Retrieval-Based Brain Decoding by Alignment, not Complexity
Pith reviewed 2026-06-26 18:34 UTC · model grok-4.3
The pith
Linear contrastive decoders map fMRI activity to foundation model embeddings more accurately than ridge regression or non-linear alternatives across images, text, and sound.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
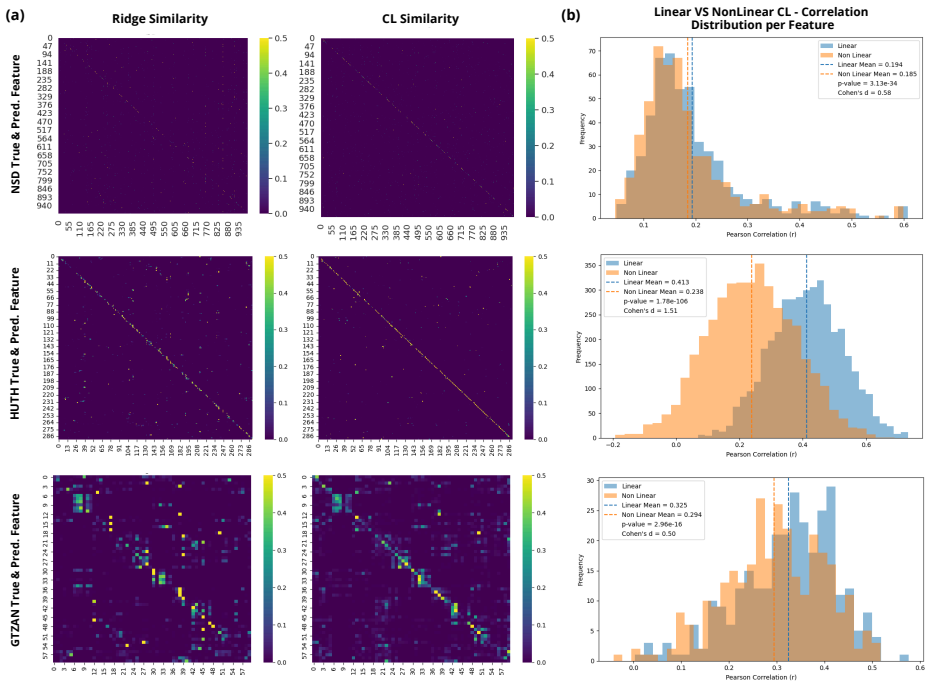
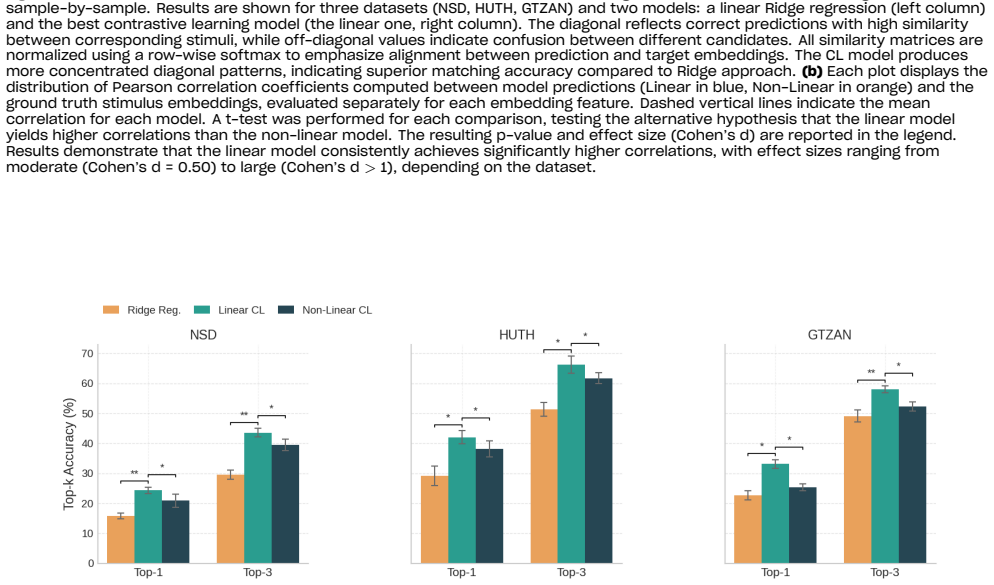
Although neural computations are highly non-linear at the microscale, fMRI measurements average signals across space and time, further smoothed by noise, effectively linearizing the observable representation. As a result, linear contrastive decoders consistently outperform ridge regression and standard non-linear alternatives when mapping fMRI activity to the embedding spaces of foundation models, and these results generalize across images, text, and sound.
