A Self-Evolving Agentic System for Automated Generation and Execution of Biological Protocols
Pith reviewed 2026-07-03 22:01 UTC · model grok-4.3
The pith
ProtoPilot converts biological protocols into executable code that passes wet-lab gates at 88 percent success.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
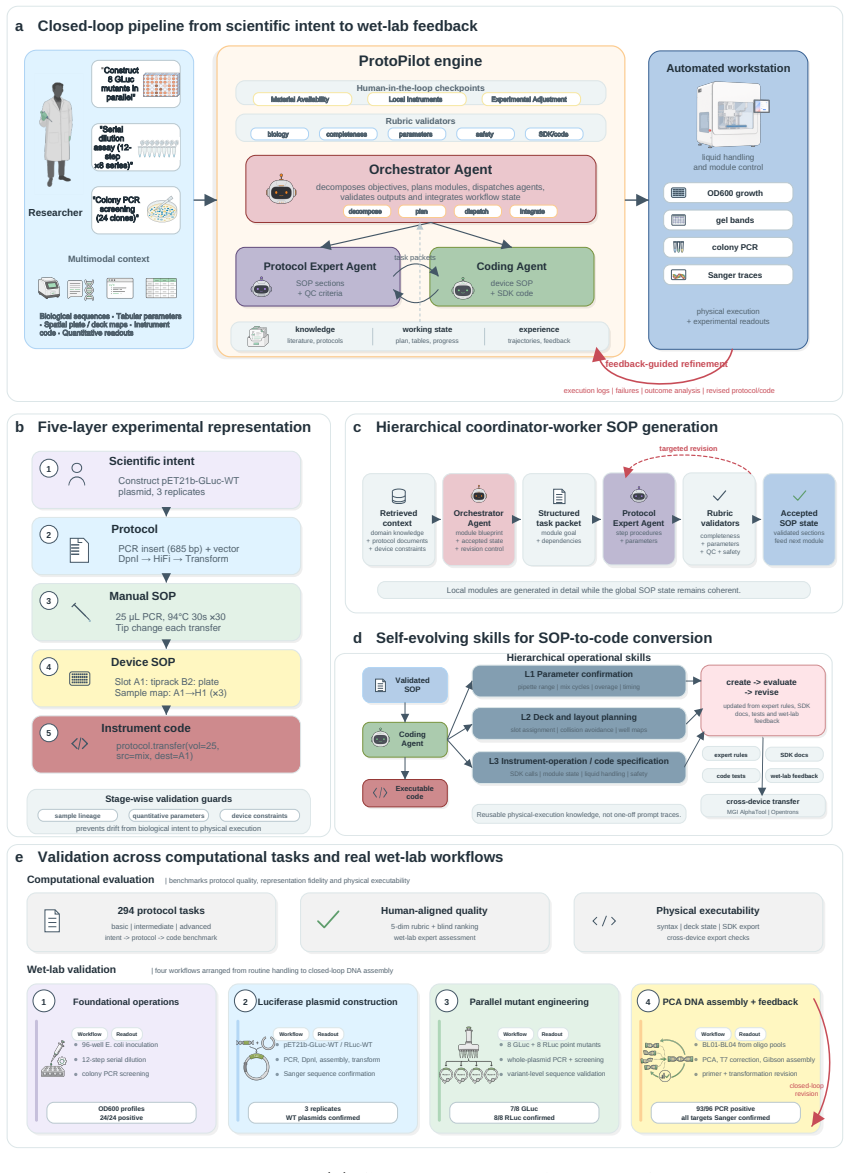
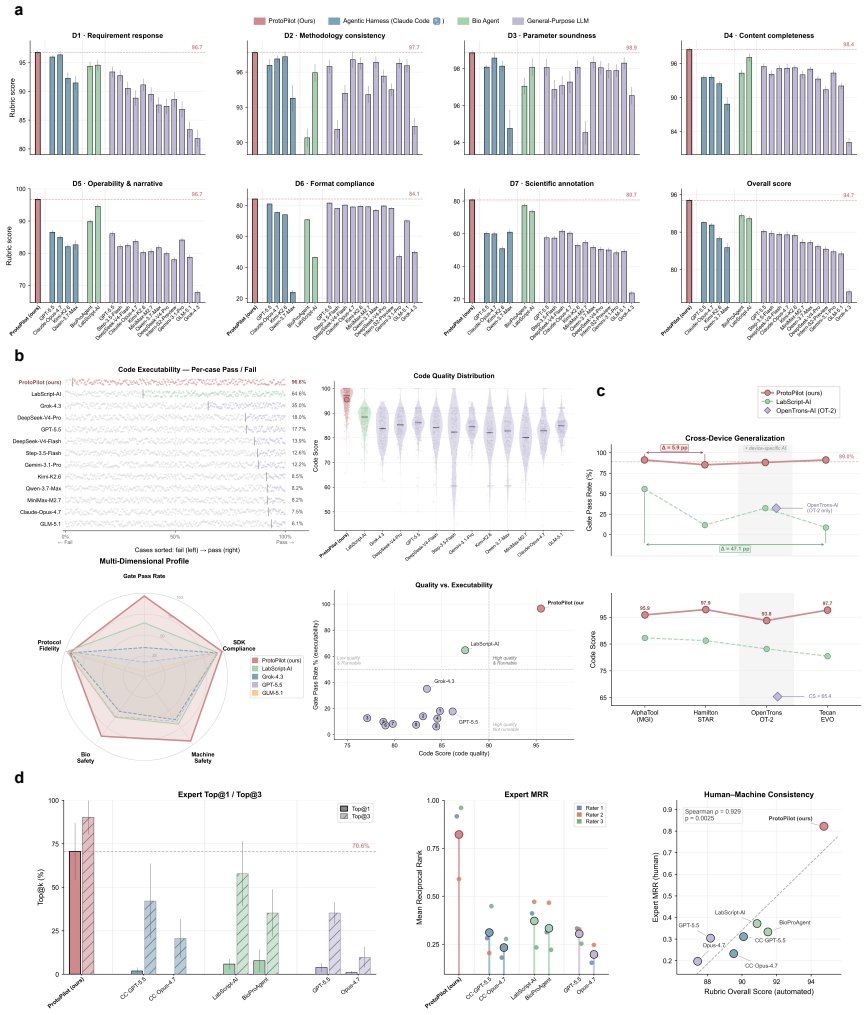
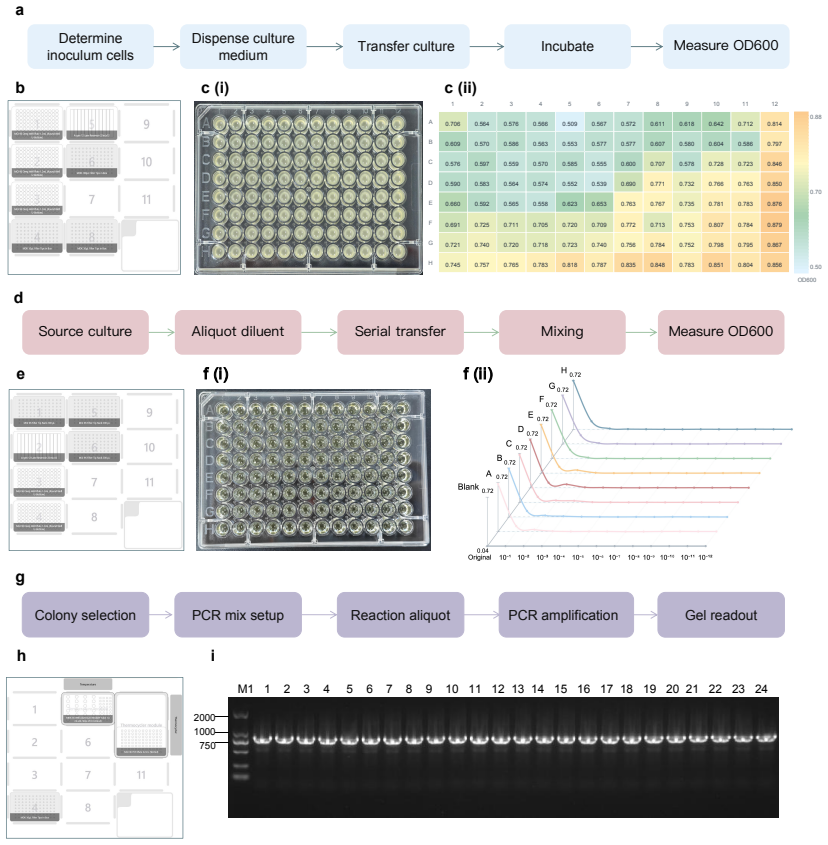
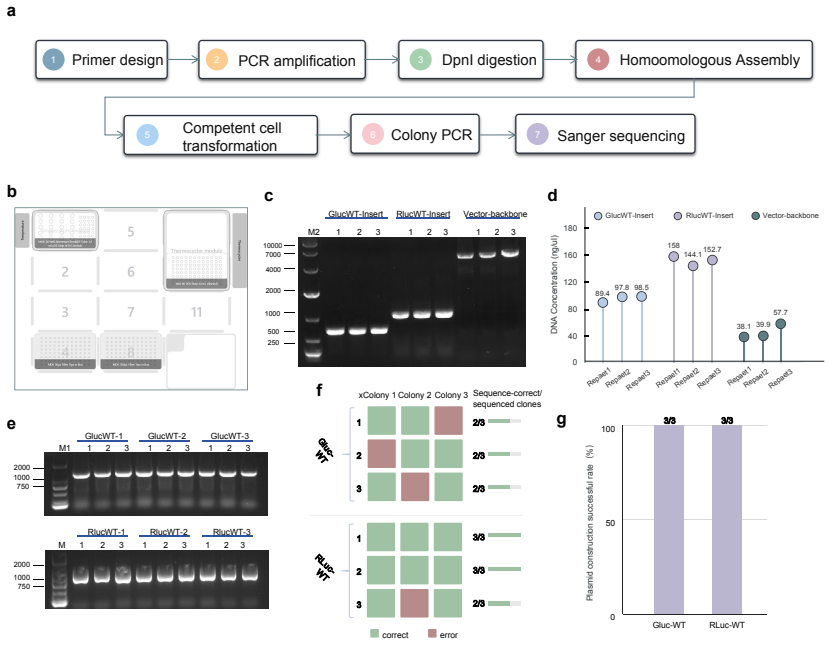
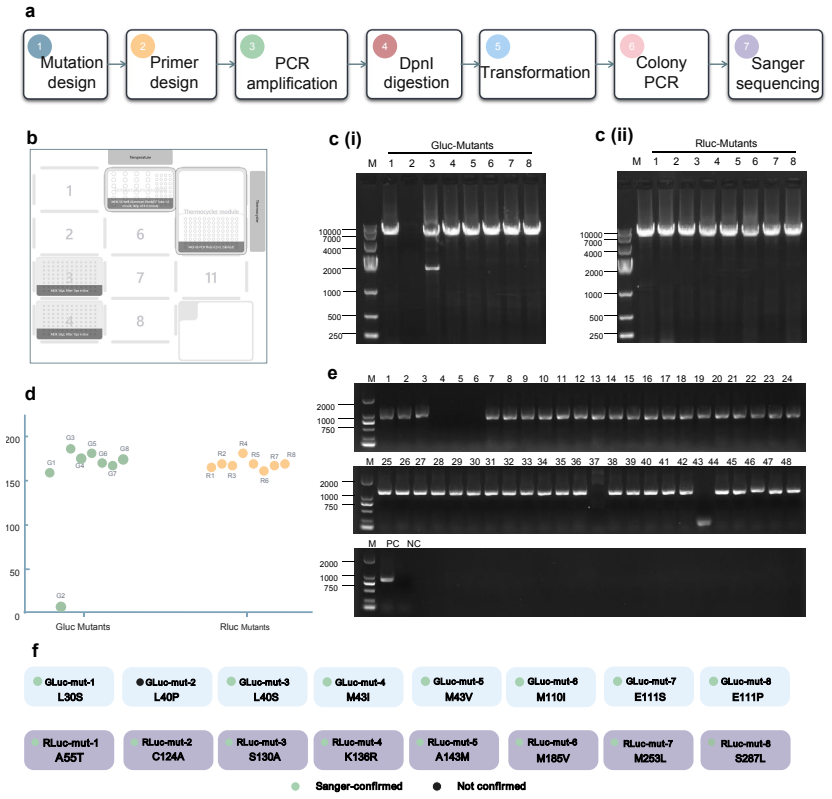
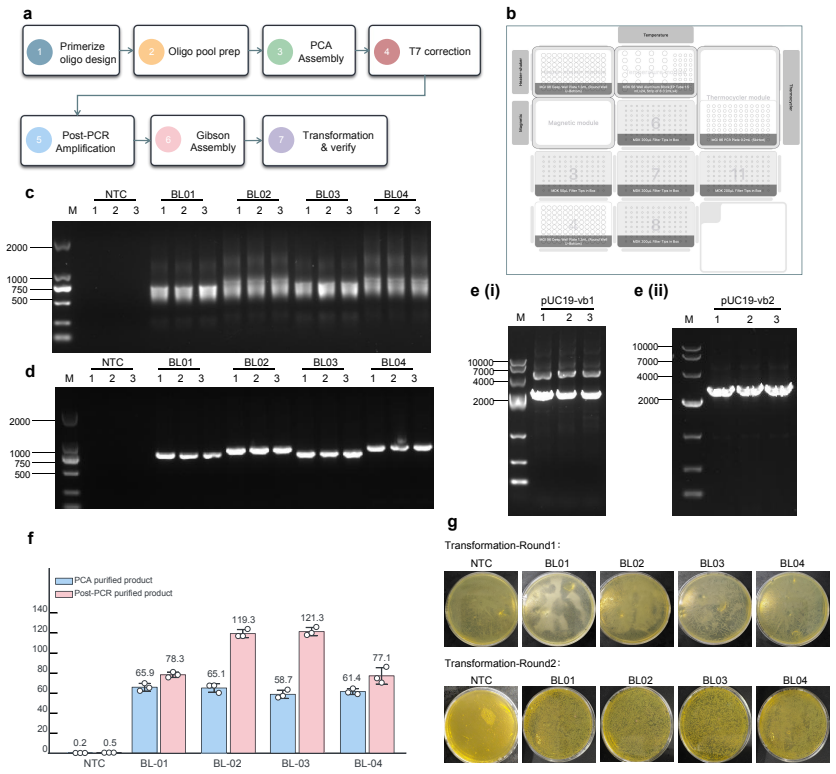
ProtoPilot incorporates layer-wise verifiability, multi-agent orchestration, and a runtime-updated skill library