CaVe-VLM-CoT: An Interpretable Vision-Language Model Framework
Pith reviewed 2026-06-27 00:28 UTC · model grok-4.3
The pith
CaVe-VLM-CoT enforces evidence-grounded reasoning in vision-language models through a five-stage closed-loop pipeline that routes verification failures back to targeted retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
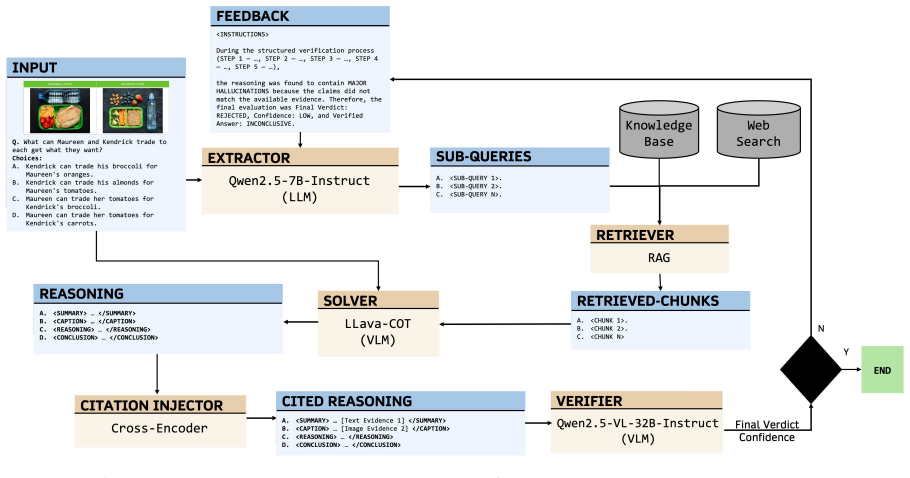
CaVe-VLM-CoT is a five-stage closed-loop pipeline consisting of Extractor, Retriever, Solver, Citation Injector, and Verifier; detected ungrounded claims trigger structured feedback to the Extractor for targeted re-retrieval, thereby enforcing evidence-grounded reasoning and step-wise citation faithfulness in vision-language models.
What carries the argument
The five-stage closed-loop pipeline (Extractor, Retriever, Solver, Citation Injector, Verifier) that detects ungrounded claims and routes targeted feedback for re-retrieval.
If this is right
- The pipeline produces higher accuracy together with higher citation precision, recall, and evidence-grounding scores on visual reasoning benchmarks.
- The 23 component-wise metrics allow separate diagnosis of retrieval quality, step-wise citation faithfulness, and cross-modal grounding failures.
- The approach requires no architectural or prompt changes to the base vision-language model.
- CaVeScore serves as a single composite metric that weights accuracy, citation precision and recall, attribution, and evidence grounding.
- The closed-loop design can be applied to existing models while preserving their original parameters.
Where Pith is reading between the lines
- The feedback mechanism could be tested on additional multimodal benchmarks beyond the two reported here to check consistency of the gains.
- If the Verifier proves reliable across domains, the same structure might reduce hallucinations in purely text-based language models.
- The explicit separation of the five stages makes it possible to replace any single stage with a stronger module while keeping the rest fixed.
- The emphasis on measurable citation faithfulness opens a path for human-in-the-loop evaluation protocols that score individual reasoning steps.
Load-bearing premise
The Verifier stage can reliably detect ungrounded claims and route feedback that produces measurably better retrieval without adding new errors or prohibitive latency.
What would settle it
Running the same benchmarks with the feedback loop from Verifier to Extractor disabled and observing whether accuracy and CaVeScore remain at the reported levels or drop.
