Focusing on What Matters: Saliency-Harnessing Accurate Routing for Diffusion MoE
Pith reviewed 2026-06-26 05:10 UTC · model grok-4.3
The pith
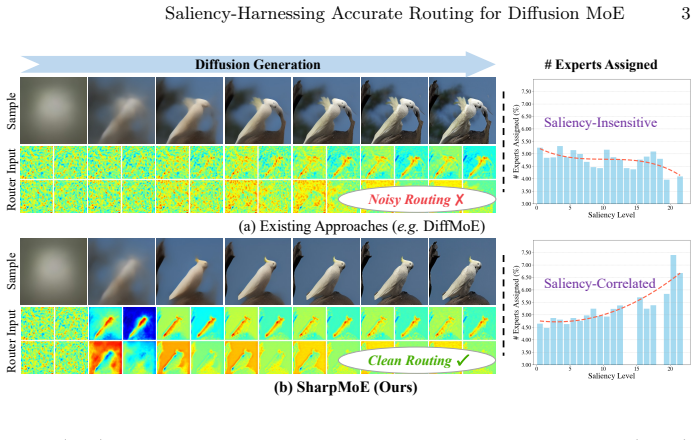
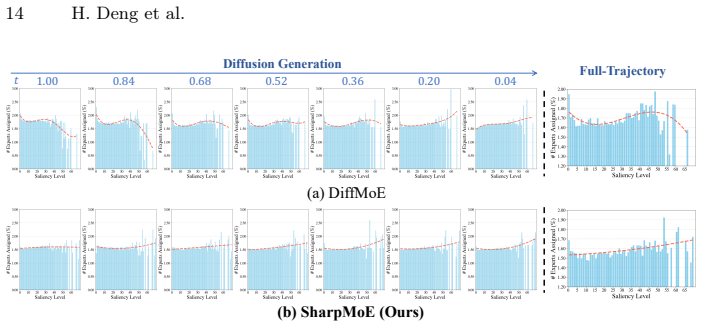
Diffusion MoE routers fail to prioritize salient tokens because noise corrupts their input features throughout denoising.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
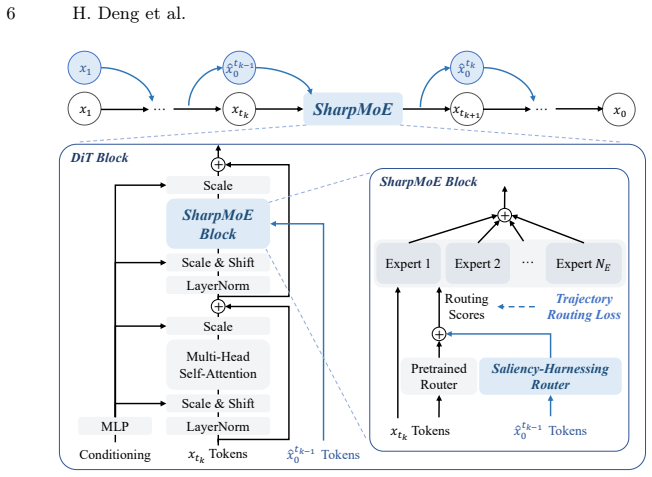
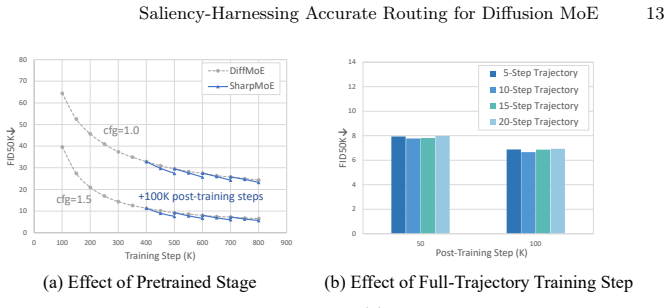
By supplying the router with clean latent features as noise-free saliency guidance and constraining allocation with a trajectory routing loss, SharpMoE enables accurate identification of salient tokens and precise compute distribution along the full multi-step denoising trajectory.
What carries the argument
Saliency-harnessing accurate routing mechanism that routes on clean latent features rather than noise-corrupted inputs.
