Augmenting Dysarthric Speech Severity Assessment with MOS Supervision
Pith reviewed 2026-06-26 19:57 UTC · model grok-4.3
The pith
Models for assessing dysarthric speech improve when trained with MOS labels from speech synthesis data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
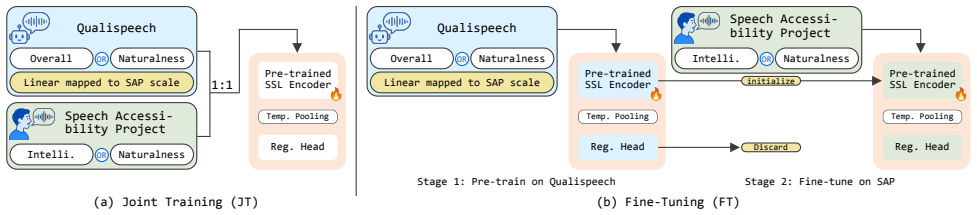
Core claim
Augmenting training with human-annotated MOS from the QualiSpeech speech synthesis corpus improves utterance-level prediction of intelligibility and naturalness in dysarthric speech, with fine-tuning providing consistent gains on both metrics and joint training mainly on naturalness.
What carries the argument
Transfer of MOS supervision from synthesis assessment data to dysarthric speech models via fine-tuning or joint training.
If this is right
- Fine-tuning on synthesis assessment data produces consistent gains on both intelligibility and naturalness prediction.
- Joint training with synthesis data yields gains primarily on naturalness prediction.
- Synthesis artifacts and dysarthric speech share perceptual commonalities that support the transfer.
- Speech synthesis evaluation corpora can reduce reliance on scarce clinical annotations for model training.
Where Pith is reading between the lines
- The same augmentation strategy could apply to assessment of other speech disorders if similar perceptual overlaps hold.
- Public synthesis datasets might enable scalable assessment tools in settings with limited clinical data collection.
- Direct comparisons of listener ratings across synthetic and dysarthric stimuli could quantify the degree of shared perceptual dimensions.
Load-bearing premise
That perceptual commonalities between synthesis artifacts and dysarthric speech exist and are sufficient for effective transfer of MOS supervision to clinical assessment tasks.
What would settle it
An experiment showing no improvement or degradation in dysarthric speech prediction performance after fine-tuning on QualiSpeech MOS data would falsify the transfer benefit.
Figures

read the original abstract
Dysarthria is a speech disorder marked by reduced intelligibility and communicative effectiveness. Automatic utterance-level assessment of dysarthric speech can support scalable speech monitoring and therapy-related analysis. Yet training such systems is bottlenecked by the scarcity of clinically annotated dysarthric speech. This work proposes to augment dysarthric speech assessment using data from speech synthesis evaluations, specifically human-annotated utterances with Mean Opinion Score (MOS) labels from the QualiSpeech corpus. Experiments show that fine-tuning on speech synthesis assessment data consistently improves performance on both intelligibility and naturalness prediction, while joint training yields gains primarily on naturalness. These results suggest that synthesis artifacts and dysarthric speech share perceptual commonalities, and speech synthesis evaluation corpora offer a practical augmentation source that reduces reliance on scarce clinical annotations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes augmenting scarce clinically annotated dysarthric speech data for automatic utterance-level severity assessment by incorporating MOS labels from the QualiSpeech speech synthesis evaluation corpus. It reports that fine-tuning on synthesis MOS data improves both intelligibility and naturalness prediction, while joint training yields gains mainly on naturalness, attributing this to shared perceptual commonalities between synthesis artifacts and dysarthric speech.