What carries the argument
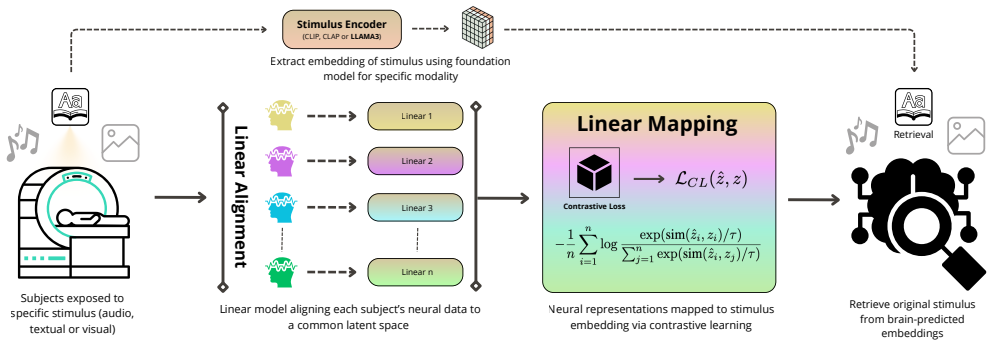
Linear contrastive decoder that aligns fMRI activity vectors with foundation-model embeddings via a contrastive training objective.
If this is right
- Decoding gains arise more from the choice of training objective than from architectural complexity.
- Contrastive-linear models constitute a principled strategy for brain decoding.
- The same linear-contrastive approach succeeds for vision, language, and audio stimuli.
- Performance improvements are expected to generalize across additional fMRI datasets.
Where Pith is reading between the lines
- Retrieval-based decoding may extend naturally to other coarse-grained neuroimaging signals such as EEG or MEG.
- Semantic embedding spaces appear to capture a large fraction of the variance observable in averaged fMRI responses.
- Linear alignment could serve as a baseline for testing whether finer-scale recordings require non-linear mappings.
Load-bearing premise
fMRI measurements average signals across space and time and are smoothed by noise, which linearizes the observable brain representation.
What would settle it
Non-linear models trained with the identical contrastive objective would need to produce reliably higher retrieval accuracy than the linear version on held-out fMRI data from at least two modalities.
Figures

read the original abstract
A prominent theory in cognitive science suggests that concepts in the brain are organized as high-dimensional vectors, with semantic meaning captured by directions and relative angles in this space. Brain decoding is the effort of reconstructing or retrieving stimuli (or their representations) from neural activity and involves finding a function that approximates how the brain represents concepts. This motivates the investigation of contrastive objectives as biologically plausible candidates to reverse the brain loss function. In this work, we study how functional MRI (fMRI) activity can generally be mapped with the embedding spaces of foundation models in vision, language, and audio. Although neural computations are highly non-linear at the microscale, fMRI measurements average signals across space and time, further smoothed by noise, effectively linearizing the observable representation. Consistent with these views, our experiments across multiple datasets demonstrate that linear contrastive decoders consistently outperform ridge regression and standard non-linear alternatives, and that these results generalize across images, text, and sound. These findings indicate that decoding gains arise more from the choice of training objective than from architectural complexity, pointing to contrastive-linear models as a principled strategy for brain decoding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that fMRI-based brain decoding to foundation model embeddings (vision, language, audio) is best performed by linear contrastive decoders, which outperform both ridge regression and standard non-linear alternatives across multiple datasets. It attributes the gains primarily to the choice of contrastive training objective rather than architectural complexity, and argues that fMRI's spatial/temporal averaging and noise effectively linearize the observable neural representations, making contrastive-linear models a principled decoding strategy.