Figures
read the original abstract
Vision-Language Models (VLMs) remain prone to hallucinations, producing fluent but visually unfaithful outputs. Existing chain-of-thought and retrieval-augmented methods only partially address this, as they neither enforce step-level citation grounding nor route verification failures back to retrieval for correction. We present CaVe-VLM-CoT, a modular reflection-based agentic-RAG framework that enforces evidence-grounded reasoning through a five-stage closed-loop pipeline: Extractor, Retriever, Solver, Citation Injector, and Verifier, in which detected ungrounded claims trigger structured feedback to the Extractor for targeted re-retrieval. Since no existing framework jointly measures retrieval quality, step-wise citation faithfulness, and cross-modal grounding, we propose a suite of 23 component-wise metrics across all stages, anchored by CaVeScore, a composite metric weighting accuracy, citation precision and recall, attribution, and evidence grounding. Without any architectural or prompt modifications, CaVe-VLM-CoT achieves 87.1\% accuracy and 56.6\% CaVeScore on ScienceQA , and 55.2\% accuracy and 35.7\% CaVeScore on MMMU (30 subjects).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents CaVe-VLM-CoT, a modular five-stage closed-loop agentic-RAG framework (Extractor, Retriever, Solver, Citation Injector, Verifier) for vision-language models that routes verification failures back to retrieval to enforce step-level citation grounding and reduce hallucinations. It introduces a suite of 23 component-wise metrics anchored by the composite CaVeScore (weighting accuracy, citation precision/recall, attribution, and evidence grounding) and reports 87.1% accuracy / 56.6% CaVeScore on ScienceQA and 55.2% accuracy / 35.7% CaVeScore on MMMU (30 subjects) with no architectural or prompt changes to the underlying VLM.
Significance. If the closed-loop feedback mechanism can be shown via ablations to deliver measurable grounding gains on independent metrics, the modular pipeline and multi-stage metric suite would represent a useful contribution to interpretable VLMs. The explicit separation of stages and proposal of component-wise metrics are strengths that facilitate future analysis.
major comments (3)
- [§3.3] §3.3 (CaVeScore definition): CaVeScore is defined as a weighted combination of accuracy, citation precision/recall, attribution, and evidence grounding; reporting primary results exclusively on this author-defined composite creates circularity risk because improvements may be artifacts of the weighting rather than independent evidence of better grounding.
- [§4] §4 (experimental protocol): The results section states the 87.1% / 56.6% and 55.2% / 35.7% figures but supplies no baseline comparisons (standard CoT, RAG, or other agentic methods), number of runs, statistical tests, or implementation details (base VLM, retrieval corpus, latency), preventing evaluation of whether the Verifier-to-Extractor feedback loop is responsible for the gains.
- [§3.4] §3.4 (Verifier stage): The claim that the Verifier reliably detects ungrounded claims and routes targeted feedback rests on the weakest assumption; without an ablation isolating the feedback loop (e.g., performance with vs. without Verifier) or error analysis of false positives/negatives in detection, the central premise that the closed-loop pipeline produces the reported improvements remains unsubstantiated.
minor comments (2)
- [Abstract] The abstract introduces '23 component-wise metrics' without enumeration or pointer to their definitions; adding a short table or reference would improve readability.
- [§3] Notation for the five stages is introduced in §3 but the feedback arrow from Verifier to Extractor is described only in prose; a diagram with explicit data-flow labels would clarify the closed-loop structure.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments, which highlight important aspects of our presentation and evaluation. We address each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.3] §3.3 (CaVeScore definition): CaVeScore is defined as a weighted combination of accuracy, citation precision/recall, attribution, and evidence grounding; reporting primary results exclusively on this author-defined composite creates circularity risk because improvements may be artifacts of the weighting rather than independent evidence of better grounding.
Authors: We note that the manuscript reports both accuracy (87.1% on ScienceQA and 55.2% on MMMU) and CaVeScore as primary results in the abstract and results section. Accuracy is an independent, standard metric not dependent on the weighting scheme. The CaVeScore is presented as a composite to capture multiple dimensions of interpretability and grounding. To address the concern, we will revise the text in §3.3 to explicitly state that accuracy is reported separately and provide the individual component scores for transparency. revision: partial
-
Referee: [§4] §4 (experimental protocol): The results section states the 87.1% / 56.6% and 55.2% / 35.7% figures but supplies no baseline comparisons (standard CoT, RAG, or other agentic methods), number of runs, statistical tests, or implementation details (base VLM, retrieval corpus, latency), preventing evaluation of whether the Verifier-to-Extractor feedback loop is responsible for the gains.
Authors: This is a valid observation; the current manuscript does not include these experimental details. We will revise §4 to incorporate baseline comparisons with standard CoT and RAG approaches, report results averaged over multiple runs with statistical measures, and provide implementation details including the base VLM used, the retrieval corpus, and latency information. This will allow better assessment of the framework's contributions. revision: yes
-
Referee: [§3.4] §3.4 (Verifier stage): The claim that the Verifier reliably detects ungrounded claims and routes targeted feedback rests on the weakest assumption; without an ablation isolating the feedback loop (e.g., performance with vs. without Verifier) or error analysis of false positives/negatives in detection, the central premise that the closed-loop pipeline produces the reported improvements remains unsubstantiated.