Significance. If the claimed transfer effects hold under controlled conditions, the approach could reduce dependence on limited clinical annotations by repurposing existing synthesis evaluation datasets, supporting more scalable tools for dysarthria monitoring and therapy analysis.
major comments (1)
- [Abstract] Abstract: The central claim of consistent performance gains from fine-tuning on QualiSpeech MOS data (and differential effects from joint training) is presented without any supporting experimental details, including dataset sizes, model architectures, baseline systems, ablation controls for data volume, or statistical tests. This absence makes it impossible to determine whether observed improvements (if any) arise from the hypothesized perceptual overlap rather than generic effects of additional training utterances.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in the abstract. We address the comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of consistent performance gains from fine-tuning on QualiSpeech MOS data (and differential effects from joint training) is presented without any supporting experimental details, including dataset sizes, model architectures, baseline systems, ablation controls for data volume, or statistical tests. This absence makes it impossible to determine whether observed improvements (if any) arise from the hypothesized perceptual overlap rather than generic effects of additional training utterances.
Authors: The abstract is intentionally concise and summarizes results whose full details appear in Sections 3 and 4 of the manuscript (QualiSpeech: 5,000+ utterances; dysarthric corpora: TORGO and UASpeech; architecture: fine-tuned wav2vec 2.0 with linear head; baselines: from-scratch training and data-volume-matched controls; significance: paired t-tests with p<0.01). We agree that the abstract would benefit from a brief mention of these elements to allow immediate evaluation of the transfer claim. We will therefore revise the abstract to include approximate dataset sizes, the model family, and the reported relative gains, while preserving its length constraints. revision: yes
Circularity Check
No significant circularity; empirical claims rest on reported experiments
full rationale
The paper describes an empirical transfer-learning setup: fine-tuning or joint training on QualiSpeech MOS data to improve intelligibility/naturalness prediction for dysarthric speech. No equations, parameter-fitting steps, self-definitional relations, or load-bearing self-citations appear in the abstract or described claims. The central assertion (shared perceptual commonalities enable augmentation) is presented as an interpretation of experimental outcomes rather than a quantity derived by construction from the same inputs. Results are externally falsifiable via replication on held-out data, satisfying the criterion for non-circular empirical work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthesis artifacts and dysarthric speech share perceptual commonalities that enable effective MOS transfer
Reference graph
Works this paper leans on
-
[1]
Introduction Dysarthria is a neuro-motor speech disorder resulting from neurological injuries or diseases, such as cerebral palsy, amy- otrophic lateral sclerosis, Parkinson’s disease, or stroke [1, 2]. These disruptions manifest in several perceptually salient char- acteristics, with reduced intelligibility and degraded naturalness being among the most p...
-
[2]
and HuBERT [19, 20] have been successfully applied to both detection and severity assessment of dysarthria [21, 22]. A wide spectrum of data augmentation techniques has also been explored, including signal processing [23], adversarial domain adaptation [24], generative approaches [25, 26, 27], reverse au- toencoders that transform healthy speech into dysa...
Pith/arXiv arXiv 2026
-
[3]
Task Description 2.1. The Speech Accessibility Project Challenge 2025 1 2 3 4 5 6 7 Severity Level 0 1000 2000 3000 4000# utterances (a)Intelligibility 1 2 3 4 5 6 7 Severity Level 0 250 500 750 1000 1250 1500 1750 2000# utterances (b)Naturalness Figure 1:Distribution of utterances across severity levels for (a)Intelligibility and(b)Naturalness in the Spe...
2025
-
[4]
and various TTS models with standardized MOS scores; simulated real speech (27%), sourced from the Non-Intrusive Speech Quality Assessment (NISQA) corpus [43] featuring distortions that emulate actual transmission; and real speech (24%), encompassing NISQA live recordings and in-the-wild samples from GigaSpeech [44]. To ensure balanced speech quality cond...
-
[5]
Method 3.1. Model Architecture To leverage transferable representations from large-scale un- labeled speech, self-supervised learning (SSL) pre-trained en- coders are adopted as the backbone for feature extraction [46]. The core idea is to augment the limited in-domain dysarthric speech data with human-annotated TTS assessment data from QualiSpeech, using...