If this is right
- Routers can now allocate more experts to salient tokens even in the earliest, noisiest denoising steps.
- Compute budgets stay consistent along the entire generation trajectory rather than fluctuating with noise level.
- Pretrained and converged diffusion MoE models gain performance as a drop-in post-training step.
- The same clean-feature guidance can be applied to other token-adaptive MoE diffusion architectures.
Where Pith is reading between the lines
- The same clean-reference idea could be tested on non-diffusion generative models that also suffer from noisy intermediate states.
- If clean features prove cheap to approximate, the method might lower total FLOPs by letting weaker experts handle background tokens earlier.
- Future router training loops could be redesigned to treat clean latents as an auxiliary training signal rather than an inference-only trick.
Load-bearing premise
Clean latent features can be obtained or approximated during inference to give the router reliable saliency information without adding substantial computation or new errors.
What would settle it
A controlled test that measures router accuracy on high-noise inputs and shows no improvement when clean features are substituted for noisy ones would falsify the claim.
Figures

read the original abstract
Mixture-of-Experts (MoE) architectures have emerged as a powerful paradigm for scaling diffusion models in visual generation. Recent advancements have focused on adaptively allocating computational resources across diverse tokens to improve efficiency and performance. However, we identify a routing assignment problem in existing diffusion MoE frameworks: the router fails to accurately allocate more computational resources to salient tokens. Our analysis attributes this failure to the router's reliance on noise-corrupted latent features throughout the denoising process. Such stochastic noise obscures the critical structural and textural information, thereby preventing the router from effectively distinguishing salient tokens. To address this, we propose SharpMoE, a post-training framework with a saliency-harnessing accurate routing mechanism, which utilizes clean latent features as a noise-free guidance signal for routing. By bypassing the noise-distorted inputs, SharpMoE provides the router with clear saliency guidance, enabling the identification of salient tokens even in high-noise stages. Furthermore, we introduce a trajectory routing loss to constrain the compute allocation throughout the multi-step denoising trajectory, ensuring precise resource allocation along the generation rollout. Extensive experiments demonstrate that SharpMoE serves as a versatile, plug-and-play solution that further enhances the pretrained, converged MoE models, achieving state-of-the-art performance in visual generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript identifies a routing failure in diffusion MoE models, where noise-corrupted latent features prevent accurate allocation of compute to salient tokens. It proposes SharpMoE, a post-training framework that supplies the router with clean latent features as noise-free saliency guidance and adds a trajectory routing loss to enforce consistent resource allocation across the multi-step denoising process, claiming plug-and-play SOTA gains on pretrained models for visual generation.
Significance. If the core mechanism can be shown to work without hidden costs or new errors, the approach would supply a lightweight way to retrofit existing diffusion MoE architectures with better saliency-aware routing and trajectory-consistent allocation, which could improve efficiency-quality trade-offs in large-scale generative models.
major comments (2)
- [Method (abstract and §3)] The central claim rests on the router receiving clean latent features as reliable saliency guidance, yet the manuscript provides no description of how these features are obtained or approximated at inference (e.g., via extra forward pass, reuse of the current estimate, or auxiliary predictor). This omission is load-bearing for the 'plug-and-play' and 'no substantial extra computation' assertions.
- [§3.2 (trajectory routing loss)] The trajectory routing loss is introduced to constrain compute allocation along the denoising trajectory, but no formulation, weighting schedule, or interaction with the saliency signal is given; without these details it is impossible to verify that the loss actually enforces the claimed precise allocation rather than merely adding an auxiliary term.
minor comments (2)
- [Abstract and Experiments section] The abstract states that 'extensive experiments demonstrate' SOTA performance, yet no quantitative tables, baselines, or ablation numbers appear in the provided text; these must be added with explicit metrics and controls.
- [§3] Notation for the clean latent feature extraction and the routing loss should be introduced with explicit equations rather than prose descriptions alone.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The two major comments correctly identify areas where the manuscript lacks sufficient detail. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Method (abstract and §3)] The central claim rests on the router receiving clean latent features as reliable saliency guidance, yet the manuscript provides no description of how these features are obtained or approximated at inference (e.g., via extra forward pass, reuse of the current estimate, or auxiliary predictor). This omission is load-bearing for the 'plug-and-play' and 'no substantial extra computation' assertions.