Authors: We agree that an ablation study isolating the Verifier's contribution would strengthen the claims. The manuscript describes the framework but lacks this analysis. We will add an ablation comparing the full closed-loop system to a version without the Verifier feedback, as well as an error analysis of the Verifier's detection performance, to provide evidence for the effectiveness of the closed-loop mechanism. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper introduces CaVe-VLM-CoT as a five-stage pipeline and defines CaVeScore as a new composite metric (accuracy + citation precision/recall + attribution + evidence grounding). It reports results using both this metric and standard accuracy on external benchmarks (ScienceQA, MMMU). No derivation step reduces by construction to its inputs: the pipeline stages are described procedurally without equations that equate outputs to fitted parameters or self-referential definitions. No self-citations are invoked as load-bearing uniqueness theorems. The evaluation uses independent accuracy numbers alongside the new metric, satisfying the criterion for self-contained claims against external benchmarks. No patterns from the enumerated list (self-definitional, fitted-input prediction, etc.) are exhibited with quotable reductions.
Axiom & Free-Parameter Ledger
free parameters (1)
- CaVeScore component weights
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE international conference on computer vision , pages=
Vqa: Visual question answering , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[2]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[3]
Advances in neural information processing systems , volume=
Instructblip: Towards general-purpose vision-language models with instruction tuning , author=. Advances in neural information processing systems , volume=
-
[4]
arXiv preprint arXiv:2303.08774 , year=
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[5]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Evaluating object hallucination in large vision-language models , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[6]
arXiv preprint arXiv:2404.18930 , year=
Hallucination of multimodal large language models: A survey , author=. arXiv preprint arXiv:2404.18930 , year=
-
[7]
Advances in Neural Information Processing Systems , volume=
Generate, but verify: Reducing hallucination in vision-language models with retrospective resampling , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
arXiv preprint arXiv:2508.00378 , year=
CoRGI: Verified Chain-of-Thought Reasoning with Post-hoc Visual Grounding , author=. arXiv preprint arXiv:2508.00378 , year=
-
[9]
Xu, Guowei and Jin, Peng and Wu, Ziang and Li, Hao and Song, Yibing and Sun, Lichao and Yuan, Li , booktitle=
-
[10]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Improve vision language model chain-of-thought reasoning , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[11]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Enabling large language models to generate text with citations , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[12]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Chain-of-thought improves text generation with citations in large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[13]
arXiv preprint arXiv:2501.04671 , year=
Retrieval-based interleaved visual chain-of-thought in real-world driving scenarios , author=. arXiv preprint arXiv:2501.04671 , year=
-
[14]
Multimodal Iterative
Choi, Changin and Lee, Wonseok and Ko, Jungmin and Rhee, Wonjong , journal=. Multimodal Iterative
-
[15]
Mohammadshirazi, Ali and Ghosh Neogi, Pratyay P and Kulshrestha, Divyanshu and Ramnath, Rahul , journal =
-
[16]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Xiong, Tianyi and Wang, Xiyao and Guo, Dong and Ye, Qinghao and Fan, Haoqi and Gu, Quanquan and Huang, Heng and Li, Chunyuan , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2025 , pages =
2025
-
[17]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Prometheus-vision: Vision-language model as a judge for fine-grained evaluation , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[18]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[19]
Marino, Kenneth and Rastegari, Mohammad and Farhadi, Ali and Mottaghi, Roozbeh , booktitle =
-
[20]
Information Processing & Management , volume =
Retriever-Generator-Verification: A Novel Approach to Enhancing Factual Coherence in Open-Domain Question Answering , author =. Information Processing & Management , volume =