-
[6]
Experiments and Results To leverage human-perception-aligned supervision from Qual- iSpeech for dysarthria assessment, we evaluate two TTS-based data augmentation paradigms: joint training (JT) and fine- tuning (FT). All models evaluated are optimized using the Adam optimizer with mean squared error (MSE) as the train- ing objective, a learning rate of1e−...
-
[7]
Fine-tuning consistently improved pre- diction accuracy over the baseline on both dimensions, while joint training yielded gains primarily on naturalness
Conclusion This study demonstrated that leveraging perceptual annotations from the QualiSpeech corpus significantly enhances automatic dysarthria assessment. Fine-tuning consistently improved pre- diction accuracy over the baseline on both dimensions, while joint training yielded gains primarily on naturalness. Larger models derived greater benefit from a...
-
[8]
Illus- trative icons in Figure 2 are AI generated
Generative AI Use Disclosure During the preparation of this manuscript, the authors used gen- erative AI to correct grammar mistakes and misspellings. Illus- trative icons in Figure 2 are AI generated. After using these tools, the authors carefully reviewed and edited the manuscript, and take full responsibility for the final content of the paper
-
[9]
Articulatory Knowledge in the Recognition of Dysarthric Speech,
F. Rudzicz, “Articulatory Knowledge in the Recognition of Dysarthric Speech,”IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 4, pp. 947–960, 2011
2011
-
[10]
Phonological Features in Discriminative Classification of Dysarthric Speech,
——, “Phonological Features in Discriminative Classification of Dysarthric Speech,” inProc. IEEE ICASSP, Taipei, 2009
2009
-
[11]
End-to- end Speech Recognition Using Lattice-free MMI,
H. Hadian, H. Sameti, D. Povey, and S. Khudanpur, “End-to- end Speech Recognition Using Lattice-free MMI,” inProc. In- terspeech, Hyderabad, 2018
2018
-
[12]
Conformer: Convolution-augmented Transformer for Speech Recognition,
A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y . Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y . Wu, and R. Pang, “Conformer: Convolution-augmented Transformer for Speech Recognition,” in Proc. Interspeech, Shanghai, 2020
2020
-
[13]
Zipformer: A faster and better encoder for automatic speech recognition,
Z. Yao, L. Guo, X. Yang, W. Kang, F. Kuang, Y . Yang, Z. Jin, L. Lin, and D. Povey, “Zipformer: A faster and better encoder for automatic speech recognition,” inProc. ICLR, Vienna, 2024
2024
-
[14]
CR-CTC: Consistency regularization on CTC for improved speech recognition,
Z. Yao, W. Kang, X. Yang, F. Kuang, L. Guo, H. Zhu, Z. Jin, Z. Li, L. Lin, and D. Povey, “CR-CTC: Consistency regularization on CTC for improved speech recognition,” inProc. ICLR, Singapore, 2025
2025
-
[15]
Personalized Adversarial Data Augmentation for Dysarthric and Elderly Speech Recognition,
Z. Jin, M. Geng, J. Deng, T. Wang, S. Hu, G. Li, and X. Liu, “Personalized Adversarial Data Augmentation for Dysarthric and Elderly Speech Recognition,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 413–429, 2023
2023
-
[16]
Hyper-parameter Adaptation of Conformer ASR Systems for Elderly and Dysarthric Speech Recognition,