Significance. If the central comparison is shown to isolate objective from architecture, the result would be significant: it supplies cross-modal evidence that simple linear models suffice for retrieval-based decoding when trained contrastively, offers a computationally efficient alternative to complex non-linear decoders, and aligns with the view that contrastive objectives are biologically plausible for approximating brain representations. The generalization across images, text, and sound is a clear strength of the reported experiments.
major comments (1)
- [Abstract] Abstract: the central interpretation that 'decoding gains arise more from the choice of training objective than from architectural complexity' requires that the 'standard non-linear alternatives' were trained under the identical contrastive objective used for the linear decoders. The provided description gives no indication that non-linear contrastive variants were evaluated; without this control the results remain consistent with either objective or model-class effects and therefore do not support the claimed separation of factors.
minor comments (2)
- Methods and results sections should report dataset sizes, number of subjects, exact statistical tests, and p-values supporting the outperformance claims.
- The precise architectures, loss functions, and hyper-parameter regimes for the non-linear baselines need explicit description to allow replication of the comparison.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive comment. The observation correctly identifies a limitation in how the abstract frames the separation between training objective and model complexity. We address the point directly below and will revise the manuscript to ensure the claims accurately reflect the experiments performed.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central interpretation that 'decoding gains arise more from the choice of training objective than from architectural complexity' requires that the 'standard non-linear alternatives' were trained under the identical contrastive objective used for the linear decoders. The provided description gives no indication that non-linear contrastive variants were evaluated; without this control the results remain consistent with either objective or model-class effects and therefore do not support the claimed separation of factors.
Authors: We agree with the referee's assessment. The non-linear alternatives evaluated in the manuscript were trained with standard regression objectives (primarily mean-squared error), not the contrastive loss used for the linear decoders. Consequently, the reported results show that linear contrastive models outperform both ridge regression and typical non-linear regression models, but they do not isolate the contribution of the objective from architectural capacity. We will revise the abstract and the corresponding discussion sections to remove the stronger claim of separation and instead state that contrastive training yields strong retrieval performance even when restricted to linear mappings, outperforming more complex non-linear models trained under conventional regression losses. This revision will be made in the next version of the manuscript. revision: yes
Circularity Check
No circularity: purely empirical comparison with no derivation chain
full rationale