-
[21]
arXiv preprint arXiv:2310.02567 , year =
Automatic Evaluation of Attribution by Large Language Models , author =. arXiv preprint arXiv:2310.02567 , year =
-
[22]
Wang, Junyang and Wang, Yuhang and Xu, Guohai and Zhang, Jing and Gu, Yukai and Jia, Haitao and Wang, Jiaqi and Xu, Haiyang and Yan, Ming and Zhang, Ji and others , journal =
-
[23]
Lee, Tony and Tu, Haoqin and Wong, Chi Heem and Zheng, Wenhao and Zhou, Yiyang and Mai, Yifan and Roberts, Josselin Somerville and Yasunaga, Michihiro and Yao, Huaxiu and Xie, Cihang and Liang, Percy , journal=
-
[24]
Zhang, Tianyi and Kishore, Varsha and Wu, Felix and Weinberger, Kilian Q and Artzi, Yoav , journal =
-
[25]
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing , booktitle =
-
[26]
Lin, Chin-Yew , booktitle =
-
[27]
Proceedings of the 11th International Workshop on Vietnamese Language and Speech Processing , pages =
A Hybrid Dual-Branch Retrieval and Chain-of-Thought Reasoning Framework for Multimodal Legal Question Answering , author =. Proceedings of the 11th International Workshop on Vietnamese Language and Speech Processing , pages =
-
[28]
Zhang, Di and Lei, Jingdi and Li, Junxian and Wang, Xunzhi and Liu, Yujie and Yang, Zonglin and Li, Jiatong and Wang, Weida and Yang, Suorong and Wu, Jianbo and others , booktitle=
-
[29]
Retrieval-Augmented Generation for Knowledge-Intensive
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K\". Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[30]
Li, Junnan and Li, Dongxu and Xiong, Caiming and Hoi, Steven , booktitle =
-
[31]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[32]
and Clarke, Charles L
Cormack, Gordon V. and Clarke, Charles L. A. and Buettcher, Stefan , title =. Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval , series =. 2009 , publisher =
2009
-
[33]
Proceedings of the European Conference on Computer Vision (ECCV) , year =
Liu, Shilong and Zeng, Zhaoyang and Ren, Tianhe and Li, Feng and Zhang, Hao and Yang, Jie and Li, Chunyuan and Yang, Jianwei and Su, Hang and Zhu, Jun and Zhang, Lei , title =. Proceedings of the European Conference on Computer Vision (ECCV) , year =
-
[34]
IEEE transactions on big data , volume=
Billion-scale similarity search with GPUs , author=. IEEE transactions on big data , volume=. 2019 , publisher=
2019
-
[35]
Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
Reimers, Nils and Gurevych, Iryna , title =. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =. 2019 , publisher =
2019
-
[36]
Proceedings of the 12th International Conference on Learning Representations (ICLR) , year =
Asai, Akari and Wu, Zeqiu and Wang, Yizhong and Sil, Avirup and Hajishirzi, Hannaneh , title =. Proceedings of the 12th International Conference on Learning Representations (ICLR) , year =
-
[37]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
Object Hallucination in Image Captioning , author =. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
2018
-
[38]
Xiang Yue and Yuansheng Ni and Kai Zhang and Tianyu Zheng and Ruoqi Liu and Ge Zhang and Samuel Stevens and Dongfu Jiang and Weiming Ren and Yuxuan Sun and Cong Wei and Botao Yu and Ruibin Yuan and Renliang Sun and Ming Yin and Boyuan Zheng and Zhenzhu Yang and Yibo Liu and Wenhao Huang and Huan Sun and Yu Su and Wenhu Chen , booktitle =
-
[39]
Some simple effective approximations to the 2-poisson model for probabilistic weighted retrieval , author=. SIGIR’94: Proceedings of the Seventeenth Annual International ACM-SIGIR Conference on Research and Development in Information Retrieval, organised by Dublin City University , pages=. 1994 , organization=
1994
-
[40]
IEEE Transactions on Big Data , year=
The Faiss library , author=. IEEE Transactions on Big Data , year=
-
[41]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Reflexion: Language Agents with Verbal Reinforcement Learning , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[42]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Factscore: Fine-grained atomic evaluation of factual precision in long form text generation , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[43]
arXiv preprint arXiv:2412.15115 , year =
Qwen2.5 Technical Report , author =. arXiv preprint arXiv:2412.15115 , year =
-
[44]
arXiv preprint arXiv:2502.13923 , year =
Qwen2.5-VL Technical Report , author =. arXiv preprint arXiv:2502.13923 , year =
-
[45]
Pengcheng He and Jianfeng Gao and Weizhu Chen , booktitle=. De. 2023 , url=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.