to generate protocols, expand SOPs, synthesize SDK-compliant code, and revise workflows from wet-lab feedback, achieving a Top@3 expert-preference rate of 90.2 percent, an overall protocol-to-code gate pass rate of 89.5 percent, and an Opentrons pass rate of 88.24 percent on 294 tasks from 98 gold-standard protocols, with wet-lab validation producing interpretable readouts, Sanger-confirmed products, and feedback-corrected PCA-assembled DNA targets.
What carries the argument
ProtoPilot, the self-evolving multi-agent system that uses layer-wise verifiability, multi-agent orchestration, and a runtime-updated skill library to align protocol text with device execution and experimental feedback.
If this is right
- The evaluation framework captures execution-relevant requirements for autonomous wet-lab automation.
- ProtoPilot converts protocol and code generation into validated execution and feedback-guided revision at scale.
- The system outperforms prior baselines such as OpenTrons-AI by more than 50 percentage points on the same gates.
- Wet-lab feedback loops enable correction of PCA-assembled DNA targets to produce Sanger-confirmed products.
Where Pith is reading between the lines
- Systems built on the same self-evolving loop could be tested on protocols for other lab platforms beyond Opentrons.
- The skill-library update mechanism might reduce the number of human revisions needed when new device constraints appear.
- If the benchmark tasks generalize, the same architecture could support iterative protocol improvement across multiple experimental rounds without restarting from text.
Load-bearing premise
The 294 tasks derived from 98 gold-standard protocols, together with the expert rubrics and device gates, are representative of the requirements for autonomous wet-lab automation in general.
What would settle it
A new collection of protocols outside the original 98 that produces expert preference or hardware pass rates comparable to the 32 percent baseline instead of the reported 88-90 percent figures.