T. Wang, S. Hu, J. Deng, Z. Jin, M. Geng, Y . Wang, H. Meng, and X. Liu, “Hyper-parameter Adaptation of Conformer ASR Systems for Elderly and Dysarthric Speech Recognition,” inProc. Inter- speech, Dublin, 2023
2023
-
[17]
Enhancing Pre-Trained ASR System Fine-Tuning for Dysarthric Speech Recognition Using Adversarial Data Augmen- tation,
H. Wang, Z. Jin, M. Geng, S. Hu, G. Li, T. Wang, H. Xu, and X. Liu, “Enhancing Pre-Trained ASR System Fine-Tuning for Dysarthric Speech Recognition Using Adversarial Data Augmen- tation,” inProc. IEEE ICASSP, Seoul, 2024
2024
-
[18]
Exploring the Role of Fricatives in Classifying Healthy Subjects and Patients with Amyotrophic Lateral Sclerosis and Parkinson’s Disease,
T. Bhattacharjee, Y . Belur, A. Nalini, R. Yadav, and P. K. Ghosh, “Exploring the Role of Fricatives in Classifying Healthy Subjects and Patients with Amyotrophic Lateral Sclerosis and Parkinson’s Disease,” inProc. IEEE ICASSP, Rhodes Island, 2023
2023
-
[19]
Automatic Assess- ment of Dysarthria Severity Level Using Audio Descriptors,
C. Bhat, B. Vachhani, and S. K. Kopparapu, “Automatic Assess- ment of Dysarthria Severity Level Using Audio Descriptors,” in Proc. IEEE ICASSP, New Orleans, 2017
2017
-
[20]
Use of Speech Impairment Severity for Dysarthric Speech Recognition,
M. Geng, Z. Jin, T. Wang, S. Hu, J. Deng, M. Cui, G. Li, J. Yu, X. Xie, and X. Liu, “Use of Speech Impairment Severity for Dysarthric Speech Recognition,” inProc. Interspeech, Dublin, 2023
2023
-
[21]
Facilitating Personalized TTS for Dysarthric Speakers Using Knowledge Anchoring and Curriculum Learning,
Y . Jeon, S. Im, Y . Kim, and G. G. Lee, “Facilitating Personalized TTS for Dysarthric Speakers Using Knowledge Anchoring and Curriculum Learning,” inProc. Interspeech, Rotterdam, 2025
2025
-
[22]
Exploiting Audio-Visual Features with Pretrained A V-HuBERT for Multi-Modal Dysarthric Speech Reconstruction,
X. Chen, Y . Wang, X. Wu, D. Wang, Z. Wu, X. Liu, and H. Meng, “Exploiting Audio-Visual Features with Pretrained A V-HuBERT for Multi-Modal Dysarthric Speech Reconstruction,” inProc. IEEE ICASSP, Seoul, 2024
2024
-
[23]
UNIT- DSR: Dysarthric Speech Reconstruction System Using Speech Unit Normalization,
Y . Wang, X. Wu, D. Wang, L. Meng, and H. Meng, “UNIT- DSR: Dysarthric Speech Reconstruction System Using Speech Unit Normalization,” inProc. IEEE ICASSP, Seoul, 2024
2024
-
[24]
The TORGO database of acoustic and articulatory speech from speakers with dysarthria,
F. Rudzicz, A. K. Namasivayam, and T. Wolff, “The TORGO database of acoustic and articulatory speech from speakers with dysarthria,”Lang. Resour. Eval., vol. 46, no. 4, pp. 523–541, 2012
2012
-
[25]
Dysarthric Speech Database for Universal Access Research,
H. Kim, M. Hasegawa-Johnson, A. Perlman, J. R. Gunderson, T. S. Huang, K. L. Watkin, S. Frameet al., “Dysarthric Speech Database for Universal Access Research,” inProc. Interspeech, Brisbane, 2008
2008
-
[26]
wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Represen- tations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Represen- tations,” inProc. NeurIPS, virtual, 2020
2020
-
[27]
HuBERT: Self-Supervised Speech Rep- resentation Learning by Masked Prediction of Hidden Units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhutdi- nov, and A. Mohamed, “HuBERT: Self-Supervised Speech Rep- resentation Learning by Masked Prediction of Hidden Units,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 29, pp. 3451–3460, 10 2021