The paper reports experimental results comparing linear contrastive decoders against ridge regression and non-linear baselines on fMRI datasets for image, text, and audio modalities. No equations, first-principles derivations, or load-bearing self-citations are present in the provided text that reduce any claimed result to its own inputs by construction. The central claim rests on observed performance differences, which are falsifiable via replication on held-out data and do not involve fitted parameters renamed as predictions or ansatzes smuggled through citations. This is a standard empirical study; the derivation chain is absent, so circularity score is 0.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption fMRI measurements average signals across space and time, further smoothed by noise, effectively linearizing the observable representation
Reference graph
Works this paper leans on
-
[1]
Why concepts are (probably) vectors
Steven T Piantadosi, Dyana CY Muller, Joshua S Rule, Karthikeya Kaushik, Mark Gorenstein, Elena R Leib, and Emily Sanford. Why concepts are (probably) vectors. Trends in Cognitive Sciences , 28(9):844–856, 2024
2024
-
[2]
Bassett, et al
Erfan Nozari, Dani S. Bassett, et al. Macroscopic resting-state brain dynamics are best described by linear models. Nature Biomedical Engineering , 8:7–8, 2024
2024
-
[3]
Reconstructing visual experiences from brain activity evoked by natural movies
Shinji Nishimoto, An T Vu, Thomas Naselaris, Yuval Benjamini, Bin Yu, and Jack L Gallant. Reconstructing visual experiences from brain activity evoked by natural movies. Current biology , 21(19):1641–1646, 2011
2011
-
[4]
Huth, Willem A
Alexander G. Huth, Willem A. de Heer, Thomas L. Griffiths, et al. Natural speech reveals the semantic maps that tile human cerebral cortex. Nature, 532(7600):453–458, 2016
2016
-
[5]
Through their eyes: Multi- subject brain decoding with simple alignment techniques
Matteo Ferrante, Tommaso Boccato, Furkan Ozcelik, Rufin VanRullen, and Nicola Toschi. Through their eyes: Multi- subject brain decoding with simple alignment techniques. Imaging Neuroscience, 2:1–21, 05 2024
2024
-
[6]
Scaling laws for de- coding images from brain activity, 2025
Hubert Banville, Y ohann Benchetrit, Stéphane d’Ascoli, Jérémy Rapin, and Jean-Rémi King. Scaling laws for de- coding images from brain activity, 2025
2025
-
[7]
Natural scene reconstruction from fmri signals using generative latent diffu- sion
Furkan Ozcelik and Rufin VanRullen. Natural scene reconstruction from fmri signals using generative latent diffu- sion. Scientific Reports , 13(1):15666, 2023
2023
-
[8]
Mind reader: Reconstructing complex images from brain activities
Sikun Lin, Thomas Sprague, and Ambuj K Singh. Mind reader: Reconstructing complex images from brain activities. Advances in Neural Information Processing Systems , 35:29624–29636, 2022
2022
-
[9]
Reconstructing the mind’s eye: fmri-to-image with con- trastive learning and diffusion priors
Paul Scotti, Atmadeep Banerjee, Jimmie Goode, Stepan Shabalin, Alex Nguyen, Aidan Dempster, Nathalie Verlinde, Elad Yundler, David Weisberg, Kenneth Norman, et al. Reconstructing the mind’s eye: fmri-to-image with con- trastive learning and diffusion priors. Advances in Neural Information Processing Systems , 36:24705–24728, 2023
2023
-
[10]
Dream: Visual decoding from reversing human visual system
Weihao Xia, Raoul De Charette, Cengiz Oztireli, and Jing-Hao Xue. Dream: Visual decoding from reversing human visual system. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages 8226– 8235, 2024
2024
-
[11]
Cinematic mindscapes: High-quality video reconstruction from brain activity
Zijiao Chen, Jiaxin Qing, and Juan Helen Zhou. Cinematic mindscapes: High-quality video reconstruction from brain activity. Advances in Neural Information Processing Systems , 36:24841–24858, 2023
2023
-
[12]
T ang, A
J. T ang, A. LeBel, S. Jain, et al. Semantic reconstruction of continuous language from non-invasive brain recordings. Nature Neuroscience, 26:858–866, 2023
2023
-
[13]
Optimizing fmri data acquisition for decoding natural speech with limited participants