Figures
read the original abstract
Autonomous wet-lab experimentation requires more than plausible protocol text: biological intent, quantitative procedures, device constraints and experimental feedback must remain aligned from protocol and SOP design to code and physical execution. We developed ProtoPilot, a self-evolving multi-agent system, together with an expert-grounded benchmark and evaluation framework for testing this conversion as an experimental automation problem. The framework spans 294 synthetic-biology and molecular-biology tasks derived from 98 gold-standard protocols, wet-lab expert rubrics, device-level validity gates and real experimental tests. ProtoPilot incorporates layer-wise verifiability, multi-agent orchestration and a runtime-updated skill library to generate protocols, expand SOPs, synthesize SDK-compliant code and revise workflows from wet-lab feedback. It achieved a Top@3 expert-preference rate of 90.2%, an overall protocol-to-code gate pass rate of 89.5% and an Opentrons pass rate of 88.24%, compared with 32.35% for OpenTrons-AI. Wet-lab validation produced interpretable readouts, Sanger-confirmed products and feedback-corrected PCA-assembled DNA targets, establishing a verifiable route to autonomous experimentation. Together, these results show that the evaluation framework captures execution-relevant requirements for autonomous wet-lab automation, and that ProtoPilot can meet them by converting protocol and code generation into validated execution and feedback-guided revision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ProtoPilot, a self-evolving multi-agent system for automated generation of biological protocols, expansion to SOPs, synthesis of SDK-compliant code, and revision from wet-lab feedback. It presents an expert-grounded benchmark of 294 synthetic-biology and molecular-biology tasks derived from 98 gold-standard protocols, along with device-level validity gates and real experimental tests. Reported results include a 90.2% Top@3 expert-preference rate, 89.5% protocol-to-code gate pass rate, and 88.24% Opentrons pass rate (vs. 32.35% for OpenTrons-AI), with wet-lab validations yielding interpretable readouts, Sanger-confirmed products, and feedback-corrected PCA-assembled DNA targets. The central claim is that the evaluation framework captures execution-relevant requirements for autonomous wet-lab automation and that ProtoPilot meets them.
Significance. If the benchmark representativeness holds, the work would be significant for demonstrating an integrated pipeline from protocol text to physical execution with self-evolution via feedback. The inclusion of real wet-lab validation, expert rubrics, and a direct baseline comparison provides concrete, falsifiable evidence of feasibility that goes beyond text generation. These elements strengthen the assessment of practical utility in lab automation.
major comments (2)
- [Abstract] Abstract: The claim that 'the evaluation framework captures execution-relevant requirements for autonomous wet-lab automation' is load-bearing for the conclusion but rests on the unverified assumption that the 294 tasks from 98 protocols are representative; no diversity breakdown, coverage argument across domains (e.g., cell-based assays, real-time adaptive control, non-Opentrons hardware), or ablation outside the sampled set is provided.
- [Evaluation Framework] Evaluation Framework section: The assumption that expert rubrics and device-level validity gates are sufficiently representative of general autonomous wet-lab automation requirements is central to interpreting the high numeric scores (90.2%, 89.5%, 88.24%) as evidence of broader capability, yet no supporting analysis of protocol diversity or cross-domain generalization is supplied.
minor comments (2)
- [Abstract] Abstract: Terms such as 'layer-wise verifiability' and 'runtime-updated skill library' are introduced without concise definitions or pointers to their implementation in the methods.
- [Results] The description of how post-hoc protocol revisions from wet-lab feedback were counted and incorporated into performance metrics lacks sufficient detail for independent verification.
Simulated Author's Rebuttal
We thank the referee for their detailed feedback on the representativeness of the evaluation framework. We address each major comment below and agree that explicit scoping and limitations discussion will improve the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'the evaluation framework captures execution-relevant requirements for autonomous wet-lab automation' is load-bearing for the conclusion but rests on the unverified assumption that the 294 tasks from 98 protocols are representative; no diversity breakdown, coverage argument across domains (e.g., cell-based assays, real-time adaptive control, non-Opentrons hardware), or ablation outside the sampled set is provided.
Authors: We agree that the abstract claim is scoped to the domains and hardware in the study. The 98 protocols were selected as gold-standard examples from synthetic-biology and molecular-biology literature for Opentrons-executable tasks. The manuscript does not provide a diversity breakdown or cross-domain coverage argument. We will revise the abstract to qualify the claim and add a limitations subsection in the Evaluation Framework section that includes a brief overview of protocol categories (e.g., PCR, assembly, transformation) and explicitly states the benchmark's intended scope without asserting generalization beyond Opentrons-based synthetic and molecular biology workflows. revision: yes
-
Referee: [Evaluation Framework] Evaluation Framework section: The assumption that expert rubrics and device-level validity gates are sufficiently representative of general autonomous wet-lab automation requirements is central to interpreting the high numeric scores (90.2%, 89.5%, 88.24%) as evidence of broader capability, yet no supporting analysis of protocol diversity or cross-domain generalization is supplied.
