate and context-efficient tool discovery in large-scale agentic ecosystems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SING, an intention-aware active tool discovery framework that constructs a Synthetic Intention Graph linking user intentions, tool capabilities, and collaboration patterns from a unified corpus of 7,471 tools. It dynamically retrieves tools for LLM agents based on evolving task states and evaluates the approach on three real-world tool-use benchmarks, claiming improvements of up to 59.8% in Global Recall@5 and 28.9% in downstream success rate over baselines, alongside a 99.8% reduction in full-corpus tool-schema exposure.
Significance. If the reported gains hold under proper controls for generalization and baseline fidelity, the work would offer a practical path toward scalable tool use in large agentic systems by replacing exhaustive schema injection with structured, intention-driven retrieval; the emphasis on graph-based decomposition of long-horizon tasks addresses a recognized bottleneck in current retrieval-augmented agents.
major comments (2)
- [Abstract / Evaluation] Abstract and Evaluation section: the headline gains (Global Recall@5 +59.8%, success rate +28.9%) are obtained on a fixed corpus of 7,471 tools whose intention-tool graph is constructed from the same data; the manuscript must demonstrate that the synthetic intentions and collaboration patterns transfer to held-out tasks or novel tool inventories, as this is the load-bearing assumption for the generalization claim.
- [Evaluation] Evaluation section: no information is supplied on statistical significance, error bars, variance across runs, or the precise implementation details of the baselines; without these, it is impossible to assess whether the reported deltas are robust or could be artifacts of post-hoc benchmark selection or corpus construction.
minor comments (1)
- [Abstract] Abstract: the description of graph construction and dynamic update mechanism is too high-level to allow replication or to judge whether the 99.8% exposure reduction is achieved without sacrificing recall on complex multi-turn tasks.
Simulated Author's Rebuttal
We thank the referee for the thoughtful feedback. Below we respond point-by-point to the major comments, offering clarifications on the evaluation design and committing to additions that strengthen the claims.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: the headline gains (Global Recall@5 +59.8%, success rate +28.9%) are obtained on a fixed corpus of 7,471 tools whose intention-tool graph is constructed from the same data; the manuscript must demonstrate that the synthetic intentions and collaboration patterns transfer to held-out tasks or novel tool inventories, as this is the load-bearing assumption for the generalization claim.
Authors: The intention-tool graph is built solely from the static corpus of 7,471 tool descriptions and synthetically generated intentions; the three benchmarks supply task instances and evolving state sequences that were never used in graph construction. This separation already tests generalization to unseen task decompositions. Nevertheless, to directly address transfer to novel tool inventories we will add an explicit held-out tool partition experiment in the revised manuscript. revision: yes
-
Referee: [Evaluation] Evaluation section: no information is supplied on statistical significance, error bars, variance across runs, or the precise implementation details of the baselines; without these, it is impossible to assess whether the reported deltas are robust or could be artifacts of post-hoc benchmark selection or corpus construction.
Authors: We agree these details are required. The revised manuscript will report means and standard deviations over multiple random seeds, include statistical significance tests for the key deltas, and supply complete baseline implementations, hyperparameters, and prompt templates. revision: yes
Circularity Check
No significant circularity; claims rest on empirical evaluation of constructed graph
full rationale
The paper constructs an intention-tool graph from a unified corpus of 7,471 tools and reports measured improvements (Global Recall@5, success rate, exposure reduction) on three benchmarks. No equations, parameter-fitting steps, or self-citation chains are present that reduce any claimed result to its inputs by definition or construction. The central claims are externally falsifiable via the reported benchmark metrics and do not rely on self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Synthetic Intention Graph (SING)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Mcpagentbench: A real-world task bench- mark for evaluating llm agent mcp tool use.Preprint, arXiv:2512.24565. Ziyang Luo, Zhiqi Shen, Wenzhuo Yang, Zirui Zhao, Prathyusha Jwalapuram, Amrita Saha, Doyen Sahoo, Silvio Savarese, Caiming Xiong, and Junnan Li. 2025. Mcp-universe: Benchmarking large language mod- els with real-world model context protocol serv...
arXiv 2025
-
[2]
Mcp-bench: Benchmarking tool-using llm agents with complex real-world tasks via mcp servers. Preprint, arXiv:2508.20453. Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, and 1 others
-
[3]
Advances in Neural Information Processing Systems, 37:52040–52094
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. Advances in Neural Information Processing Systems, 37:52040–52094. Zhangchen Xu, Adriana Meza Soria, Shawn Tan, Anurag Roy, Ashish Sunil Agrawal, Radha Pooven- dran, and Rameswar Panda. 2025. Toucan: Synthe- sizing 1.5m tool-agentic data from real-world mcp environ...
arXiv 2025
-
[4]
Yuanhang Zheng, Peng Li, Wei Liu, Yang Liu, Jian Luan, and Bin Wang
Clawbench: Can ai agents complete everyday online tasks?Preprint, arXiv:2604.08523. Yuanhang Zheng, Peng Li, Wei Liu, Yang Liu, Jian Luan, and Bin Wang. 2024. Toolrerank: Adap- tive and hierarchy-aware reranking for tool re- trieval. InProceedings of the 2024 joint international conference on computational linguistics, language resources and evaluation (L...
Pith/arXiv arXiv 2024
-
[5]
Each instruction should be a natural user request (as if a user is asking an AI assistant)
-
[6]
Instructions should be DIVERSE -- vary the specific entities, parameters, and complexity
-
[7]
Arguments must match the tool's parameter schema -- use realistic values
-
[8]
xxx" or
Do NOT use placeholder values like "xxx" or "example" -- use realistic but fictional data
-
[9]
source_instruction
Output ONLY a JSON array, each element has " source_instruction" (string) and "arguments" (object) Example output format: [ {{"source_instruction": "FindallflightsfromNew York to London on December 15th", "arguments": {{"origin": "JFK", "destination": "LHR", "date": "2024-12-15"}}}}, {{"source_instruction": "Searchforthe cheapest flights to Tokyonextweek"...
2024
-
[10]
Evaluate whether any of the available tools can NATURALLY extend the user's query
-
[11]
The extension must be a logical follow-up or complement -- NOT forced or artificial
-
[12]
can_extend
The extended query should read as a SINGLE coherent user request that naturally requires both old and new tools Key criteria for a MEANINGFUL extension: - The new tool provides genuine additional value (e.g., transforming results, enriching data, performing a next step) - A real user would plausibly combine these tools in one request - It is NOT just rest...
-
[13]
fetch historical stock prices
Each intention should describe a CONCRETE tool action, e.g. "fetch historical stock prices", "geocode address to coordinates", "parse HTML table into structured data"
-
[14]
Include 1-2 intentions for IMPLICIT prerequisite or follow- up actions -- tools the user would ALSO need in the same workflow but didn't explicitly mention
-
[15]
A researcher wants to
Do NOT describe user scenarios or personas -- no "A researcher wants to..." or "planning a trip..."
-
[16]
Do NOT rephrase the tool description -- focus on WHAT DATA the tool operates on and HOW
-
[17]
ServerA__geocode
Keep each intention 4-8 words, starting with an action verb Output ONLY a JSON object mapping tool_key to intention array, no explanation. Example: {{"ServerA__geocode": ["resolve city names to GPS coordinates", "convert postal codes to lat/lng", " prepare locationinput forroute planning", "validate addressformatbefore geocoding"]}} Tools to analyze: {too...
1965
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.