Louis Jalouzot, Alexis Thual, Y air Lakretz, Christophe Pallier, and Bertrand Thirion. Optimizing fmri data acquisition for decoding natural speech with limited participants. arXiv preprint arXiv:2505.21304 , 2025
arXiv 2025
-
[14]
Denk, Yu T akagi, T akuya Matsuyama, Andrea Agostinelli, Tomoya Nakai, Christian Frank, and Shinji Nishimoto
Timo I. Denk, Yu T akagi, T akuya Matsuyama, Andrea Agostinelli, Tomoya Nakai, Christian Frank, and Shinji Nishimoto. Brain2music: Reconstructing music from human brain activity, 2023. 8
2023
-
[15]
R&b-rhythm and brain: Cross-subject decoding of music from human brain activity
Matteo Ciferri, Matteo Ferrante, and Nicola Toschi. R&b-rhythm and brain: Cross-subject decoding of music from human brain activity. Neural Networks , page 109195, 2026
2026
-
[16]
Generative language reconstruction from brain recordings
Ziyi Y e, Qingyao Ai, Yiqun Liu, Maarten de Rijke, Min Zhang, Christina Lioma, and Tuukka Ruotsalo. Generative language reconstruction from brain recordings. Communications Biology , 8(1):346, 2025
2025
-
[17]
Yulong Liu, Y ongqiang Ma, Wei Zhou, Guibo Zhu, and Nanning Zheng. Brainclip: Bridging brain and visual-linguistic representation via clip for generic natural visual stimulus decoding. arXiv preprint arXiv:2302.12971 , 2023
arXiv 2023
-
[18]
Mindeye2: Shared-subject models enable fmri-to-image with 1 hour of data
Paul S Scotti, Mihir Tripathy, Cesar Kadir Torrico Villanueva, Reese Kneeland, Tong Chen, Ashutosh Narang, Charan Santhirasegaran, Jonathan Xu, Thomas Naselaris, Kenneth A Norman, et al. Mindeye2: Shared-subject models enable fmri-to-image with 1 hour of data. arXiv preprint arXiv:2403.11207 , 2024
arXiv 2024
-
[19]
Umbrae: Unified multimodal brain decoding
Weihao Xia, Raoul de Charette, Cengiz Oztireli, and Jing-Hao Xue. Umbrae: Unified multimodal brain decoding. In European Conference on Computer Vision , pages 242–259. Springer, 2024
2024
-
[20]
Dynadiff: Single-stage decoding of images from contin- uously evolving fmri
Marlène Careil, Y ohann Benchetrit, and Jean-Rémi King. Dynadiff: Single-stage decoding of images from contin- uously evolving fmri. arXiv preprint arXiv:2505.14556 , 2025
arXiv 2025
-
[21]
Matteo Ciferri, Tommaso Boccato, Michal Olak, Matteo Ferrante, and Nicola Toschi. Mapping whisper representa- tions to human ecog responses with interpretable time-resolved neural encoding. arXiv preprint arXiv:2606.02305, 2026
Pith/arXiv arXiv 2026
-
[22]
Seeing beyond the brain: Conditional diffusion model with sparse masked modeling for vision decoding
Zijiao Chen, Jiaxin Qing, Tiange Xiang, Wan Lin Yue, and Juan Helen Zhou. Seeing beyond the brain: Conditional diffusion model with sparse masked modeling for vision decoding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 22710–22720, 2023
2023
-
[23]
A massive 7t fmri dataset to bridge cognitive neuroscience and artificial intelligence
Emily J Allen, Ghislain St-Yves, Yihan Wu, Jesse L Breedlove, Jacob S Prince, Logan T Dowdle, Matthias Nau, Brad Caron, Franco Pestilli, Ian Charest, et al. A massive 7t fmri dataset to bridge cognitive neuroscience and artificial intelligence. Nature neuroscience, 25(1):116–126, 2022
2022
-
[24]
Glmdenoise: a fast, auto- mated technique for denoising task-based fmri data
Kendrick Kay, Ariel Rokem, Jonathan Winawer, Robert Dougherty, and Brian Wandell. Glmdenoise: a fast, auto- mated technique for denoising task-based fmri data. Frontiers in Neuroscience , 7, 2013
2013
-
[25]
Improving the accuracy of single-trial fmri response estimates using glmsingle
Jacob S Prince, Ian Charest, Jan W Kurzawski, John A Pyles, Michael J T arr, and Kendrick N Kay. Improving the accuracy of single-trial fmri response estimates using glmsingle. eLife, 11:e77599, nov 2022