2021
-
[28]
k2SSL: A Faster and Better Framework for Self-Supervised Speech Representation Learning,
Y . Yang, J. Zhuo, Z. Jin, Z. Ma, X. Yang, Z. Yao, L. Guo, W. Kang, F. Kuang, L. Linet al., “k2SSL: A Faster and Better Framework for Self-Supervised Speech Representation Learning,” inProc. IEEE ICME, Nantes, 2025
2025
-
[29]
Automatic Sever- ity Classification of Dysarthric Speech by Using Self-Supervised Model with Multi-Task Learning,
E. J. Yeo, K. Choi, S. Kim, and M. Chung, “Automatic Sever- ity Classification of Dysarthric Speech by Using Self-Supervised Model with Multi-Task Learning,” inProc. IEEE ICASSP, Rhodes Island, 2023
2023
-
[30]
Wav2vec-Based Detection and Severity Level Classification of Dysarthria From Speech,
F. Javanmardi, S. Tirronen, M. Kodali, S. R. Kadiri, and P. Alku, “Wav2vec-Based Detection and Severity Level Classification of Dysarthria From Speech,” inProc. IEEE ICASSP, Rhodes Island, 2023
2023
-
[31]
Investigation of Data Augmentation Techniques for Disordered Speech Recognition,
M. Geng, X. Xie, S. Liu, J. Yu, S. Hu, X. Liu, and H. Meng, “Investigation of Data Augmentation Techniques for Disordered Speech Recognition,” inProc. Interspeech, Shanghai, 2020
2020
-
[32]
Multilingual Speaker- Invariant Dysarthria Severity Assessment Using Adversarial Do- main Adaptation and Self-Supervised Learning,
L. Stumpf, B. Kadirvelu, and A. A. Faisal, “Multilingual Speaker- Invariant Dysarthria Severity Assessment Using Adversarial Do- main Adaptation and Self-Supervised Learning,” inProc. IEEE ICASSP, Hyderabad, 2025
2025
-
[33]
DuTa-VC: A Duration-aware Typical-to-atypical V oice Conversion Approach with Diffusion Probabilistic Model,
H. Wang, T. Thebaud, J. Villalba, M. Sydnor, B. Lammers, N. Dehak, and L. Moro-Velazquez, “DuTa-VC: A Duration-aware Typical-to-atypical V oice Conversion Approach with Diffusion Probabilistic Model,” inProc. Interspeech, Dublin, 2023
2023
-
[34]
Adversarial Data Augmentation for Disordered Speech Recogni- tion,
Z. Jin, M. Geng, X. Xie, J. Yu, S. Liu, X. Liu, and H. Meng, “Adversarial Data Augmentation for Disordered Speech Recogni- tion,” inProc. Interspeech, Brno, 2021
2021
-
[35]
Adversarial Data Augmentation Using V AE-GAN for Disordered Speech Recognition,
Z. Jin, X. Xie, M. Geng, T. Wang, S. Hu, J. Deng, G. Li, and X. Liu, “Adversarial Data Augmentation Using V AE-GAN for Disordered Speech Recognition,” inProc. IEEE ICASSP, Rhodes Island, 2023
2023
-
[36]
Improved ASR Performance for Dysarthric Speech Using Two-stage Data Augmentation,
C. Bhat, A. Panda, and H. Strik, “Improved ASR Performance for Dysarthric Speech Using Two-stage Data Augmentation,” in Proc. Interspeech, Incheon, 2022
2022
-
[37]
Few-shot Dysarthric Speech Recognition with Text-to-Speech Data Augmentation,
E. Hermann and M. Magimai-Doss, “Few-shot Dysarthric Speech Recognition with Text-to-Speech Data Augmentation,” inProc. Interspeech, Dublin, 2023
2023
-
[38]
Training Data Augmentation for Dysarthric Automatic Speech Recognition by Text-to-Dysarthric-Speech Synthesis,
W.-Z. Leung, M. Cross, A. Ragni, and S. Goetze, “Training Data Augmentation for Dysarthric Automatic Speech Recognition by Text-to-Dysarthric-Speech Synthesis,” inProc. Interspeech, Kos, 2024