Authors: We agree that the current manuscript does not describe the inference-time procedure for obtaining or approximating clean latent features. This is a substantive omission that weakens the plug-and-play and efficiency claims. In the revised version we will add an explicit description in §3 (including whether an auxiliary predictor, feature reuse, or additional forward pass is used) together with measured computational overhead. revision: yes
-
Referee: [§3.2 (trajectory routing loss)] The trajectory routing loss is introduced to constrain compute allocation along the denoising trajectory, but no formulation, weighting schedule, or interaction with the saliency signal is given; without these details it is impossible to verify that the loss actually enforces the claimed precise allocation rather than merely adding an auxiliary term.
Authors: The referee is correct; the manuscript omits the mathematical formulation, weighting schedule, and interaction details of the trajectory routing loss. We will expand §3.2 with the full loss equation, the schedule for the weighting hyper-parameter across denoising steps, and how the loss couples to the clean-feature saliency signal. revision: yes
Circularity Check
No significant circularity; new routing mechanism and loss are independent additions
full rationale
The paper proposes SharpMoE as a post-training framework that adds a saliency-harnessing routing mechanism (using clean latent features) and a trajectory routing loss. These are presented as novel components grafted onto pretrained MoE models. No equations or steps reduce by construction to fitted inputs, self-citations, or renamed known results. The derivation chain introduces external signals and constraints rather than re-deriving quantities from the original noisy inputs. This is self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diffusion models generate images via iterative denoising of latent features
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2211.01324 (2022)
Balaji, Y., Nah, S., Huang, X., Vahdat, A., Song, J., Zhang, Q., Kreis, K., Ait- tala, M., Aila, T., Laine, S., et al.: ediff-i: Text-to-image diffusion models with an ensemble of expert denoisers. arXiv preprint arXiv:2211.01324 (2022)
Pith/arXiv arXiv 2022
-
[2]
arXiv preprint arXiv:2509.23951 (2025)
Cao, S., Chen, H., Chen, P., Cheng, Y., Cui, Y., Deng, X., Dong, Y., Gong, K., Gu, T., Gu, X., et al.: Hunyuanimage 3.0 technical report. arXiv preprint arXiv:2509.23951 (2025)
Pith/arXiv arXiv 2025
-
[3]
arXiv preprint arXiv:2310.00426 (2023)
Chen, J., Yu, J., Ge, C., Yao, L., Xie, E., Wu, Y., Wang, Z., Kwok, J., Luo, P., Lu, H., et al.: Pixart-α: Fast training of diffusion transformer for photorealistic text-to-image synthesis. arXiv preprint arXiv:2310.00426 (2023)
Pith/arXiv arXiv 2023
-
[4]
arXiv preprint arXiv:2401.06066 (2024)
Dai, D., Deng, C., Zhao, C., Xu, R., Gao, H., Chen, D., Li, J., Zeng, W., Yu, X., Wu, Y., et al.: Deepseekmoe: Towards ultimate expert specialization in mixture- of-experts language models. arXiv preprint arXiv:2401.06066 (2024)
Pith/arXiv arXiv 2024
-
[5]
arXiv preprint arXiv:2601.20218 (2026)
Deng, H., Yan, K., Mao, C., Wang, X., Liu, Y., Gao, C., Sang, N.: Densegrpo: From sparse to dense reward for flow matching model alignment. arXiv preprint arXiv:2601.20218 (2026)
arXiv 2026
-
[6]
In: CVPR
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. In: CVPR. pp. 248–255. Ieee (2009) 16 H. Deng et al
2009
-
[7]
NeurIPS 34, 8780–8794 (2021)