2022
-
[26]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning , pages 87 48–8763. PmLR, 2021
2021
-
[27]
LeBel, L
A. LeBel, L. Wagner, S. Jain, et al. A natural language fmri dataset for voxelwise encoding models. Scientific Data , 10:555, 2023
2023
-
[28]
The llama 3 herd of models
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Y ang, Angela Fan, et al. The llama 3 herd of models. arXiv e-prints , pages arXiv–2407, 2024
2024
-
[29]
Interpreting and improving natural-language processing (in machines) with natural language-processing (in the brain)
Mariya Toneva and Leila Wehbe. Interpreting and improving natural-language processing (in machines) with natural language-processing (in the brain). Advances in neural information processing systems , 32, 2019
2019
-
[30]
Music genre neuroimaging dataset
Tomoya Nakai, Naoko Koide-Majima, and Shinji Nishimoto. Music genre neuroimaging dataset. Data in Brief , 40:107675, 2022
2022
-
[31]
Clap learning audio concepts from natural language supervision
Benjamin Elizalde, Soham Deshmukh, Mahmoud Al Ismail, and Huaming Wang. Clap learning audio concepts from natural language supervision. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages 1–5. IEEE, 2023
2023
-
[32]
Evidence for compositionality in fmri visual representations via brain algebra
Matteo Ferrante, Tommaso Boccato, Nicola Toschi, and Rufin VanRullen. Evidence for compositionality in fmri visual representations via brain algebra. Communications Biology , 8(1):1263, 2025
2025
-
[33]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In International conference on machine learning , pages 1597–1607. PmLR, 2020
2020
-
[34]
Different scaling of linear models and deep learning in ukbiobank brain images versus machine-learning datasets
Marc-Andre Schulz, BT Thomas Y eo, Joshua T Vogelstein, Janaina Mourao-Miranada, Jakob N Kather, Konrad Ko- rding, Blake Richards, and Danilo Bzdok. Different scaling of linear models and deep learning in ukbiobank brain images versus machine-learning datasets. Nature communications, 11(1):4238, 2020
2020
-
[35]
Semantic language decoding across participants and stimulus modalities
Jerry T ang and Alexander G Huth. Semantic language decoding across participants and stimulus modalities. Cur- rent Biology , 35(5):1023–1032, 2025
2025
-
[36]
Tribe: Trimodal brain encoder for whole-brain fmri response prediction
Stéphane d’Ascoli, Jérémy Rapin, Y ohann Benchetrit, Hubert Banville, and Jean-Rémi King. Tribe: Trimodal brain encoder for whole-brain fmri response prediction. arXiv preprint arXiv:2507.22229 , 2025
arXiv 2025
-
[37]
Across-subject ensemble-learning alleviates the need for large samples for fmri decoding
Himanshu Aggarwal, Liza Al-Shikhley, and Bertrand Thirion. Across-subject ensemble-learning alleviates the need for large samples for fmri decoding. In International Conference on Medical Image Computing and Computer- Assisted Intervention , pages 35–45. Springer, 2024
2024
-
[38]
Aligning brain functions boosts the decoding of visual semantics in novel subjects
Alexis Thual, Y ohann Benchetrit, Felix Geilert, Jérémy Rapin, Iurii Makarov, Hubert Banville, and Jean-Rémi King. Aligning brain functions boosts the decoding of visual semantics in novel subjects. arXiv preprint arXiv:2312.06467 , 2023
arXiv 2023
-
[39]
Identity
Rafael Yuste, Sara Goering, Blaise Agüera Y Arcas, Guoqiang Bi, Jose M Carmena, Adrian Carter, Joseph J Fins, Phoebe Friesen, Jack Gallant, Jane E Huggins, et al. Four ethical priorities for neurotechnologies and ai. Nature, 551(7679):159–163, 2017. 9 A Statements Ethics Statement This study uses only publicly available datasets. No new human-subject data...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.