2024
-
[39]
Data Augmenta- tion using Speech Synthesis for Speaker-Independent Dysarthria Severity Classification,
M. Kim, M. Han, S. Hong, and M.-w. Koo, “Data Augmenta- tion using Speech Synthesis for Speaker-Independent Dysarthria Severity Classification,” inProc. Interspeech, Rotterdam, 2025
2025
-
[40]
The V oiceMOS Challenge 2022,
W.-C. Huang, E. Cooper, Y . Tsao, H.-M. Wang, T. Toda, and J. Ya- magishi, “The V oiceMOS Challenge 2022,” inProc. Interspeech, Incheon, 2022
2022
-
[41]
MOSNet: Deep Learning-Based Ob- jective Assessment for V oice Conversion,
C.-C. Lo, S.-W. Fu, W.-C. Huang, X. Wang, J. Yamagishi, Y . Tsao, and H.-M. Wang, “MOSNet: Deep Learning-Based Ob- jective Assessment for V oice Conversion,” inProc. Interspeech, Graz, 2019
2019
-
[42]
Position: Towards Responsible Evaluation for Text-to-Speech,
Y . Yang, H. Wang, B. Han, S. Liu, J. Li, Y . Qin, and X. Chen, “Position: Towards Responsible Evaluation for Text-to-Speech,” inProc. ICML, Seoul, 2026
2026
-
[43]
Towards Fine-Grained and Multi-Granular Contrastive Language-Speech Pre-training,
Y . Yang, B. Han, H. Wang, W. Wang, Z. Ma, L. Zhou, Z. Jin, G. Yang, T. Wang, X. Tanet al., “Towards Fine-Grained and Multi-Granular Contrastive Language-Speech Pre-training,” in Proc. ACL, San Diego, 2026
2026
-
[44]
Measuring Prosody Diversity in Zero-Shot TTS: A New Metric, Benchmark, and Exploration,
Y . Yang, B. Han, H. Wang, L. Zhou, W. Wang, M. Cui, X. Tan, and X. Chen, “Measuring Prosody Diversity in Zero-Shot TTS: A New Metric, Benchmark, and Exploration,” inProc. IEEE ICASSP, Barcelona, 2026
2026
-
[45]
Enabling Auditory Large Lan- guage Models for Automatic Speech Quality Evaluation,
S. Wang, W. Yu, Y . Yang, C. Tang, Y . Li, J. Zhuang, X. Chen, X. Tian, J. Zhang, G. Sunet al., “Enabling Auditory Large Lan- guage Models for Automatic Speech Quality Evaluation,” inProc. ICASSP, Hyderabad, 2025
2025
-
[46]
Audio Large Language Models Can Be De- scriptive Speech Quality Evaluators,
C. Chen, Y . Hu, S. Wang, H. Wang, Z. Chen, C. Zhang, C.-H. H. Yang, and E. Chng, “Audio Large Language Models Can Be De- scriptive Speech Quality Evaluators,” inProc. ICLR, Singapore, 2025
2025
-
[47]
Towards General Auditory Intelligence: Large Multimodal Models for Machine Listening and Speaking,
S. Wang, Z. Jin, C. Tang, Q. Li, B. Li, C. Chen, Y . Hu, W. Yu, Y . Li, J. Zhuanget al., “Towards General Auditory Intelligence: Large Multimodal Models for Machine Listening and Speaking,” arXiv preprint arXiv:2511.01299, 2025
arXiv 2025
-
[48]
The Interspeech 2025 Speech Accessibility Project Challenge,
X. Zheng, B. Phukon, J. Na, E. Cutrell, K. Han, M. Hasegawa- Johnson, P.-P. Jiang, A. Kuila, C. Lea, B. MacDonaldet al., “The Interspeech 2025 Speech Accessibility Project Challenge,” inProc. Interspeech, Rotterdam, 2025
2025
-
[49]
QualiSpeech: A Speech Quality Assessment Dataset with Natural Language Reasoning and Descriptions,
S. Wang, W. Yu, X. Chen, X. Tian, J. Zhang, L. Lu, Y . Tsao, J. Yamagishi, Y . Wang, and C. Zhang, “QualiSpeech: A Speech Quality Assessment Dataset with Natural Language Reasoning and Descriptions,” inProc. ACL, Vienna, 2025
2025
-
[50]
How do V oices from Past Speech Synthesis Challenges Compare Today?