Dhariwal, P., Nichol, A.: Diffusion models beat gans on image synthesis. NeurIPS 34, 8780–8794 (2021)
2021
-
[8]
In: ICML (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: ICML (2024)
2024
-
[9]
arXiv preprint arXiv:2407.11633 (2024)
Fei, Z., Fan, M., Yu, C., Li, D., Huang, J.: Scaling diffusion transformers to 16 billion parameters. arXiv preprint arXiv:2407.11633 (2024)
arXiv 2024
-
[10]
In: ECCV
Hatamizadeh, A., Song, J., Liu, G., Kautz, J., Vahdat, A.: Diffit: Diffusion vision transformers for image generation. In: ECCV. pp. 37–55. Springer (2024)
2024
-
[11]
NeurIPS30 (2017)
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. NeurIPS30 (2017)
2017
-
[12]
NeurIPS33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. NeurIPS33, 6840–6851 (2020)
2020
-
[13]
arXiv preprint arXiv:2207.12598 (2022)
Ho, J., Salimans, T.: Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598 (2022)
Pith/arXiv arXiv 2022
-
[14]
Neural computation3(1), 79–87 (1991)
Jacobs, R.A., Jordan, M.I., Nowlan, S.J., Hinton, G.E.: Adaptive mixtures of local experts. Neural computation3(1), 79–87 (1991)
1991
-
[15]
arXiv preprint arXiv:2006.16668 (2020)
Lepikhin, D., Lee, H., Xu, Y., Chen, D., Firat, O., Huang, Y., Krikun, M., Shazeer, N., Chen, Z.: Gshard: Scaling giant models with conditional computation and automatic sharding. arXiv preprint arXiv:2006.16668 (2020)
Pith/arXiv arXiv 2006
-
[16]
arXiv preprint arXiv:2501.08313 (2025)
Li, A., Gong, B., Yang, B., Shan, B., Liu, C., Zhu, C., Zhang, C., Guo, C., Chen, D., Li, D., et al.: Minimax-01: Scaling foundation models with lightning attention. arXiv preprint arXiv:2501.08313 (2025)
Pith/arXiv arXiv 2025
-
[17]
arXiv preprint arXiv:2210.02747 (2022)
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022)
Pith/arXiv arXiv 2022
-
[18]
arXiv preprint arXiv:2412.19437 (2024)
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al.: Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437 (2024)
Pith/arXiv arXiv 2024
-
[19]
arXiv preprint arXiv:2209.03003 (2022)
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003 (2022)
Pith/arXiv arXiv 2022
-
[20]
In: ECCV
Ma, N., Goldstein, M., Albergo, M.S., Boffi, N.M., Vanden-Eijnden, E., Xie, S.: Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers. In: ECCV. pp. 23–40. Springer (2024)
2024
-
[21]
arXiv preprint arXiv:2604.19858 (2026)
Mao, C., Xie, C.W., Zhong, C., Deng, H., Zhao, J., Xiao, J., Xing, J., Zhang, J., Zhou, J., Zhang, J., et al.: Wan-image: Pushing the boundaries of generative visual intelligence. arXiv preprint arXiv:2604.19858 (2026)
Pith/arXiv arXiv 2026
-
[22]
In: ICCV
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: ICCV. pp. 4195–4205 (2023)
2023
-
[23]
arXiv preprint arXiv:2307.01952 (2023)
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952 (2023)
Pith/arXiv arXiv 2023
-
[24]
In: CVPR
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: CVPR. pp. 10684–10695 (2022)
2022
-
[25]
In: MICCAI
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomed- ical image segmentation. In: MICCAI. pp. 234–241. Springer (2015)
2015
-
[26]
NeurIPS29(2016)
Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., Chen, X.: Improved techniques for training gans. NeurIPS29(2016)
2016
-
[27]
arXiv preprint arXiv:2509.20427 (2025) Saliency-Harnessing Accurate Routing for Diffusion MoE 17
Seedream, T., Chen, Y., Gao, Y., Gong, L., Guo, M., Guo, Q., Guo, Z., Hou, X., Huang, W., Huang, Y., et al.: Seedream 4.0: Toward next-generation multimodal image generation. arXiv preprint arXiv:2509.20427 (2025) Saliency-Harnessing Accurate Routing for Diffusion MoE 17