Authors: The framework and metrics are presented for the specific setting of protocol-to-Opentrons-code conversion on the sampled tasks. No diversity analysis or cross-domain generalization tests appear in the current text. In revision we will add a short diversity table or paragraph summarizing task distribution across the 98 protocols and a limitations paragraph clarifying that the reported scores reflect performance within this scope rather than general autonomous wet-lab automation. revision: yes
Circularity Check
No circularity: empirical validation rests on external gold standards and wet-lab tests
full rationale
The provided abstract and description contain no equations, fitted parameters, or derivation chain. The benchmark is constructed from 98 external gold-standard protocols plus independent expert rubrics and physical wet-lab execution (Sanger sequencing, PCA assembly). Success metrics are reported against these external references and a baseline (OpenTrons-AI), with no reduction of predictions to the system's own training loop or self-citations. The self-evolving mechanism uses runtime feedback for revision, but the evaluation framework is presented as separately grounded and falsifiable via wet-lab outcomes. This satisfies the criteria for a self-contained empirical result with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gottweis, J.et al.Accelerating scientific discovery with Co-Scientist.Nature,1–3 (2026)
2026
-
[2]
L., Pak, J
Swanson, K., Wu, W., Bulaong, N. L., Pak, J. E. & Zou, J. The Virtual Lab of AI agents designs new SARS-CoV-2 nanobodies.Nature646,716–723 (2025)
2025
-
[3]
Gao, S.et al.Empowering biomedical discovery with AI agents.Cell187,6125–6151 (2024)
2024
-
[4]
E.et al.A multi-agent system for automating scientific discovery.Nature,1–3 (2026)
Ghareeb, A. E.et al.A multi-agent system for automating scientific discovery.Nature,1–3 (2026)
2026
-
[5]
Wang, Y.et al.Accelerating primer design for amplicon sequencing using large language model- powered agents.Nature Biomedical Engineering10,338–353 (2026)
2026
-
[6]
D.et al.The automation of science.Science324,85–89 (2009)
King, R. D.et al.The automation of science.Science324,85–89 (2009)
2009
-
[7]
T., Bremer, B
Rapp, J. T., Bremer, B. J. & Romero, P. A. Self-driving laboratories to autonomously navigate the protein fitness landscape.Nature chemical engineering1,97–107 (2024)
2024
-
[8]
A.et al.Using a GPT-5-driven autonomous lab to optimize the cost and titer of cell-free protein synthesis.bioRxiv,2026–02 (2026)
Smith, A. A.et al.Using a GPT-5-driven autonomous lab to optimize the cost and titer of cell-free protein synthesis.bioRxiv,2026–02 (2026)
2026
-
[9]
Jin, R.et al.BioLab: End-to-end autonomous life sciences research with multi-agents system integrating biological foundation models.BioRxiv,2025–09 (2025)
2025
- [10]
-
[11]
Li, J., Wang, M., Zheng, Z. & Zhang, M.Loogle: Can long-context language models understand long contexts?inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)(2024), 16304–16333
2024
-
[12]
& Thies, W
Ananthanarayanan, V. & Thies, W. Biocoder: A programming language for standardizing and automating biology protocols.Journal of biological engineering4,13 (2010). 16
2010
-
[13]
Gao, Y.et al.Autonomous liquid-handling robotics scripting through large language models enables accessible and safe protein engineering workflows.bioRxiv,2025–09 (2025)
2025
-
[14]
Bartley, B.et al.Building an open representation for biological protocols.ACM Journal on Emerging Technologies in Computing Systems19,1–21 (2023)
2023
-
[15]
& Goñi-Moreno, Á
Anhel, A.-M., Alejaldre, L. & Goñi-Moreno, Á. The Laboratory Automation Protocol (LAP) Format and Repository: a platform for enhancing workflow efficiency in synthetic biology.ACS synthetic biology12,3514–3520 (2023)
2023
-
[16]
BioProAgent: Neuro-Symbolic Grounding for Constrained Scientific Planning
Liu, Y., Wang, J., Lv, L. & Tian, Y. BioProAgent: Neuro-Symbolic Grounding for Constrained Scientific Planning.arXiv preprint arXiv:2603.00876(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Acknowledgements This work was jointly supported by Shanghai Artificial Intelligence Laboratory and Genoria AI Tech- nology Co., Ltd
Song, R.et al.Towards autonomous biology: Compiler-Verified Protocols as a Foundation for Real World AI Execution.bioRxiv,2026–05 (2026). Acknowledgements This work was jointly supported by Shanghai Artificial Intelligence Laboratory and Genoria AI Tech- nology Co., Ltd. Competing Interests The authors declare no competing interests. Appendix Extended Dat...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.