E. Cooper and J. Yamagishi, “How do V oices from Past Speech Synthesis Challenges Compare Today?” inProc. ISCA SSW, Bu- dapest, 2021
2021
-
[51]
NISQA: A Deep CNN-Self-Attention Model for Multidimensional Speech Quality Prediction with Crowdsourced Datasets,
G. Mittag, B. Naderi, A. Chehadi, and S. M ¨oller, “NISQA: A Deep CNN-Self-Attention Model for Multidimensional Speech Quality Prediction with Crowdsourced Datasets,” inProc. Inter- speech, Brno, 2021
2021
-
[52]
GigaSpeech: An Evolving, Multi-Domain ASR Corpus with 10,000 Hours of Transcribed Audio,
G. Chen, S. Chai, G. Wang, J. Du, W.-Q. Zhang, C. Weng, D. Su, D. Povey, J. Trmal, J. Zhanget al., “GigaSpeech: An Evolving, Multi-Domain ASR Corpus with 10,000 Hours of Transcribed Audio,” inProc. Interspeech, Brno, 2021
2021
-
[53]
UTMOS: UTokyo-SaruLab System for V oice- MOS Challenge 2022,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “UTMOS: UTokyo-SaruLab System for V oice- MOS Challenge 2022,” inProc. Interspeech, Incheon, 2022
2022
-
[54]
Gener- alization Ability of MOS Prediction Networks,
E. Cooper, W.-C. Huang, T. Toda, and J. Yamagishi, “Gener- alization Ability of MOS Prediction Networks,” inProc. IEEE ICASSP, Singapore, 2022
2022
-
[55]
Lib- riSpeech: An ASR Corpus Based on Public Domain Audio Books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- riSpeech: An ASR Corpus Based on Public Domain Audio Books,” inProc. IEEE ICASSP, South Brisbane, 2015
2015
-
[56]
Libri-Light: A Benchmark for ASR with Limited or No Supervision,
J. Kahn, M. Riviere, W. Zheng, E. Kharitonov, Q. Xu, P.-E. Mazar´e, J. Karadayi, V . Liptchinsky, R. Collobert, C. Fuegen et al., “Libri-Light: A Benchmark for ASR with Limited or No Supervision,” inProc. IEEE ICASSP, Barcelona, 2020
2020
-
[57]
Common V oice: A Massively-Multilingual Speech Corpus,
R. Ardila, M. Branson, K. Davis, M. Kohler, J. Meyer, M. Hen- retty, R. Morais, L. Saunders, F. Tyers, and G. Weber, “Common V oice: A Massively-Multilingual Speech Corpus,” inProc. LREC, Marseille, 2020
2020
-
[58]
SWITCH- BOARD: telephone speech corpus for research and development,
J. J. Godfrey, E. C. Holliman, and J. McDaniel, “SWITCH- BOARD: telephone speech corpus for research and development,” inProc. IEEE ICASSP, San Francisco, 1992
1992
-
[59]
The Fisher Corpus: a Re- source for the Next Generations of Speech-to-Text,
C. Cieri, D. Miller, and K. Walker, “The Fisher Corpus: a Re- source for the Next Generations of Speech-to-Text,” inProc. LREC’04, Lisbon, 2004
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.