Pith/arXiv arXiv 2025
-
[28]
arXiv preprint arXiv:1701.06538 (2017)
Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., Dean, J.: Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538 (2017)
Pith/arXiv arXiv 2017
-
[29]
arXiv preprint arXiv:2503.14487 (2025)
Shi, M., Yuan, Z., Yang, H., Wang, X., Zheng, M., Tao, X., Zhao, W., Zheng, W., Zhou, J., Lu, J., et al.: Diffmoe: Dynamic token selection for scalable diffusion transformers. arXiv preprint arXiv:2503.14487 (2025)
arXiv 2025
-
[30]
arXiv preprint arXiv:2011.13456 (2020)
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456 (2020)
Pith/arXiv arXiv 2011
-
[31]
arXiv preprint arXiv:2410.02098 (2024)
Sun, H., Lei, T., Zhang, B., Li, Y., Huang, H., Pang, R., Dai, B., Du, N.: Ec-dit: Scaling diffusion transformers with adaptive expert-choice routing. arXiv preprint arXiv:2410.02098 (2024)
arXiv 2024
-
[32]
arXiv preprint arXiv:2503.20314 (2025)
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
Pith/arXiv arXiv 2025
-
[33]
arXiv preprint arXiv:2408.15664 (2024)
Wang, L., Gao, H., Zhao, C., Sun, X., Dai, D.: Auxiliary-loss-free load balancing strategy for mixture-of-experts. arXiv preprint arXiv:2408.15664 (2024)
Pith/arXiv arXiv 2024
-
[34]
arXiv preprint arXiv:2511.20520 (2025)
Wang, X., Zhang, Z., Zhang, H., Lin, Z., Zhou, Y., Liu, Q., Zhang, S., Li, Y., Liu, S., Zheng, H., et al.: Hbridge: H-shape bridging of heterogeneous experts for unified multimodal understanding and generation. arXiv preprint arXiv:2511.20520 (2025)
arXiv 2025
-
[35]
arXiv preprint arXiv:2412.14711 (2024)
Wang, Z., Zhu, J., Chen, J.: Remoe: Fully differentiable mixture-of-experts with relu routing. arXiv preprint arXiv:2412.14711 (2024)
arXiv 2024
-
[36]
In: CVPR
Wei, Y., Zhang, S., Qing, Z., Yuan, H., Liu, Z., Liu, Y., Zhang, Y., Zhou, J., Shan, H.: Dreamvideo: Composing your dream videos with customized subject and motion. In: CVPR. pp. 6537–6549 (2024)
2024
-
[37]
arXiv preprint arXiv:2510.24711 (2025)
Wei, Y., Zhang, S., Yuan, H., Han, Y., Chen, Z., Wang, J., Zou, D., Liu, X., Zhang, Y., Liu, Y., et al.: Routing matters in moe: Scaling diffusion transformers with explicit routing guidance. arXiv preprint arXiv:2510.24711 (2025)
arXiv 2025
-
[38]
arXiv preprint arXiv:2508.02324 (2025)
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.m., Bai, S., Xu, X., Chen, Y., et al.: Qwen-image technical report. arXiv preprint arXiv:2508.02324 (2025)
Pith/arXiv arXiv 2025
-
[39]
NeurIPS36, 41693–41706 (2023)
Xue, Z., Song, G., Guo, Q., Liu, B., Zong, Z., Liu, Y., Luo, P.: Raphael: Text-to- image generation via large mixture of diffusion paths. NeurIPS36, 41693–41706 (2023)
2023
-
[40]
arXiv preprint arXiv:2503.16057 (2025)
Yuan, Y., Wang, Z., Huang, Z., Zhu, D., Zhou, X., Yu, J., Min, Q.: Expert race: A flexible routing strategy for scaling diffusion transformer with mixture of experts. arXiv preprint arXiv:2503.16057 (2025)
arXiv 2025
-
[41]
arXiv preprint arXiv:2410.03456 (2024)
Zhao, W., Han, Y., Tang, J., Wang, K., Song, Y., Huang, G., Wang, F., You, Y.: Dynamic diffusion transformer. arXiv preprint arXiv:2410.03456 (2024)
arXiv 2024
-
[42]
NeurIPS35, 7103–7114 (2022)
Zhou, Y., Lei, T., Liu, H., Du, N., Huang, Y., Zhao, V., Dai, A.M., Le, Q.V., Laudon, J., et al.: Mixture-of-experts with expert choice routing. NeurIPS35, 7103–7114 (2022)
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.